由浅到深,入门搜索原理
SkrShop电商搜索业务第2篇(第一阶段全2篇) ~

本文均以开源搜索引擎ES(Elasticsearch)为例,下文简称ES。
SkrShop系列终于更新了,本次带来电商搜索页面的介绍,本电商搜索系列分为两篇文章:
电商搜索业务介绍(上篇文章点击查看)
由浅到深,入门搜索原理
首先,本篇文章对于初次接触的同学来讲,涉及的概念会比较多,主要如下
| 搜索名词概念 | 描述 |
|---|---|
| 文档(Doc) | ? |
| 词条(Term) | ? |
| 倒排索引(Inverted Index) | ? |
| 关键字(Query) | ? |
| 召回(Recall) | ? |
| 词频(tf:Term Frequency) | ? |
| 逆文档率(idf:Inverse Document Frequency) | ? |
| 粗排 | ? |
| 精排 | ? |
本篇文章由简到繁入门搜索原理,并逐步揭开上面这些概念的面纱。本文结构如下:
搜索引擎ES的诞生
简易版搜索过程
索引过程
查询过程
进阶版搜索过程
索引过程
什么是文档(Doc)
什么是词条(Term)
什么是倒排索引(Inverted Index)
文档(Doc)分析
字符过滤器
分词器
分词过滤器
创建倒排索引
查询过程
关键字(Query)分析
字符过滤器
分词器
分词过滤器
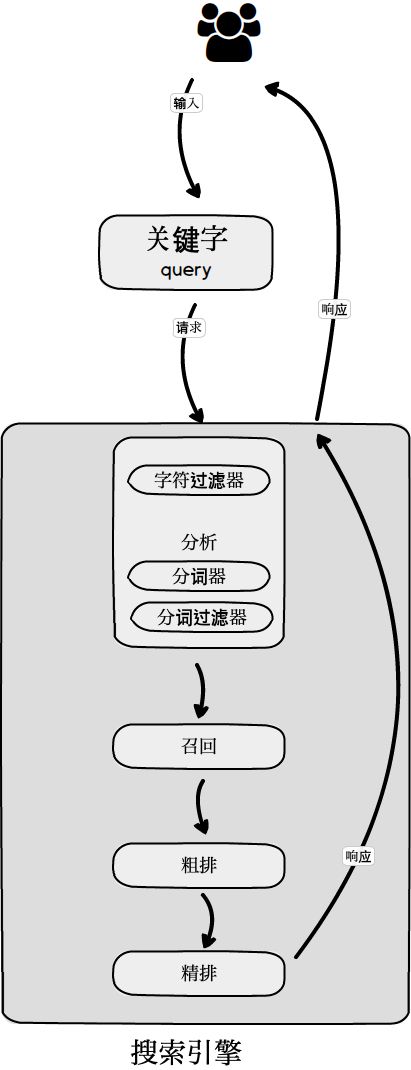
召回(Recall)
什么是召回(Recall)
排序
什么是词频(tf:Term Frequency)
什么是逆文档率(idf:Inverse Document Frequency)
粗排/精排
搜索过程总结
搜索引擎ES进阶
索引(名词)的基本结构
搜索引擎ES的逻辑结构
搜索引擎ES的诞生
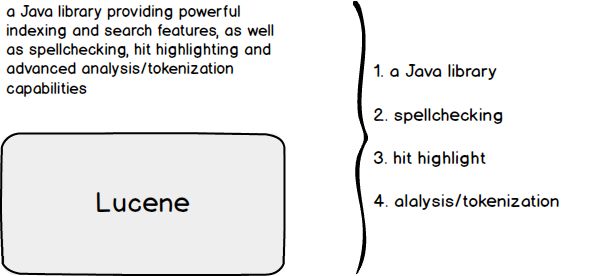
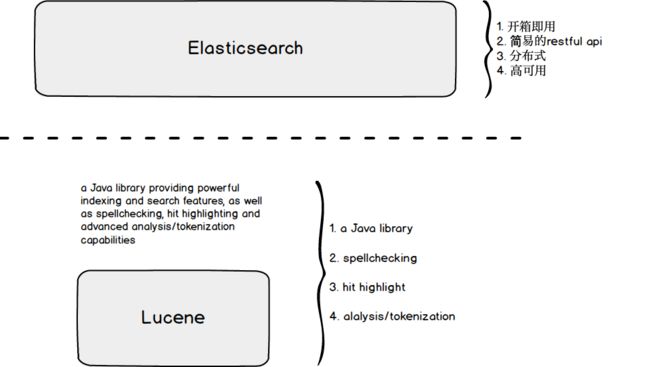
ES诞生于一个开源的JAVA库Lucene。通过Lucene官网的描述我们可以发现Lucene具备如下能力:
Lucene是一个JAVA库Lucene实现了拼写检查Lucene实现了命中字符高亮Lucene实现了分析、分词功能
Lucene不具备的能力:
分布式
高可用
开箱即用
等等
