Python设计模式系列之一: 用模式改善软件设计
设计模式(design pattern)的提出,是面向对象程序设计演化过程中的一个重要里程碑。正如Gamma,Helm,Johnson和Vlissides在他们的经典著作《设计模式》一书中所说的:设计模式使得人们可以更加简单和方便地去复用成功的软件设计和体系结构,从而能够帮助设计者更快更好地完成系统设计。
设计模式的概念最早起源于建筑设计大师Christopher Alexander关于城市规划和建筑设计的著作《建筑的永恒方法》,尽管Alexander的著作是针对建筑领域的,但他的观点实际上适用于所有的工程设计领域,其中就包括软件设计领域。在《建筑的永恒方法》一书中,Alexander是这样描述模式的:
模式是一条由三部分组成的规则,它表示了一个特定环境、一个问题和一个解决方案之间的关系。每一个模式描述了一个在我们周围不断重复发生的问题,以及该问题的解决方案的核心。这样,你就能一次又一次地使用该方案而不必做重复劳动。
将设计模式引入软件设计和开发过程的目的在于充分利用已有的软件开发经验,这是因为设计模式通常是对于某一类软件设计问题的可重用的解决方案。优秀的软件设计师都非常清楚,不是所有的问题都需要从头开始解决,他们更愿意复用以前曾经使用过的解决方案,每当他们找到一个好的解决方案,他们会一遍又一遍地使用,这些经验是他们成为专家的部分原因。设计模式的最终目标就是帮助人们利用熟练的软件设计师的集体经验,来设计出更加优秀的软件。
在软件设计领域中,每一个设计模式都系统地命名、解释和评价了面向对象系统中的一个重要的和可复用的设计。这样,我们只要搞清楚这些设计模式,就可以完全或者说很大程度上吸收了那些蕴含在模式中的宝贵经验,从而对软件体系结构有了比较全面的了解。更加重要的是,这些模式都可以直接用来指导面向对象系统设计中至关重要的对象建模问题,实际工作中一旦遇到具有相同背景的场合,只需要简单地套用这些模式就可以了,从而省去了很多摸索工作。
在长期的软件实践过程中,人们逐渐总结出了一些实用的设计模式,并将它们应用于具体的软件系统中,出色地解决了很多设计上的难题。源于Smalltalk,并在Java中得到广泛应用的模型-视图-控制器(Model-View-Controller,MVC)模式,是非常经典的一个设计模式,通过它你可以更好地理解"模式"这一概念。
MVC模式通常用在开发人机交互软件的时候,这类软件的最大特点就是用户界面容易改变,例如,当你要扩展一个应用程序的功能时,通常需要修改菜单来反映这种变化。如果用户界面和核心功能紧紧交织在一起,要建立这样一个灵活的系统通常是非常困难的,因为很容易产生错误。为了更好地开发这样的软件系统,系统设计师必须考虑下面两个因素:
- 用户界面应该是易于改变的,甚至在运行期间也是有可能改变的;
- 用户界面的修改或移植不会影响软件的核心功能代码。
为了解决这个问题,可以采用将模型(Model)、视图(View)和控制器(Controller)相分离的思想。在这种设计模式中,模型用来封装核心数据和功能,它独立于特定的输出表示和输入行为,是执行某些任务的代码,至于这些任务以什么形式显示给用户,并不是模型所关注的问题。模型只有纯粹的功能性接口,也就是一系列的公开方法,这些方法有的是取值方法,让系统其它部分可以得到模型的内部状态,有的则是置值方法,允许系统的其它部分修改模型的内部状态。
视图用来向用户显示信息,它获得来自模型的数据,决定模型以什么样的方式展示给用户。同一个模型可以对应于多个视图,这样对于视图而言,模型就是可重用的代码。一般来说,模型内部必须保留所有对应视图的相关信息,以便在模型的状态发生改变时,可以通知所有的视图进行更新。
控制器是和视图联合使用的,它捕捉鼠标移动、鼠标点击和键盘输入等事件,将其转化成服务请求,然后再传给模型或者视图。整个软件的用户是通过控制器来与系统交互的,他通过控制器来操纵模型,从而向模型传递数据,改变模型的状态,并最后导致视图的更新。
MVC设计模式将模型、视图与控制器三个相对独立的部分分隔开来,这样可以改变软件的一个子系统而不至于对其它子系统产生重要影响。例如,在将一个非图形化用户界面软件修改为图形化用户界面软件时,不需要对模型进行修改,而添加一个对新的输入设备的支持,则通常不会对视图产生任何影响。
应用了MVC设计模式的软件系统,其基本的实现过程是:
- 控制器创建模型;
- 控制器创建一个或多个视图,并将它们与模型相关联;
- 控制器负责改变模型的状态;
- 当模型的状态发生改变时,模型会通知与之相关的视图进行更新。
如果用UML来表示MVC设计模式,则如图1所示:
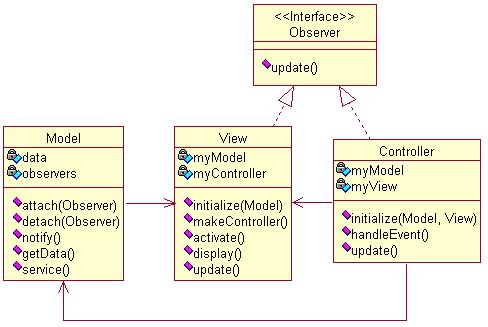
尽管设计模式的目标是努力做到与语言的无关性,但事实上许多模式在应用时还是需要依赖于具体实现语言的某些特性,尤其是该语言的对象模型。由于《设计模式》一书采用的是C++和Smalltalk来讲述设计模式,因此访问控制符和静态成员方法(类方法)等都可以直接使用,可惜的是这些特性在Python中都无法用到,原因是Python采了与C++完全不同的对象模式。
简单说来,Python是一种优秀的面向对象脚本语言,它具有动态语义和快速的原型开发能力,也许在短短的几分钟内,你就可以开发出使用其它语言可能需要花费几个小时的原型系统。Python丰富的工具集使得它位于传统脚本语言(如Tcl、Perl和Scheme)和系统编程语言(如C、C++和Java)之间,既具备了脚本语言的简单易用性,同时又能够提供只有系统语言才可能拥有的某些高级特性。
