爬虫练习题(三)
- 博主链接:张立梵的爬虫开端
- 个人介绍:小编大一视传在读,目前即将大二
- 欢迎大家对文章
关注、点赞、收藏
最近小伙伴问我有什么刷题网站推荐,我在这里推荐一下牛客网,这里面包含各种题库,全都是免费的题库,可以全方面提升你的数据操纵逻辑,提升编程实战技巧,赶快来一起刷题吧牛客网笔试题库|面试经验
题目一:目标网站:https://www.1ppt.com/moban/
爬取要求:
1、 翻页爬取这个网页上面的源代码
2、 并且保存到本地,注意编码
分析网站:
https://www.1ppt.com/moban/
https://www.1ppt.com/moban/ppt_moban_2.html
https://www.1ppt.com/moban/ppt_moban_3.html
'''
import urllib.request
start = int(input("输入起始页")) # 转int
end = int(input("输入结束页"))
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36'
}
for n in range(start, end + 1):
url = 'https://www.1ppt.com/moban/ppt_moban_{}.html'.format(n)
print(url)
req = urllib.request.Request(url, headers=headers) # 实例化请求对象
response = urllib.request.urlopen(req) # 发送请求的方法
with open(f'第{n}页.html', 'a', encoding='gb2312') as f:
f.write(response.read().decode('gb2312'))首先,我们打开网址,右击点开查看网页源代码,或者是右击检查抓包,Network 网络是展现网页数据包的地方,找网址相同的数据包,点开 response 响应内容,这也是页面源码。
我们在 pycharm 新建文件,第一步分析网页抓包,手动翻页,找到 url 规律,把网页链接拿下来复制并粘贴在 pycharm 工程文件中,我们可以看到第一页和后面的网页链接不一致,这里可以手动加上,后面可能会需要用到判断。
然后,我们用 import 导入 urllib.request 模块,Ctrl+Alt+L 可以让代码变规范。
构建 url,可以用循环,也可以一页一页构建,网址之前是 http(80)https(443)协议,括号内为端口,紧接着是域名,“?”后是 get 请求携带的一些参数,kw 搜索内容,pn 为页面,其他的参数可能不怎么影响爬取进程,就可以删掉。构建好 URL 后,可以打印
发起请求
zlf = urllib.request.Request(url,headers=headers),构建请求对象,实例化请求对象,并用变量接收
response = urllib.request.urlopen(zlf)
拿到响应内容,最后,用 with open 保存,文件名,'w'写入(模式默认只读'r'),encoding(编码格式,怎么解码怎么写),as 后面取别名,
read 把数据以字节形式提取出来,后面可以转码用 decode
题目二:网页"https://www.6pian.cn/xq.html"
1.需求爬取前六页的页面源码
2.保存
'''
1.分析网页:
https://www.6pian.cn/
https://www.6pian.cn/xq.html
https://www.6pian.cn/xq/1/0.html
https://www.6pian.cn/xq/2/0.html
https://www.6pian.cn/xq/3/0.html
'''
import urllib.request
start = int(input("请输入起始页"))
end = int(input("请输入结束页"))
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.5060.66 Safari/537.36 Edg/103.0.1264.44'
}
for n in range(start, end + 1):
url = 'https://www.6pian.cn/xq/{}/0.html'.format(n)
print(url)
q = urllib.request.Request(url,headers=headers)
response = urllib.request.urlopen(q)
with open(f'第{n}页.html','w',encoding='utf-8')as f:
f.write(response.read().decode('utf-8'))首先,分析牛片网页链接,找到网页的规律,构建URL
每一个页面的网页链接都不一样,一定要谨慎仔细的检查,找到规律,分别用input导入起始页和终止页,并用变量接收,用headers伪装,在页面中有几点开检查,找到整个网页的包,点开后找到user agent,复制到headers里面,有的时候会需要复制cookie,但在这题不需要用到
输入循环保证一面爬完后,紧接着爬下一页,这样你的公式必须要写对,逻辑清楚才能写出正确答案,答案不能死,搬硬套,后面就是构建URL,把变量n传入,代替链接中的变量,使整个链接,满足所有页面链接,一旦爬取失败,你就要重新审视自己的构建,有没有出现问题?能不能满足其他页面的链接,后面最好是打印一下,你刚构建好的网址,确保无误后就可以实例化请对象,这里要看Request里面有哪几个变量并且传入用一个变量接收整个实例化过程
With open用来保存数据第二个引号中,w为写入如果不写默认为r为只读,转码时一定要注意看看他的编码类型输错了肯定会报错,这样你就可以在pycharm里得到六个页面的网页源码了。

User-Agent在这里:
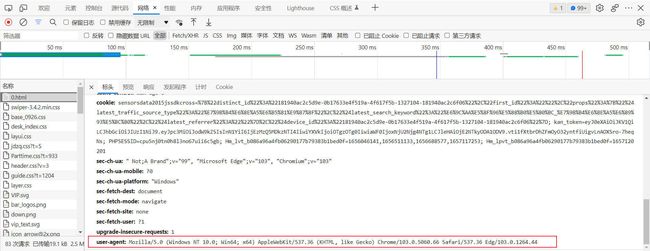
整个页面的数据包:

题目三:爬取百度贴吧https://tieba.baidu.com
要求1.在输入框中输入海贼王
2.爬取前六页的网页源代码
3.掌握百度贴吧网页链接的运行规律,构建合适的URL
'''
1、分析网站
2、发送请求
3、提取数据
4、保存数据
'''
'''
https://tieba.baidu.com/f?kw=%E6%B5%B7%E8%B4%BC%E7%8E%8B&ie=utf-8&pn=0
https://tieba.baidu.com/f?kw=%E6%B5%B7%E8%B4%BC%E7%8E%8B&ie=utf-8&pn=50
https://tieba.baidu.com/f?kw=%E6%B5%B7%E8%B4%BC%E7%8E%8B&ie=utf-8&pn=100
https://tieba.baidu.com/f?kw=%E6%B5%B7%E8%B4%BC%E7%8E%8B&ie=utf-8&pn=150
https://tieba.baidu.com/f?kw=%E6%B5%B7%E8%B4%BC%E7%8E%8B&ie=utf-8&pn=200
https://tieba.baidu.com/f?kw=%E6%B5%B7%E8%B4%BC%E7%8E%8B&ie=utf-8&pn=250
'''
import requests
word = input("输入要搜索的内容")
start = int(input("输入起始页"))
end = int(input("输入结束页"))
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36'
}
for n in range(start,end+1):
url = f'https://tieba.baidu.com/f?kw={word}&pn={(n-1)*50}'
print(url)
response = requests.get(url, headers=headers)
with open(f"{word}的第{n}页.html", 'w', encoding='utf-8') as file:
file.write(response.content.decode('utf-8'))
接下来我们就打开百度贴吧看看他的URL与之前的有什么区别吧!
1.打开网址https://tieba.baidu.com

2.分析网页
初始链接
https://tieba.baidu.com/f?ie=utf-8&kw=%E6%B5%B7%E8%B4%BC%E7%8E%8B&fr=search
第一页至第四页的链接
https://tieba.baidu.com/f?kw=%E6%B5%B7%E8%B4%BC%E7%8E%8B&ie=utf-8&pn=0
https://tieba.baidu.com/f?kw=%E6%B5%B7%E8%B4%BC%E7%8E%8B&ie=utf-8&pn=50
https://tieba.baidu.com/f?kw=%E6%B5%B7%E8%B4%BC%E7%8E%8B&ie=utf-8&pn=100
https://tieba.baidu.com/f?kw=%E6%B5%B7%E8%B4%BC%E7%8E%8B&ie=utf-8&pn=150
我们可以发现除了https://tieba.baidu.com原始百度贴吧的网页链接后面还有kw,ie,pn,这都在符号/f?后面,这些参数我们在上一篇都已明晰,唯一不同的是搜索内容变成了%E6%B5%B7%E8%B4%BC%E7%8E%8B原因很简单,kw是用户在输入框中输入的搜索内容,“海贼王”是汉字所以就被转码了,这一串字符的意思就是“海贼王”的意思。
值得注意的是
在“&”符号后面出现了pn=0的字样
每一个网址都有自己独特的一面,百度贴吧也是一样,自己携带的pn参数在一些链接中是没有的,所以在构建URL时要注意他的变化,由分析可得第一页pn=0,爹人也陪你,第三页100,每页以50递增,我们不妨修改URL测试一下第五页和第六页的链接,把pn后面的值改成200和250

这样剩余俩页的就可以凭空写出:
https://tieba.baidu.com/f?kw=%E6%B5%B7%E8%B4%BC%E7%8E%8B&ie=utf-8&pn=200
https://tieba.baidu.com/f?kw=%E6%B5%B7%E8%B4%BC%E7%8E%8B&ie=utf-8&pn=250
3.发送请求
导入requests模块,并且导入起始页和结束页(这里别忘了强转哦)还有一点就是导入搜索内容用word接收,构建好UA(User-Agent)。
import requests
word = input("输入要搜索的内容")
start = int(input("输入起始页"))
end = int(input("输入结束页"))
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36'
}4.提取数据(pn的变化)
for n in range(start,end+1):
url = f'https://tieba.baidu.com/f?kw={word}&pn={(n-1)*50}'
print(url)
response = requests.get(url, headers=headers)
首先,我们需要提取第一页到第六页的数据,因为第一页pn的值为零,要满足每增长一页nn的值增加50,这个规律,我们就可以用公式pn =(n- 1)*50,当n为1时,Pn的值正好等于零,满足需求,后面的页面正好是以倍数增加,所以这个公式满足要求。以后我们要注意各种网址,每一种网址规律都不一样,想要找到它们之间的规律还是很难的,后面的文章我会详细的和大家慢慢的分析各种网址的应对情况,每一种网址需要找到规律,并且用公式把规律概括出来,并且反复的验证公式的准确性,所以公式不是唯一的,他极为灵活,要应对不同的场合,构建不同的公式,构建好可以打印一下发送请求的url。
还有一点需要注意的是,要明确是什么请求类型,这个就是Get请求,所以response=requests.get,后面传入相关成分 这个发送请求的过程就包含了get请求,突显了这是一个get请求类型的网页,后面我们会遇到post请求类型,这个咱们遇到再说,百度翻译就是一个post的请求。
5.保存数据
with open(f"{word}的第{n}页.html", 'w', encoding='utf-8') as file:
file.write(response.content.decode('utf-8'))
这里就是依次把文件名,写入,转码处理好就可以,转码类型一定要看清否则会报错。
希望大家能在我的文章中打好基础能够满怀信心的应对初级爬虫的任何挑战!后续会继续推出爬虫知识点与相关题目!
快来牛客刷题吧