爬虫练习题(一)
- 博主链接:张立梵的爬虫开端
- 个人介绍:小编大一视传在读,目前即将大二
- 欢迎大家对文章
关注、点赞、收藏
最近小伙伴问我有什么刷题网站推荐,我在这里推荐一下牛客网,这里面包含各种题库,全都是免费的题库,可以全方面提升你的数据操纵逻辑,提升编程实战技巧,赶快来一起刷题吧牛客网笔试题库|面试经验
Don't just follow the path .Make your own trail .
不要只是沿着路走,走你自己的路。
这次发稿具有极强的纪念意义,生日当天发稿,开启了我网络笔记的生涯,以及加深了对爬虫的无限热爱,希望大家能够给予我支持!!!第一次发稿还请多多支持!!!以后精彩不断哦。
10.(选做题1)目标网站https://www.sogou.com/
要求:
1.用户输入要搜索的内容,起始页和终止页
2.根据用户输入的内容爬取相关页面的源码
3.把获取下来的数据保存到本地
import requests
word = input("请输入搜索内容")
start = int(input("请输入起始页"))
end = int(input("请输入结束页"))
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.127 Safari/537.36 Edg/100.0.1185.44'
}
for n in range(start, end + 1):
url = f'https://www.sogou.com/web?query={word}&page={n}'
# print(url)
response = requests.get(url, headers=headers)
with open(f'{word}的第{n}页。html', "w", encoding="utf-8")as file:
file.write(response.content.decode("utf-8"))一、分析网页
1.先录入网址
python - 搜狗搜索 (sogou.com) https://www.sogou.com/web?query=python&_ast=1650447467&_asf=www.sogou.com&w=01029901&p=40040100&dp=1&cid=&s_from=result_up&sut=7606&sst0=1650447682406&lkt=0%2C0%2C0&sugsuv=1650427656976942&sugtime=1650447682406 2.分别搜索 “Python”,“中国”并进行网址对比。
https://www.sogou.com/web?query=python&_ast=1650447467&_asf=www.sogou.com&w=01029901&p=40040100&dp=1&cid=&s_from=result_up&sut=7606&sst0=1650447682406&lkt=0%2C0%2C0&sugsuv=1650427656976942&sugtime=1650447682406 2.分别搜索 “Python”,“中国”并进行网址对比。
中国 - 搜狗搜索 (sogou.com)https://www.sogou.com/web?query=%E4%B8%AD%E5%9B%BD&_ast=1650446881&_asf=www.sogou.com&w=01029901&p=40040100&dp=1&cid=&s_from=result_up&sut=9319&sst0=1650447465594&lkt=0%2C0%2C0&sugsuv=1650427656976942&sugtime=1650447465594
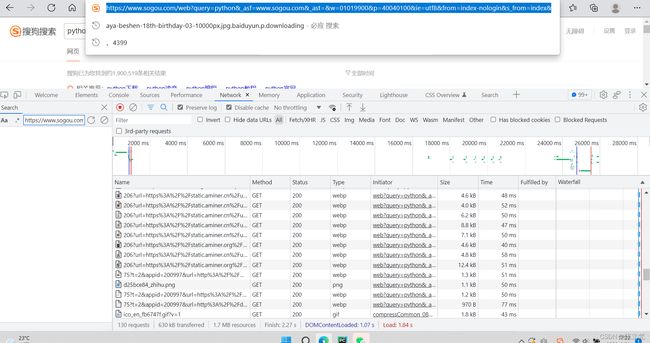
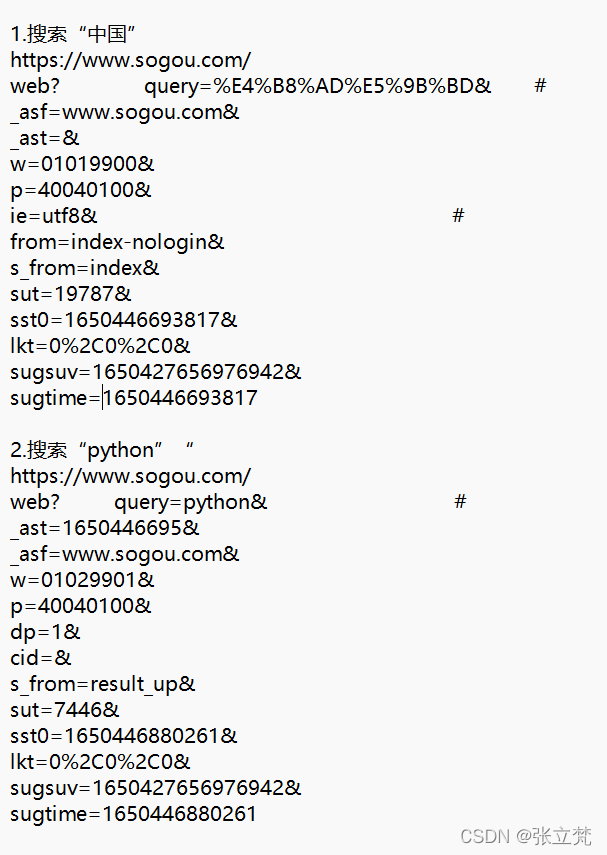
3.把每个参数以"&"符分割开来
结论:(1)参数query是搜索对象,中文字符会进行转义(转义后编码不用记忆)
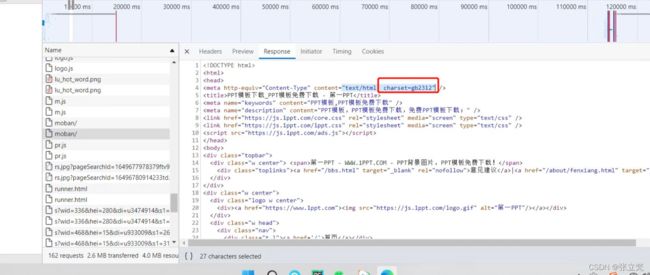
(2)参数ie是转义的编码类型,以"utf-8"为例,该参数可以在Network- Payload-ie=utf-8,有些包也可以在Network-Response-charset='utf-8',如图:
4.但是有这俩个参数还不能满足试题的翻页爬取需求,所以我们要手动翻页再进行检查 
https://www.sogou.com/web?query=python&page=2&ie=utf85.终于到了最关键的时刻了!我们找到了规律,以及重要参数的含义,就可以构建通用的 URL了,如图:
url = f'https://www.sogou.com/web?query={word}&page={n}'
# 用变量把可变参数赋值,这样就构建好了一个新的URL
二、找参数
https://www.sogou.com/web?query=Python&_asf=www.sogou.com&_ast=&w=01019900&p=40040100&ie=utf8&from=index-nologin&s_from=index&sut=12736&sst0=1650428312860&lkt=0%2C0%2C0&sugsuv=1650427656976942&sugtime=1650428312860
https://www.sogou.com/web?query=java&_ast=1650428313&_asf=www.sogou.com&w=01029901&p=40040100&dp=1&cid=&s_from=result_up&sut=10734&sst0=1650428363389&lkt=0%2C0%2C0&sugsuv=1650427656976942&sugtime=1650428363389