所以多年之前名叫Shay Banon的开发者,通过Lucene实现了一个高可用的开源分布式搜索引擎Elasticsearch。
常见的搜索功能都是基于「搜索引擎」实现的,接着我们来看看简易版搜索过程。
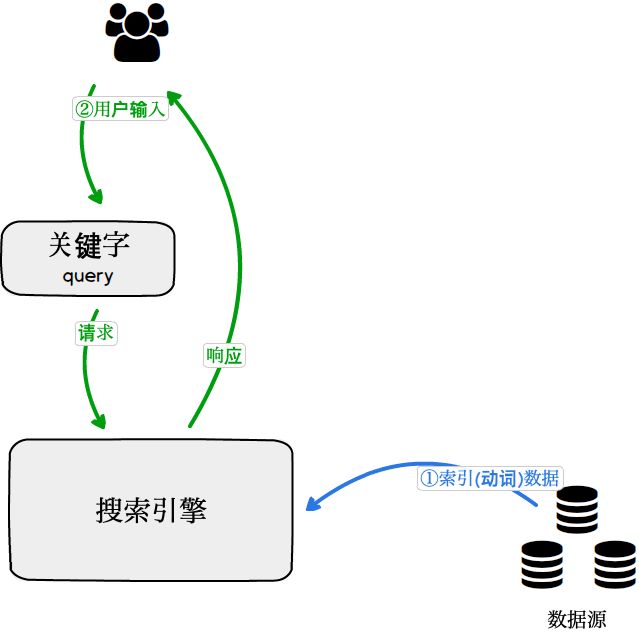
简易版搜索过程
简易版搜索过程如下:
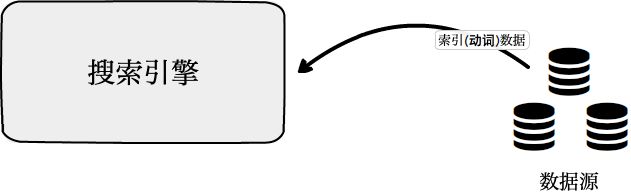
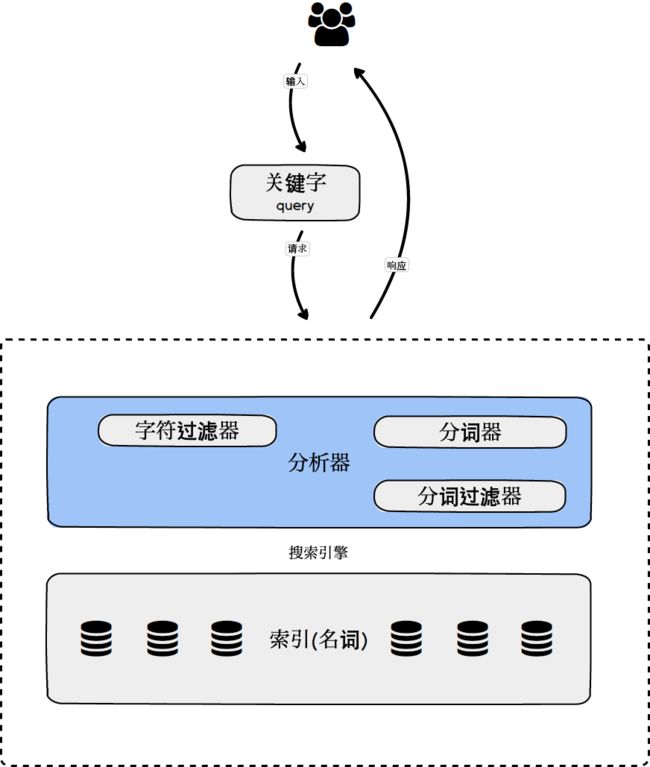
第①步:索引过程,需要被搜索的源数据被索引(动词)到搜索引擎中,并建立索引(名词)。
第②步:查询过程,用户输入关键字(Query),搜索引擎分析Query并返回查询结果。
p
进阶版搜索过程
索引过程
什么是文档(Doc)
举个栗子,比如《电商设计手册 | SkrShop》网页内容需要被搜索到,那这页网页的全部内容就称之为一个文档Doc。

文档Doc内容如下:
电商设计手册 | SkrShop 秒杀是电商的一种营销手段
| 搜索名词概念 | 描述 |
|---|---|
| 文档(doc) | 需要被搜索的文本内容,可以是某个商品详细信息、某个网页信息等等文本。 |
什么是词条(Term)
继续以上文的文档Doc为例。为了简化对词条(Term)的理解,把上述文档Doc的内容简化为一句话秒杀是电商的一种营销手段。
词条(Term)就是文档Doc经过分词处理得到的词条结果集合。比如秒杀是电商的一种营销手段被中文分词之后得到:
秒杀 / 是 / 电商 / 的 / 一种 / 营销 / 手段秒杀、是、电商、的、一种、营销、手段分别称之为词条(Term),该集合称之为Terms。
表格左右滑动查看
| 搜索名词概念 | 描述 |
|---|---|
| 词条(Term) | 被搜索的文本Doc被分词器拆解成N个标准的语句。 |
什么是倒排索引(Inverted Index)
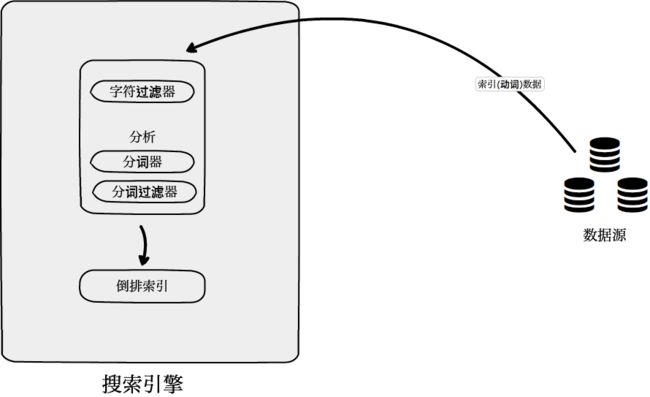
「倒排索引」是索引(动词)源数据时,创建的索引(名词)的具体实现。
我们以如下文档(Doc)为例,解释倒排索引:
表格左右滑动查看
| 文档ID | 文档内容(Doc) |
|---|---|
| 1 | 电商设计手册SkrShop |
| 2 | 秒杀是电商的一种营销手段 |
| 3 | 购物车是电商购买流程最重要的一步 |
分词器:文档(Doc)拆解为多个独立词条(Doc -> Terms)。
