【springboot项目】纳米搜索引擎
这是个什么样的项目
作为一个面向百度编程的开发者,平时用到最多的就是某DN啊,某乎啊这类网站。不得不说,这些平台都有非常不错的文章,但是相对应的,也有非常多质量一般的文章混迹其中(比如我写的博客~(~ ̄▽ ̄)~)。那么为了提高我们使用这些平台查询代码的效率,我就像是不是可以自己做一个超级小的搜索引擎,检索某个平台的文章,然后存起来,然后再根据一定的算法将他们排序,最终对文章做一个筛选,将高质量的文章呈现在眼前。我觉得这是一件很酷的事,所以打算尝试一下。
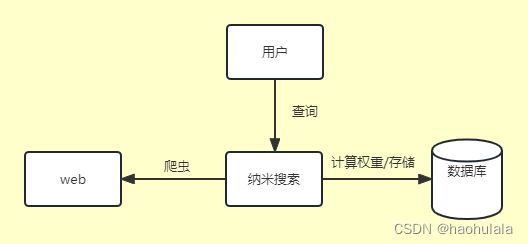
项目整体架构
虽然说的是架构,但是实际上这就是一个springboot单体项目,整个项目非常简单,就是使用一个全量爬虫,尽量去爬文章信息,将相应的信息放到数据库,然后根据一定的算法计算权重,当用户进行查询的时候就按照权重将信息呈现出来,整体的项目架构如下所示。
权重计算规则
既然我们的目标是对平台文章进行一个整合过滤,那么过滤规则就显得尤为重要了。
在使用某DN的时候,我非常不喜欢突然点进入一个连接,然后发现是资源的下载页面,因为下载资源是需要收费的,而且在下载前不知道该资源的质量如何,简直就是开盲盒,所以我们直接将下载连接过滤掉,只存文章的内容。
对于文章内容需要做一个权重计算,观察后发现,大概有两个指标可以衡量一篇文章的质量,一个是文章的阅读量,另一个就是收藏数。其中阅读量可以作为一个参考,但是参考的意义并不是特别大,因为有些文章标题起的很好,吸引人点进来后发现干货不多。与此相对应的,收藏数量是一个很好的衡量指标。
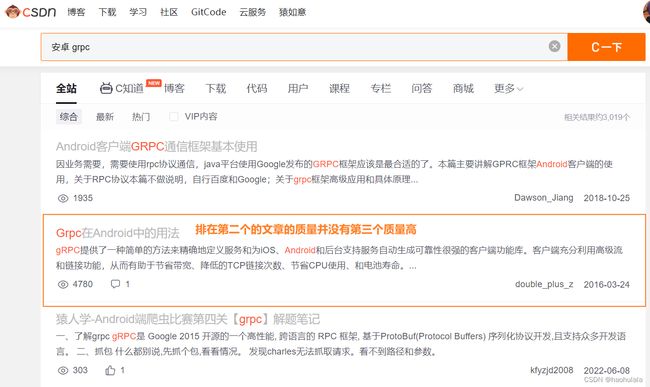
上图就是一个例子,当我们搜“安卓 grpc”的时候,排在第二的文章质量并没有第三的文章质量高。当我们继续往后面寻找的时候,会发现高质量的文章被藏在很后面了。这样就导致我们在查询的时候可能需要往后面翻很久才能找到想要的代码(当然我们都希望找到的代码直接复制粘贴就能运行哈哈)。
除了上面提到的点赞和收藏外,我们还可以注意到一点,就是csdn的搜索结果并没有将发布时间放在一个很重要的位置上,但是这也会造成一定的问题,因为有些技术更新换代很快,如果参考2016年的文章,可能得到的是一个比较有年代感的结果,这样可能也不利于我们的复制粘贴工作,因此我觉得文章的发布时间也是需要参考的一个点。
综合上述的规则,我们可以设定一个非常简单的权重计算规则
权重=系数1*收藏量+系数2*阅读量/1000+系数3*(1/(今年-发表年份+1))
我们知道收藏量和阅读量对于文章质量的衡量是非常重要的,添加了发表年份的计算是为了让更新的文章权重更高一点。由于阅读量可能很大,为了让权重小一点,所以阅读量要除以1000。系数1代表的是收藏量的权重,系数2代表的是阅读量的权重,系数3代表的是文章发表年份的权重。我们可以将系数1设定最大,将系数2设定小一点,系数3设定最小因为发表年份只是一个参考,并不能直接决定文章质量。我们可以设定系数1=0.5,系数2=0.4,系数3=0.1。
当然这是一个非常简单的尝试,并不一定就是最好的方案,以上只是设计权重计算公式的大致思路,也就是说希望将各个维度的参数量化然后达到文章质量筛选的效果。如果有能力和有条件的话,还可以用机器学习等的方法来找出一个更合理的权重计算公式,在这个项目里,我们暂时就用这个吧。
数据库设计
由于我们只需要保存文章的简单信息,所以只需要设计一个表就行了。
首先创建一个数据库
然后来看一下我们需要拿到哪些数据,由于只是做一个非常简单的案例,所以我们就先拿最主要的信息。
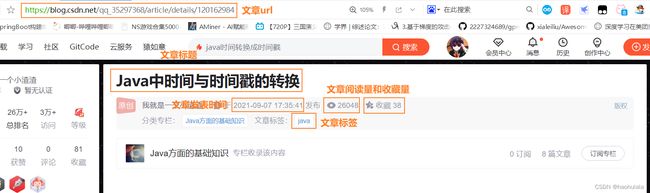
从上图可以看出来,我们需要拿到的信息有
- 文章的url
- 文章标题
- 文章发表时间
- 文章阅读量
- 文章收藏量
- 文章标签
根据上面的信息在mysql中建表
use csdn_article;
/* 文章信息表 */
drop table if exists t_article;
create table t_article(
u_id bigint(20) unsigned NOT NULL AUTO_INCREMENT PRIMARY KEY COMMENT '文章id',
title varchar(60) NOT NULL COMMENT '文章标题',
url varchar(200) NOT NULL COMMENT '文章url',
up_time varchar(10) NOT NULL COMMENT '文章发表时间 yyyy-mm-dd',
read_volum int NOT NULL COMMENT '文章阅读量',
collection_volum int NOT NULL COMMENT '文章收藏量',
tag varchar(100) NOT NULL COMMENT '文章标签,使用-分隔',
score double NOT NULL COMMENT '文章的权重得分'
)ENGINE=InnoDB COMMENT '文章信息表';爬取一页的信息
我们首先写一个爬虫,爬取一篇文章中的信息,主要用到okhttp库和jsoup库进行信息提取,两个库的依赖版本如下,前后端交互的时候需要将类变成json格式传输,所以还需要一个fastjson的包
com.squareup.okhttp3