https://www.sogou.com/web?query=C%E8%AF%AD%E8%A8%80&_ast=1650428364&_asf=www.sogou.com&w=01029901&p=40040100&dp=1&cid=&s_from=result_up&sut=11662&sst0=1650428406805&lkt=0%2C0%2C0&sugsuv=1650427656976942&sugtime=1650428406805
https://www.sogou.com/web?
https://www.sogou.com/web?query=Python&
https://www.sogou.com/web?query=Python&page=2&ie=utf8
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.127 Safari/537.36 Edg/100.0.1185.44'
'cookie' = "IPLOC=CN3600; SUID=191166B6364A910A00000000625F8708; SUV=1650427656976942; browerV=3; osV=1; ABTEST=0|1650428297|v17; SNUID=636A1DCD7B7EA775332A80CB7B347D43; sst0=663; ld=llllllllll2AgcuYlllllpJK6jclllllHuYSpyllllDlllllVllll5@@@@@@@@@@; LSTMV=229,37; LCLKINT=1424"
'URl' = "https://www.sogou.com/web?query=Python&_ast=1650429998&_asf=www.sogou.com&w=01029901&cid=&s_from=result_up&sut=5547&sst0=1650430005573&lkt=0,0,0&sugsuv=1650427656976942&sugtime=1650430005573"
url="https://www.sogou.com/web?query={}&page={}:# UA要以字典形式被headers接收
1.headers的错误:
" ":" ",
# 构建字典的格式,','千万千万别忘了
# headers是关键字不能写错了,写错的话就会有如下报错
import requests
url = "https://www.bxwxorg.com/"
hearders = {
'cookie':'Hm_lvt_46329db612a10d9ae3a668a40c152e0e=1650361322; mc_user={"id":"20812","name":"20220415","avatar":"0","pass":"2a5552bf13f8fa04f5ea26d15699233e","time":1650363349}; Hm_lpvt_46329db612a10d9ae3a668a40c152e0e=1650363378',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.127 Safari/537.36 Edg/100.0.1185.44'
}
response = requests.get(url, hearders=hearders)
print(response.content.decode("UTF-8"))
Traceback (most recent call last):
File "D:/pythonproject/第二次作业.py", line 141, in
response = requests.get(url, hearders=hearders)
File "D:\python37\lib\site-packages\requests\api.py", line 75, in get
return request('get', url, params=params, **kwargs)
File "D:\python37\lib\site-packages\requests\api.py", line 61, in request
return session.request(method=method, url=url, **kwargs)
TypeError: request() got an unexpected keyword argument 'hearders'
# 原因:三个hearders写的一致,但是headers是关键字,所以报类型错误
# 但是写成heades会有另一种报错形式
import requests
word = input("请输入搜索内容")
start = int(input("请输入起始页"))
end = int(input("请输入结束页"))
heades = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.127 Safari/537.36 Edg/100.0.1185.44'
}
for n in range(start, end + 1):
url = f'https://www.sogou.com/web?query={word}&page={n}'
# print(url)
response = requests.get(url, headers=headers)
with open(f'{word}的第{n}页。html', "w", encoding="utf-8")as file:
file.write(response.content.decode("utf-8"))
Traceback (most recent call last):
File "D:/pythonproject/第二次作业.py", line 117, in
response = requests.get(url, headers=headers)