开源中文分词器:
IK Analyzer
jieba
等
以jieba分词器在线演示为例:https://app.gumble.pw/jiebademo/
表格左右滑动查看
| 文档ID | 文档内容(Doc) | 中文分词结果(Terms) |
|---|---|---|
| 1 | 电商设计手册SkrShop | 电商 / 设计 / 手册 / SkrShop |
| 2 | 秒杀是电商的一种营销手段 | 秒杀 / 是 / 电商 / 的 / 一种 / 营销 / 手段 |
| 3 | 购物车是电商购买流程最重要的一步 | 购物车 / 是 / 电商 / 购买 / 流程 / 最 / 重要 / 的 / 一步 |
每个词条对应的文档ID如下:
表格左右滑动查看
| 词条 | 文档IDs |
|---|---|
| 电商 | 1、2、3 |
| 设计 | 1 |
| 手册 | 1 |
| SkrShop | 1 |
| 秒杀 | 2 |
| 是 | 2、3 |
| 的 | 2、3 |
| 一种 | 2 |
| 营销 | 2 |
| 手段 | 2 |
| 购物车 | 3 |
| 购买 | 3 |
| 流程 | 3 |
| 最 | 3 |
| 重要 | 3 |
| 一步 | 3 |
以上就是建立倒排索引的基本过程。
完成倒排索引建立之后,模拟搜索过程,假设:
搜索
电商,能快速找到文档1、2、3搜索
营销,能快速找到文档2
(这个过程叫做「召回」)
以上就是「倒排索引」的概念。
表格左右滑动查看
| 搜索名词概念 | 描述 |
|---|---|
| 倒排索引(Inverted Index) | 索引(动词)源数据时,创建的索引(名词)的具体实现。 |
文档(Doc)分析
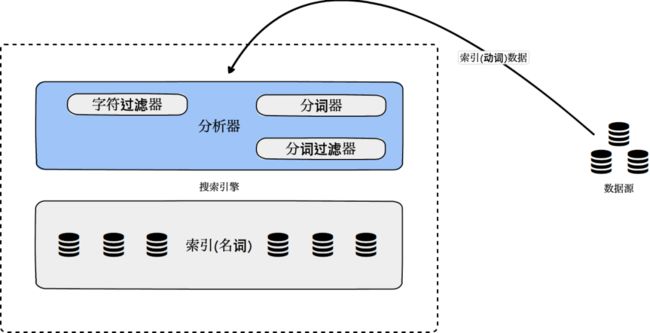
分析就是标准化文档(Doc)文本的过程,以及把文档(Doc)转换成标准化词条(Term)的过程。搜索引擎ES分析过程的实现依赖于分析器。
分析器基本组成:
字符过滤器
分词器
分词过滤器
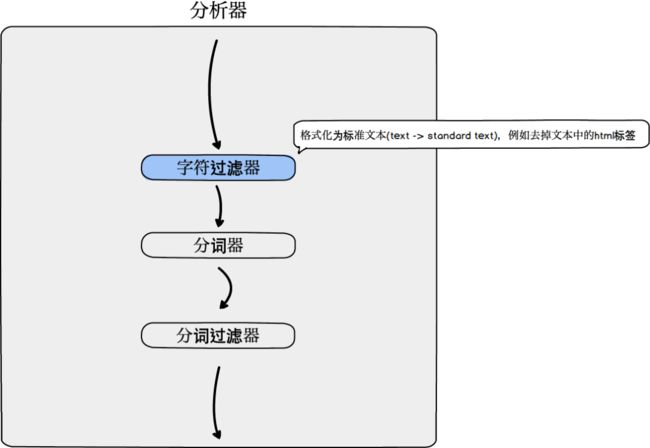
字符过滤器
一个分析器对应一个字符过滤器。
格式化为标准文本(text -> standard text),例如去掉文本中的html标签。
比如 电商设计手册SkrShop电商设计手册SkrShop