okhttp
3.10.0
org.jsoup
jsoup
1.11.3
com.alibaba
fastjson
1.2.47
爬虫内容比较简单,只需要找到对应的标签,然后提取信息就行了,我们创建一个实体类来映射数据库表
public class ArticleEntity {
private Long u_id;
private String title;
private String url;
private String up_time;
private Integer read_volum;
private Integer collection_volum;
private String tag;
private Double score;
public ArticleEntity() {
}
public ArticleEntity(Long u_id, String title, String url, String up_time, Integer read_volum, Integer collection_volum, String tag, Double score) {
this.u_id = u_id;
this.title = title;
this.url = url;
this.up_time = up_time;
this.read_volum = read_volum;
this.collection_volum = collection_volum;
this.tag = tag;
this.score = score;
}
public Long getU_id() {
return u_id;
}
public void setU_id(Long u_id) {
this.u_id = u_id;
}
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}
public String getUrl() {
return url;
}
public void setUrl(String url) {
this.url = url;
}
public String getUp_time() {
return up_time;
}
public void setUp_time(String up_time) {
this.up_time = up_time;
}
public Integer getRead_volum() {
return read_volum;
}
public void setRead_volum(Integer read_volum) {
this.read_volum = read_volum;
}
public Integer getCollection_volum() {
return collection_volum;
}
public void setCollection_volum(Integer collection_volum) {
this.collection_volum = collection_volum;
}
public String getTag() {
return tag;
}
public void setTag(String tag) {
this.tag = tag;
}
public Double getScore() {
return score;
}
public void setScore(Double score) {
this.score = score;
}
}
接着写一爬虫逻辑,把数据装到实体类中,然后返回
@Component
public class ArticleSpider {
// 给定一个url,提取固定的信息
public ArticleEntity parseUrl(String url) {
// 先判断一下url是否是文章的url
if(!url.contains("article")) {
return null;
}
// 然后再加载html页面然后解析
// 建立连接
Request request = new Request.Builder()
.url(url)
.get() //默认就是GET请求,可以不写
.addHeader("User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.122 Safari/537.36")
.build();
try {
Response response = SpiderUtils.client.newCall(request).execute();
Document dom = Jsoup.parse(response.body().string());
// 找到文章标题
String title = dom.getElementsByClass("title-article").text();
// 找到发表时间
String up_time = dom.getElementsByClass("time").text().split(" ")[1];
// 找到文章阅读量
Integer read_volum = Integer.parseInt(dom.getElementsByClass("read-count").text());