从面向对象角度来看,Python和Smalltalk一样都采用了完全的面向对象设计思想,其对象模型能够支持诸如运算符重载、多重继承等高级概念。但Python在设计时似乎忽略了面向对象的一项基本原则,那就是数据隐藏。与C++和Java不同,Python没有为类定义提供public、protected和private等关键字,这就意味着任何人都可以直接修改对象的属性。Python之所以这么做,也许是为了保证语法上的简洁性,就像Python的发明人Guido van Rossum所认为的那样:"丰富的语法带来的负担多于帮助"。但在某些设计模式中,向外界隐藏数据和方法都是非常必要的,为此我们不得不利用Python对象模型提供的某些高级特性,来实现某种程度上的隐藏性。
在Python中应用设计模式的一个有利因素是它的动态类型绑定,也就是说一个对象很少只是一个类的实例,而是可以在运行时动态改变。在面向对象系统中,接口是一个基本的组成部分,对象只有通过它们的接口才能与外界进行交互。对象的接口与其功能是完全分离的,支持相同请求的不同对象针对同一请求所触发的操作可能完全不同,这就是动态绑定的概念。动态绑定虽然看起来在一定程度上使得代码不同那么容易理解和维护,但它的确可以使整个软件系统的结构显得更加清晰和合理。
作为一门优秀的脚本语言,Python正在被越来越多的人所接受,使用Python开发的项目也越来越多,这也难怪会被大家推崇为"下一代编程语言"中的典型代表。随着应用范围的不断扩展,如何在用Python开发软件时充分利用已有的经验和成果将成为人们关注的焦点,而设计模式作为软件复用的一个重要方面,其价值自然是不言而喻。可问题是目前所使用的设计模式大都是人们在用Smalltalk、C++和Java开发软件时所总结出来的,因此或多或少地带有这些语言的影子,而要想在Python中使用这些设计模式,必须根据Python的自身特点和实际需要,灵活地加以运用。
对一门具体的编程语言来说,在应用设计模式时影响最大的莫过于它的对象模型了,这是因为大部分设计模式都源自于C++和Java这类面向对象编程语言。要想在Python中复用这些设计模式,首先需要对Python的对象模型有一个比较清晰的认识。
同其它面向对象编程语言一样,Python中的类也是一种用户自定义的数据类型,其基本的语法格式是:
class <name>(superclass, ...): # 定义类
data = value # 共享的类变量
def method(self, ...): # 类中的方法
self.member = value # 实例的数据
|
类定义从关键字class开始,并包含整个缩进代码块,类中定义的方法和属性构成了类的名字空间(name space)。一个类通常会有多个方法,它们都以关键字def开头,并且第一个参数通常都是self,Python中的变量self相当于C++中的关键字this,其作用是传递一个对象的引用。
Python中的类属性位于类的名字空间中,可以被所有的类实例所共享,这一点同C++和Java相同。访问类属性时不需要事先创建类的实例,直接使用类名就可以了。例如:
>>> class Friend:
default_age = 20
>>> Friend.default_age
20
|
除了自定义的类属性外,Python中的每个类其实都具有一些特殊的类属性,它们都是由Python的对象模型所提供的。表1列出了这些类属性:
| 属性名 | 说明 |
| __dict__ | 类名字空间的字典变量 |
| __doc__ | 类的文档说明字符串 |
| __name__ | 类的名称 |
| __module__ | 类的模块名 |
| __bases__ | 该类所有父类组成的元组 |
>表1特殊的类属性
定义类的目的是为了创建它的实例,从面向对象的角度看,类是对数据及其相关操作的封装,而类实例则是对现实生活中某个实体的抽象。假设定义了如下一个类:
class School:
def __init__(self, name):
self.name = name
self.students = []
def addStudent(self, student):
self.students.append(student)
|
要创建School类的一个实例,可以执行下面的语句:
bit = School("Beijing Institute of Technology")
|
在C++和Java中创建类实例时,与类具有相同名称的构造函数被调用,而在Python中创建一个类的实例时,将调用名为__init__的特殊方法。Python中的类实例继承了类的所有方法和属性,并且有自己独立的名字空间,使用下面的方法可以访问类实例的方法和属性:
bit.addStudent("gary")
bit.students
|
Python中的对象属性有一个非常有趣的地方,那就是使用它们之前不用像C++和Java那样,必须先在类中进行声明,因为这些都是可以动态创建的。作为一门动态类型语言,Python的这一特性的确非常灵活,但有时也难免产生问题。例如在许多针对接口的设计模式中,通常都需要知道对象所属的类,以便能够调用不同的实现方法,这些在C++和Java这些强类型语言的对象模型中不难实现,但对Python来讲可就不那么简单了,因为Python中的每个变量事实上都没有固定的类型。