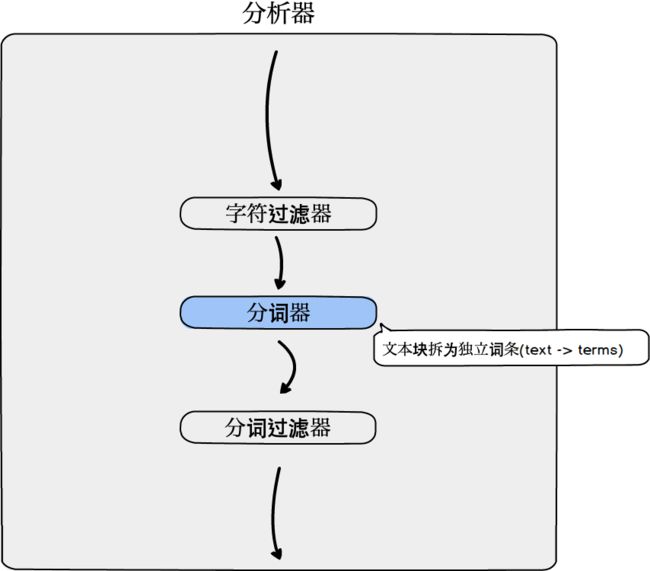
分词器
一个分析器对应一个分词器。
文档(Doc)拆解为多个独立词条(doc -> terms)的过程。举个例子:比如电商设计手册SkrShop--->电商 / 设计 / 手册 / SkrShop
这里还需要提到的是自定义词库:原始词库不具备的词汇,比如最近新产生的网络词汇。
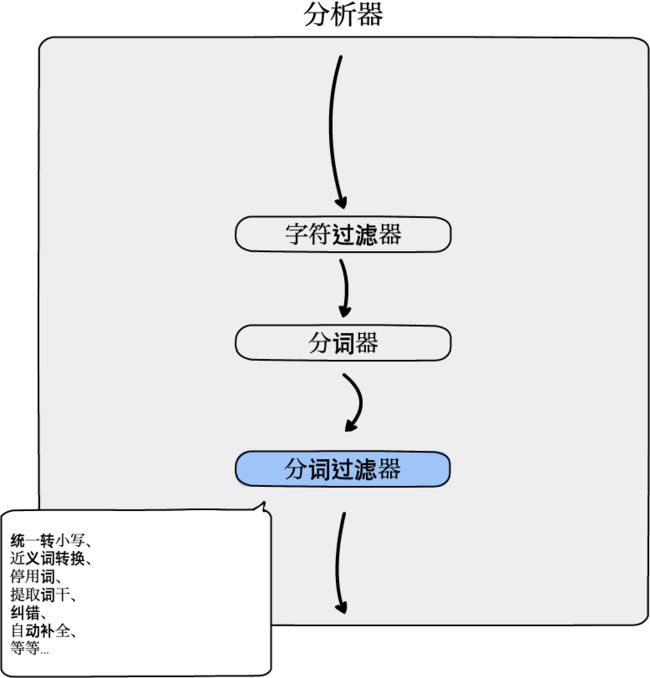
分词过滤器
一个分析器对应N个分词过滤器。
统一转小写
近义词转换
停用词
提取词干
纠错
自动补全
等等...
表格左右滑动查看
| 分词过滤器 | 示例 |
|---|---|
| 统一转小写 | 适用于英文等。比如统一把英文字母转换为小写,例Word -> word |
| 近义词转换 | 适用于各语言。例宽敞 -> 宽阔 |
| 停用词 | 适用于各语言。去除含义宽泛不具备代表性的词语和其他人工指定停用的词语,例的、是。中文停用词库:https://github.com/goto456/stopwords |
| 提取词干 | 适用于英文等。例words -> word |
| 纠错 | 适用于各语言。例宽肠 -> 宽敞 |
| 自动补全 | 适用于各语言。 |
索引过程总结
查询过程

表格左右滑动查看
| 搜索名词概念 | 描述 |
|---|---|
| 关键字(Query) | 发起搜索是用户输入的关键字 |
关键字(Query)分析
关键字(Query)同样需要经过分析器,且和文档索引过程是相同的分析器。
相同分析器:
相同字符过滤器
相同分词器
相同分词过滤器
分词器:
表格左右滑动查看
| 关键字(Query) | 中文分词结果(Terms) |
|---|---|
| 秒杀系统的设计 | 秒杀 / 系统 / 的 / 设计 |
| 词条(Terms) |
|---|
| 秒杀 |
| 系统 |
| 的 |
| 设计 |
分词过滤器:
此处以停用词分词过滤器为例讲解分词过滤器的过程,本文使用的停用词库示例:https://github.com/goto456/stopwords/blob/master/cn_stopwords.txt
得到去除了停用词的之后的词条(Terms)集合:
表格左右滑动查看
| 词条(Terms) |
|---|
| 秒杀 |
| 系统 |
| 设计 |
召回(Recall)