// 找到文章收藏量
Integer collection_volum = Integer.parseInt(dom.getElementsByClass("get-collection").text().split(" ")[0]);
// 查找文章标签
StringBuilder sb = new StringBuilder();
Element element = dom.getElementsByClass("tags-box artic-tag-box").first();
// 找到所有的a标签
// 第一个标签是文章分类的,所以忽略掉
// 第二个是个span,内容是“文章标签”,也忽略掉
Elements tag_as = element.getElementsByTag("a").next().next();
for(Element tag_a : tag_as) {
sb.append(tag_a.text());
sb.append("-");
}
String str_tag = sb.toString();
ArticleEntity articleEntity = new ArticleEntity();
articleEntity.setTitle(title);
articleEntity.setUp_time(up_time);
articleEntity.setRead_volum(read_volum);
articleEntity.setCollection_volum(collection_volum);
articleEntity.setTag(str_tag);
articleEntity.setUrl(url);
articleEntity.setScore(SpiderUtils.getScore(read_volum, collection_volum, up_time));
return articleEntity;
} catch (IOException e) {
e.printStackTrace();
}
return null;
}
}
因为我们自始至终都只需要一个okhttp客户端,所以我们可以写到一个静态类中,权重计算规则也写到那个类中,作为一个静态方法来调用
public class SpiderUtils {
public static OkHttpClient client = new OkHttpClient()
.newBuilder()
.connectTimeout(1000, TimeUnit.SECONDS)
.build();
// 计算权重信息
public static double getScore(int read_volum, int collection_volum, String up_time) {
double x1 = 0.5;
double x2 = 0.4;
double x3 = 0.1;
double score = x1*read_volum/1000 + x2*collection_volum;
Calendar calendar = Calendar.getInstance();
Integer year = Integer.parseInt(String.valueOf(calendar.get(Calendar.YEAR)));
score += x3*(1/(year - Integer.parseInt(up_time.split("-")[0])));
return score;
}
}然后我们来写一个接口进行测试,现在先进行测试,到最后我会把所有的代码都放到gitee上的,大家感兴趣可以自取。
@Controller
public class HelloController {
@Autowired
private ArticleSpider articleSpider;
@RequestMapping("/hello")
@ResponseBody
public String hello(){
ArticleEntity articleEntity = articleSpider.parseUrl("https://blog.csdn.net/qq_35297368/article/details/120162984");
return JSONUtils.getJSONString(200, articleEntity);
}
}
最后在浏览器访问接口,看看结果

看到上面的结果就表示大功告成啦 (~ ̄▽ ̄)~
爬虫逻辑
上一小节我们写了解析单个网页的爬虫,接下来我们就需要想办法拿到文章的url。
我们首先看一下首页的信息,首页里面会有推荐的文章
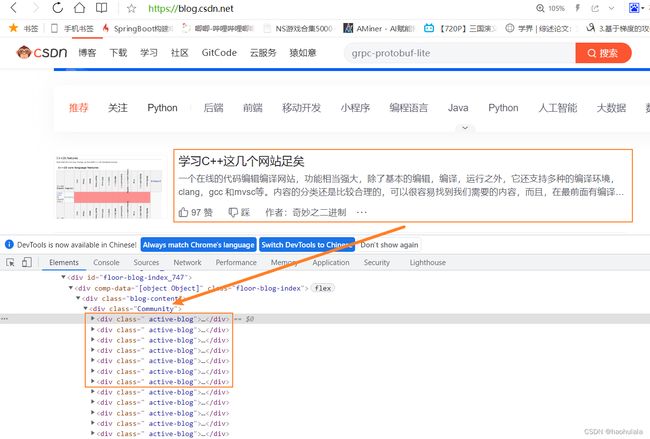
我们可以通过首页得到很多文章的url,然后进入到文章页面后,在底部会有推荐文章,这样子文章和文章之间就会连接成一个图,我们只需要按照深度优先或者广度优先 进行遍历就行了。
我们首先定义一个队列用于存放尚未消费的url,然后定义一个map记录已经消费过的url,已经消费过的url就不需要重复消费了。
public class SpiderUtils {
// 设置一个List用来记录还没有消费的url
public static ArrayBlockingQueue queue = new ArrayBlockingQueue(2048);