NameError: name 'headers' is not defined
# 原因:三个hearders写的不一致,所以报名称错误
# 正确写法是,最好不要写错!
import requests
url = "https://www.bxwxorg.com/"
headers = {
'cookie':'Hm_lvt_46329db612a10d9ae3a668a40c152e0e=1650361322; mc_user={"id":"20812","name":"20220415","avatar":"0","pass":"2a5552bf13f8fa04f5ea26d15699233e","time":1650363349}; Hm_lpvt_46329db612a10d9ae3a668a40c152e0e=1650363378',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.127 Safari/537.36 Edg/100.0.1185.44'
}
response = requests.get(url, headers=headers)
print(response.content.decode("UTF-8"))
三、循环
for n in range(start, end + 1):# 为什么是'end+1'呢:因为range函数的范围区间是左闭右开的所以真实的end值取不到,在后面加1就可以取到前一个真实值了
因为是翻页爬取,需要用到每一页的URL,所以要把构建的URL调入循环中
四、requests的基本介绍:(江湖人称 "urllib3" )
1.安装:Win + R --> cmd -->输入pip install requests
# 下载后如果不能调用是因为:模块安装在Python自带的环境中,自己用的虚拟环境没有这 个库,要指定环境
# 指定环境 : 终端输入where python找到安装路径 --> File --> setting --> project --> project interpreter --> 找到设置图标齿轮 --> Add --> system interpreter --> ... --> (where python中的路径) --> OK --> Apply应用 --> OK
2.爬虫的请求模块urllib.request模块 (urllib3)
(1)常用方法:
urllib.request.urlopen("网址")
作用:向网站发起一次请求,并获取相应
字节流 = response.read().decode('utf-8')
urllib.request request("网址", headers="字典")
# 因为urlopen() 不支持重构User-Agent
(2)requests模块
(2-1)request的常用用法:
requsts.get(网址)
(2-2)响应的对象response的方法:
response.text返回Unicode格式的数据(str)
response.content返回字节流数据(二进制)
response.conten.decode('utf-8')手动进行解码
response.url返回url
response.encode() = "编码"
(3).通过requsts模块发送POST请求:
cookie:
cookie是通过在客户端记录的信息确定用户身份
HTTP是一种连接协议客户端和服务器交互仅仅限于“请求/响应”结束后断开,下一次请 求时,服务器会认为是一个新的客户端,为了维护他们之间的连接,让服务器知道这是前一个用户发起的请求,必须在一个地方保存客户端信息
session;
session是通过在服务端记录的信息确定用户身份,这里的session就指的是一次会话
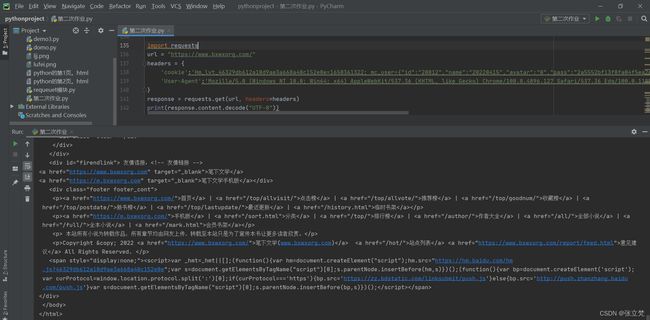
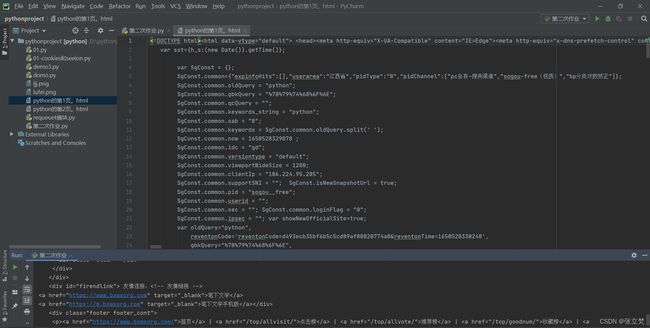
这样就可以获取页面源码了!!!
欢迎大家前来牛客网刷题哦
不要着急,最好的总会在最不经意的时候出现。那我们要做的就是:怀揣希望去努力,静待美好的出现。愿你的世界永远充满阳光,不会有多余的悲伤。愿你在人生道路上,到达心之所向的地方,陪伴你的,是你最欢喜的模样。
今天是个大喜的日子,4月21号,不仅是我的生日,也是我第一次CSDN发稿,作为一位萌新,还请大家多多支持,下午我会发帖子链接,还请大家三连哦!!!
2002/4/21
祝小梵梵生日快乐