什么是召回(Recall)
使用上文的文档内容以及文档分词结果:
表格左右滑动查看
| 文档ID | 文档内容(Doc) | 中文分词结果(Terms) |
|---|---|---|
| 1 | 电商设计手册SkrShop | 电商 / 设计 / 手册 / SkrShop |
| 2 | 秒杀是电商的一种营销手段 | 秒杀 / 是 / 电商 / 的 / 一种 / 营销 / 手段 |
| 3 | 购物车是电商购买流程最重要的一步 | 购物车 / 是 / 电商 / 购买 / 流程 / 最 / 重要 / 的 / 一步 |
进一步使用分词过滤器过滤分词结果,以相同的停用词分词过滤器为例。本文使用的停用词库示例:https://github.com/goto456/stopwords/blob/master/cn_stopwords.txt
比如命中了停用词是:

经过停用词分词过滤器之后的结果:
表格左右滑动查看
| 文档ID | 文档内容(Doc) | 中文分词结果(Terms) |
|---|---|---|
| 1 | 电商设计手册SkrShop | 电商 / 设计 / 手册 / SkrShop |
| 2 | 秒杀是电商的一种营销手段 | 秒杀 / 电商 / 一种 / 营销 / 手段 |
| 3 | 购物车是电商购买流程最重要的一步 | 购物车 / 电商 / 购买 / 流程 / 重要 / 一步 |
进一步得到倒排索引结构:
表格左右滑动查看
| 词条 | 文档IDs |
|---|---|
| 电商 | 1、2、3 |
| 设计 | 1 |
| 手册 | 1 |
| SkrShop | 1 |
| 秒杀 | 2 |
| 一种 | 2 |
| 营销 | 2 |
| 手段 | 2 |
| 购物车 | 3 |
| 购买 | 3 |
| 流程 | 3 |
| 重要 | 3 |
| 一步 | 3 |
接着模拟搜索过程,假设用户搜索秒杀系统的设计:
表格左右滑动查看
| 关键字(Query) | 中文分词结果(Terms) |
|---|---|
| 秒杀系统的设计 | 秒杀 / 系统 / 的 / 设计 |
| 词条(Terms) |
|---|
| 秒杀 |
| 系统 |
| 的 |
| 设计 |
分词过滤器,使用同上过程的停用词分词过滤器为例,得到去除了停用词的之后的词条(Terms)集合,称之为关键字(Query)的词条集合:
表格左右滑动查看