// 设置一个Map用来判断某个url是否已经被消费过
public static Map map = new HashMap<>();
public static OkHttpClient client = new OkHttpClient()
.newBuilder()
.connectTimeout(1000, TimeUnit.SECONDS)
.build();
// 计算权重信息
public static double getScore(int read_volum, int collection_volum, String up_time) {
double x1 = 0.5;
double x2 = 0.4;
double x3 = 0.1;
double score = x1*read_volum/1000 + x2*collection_volum;
Calendar calendar = Calendar.getInstance();
Integer year = Integer.parseInt(String.valueOf(calendar.get(Calendar.YEAR)));
score += x3*(1/(year - Integer.parseInt(up_time.split("-")[0]) + 1));
return score;
}
} 单个页面的消费类几乎没有变化,就是给他加了日志而已
@Slf4j
@Component
public class ArticleSpider{
public ArticleSpider() {
}
// 给定一个url,提取固定的信息
public ArticleEntity parseUrl(String url) {
// 先判断一下url是否是文章的url
if(!url.contains("article")) {
return null;
}
// 然后再加载html页面然后解析
// 建立连接
Request request = new Request.Builder()
.url(url)
.get() //默认就是GET请求,可以不写
.addHeader("User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.122 Safari/537.36")
.build();
try {
Response response = SpiderUtils.client.newCall(request).execute();
Document dom = Jsoup.parse(response.body().string());
// 找到文章标题
String title = dom.getElementsByClass("title-article").text();
// 找到发表时间
String up_time = dom.getElementsByClass("time").text().split(" ")[1];
// 找到文章阅读量
Integer read_volum = Integer.parseInt(dom.getElementsByClass("read-count").text());
// 找到文章收藏量
Integer collection_volum = Integer.parseInt(dom.getElementsByClass("get-collection").text().split(" ")[0]);
// 查找文章标签
StringBuilder sb = new StringBuilder();
Element element = dom.getElementsByClass("tags-box artic-tag-box").first();
// 找到所有的a标签
// 第一个标签是文章分类的,所以忽略掉
// 第二个是个span,内容是“文章标签”,也忽略掉
Elements tag_as = element.getElementsByTag("a").next().next();
for(Element tag_a : tag_as) {
sb.append(tag_a.text());
sb.append("-");
}
String str_tag = sb.toString();
ArticleEntity articleEntity = new ArticleEntity();
articleEntity.setTitle(title);
articleEntity.setUp_time(up_time);
articleEntity.setRead_volum(read_volum);
articleEntity.setCollection_volum(collection_volum);
articleEntity.setTag(str_tag);
articleEntity.setUrl(url);
articleEntity.setScore(SpiderUtils.getScore(read_volum, collection_volum, up_time));
log.info("获取文章entity:{}", JSON.toJSONString(articleEntity));
