X-GEAR:Multilingual Generative Language Models for Zero-Shot Cross-Lingual Event Argument Extraction
Multilingual Generative Language Models for Zero-Shot Cross-Lingual Event Argument Extraction

论文:https://arxiv.org/pdf/2203.08308.pdf
代码:https://github.com/PlusLabNLP/X-Gear
期刊/会议:ACL 2022
摘要
我们提出了一项利用多语言预训练生成语言模型进行零样本跨语言事件论元抽取(EAE)的研究。通过将EAE定义为语言生成任务,我们的方法有效地编码事件结构并捕获论元之间的依赖关系。我们设计了与语言无关的模板(language-agnostic templates)来表示与任何语言兼容的事件论元结构,从而促进了跨语言迁移。我们提出的模型对预训练的多语言生成语言模型进行微调,以生成从输入段落中抽取的论元填充语言无关模板的句子。该模型在源语言上进行训练,然后直接应用于目标语言进行事件论元抽取。实验表明,该模型在零样本跨语言EAE方面优于现有的最先进模型。为了更好地理解使用生成语言模型进行零样本跨语言迁移EAE的优势和当前的局限性,本文进行了全面的研究和误差分析。
1、简介
事件论元抽取(EAE)旨在识别作为事件论元的实体,并识别它们对应的角色。如图1中的英文示例所示,给定Conflict:Attack事件的触发词“destroyed”,事件论元抽取器预计将“commando”、“Iraq”和“post”识别为事件论元,并分别预测它们的角色为“Attacker”、“Place”和“Target”。

零样本跨语言EAE已经引起了相当大的关注,因为它消除了在低资源语言中构建EAE模型时对标记数据的需求(Subburathinam et al, 2019; Ahmad et al, 2021; Nguyen and Nguyen,2021)。在此设置中,模型使用源语言的示例进行训练,并直接在目标语言的实例上进行测试。
最近,基于生成的模型在单语言结构化预测任务上表现出了强大的性能(Yan et al, 2021; Huang et al, 2021b; Paolini et al, 2021),包括EAE(Li et al, 2021; Hsu et al, 2021)。这些工作对预训练的生成语言模型进行微调,以根据设计的模板生成输出,从而可以轻松地从输出中解码最终的预测。与传统的基于分类的模型相比(Wang et al, 2019; Wadden et al, 2019; Lin et al, 2020),它们更好地捕获实体之间的结构和依赖关系,因为模板提供了额外的声明性信息。
尽管取得了成功,但以往作品中的模板设计是语言依赖的,这使得它很难扩展到零样本跨语言迁移设置(Subburathinam et al, 2019;Ahmad et al, 2021)。简单地将这种在源语言上训练的模型应用于目标语言通常会产生 code-switching 输出,导致零样本跨语言的性能较差。如何为零样本跨语言结构化预测问题设计基于语言认知生成的模型仍然是一个悬而未决的问题。
在这项工作中,我们提出了一项研究,利用多语言预训练生成模型进行零样本跨语言事件论元抽取,并提出了X-GEAR(跨语言生成事件论元抽取器)。给定一个输入段落和一个精心设计的提示,提示包含一个事件触发词和相应的语言无关模板,训练X-GEAR生成一个句子,用论元填充语言无关模板。X-GEAR继承了基于生成的模型的优点,它比基于分类的模型更好地捕获事件结构和实体之间的依赖关系。此外,预训练的解码器固有地将命名实体识别为事件论元的候选,不需要额外的命名实体识别模块。与语言无关的模板可以防止模型过度拟合源语言的词汇表,并促进跨语言迁移。
我们在两个多语言EAE数据集上进行了实验:ACE-2005 (Doddington et al, 2004)和ERE (Song et al, 2015)。结果表明,X-GEAR的性能优于目前最先进的零样本跨语言EAE模型。我们进一步进行了消融研究,以证明我们的设计是正确的,并提出了全面的错误分析,以了解使用多语言基于生成的模型进行零样本跨语言迁移的局限性。
2、相关工作
零样本跨语言结构预测。零样本跨语言学习是一个新兴的研究主题,因为它消除了低资源语言训练模型对标记数据的需求(Ruder et al, 2021; Huang et al, 2021a)。研究了五种不同的结构化预测任务,包括命名实体识别(Pan et al, 2017; Huang et al, 2019; Hu et al, 2020),依赖解析(Ahmad et al, 2019b,a; Menget al, 2019),关系抽取(Zou et al, 2018; Ni and Florian, 2019),以及事件论元抽取(Subburathinam et al, 2019; Nguyen and Nguyen, 2021; Fincke et al, 2021)。其中大多数是基于分类的模型,在预先训练的多语言掩码语言模型之上构建分类器。为了进一步处理语言之间的差异,其中一些需要额外的信息,如双语词典(Liu et al, 2019; Ni and Florian, 2019),翻译对(Zou et al, 2018)和依赖解析树(Subburathinam et al, 2019; Ahmad et al, 2021; Nguyen and Nguyen, 2021)。然而,正如之前的文献所指出的(Li et al, 2021; Hsu et al, 2021),与基于生成的模型相比,基于分类的模型在建模实体之间的依赖关系方面不太强大。
