python采集富人帮数据并作可视化,医生说我适合吃软饭了~
前言
嗨喽,大家好呀~这里是爱看美女的茜茜呐

偶然间,我看到这么一个网站
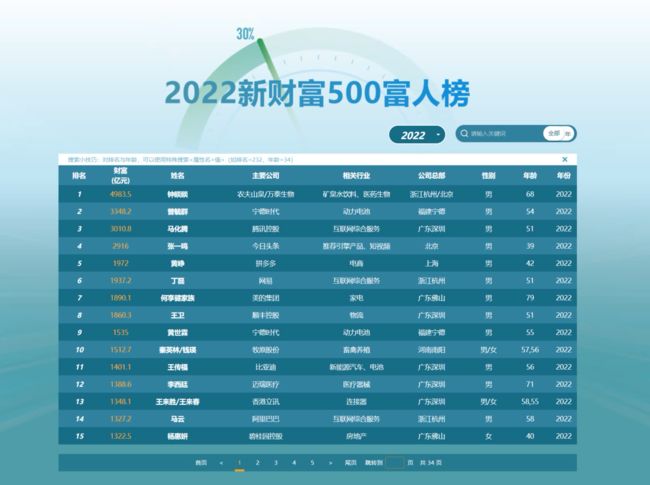
别的不说,光这富人榜这三个字就得让我采集上一手啊~

素材、教程、代码、插件安装教程我都准备好了,直接点击此处跳转文末名片领取
采集案例所用知识点
采集知识点:
-
requests简单使用 get方法 获取数据
-
re模块简单使用 .*?
-
csv 保存数据
基础知识点:
-
数据类型转换 --> json字典数据
-
列表取值
-
字典创建/取值
-
for循环遍历
-
print输出函数
-
pprint格式化输出模块的使用
-
函数关键字传参
环境使用
采集 :
-
Python 3.8
-
Pycharm
数据分析:
-
Python 3.8
-
jupyter notebook
模块使用:
采集 :
-
requests >>> pip install requests 数据请求
-
csv <表格文件> 内置模块 保存数据
数据分析
-
pandas
-
pyecharts
采集基本思路:
一. 数据来源分析: <重要点>
通过开发者工具进行抓包分析 --> 数据所对应链接地址是那个
-
打开开发者工具: F12 / fn+F12 / 右键点击检查选择network
-
点击第二页:
数据所对应:
https://service.ikuyu.cn/XinCaiFu2/pcremoting/bdListAction.domethod=getPage&callback=jsonpCallback&sortBy=&order=&type=4&keyword=&pageSize=15&year=2022&pageNo=2&from=jsonp&_=1680086650173
二. 代码实现步骤: <固定模板>
-
发送请求, 模拟浏览器对于url地址发送请求
-
获取数据, 获取服务器返回响应数据
-
解析数据, 提取我们想要的数据内容
-
保存数据, 把数据保存表格文件里面 Excel csv 数据库 json文件 文本也可以
采集代码展示
导入模块
# 导入数据数据请求模块
import requests
# 导入正则模块
import re
# 导入json
import json
# 导入格式化输出模块
from pprint import pprint
# 导入csv模块
import csv
创建文件 open函数
f = open('data.csv', mode='a', encoding='utf-8', newline='')
配置f文件对象 fieldnames 字段名 表头
csv_writer = csv.DictWriter(f, fieldnames=[
'姓名',
'财富(亿元)',
'主要公司',
'相关行业',
'公司总部',
'性别',
'年龄',
])
写入表头
csv_writer.writeheader()
多页数据采集:
for page in range(1, 35):
请求链接
url = f'https://service.ikuyu.cn/XinCaiFu2/pcremoting/bdListAction.do?method=getPage&callback=jsonpCallback&sortBy=&order=&type=4&keyword=&pageSize=15&year=2022&pageNo={page}&from=jsonp&_=1680086650173'
模拟浏览器
headers = {
# User-Agent 用户代理, 表示浏览器基本身份信息
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.0.0 Safari/537.36'
}
发送请求
response = requests.get(url=url, headers=headers)
正则匹配数据
html_data = re.findall('jsonpCallback\((.*?)\)', response.text)[0]
转换数据类型
json_data = json.loads(html_data)
for循环遍历, 提取列表元素
for index in json_data['data']['rows']:
# 创建字典 --> 字典取值
dit = {
'姓名': index['name'],
'财富(亿元)': index['assets'],
'主要公司': index['company'],
'相关行业': index['industry'],
'公司总部': index['addr'],
'性别': index['sex'],
'年龄': index['age'],
}
写入数据
csv_writer.writerow(dit)
print(dit)
数据分析代码展示
import pandas as pd
df = pd.read_csv('data.csv')
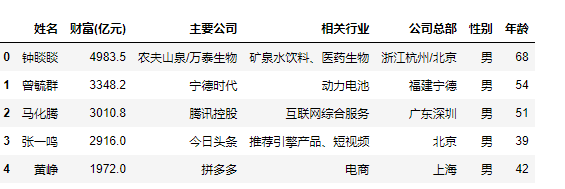
df.head()






尾语
今天的分享就到这里结束了,觉得有用的话,记得点赞收藏呀!
希望本篇文章有对你带来帮助 ,有学习到一点知识~
躲起来的星星也在努力发光,你也要努力加油(让我们一起努力叭)。

最后,宣传一下呀~更多源码、资料、素材、解答、交流皆点击下方名片获取呀