| 词条(Terms) |
|---|
| 秒杀 |
| 系统 |
| 设计 |
关键字(Query)的词条
秒杀,通过上述倒排索引可以很容易找到文档2关键字(Query)的词条
系统,通过上述倒排索引没有找到任何文档关键字(Query)的词条
设计,通过上述倒排索引可以很容易找到文档1
这样用户搜索秒杀系统的设计就找到了如下文档:
文档2:秒杀是电商的一种营销手段文档1:电商设计手册SkrShop
以上过程就是召回。
表格左右滑动查看
| 搜索名词概念 | 描述 |
|---|---|
| 召回(Recall) | 搜索引擎利用倒排索引,通过词条获取相关文档的过程。 |
上述召回过程,用户通过搜索秒杀系统的设计找到了文档1、2。
补充:以上基于倒排索引的文本召回方式。除此之外还有基于相同类目、其他相似属性的召回方式,以及基于深度学习的向量召回。接着问题来了:
文档1、2,谁在前,谁在后的顺序怎么决定呢?
接着下文来讲搜索引擎排序的实现。
排序
引入上面的问题:
文档1、2,谁在前,谁在后的顺序怎么决定呢?
答:文档的相关性决定的,搜索引擎会给文档的相关性进行打分score。通常决定这个分数score主要是两个指标:
文档率:tf(Term Frequency)
逆文档率:idf(Inverse Document Frequency)
可以简单理解为相关性 score = 文档率 * 逆文档率,相关性score的值越高排序越靠前,接着,我们分别看看相关概念的含义。
什么是词频(tf:Term Frequency)
还是使用上面的文档:
表格左右滑动查看
| 文档ID | 文档内容(Doc) | 中文分词结果(Terms) |
|---|---|---|
| 1 | 电商设计手册SkrShop | 电商 / 设计 / 手册 / SkrShop |
| 2 | 秒杀是电商的一种营销手段 | 秒杀 / 电商 / 一种 / 营销 / 手段 |
| 3 | 购物车是电商购买流程最重要的一步 | 购物车 / 电商 / 购买 / 流程 / 重要 / 一步 |
这里我们以词条:电商/秒杀为例。
词频的简单算法:词频 = 词条在单个文档出现的次数/文档总词条数,词频的值越大越相关,反之越不相关。
比如,秒杀一词在文档1中出现的频率,以单个文档的全部词条为维度,我们简单的到了秒杀一词在各文档的词频:
表格左右滑动查看