为了解决这一问题,Python的__builtin__模块提供了两个非常实用的内建函数:isinstance()和issubclass()。其中函数isinstance()用于测试一个对象是否是某个类的实例,如果是的话则返回1,否则返回0。其基本的语法格式是:
isinstance (instance_object, class_object) |
例如:
>>> class Test:
pass
>>> inst = Test()
>>> isinstance(inst, Test)
1
|
而函数issubclass()则用于测试一个类是否是另一个类的子类,如果是的话则返回1,否则返回0。其基本的语法格式是:
issubclass(classobj1, classobj2) |
例如:
>>> class TestA: pass >>> class TestB(TestA): pass >>> issubclass(TestA, TestB) 0 >>> issubclass(TestB, TestA) 1 |
和类一样,Python中的每个类实例也具有一些特殊的属性,它们都是由Python的对象模型所提供的。表2列出了这些属性:
| 属性名 | 说明 |
| __dict__ | 实例名字空间的字典变量 |
| __class__ | 生成该实例的类 |
| __methods__ | 实例所有方法的列表 |
表2 特殊的实例属性
在面向对象的程序设计中,继承(Inheritance)允许子类从父类那里获得属性和方法,同时子类可以添加或者重载其父类中的任何方法。在Python中定义继承类的语法格式是:
class <name>(superclass, superclass, ...)
suit
|
例如,对于下面这个类:
class Employee:
def __init__(self, name, salary = 0):
self.name = name
self.salary = salary
def raisesalary(self, percent):
self.salary = self.salary * (1 + percent)
def work(self):
print self.name, "writes computer code"
|
可以为其定义如下的子类:
class Designer(Employee):
def __init__(self, name):
Employee.__init__(self, name, 5000)
def work(self):
print self.name, "writes design document"
|
在C++和Java的对象模型中,子类的构造函数会自动调用父类的构造函数,但在Python中却不是这样,你必须在子类中显示调用父类的构造函数,这就是为什么在Designer. __init__方法中必须调用Employee.__init__方法的原因。
人们对多重继承的看法一直褒贬不一,C++对象模型允许多重继承,而Java对象模型则是通过接口(Interface)来间接实现多重继承的。在对多重继承的处理上,Python采用了和C++类似的方法,即允许多重继承,例如:
class A:
pass
class B(A):
pass
class C:
pass
class D(B, C):
pass
|
严格说来,像C++和Java这些强类型语言对象模型中的多态概念并不适用于Python,因为Python没有提供类型声明机制。但由于Python本身是一种动态类型语言,允许将任意值赋给任何一个变量,如果我们对多态的概念稍加扩充,将其理解为具有能同时处理多种数据类型的函数或方法,那么Python对象模型实际上也支持经过弱化后的多态。
Python直到代码运行之时才去决定一个变量所属的类型,这一特性称为运行时绑定(runtime binding)。Python解析器内部虽然也对变量进行类型分配,但却十分模糊,并且只有在真正使用它们时才隐式地分配类型。例如,如果程序调用abs(num),则除数字之外的任何类型对变量num都没有意义,此时变量num事实上就进行了非正式的类型分配。
能够处理不同抽象层次的对象,是面向对象编程最重要的特性之一,也是Python的一个非常重要的组成部分。下面的例子示范了如何让Python中的一个函数能够同时处理多种类型的数据,在C++的对象模型中,这种多态被称为方法重载。
class Polymorph:
def deal_int(self, arg):
print '%d is an integer' % arg
def deal_str(self, arg):
print '%s is a string' % arg
def deal(self, arg):
if type(arg) == type(1):
self.deal_int(arg)
elif type(arg) == type(' '):
self.deal_str(arg)
else:
print '%s is not an integer or a string' % arg
|
这样,Polymorph类中的方法deal就可以同时处理数字和字符串了:
>>> p = Polymorph()
>>> p.deal(100)
100 is an integer
>>> p.deal("Hello World!")