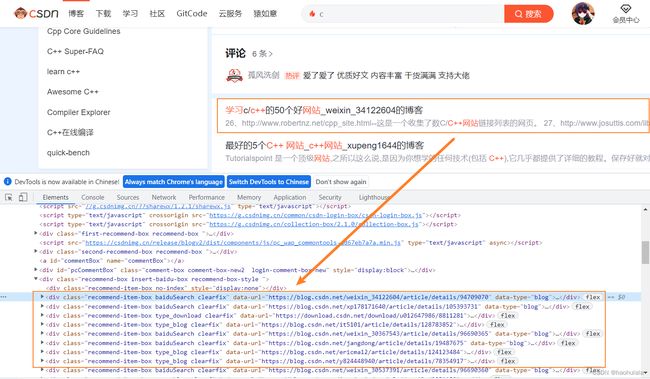
// 找到文章底部推荐的文章url
Elements elementsByClass = dom.getElementsByClass("recommend-item-box type_blog clearfix");
for(Element el : elementsByClass) {
String data_url = el.attr("data-url");
if(data_url!=null && !data_url.equals("")) {
SpiderUtils.queue.offer(data_url);
log.info("成功添加url:{}", data_url);
}
}
elementsByClass = dom.getElementsByClass("recommend-item-box baiduSearch clearfix");
for(Element el : elementsByClass) {
String data_url = el.attr("data-url");
if(data_url!=null && !data_url.equals("")) {
SpiderUtils.queue.offer(data_url);
log.info("成功添加url:{}", data_url);
}
}
return articleEntity;
} catch (IOException e) {
e.printStackTrace();
}
return null;
}
}然后就是主爬虫类使用BFS进行搜索
@Component
@Slf4j
public class MainSpider {
private String start_url = "https://blog.csdn.net/";
/*
// 我们暂时不用多线程进行消费了
// 定义一个线程池
private ThreadPoolExecutor threadPool = new ThreadPoolExecutor(16, 64,
1000, TimeUnit.MICROSECONDS,
new ArrayBlockingQueue(128));
*/
// 暂时就一个一个消费吧
@Autowired
private ArticleSpider articleSpider;
public void start() {
// 首先从首页拿到初始的文章url
Request request = new Request.Builder()
.url(start_url)
.get() //默认就是GET请求,可以不写
.addHeader("User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.122 Safari/537.36")
.build();
try {
Response response = SpiderUtils.client.newCall(request).execute();
Document dom = Jsoup.parse(response.body().string());
// 找到文章
Elements as = dom.getElementsByClass("blog");
for(Element e : as) {
String url = e.attr("href");
if(url!=null && !url.equals(" ")) {
SpiderUtils.queue.offer(url);
log.info("成功添加url:{}", url);
}
}
// 之后就是不断从队列中拿到url,然后解析顺便拿到更多的url
while(true) {
// 如果队列为空就持续等待
while(SpiderUtils.queue.isEmpty()){}
String url = SpiderUtils.queue.poll();
// 首先检查一下是否已经消费过了
if(SpiderUtils.map.containsKey(url)) {
continue;
}
SpiderUtils.map.put(url, 1);
articleSpider.parseUrl(url);
log.info("成功消费url:{}", url);
Thread.sleep(10);
}
} catch (IOException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
} 逻辑并不复杂,如果对这一块不熟的同学可以去复习一下图的遍历方式。
我们定义一个启动接口
@Controller
public class CTRLController {
@Autowired
private MainSpider mainSpider;
@RequestMapping("/start")
@ResponseBody
public String start(){
mainSpider.start();
return "ok";
}
}启动后我们看看日志的信息
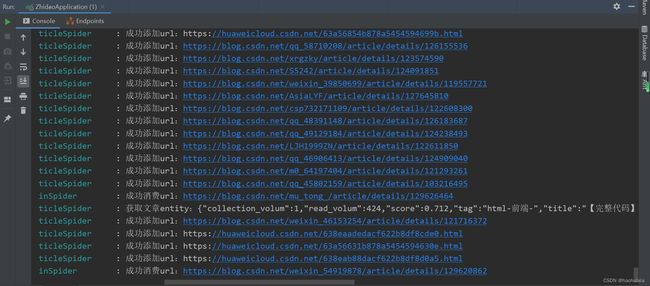
看到这样的日志输出就是大功告成啦 (~ ̄▽ ̄)~
将数据存到数据库