| 文档ID | 文档内容(Doc) | 中文分词结果(Terms) | 词条在单个文档出现的次数 | 词频(秒杀) |
|---|---|---|---|---|
| 1 | 电商设计手册SkrShop | 电商 / 设计 / 手册 / SkrShop | 0 | 0/4=0 |
| 2 | 秒杀是电商的一种营销手段 | 秒杀 / 电商 / 一种 / 营销 / 手段 | 1 | 1/5=0.2 |
| 3 | 购物车是电商购买流程最重要的一步 | 购物车 / 电商 / 购买 / 流程 / 重要 / 一步 | 0 | 0/6=0 |
同理,我们简单的到了电商一词在各文档的词频:
表格左右滑动查看
| 文档ID | 文档内容(Doc) | 中文分词结果(Terms) | 词条在单个文档出现的次数 | 词频(电商) |
|---|---|---|---|---|
| 1 | 电商设计手册SkrShop | 电商 / 设计 / 手册 / SkrShop | 1 | 1/4=0.25 |
| 2 | 秒杀是电商的一种营销手段 | 秒杀 / 电商 / 一种 / 营销 / 手段 | 1 | 1/5=0.2 |
| 3 | 购物车是电商购买流程最重要的一步 | 购物车 / 电商 / 购买 / 流程 / 重要 / 一步 | 1 | 1/6=0.167 |
| 搜索名词概念 | 描述 |
|---|---|
| 词频(tf:Term Frequency) | 词条在单个文档出现的次数/文档总词条数 |
什么是逆文档率(idf:Inverse Document Frequency)
对于单个文档而言,词频的值越大越相关。
思考个问题,如果某个词条在所有文档都出现,相关性越好还是越不好?
答:不好,对吧。这个就是文档率:文档率 = 包含某个词条的文档数 / 所有文档数,文档率值越大越不相关,反之相关。
因为词频的值越大越相关,反之越不相关。为了保证和词频的逻辑一致,以及最终相关得分越高越相关,调整了文档率的算法,调换了分子分母:所有文档数 / (包含某个词条的文档数 + 1)加1保证分母不为零,这个就是逆文档率。
逆文档率 = 所有文档数 / (包含某个词条的文档数 + 1)。
但是呢,因为文档数往往特别大,上面的到的逆文档率的值会巨大无比,所以调整下公式,引入对数,降低值的大小,且让值变得平滑:
逆文档率 = log(所有文档数 / (包含某个词条的文档数 + 1))
| 词条(Term) | 逆文档率 |
|---|---|