基于生成结构预测。一些工作已经证明了基于代的模型在单语言结构化预测任务上的巨大成功,包括命名实体识别(Yan et al, 2021),关系抽取(Huang et al, 2021b;Paolini et al,2021)和事件抽取(Du et al,2021;Li et al, 2021;Hsu et al, 2021;Lu et al, 2021)。如第1节所述,其设计的生成目标是语言相关的。因此,直接将他们的方法应用于零样本跨语言设置将导致不太理想的性能。
提示的方法。最近,人们越来越有兴趣在预先训练的语言模型上加入提示,以指导模型的行为或引出知识(Peng et al, 2019; Sheng et al, 2020; Shin et al, 2020; Schick and Schütze, 2021; Qin and Eisner, 2021; Scao and Rush, 2021)。根据(Liu et al, 2021)中的分类法,可以根据语言模型的参数是否调优以及是否引入了可训练的提示来对这些方法进行分类。我们的方法属于修复提示和调整语言模型参数的类别。尽管对提示方法的研究蓬勃发展,但对多语言任务的关注有限(Winata et al, 2021)。
3、零样本跨语言事件论元抽取
我们专注于零样本跨语言EAE。给定一个输入通道和一个事件触发词,EAE模型识别论元和它们对应的角色。更具体地说,如图2中的训练示例所示,给定一个输入段落 x x x和事件触发器 t t t (killed)属于事件类型e (Life:Die)的, EAE模型预测一个论元列表 a = [ a 1 , a 2 , … , a l ] a = [a_1, a_2,\ldots, a_l] a=[a1,a2,…,al] (coalition, civilians, woman, missile, houses)及其对应的角色 r = [ r 1 , r 2 , … , r l ] r = [r_1, r_2,\ldots, r_l] r=[r1,r2,…,rl] (Agent, Victim, Victim, Instrument, Place)。在零样本跨语言设置中,训练集 X t r a i n = { ( x i , t i , e i , a i , r i ) } i = 1 N X_{train} = \{(x_i, t_i, e_i, a_i, r_i)\}^{N}_{i=1} Xtrain={(xi,ti,ei,ai,ri)}i=1N属于源语言,而测试集 X t e s t = { ( x i , t i , e i , a i , r i ) } i = 1 M X_{test} = \{(x_i, t_i, e_i, a_i, r_i)\}^{M}_{i=1} Xtest={(xi,ti,ei,ai,ri)}i=1M属于目标语言。

与单语言EAE类似,零样本跨语言EAE模型被期望能够捕获论元之间的依赖关系并进行结构化预测。然而,与单语言EAE不同的是,零样本跨语言EAE模型需要处理语言之间的差异(例如,语法,词序),并学习将知识从源语言转移到目标语言。
4、X-GEAR模型
我们将零样本跨语言EAE作为一个语言生成任务,并提出X-GEAR,一个跨语言生成事件论元抽取器,如图2所示。这种表述提出了两个挑战:(1)在训练和测试过程中,输入语言可能会发生变化;(2)生成的输出字符串需要很容易地解析成最终的预测。因此,输出字符串必须相应地反映输入语言的变化,同时保持良好的结构。
我们通过设计与语言无关的模板来解决这些挑战。具体来说,给定一个输入段落 x x x和一个设计的提示,其中包含给定的触发词 t t t、事件类型 e e e和一个语言无关的模板,X-GEAR学习生成一个输出字符串,用从输入段落中抽取的信息填充语言无关的模板。语言无关的模板是以结构化的方式设计的,因此从生成的输出中解析最终论元预测 a a a和角色预测 r r r是非常简单的。此外,由于模板与语言无关,因此便于跨语言迁移。
X-GEAR微调多语言预训练生成模型,如mBART-50 (Tang et al, 2020)或mT5 (Xue et al, 2021),并使用复制机制增强它们,以更好地适应输入语言的变化。我们将其详细信息如下所示,包括语言无关的模板、目标输出字符串、输入格式和训练细节。
4.1 语言无关的模板
我们为每个事件类型 e e e创建一个与语言无关的模板 T e T_e Te,在其中列出所有可能关联的角色,并为该事件类型 e e e形成一个唯一的html标记样式模板。例如,在图2中,Life:Die事件与四个角色关联:Agent, Victim, Instrument, and Place。因此,Life:Die事件的模板被设计为:
为了便于理解,我们使用英语单词来表示模板。然而,这些token([None], 被编码为特殊的token,预训练的模型从未见过,因此需要从头开始学习它们的表示。由于这些特殊的符号与任何语言都没有关联,也没有预先训练过,所以它们被认为是语言无关的。
4.2 目标输出格式
X-GEAR学习生成遵循语言无关模板形式的目标输出字符串。为了组成用于训练的目标输出字符串,给定一个实例 ( x , t , e , a , r ) (x, t, e, a, r) (x,t,e,a,r),我们首先为事件类型 e e e挑选出语言无关的模板 T e T_e Te,然后根据它们的角色 r r r将 T e T_e Te中的所有“[None]”替换为 a a a中相应的论元。如果一个角色有多个论元,我们用一个特殊的标记“[and]”连接它们。例如,图2中的训练示例为Victim角色提供了两个论元(civilian和woman),输出字符串的相应部分为
如果一个角色没有对应的论元,则在 T e T_e Te中保留“[None]”。通过应用此规则,图2中训练示例的完整输出字符串变成
由于输出字符串是html标记样式的,我们可以通过一个简单的基于规则的算法从生成的输出字符串中轻松解码论元和角色预测。
4.3 输入格式
如前所述,零样本跨语言EAE生成公式的关键是引导模型以所需的格式生成输出字符串。为了促进这种行为,我们将输入段落 x x x和提示符供给X_GEAR,如图2所示。提示包含所有触发词 t t t和语言无关模板 T e T_e Te。注意,我们没有显式地在提示符中包含事件类型 e e e,因为模板 T e T_e Te隐式地包含此信息。在6.1节中,我们将展示显式地在提示符中添加事件类型 e e e的实验,并讨论它对跨语言迁移的影响。
4.4 训练
为了使X-GEAR能够生成不同语言的句子,我们将多语言预训练的生成模型作为我们的基础模型,该模型模拟了生成一个新token的条件概率,给定先前生成的标记和编码器 c c c的输入上下文,
P ( x ∣ c ) = ∏ i P g e n ( x i ∣ x < i , c ) P(x|c)=\prod_{i} P_{gen}(x_i|x_{
x i x_i xi是解码器第 i i i步的输出。
复制机制。虽然多语言预训练生成模型可以生成多种语言的序列,但仅依赖它们可能会导致产生错误的论元(Li et al, 2021)。由于目标输出字符串中的大多数token出现在输入序列中,我们用复制机制增强了多语言预训练生成模型,以帮助X-GEAR更好地适应跨语言场景。具体来说,我们遵循See et al(2017)的方法,将生成token t t t的条件概率确定为由多语言预训练生成模型 P g e n P_{gen} Pgen和副本分布 P c o p y P_{copy} Pcopy计算的词汇分布的加权和
P X G E A R ( x i = t ∣ X < i , c ) = w c o p y ⋅ P c o p y ( t ) + ( 1 − w c o p y ) ⋅ P g e n ( x i = t ∣ x < i , c ) P_{X_{GEAR}}(x_i=t|X_{
其中 w c o p y ∈ [ 0 , 1 ] w_{copy}∈[0,1] wcopy∈[0,1]是在时间步 i i i将解码器隐藏状态传递给线性层计算出的复制概率。对于 P c o p y P_{copy} Pcopy,它是指最后一个解码器层计算的(在时间步骤 i i i)的交叉注意加权的输入token的概率。然后我们的模型以以下损失端到端进行训练:
L = − log ∑ i P X G E A R ( x i ∣ x < i , c ) L=-\log \sum_{i} P_{X_GEAR}(x_i|x_{
5、实验
数据集:ACE-2005,ERE。
基线模型:OneIE,CL-GCN,GATE,TANL。
实验结果:
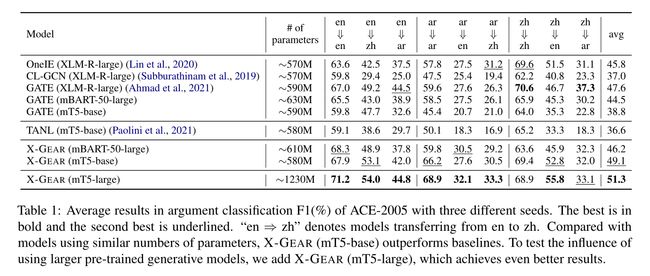

表1和表2展示了各种基线模型在两种数据集上的实验效果。具有以下结论:
- 和先前的生成模型对比:TANL模型采用语言依赖的模板,很容易生成code-switching输出,这种模板预训练语言模型已经看过,导致了差的性能。X-GEAR语言无关的模板解决了这一现状。
- 和分类模型对比:OneIE、CL-GCN和GATE,三种模型需要格外管道式的命名实体识别模块,后面两者还需要额外的依赖解析标注去对其不同语言的表征。X-GEAR不需要额外的模块和标注。
- 和不同的预训练生成模型的对比:mT5-base和mBERT-50-large参数量基本相同,但效果更佳,原因可能在于使用了特殊的token带来了不同。mBERT-50使用begin-of-sequence(BOS) token,当使用时必须先制定BOS token作为开始。而mT5-base则没有这种限制。
- 大的预训练语言模型效果可能更好。
6、结论
我们提出了第一个基于生成的的零样本跨语言事件论元抽取模型。为了克服语言之间的差异,我们设计了与语言无关的模板,并提出了X-GEAR,它可以很好地捕获输出依赖关系,并且可以在没有额外的命名实体抽取模块的情况下使用。我们的实验结果表明,X-GEAR优于目前最先进的技术,这证明了使用语言生成框架解决零样本跨语言结构化预测任务的潜力。