我们使用mybatis进行和数据库的交互,添加三个和数据库交互的方法
@Mapper
public interface ArticleMapper {
// 清空数据库
public void clear();
// 插入一条数据
public void insertOne(ArticleEntity articleEntity);
// 根据关键词从数据库中检索数据
public List queryByWords(@Param("words") String words);
} 对应的sql写道xml文件中
delete from t_article where 1=1
insert into t_article
(title, url, up_time, read_volum, collection_volum, tag, score) values
(#{title}, #{url}, #{up_time}, #{read_volum}, #{collection_volum}, #{tag}, #{score})
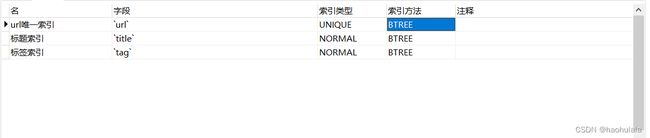
上述的查询我们使用title和tag两个字段进行模糊匹配,然后根据权重得分降序排序(权重高的结果排在前面)
于此同时,我们需要给数据库添加三个索引
将mapper类注入到爬虫类中,进行数据的写入。
然后在controller中写一个接口进行查询
@Controller
public class CTRLController {
@Autowired
private MainSpider mainSpider;
@Autowired
private ArticleMapper articleMapper;
@RequestMapping("/start")
@ResponseBody
public String start(){
new Thread(()->{
mainSpider.start();
}).start();
return "ok";
}
@GetMapping("/search")
@ResponseBody
public String search(@PathVariable("words") String words){
List articleEntities = articleMapper.queryByWords(words);
return JSONUtils.getJSONString(200, articleEntities);
}
}
接着启动爬虫,可以看到数据已经入库了
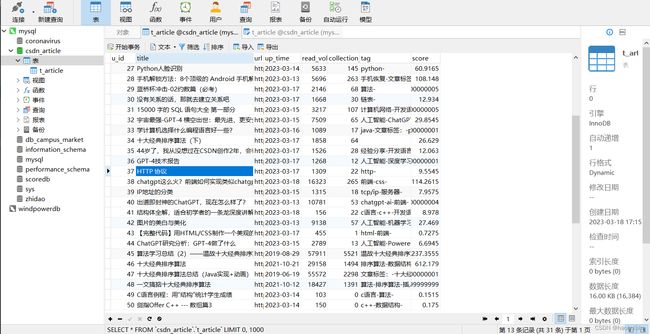
前面我们设置title字段的最大长度为60,有些文章的标题可能会过长,目前使用的策略就是如果长度超过了最大长度就进行截取。
我们先启动爬虫,然后再进行查询
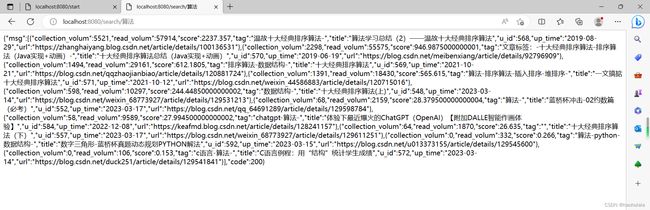
可以看到查到数据啦,大功告成 (~ ̄▽ ̄)~
前端页面
不得不说,编写前端页面不是我的强项,不过我想慢慢尝试编写一些好看的前端页面。
由于我没有使用过vue,所以暂时就先用theamleaf来写前端页面吧,theamleaf真的非常简单,给ModelAndView中添加对象,然后设置跳转的view就行了。
页面设计上参考Backdata,比较简约。
纳米搜索
在控制器中写一个接口供表单调用
/* 提供一个供jquery调用的接口 */
@RequestMapping("/search111")
public ModelAndView search111(@RequestParam("keyword") String words, ModelAndView mv){
List articleEntities = articleMapper.queryByWords(words);
mv.addObject("articleEntityList", articleEntities);
mv.setViewName("index");
log.info("搜索,关键词为 {}", words);
return mv;
} 运行程序后可以看一下效果
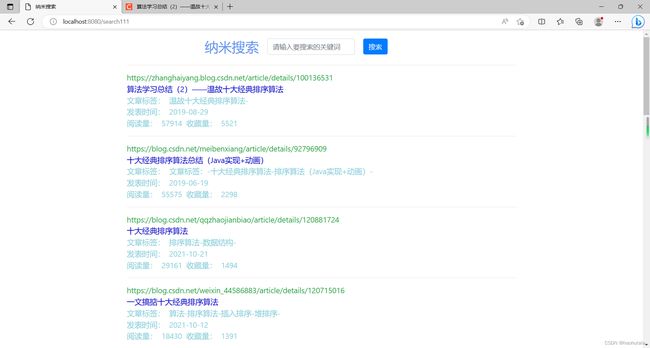
看到这样子的页面就大功告成啦 (~ ̄▽ ̄)~
我们可以看到,排名第一的文章阅读量和收藏量都很高,那么我们当初设定的目标基本上可以说初步达到了,好耶 o(* ̄︶ ̄*)o
总结
到这里终于把demo做完了,目前为止的话,算是实现了基本目标,但是项目其实还有很多模块没有完成,比如当检索的文章数量非常非常多的时候,服务器是否能抗住这个数据压力,以及当页面元素排列有问题的时候,是否还可以正确抓取数据,还有,我们是否可以基于已经爬取的数据做进一步分析,比如分析csdn文章趋势,提供当前的热点信息等等。
以上的信息都是可以拓展的点。
我认为一个好的软件,一定是迭代出来,只有在时间的过程中发现问题,然后改进问题,软件才能越来越健壮。
以后如果有空的话,我也会继续维护这个项目的,目前就先把1.0版本的代码放到gitee上,需要的同学可以自取。
https://gitee.com/haohulala/csdn_nano_search
最后,推荐一下我的微信公众号,欢迎和我交流呀。
微信公众号:进击的蛋糕(dangao123coding)