| 电商 | log(3/(3+1)) |
| 秒杀 | log(3/(1+1)) |
最终就计算出每个文档分别对应每个Query词条的相关性score(tf/idf):相关性score = 文档率 * 逆文档率。
粗排/精排
上面利用tf/idf分数(相关性score = 文档率 * 逆文档率)排序的结果只是对召回文档的初步排序,称之为粗排。
得到粗排的结果后,通常还会把文档按照实际业务的要求进行更精确的排序,比如通过人工干预增加一些文档的权重,使之排序更靠前,这个过程就是精排。
搜索过程总结
1. 索引过程:文档(Doc) -> 分析 -> 倒排索引。
2. 查询过程:关键字(Query) -> 分析 -> 召回 -> 排序。
搜索引擎ES进阶
索引(名词)的基本结构
索引index
映射mapping:管理索引的属性,比如使用的分析器等等
文档doc:需要被搜索的具体文档
类型type:区分不同的文档数据结构类型
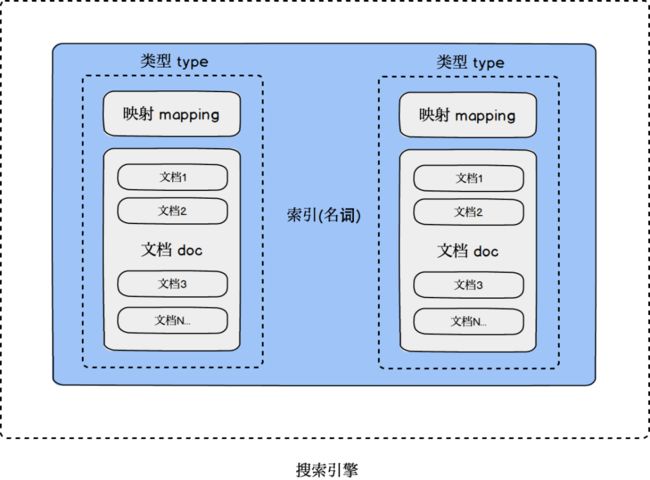
进一步完善搜索过程:加入更详细的索引(名词)结构。
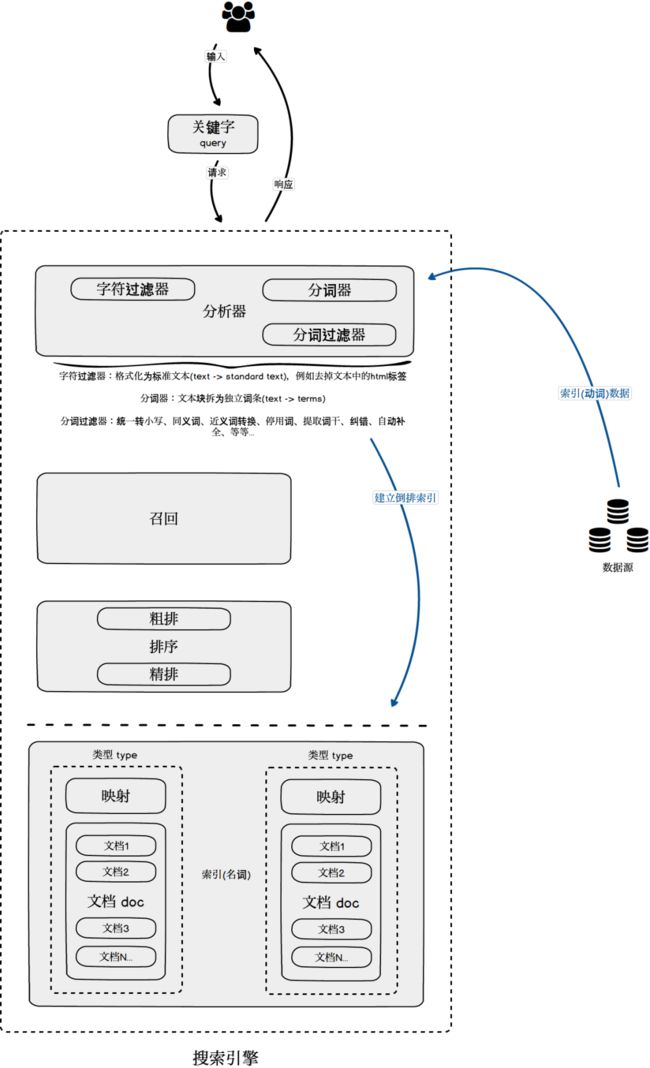
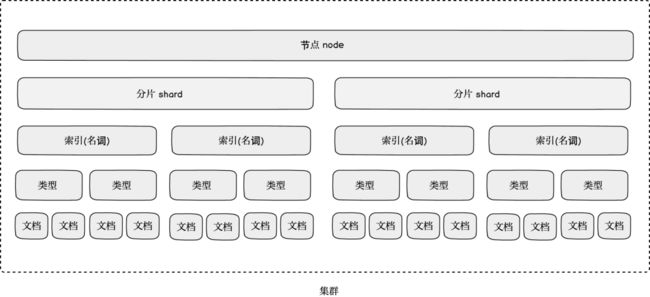
搜索引擎ES的逻辑结构
[Skr Shop] 项目地址
长按进入:https://github.com/skr-shop/manuals

Skr Shop系列更多文章
[Skr-Shop]电商搜索业务介绍
[Skr-Shop]一篇文章搞清电商订单结算页面设计?
[Skr-Shop]做电商还搞不清一元秒杀、常规秒杀、限时购?
[Skr-Shop]什么,秒杀系统也有这么多种!
[Skr-Shop]你想知道的优惠券业务,SkrShop告诉你
[Skr-Shop]通用抽奖系统之系统设计
[Skr-Shop]通用抽奖系统之需求分析
[Skr-Shop]营销体系开篇
[Skr-Shop]购物车设计之架构设计
[Skr-Shop]购物车设计之需求分析
[Skr-Shop]coder,你会设计交易系统吗(实干篇)?
[Skr-Shop]coder,你会设计交易系统吗(概念篇)?
[Skr-Shop]电商设计手册之基础商品信息
[Skr-Shop]支付开发,不得不了解的国内、国际第三方支付流程
[Skr-Shop]电商设计手册之用户体系

![]()