Hello World! is a string
|
Python对象模型对可见性的处理与C++和Java完全不同。在C++和Java中,如果属性或者方法被声明为private,那就意味着它们只能在类中被访问,而如果被声明为protected,则只有该类或者其子类中的代码能够访问这些属性和方法。但在Python对象模型中,所有属性和方法都是public的,也就是说数据没有做相应的保护,你可以在任何地方对它们进行任意的修改。
能够对可见性进行约束是面向对象编程的一个重要特点,其目的是使对象具有优良的封装性:对象仅仅向外界提供访问接口,而内部实现细节则被很好地隐藏起来。奇怪的是作为一门面向对象脚本语言,Python并没有提供对可见性进行约束的机制,所有属性和方法对任何人都是可见的,任何人想知道对象的内部实现细节都是可能的。虽然这样做能够带来部分效率上的优化,但却无法阻止其它程序员对已经封装好的类进行破坏,从某种程度上这不得不说是Python带给我们的一丝的缺憾。
直到Python 1.5,Guido才引入了名字压缩(name mangling)的概念,使得类中的一些属性得以局部化。在进行定义类时,如果一个属性的名称是以两个下划线开始,同时又不是以下划线结束的,那么它在编译时将自动地被改写为类名加上属性名。例如:
class Greeting:
__data = "Hello World!"
def __init__(self, str):
Greeting.__data = str
>>> g = Greeting("Hello Gary!")
>>> dir (g)
['_Greeting__data', '__doc__', '__init__', '__module__']
|
从上面的显示结果可以看出,Greeting类的属性__data变成了_Greeting__data。虽然这样仍然无法阻止外界对它的访问,但的确使得访问变得不再那么直接了,从而在一定程序上保护了类中的数据不被外界破坏。
《设计模式》一书总结了23个模式,依据各自的目的又被分为创建型模式(creational pattern)、结构型模式(structural pattern)和行为型模式(behavioral patterns),它们分别从对象的创建,对象和对象间的结构关系以及对象之间如何交互这三个方面入手,对面向对象系统建模方法给予了解释和指导。
- 创建型模式描述怎样创建一个对象,以及如何隐藏对象创建的细节,从而使得程序代码不依赖于具体的对象,这样在增加一个新的对象时对代码的改动非常小。
- 结构型模式描述类和对象之间如何进行有效的组织,形成良好的软件体系结构,主要的方法是使用继承关系来组织各个类。
- 行为型模式描述类或对象之间如何交互以及如何分配职责,实际上它所牵涉的不仅仅是类或对象的设计模式,还有它们之间的通讯模式。
这些设计模式如果能够在Python中直接应用的话,对所有Python程序员来讲毫无疑问将是一笔非常宝贵的财富,因为它们的正确性和有效性已经被无数次的实践所验证过了。如果想在Python中灵活地运行这些设计模式,可以遵循下面的几个步骤:
- 接受设计模式
- 识别设计模式
- 运用设计模式
首先,你应该认识到设计模式的确能够改善你所设计的软件。其次,你必须仔细研究每一种设计模式,学习如何在Python中应用这些模式,以便在今后需要时能够用到它们。最后,你要努力做到对各个设计模式都有非常清晰的认识,最好能够形成自己的独到见解,清楚哪个模式能够解决哪个设计上的问题,并将它们真正应用到你用Python开发的软件中去。所有的设计模式都来源于实践,最终也将付诸于实践,只有通过实践中你才可能掌握每个模式的精髓所在。