力扣刷题笔记21——两个链表的第一个公共节点/栈方法和双指针法
两个链表的第一个公共节点/栈方法和双指针法
- 问题
- 我的代码(栈)
- 示例代码(双指针)
问题
来自力扣:
输入两个链表,找出它们的第一个公共节点。
如下面的两个链表:
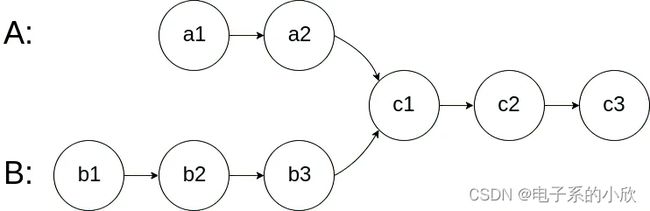
在节点 c1 开始相交。
示例 1:
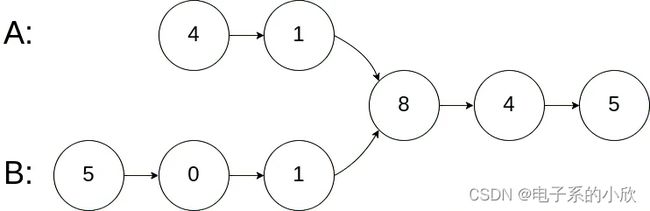
输入:intersectVal = 8, listA = [4,1,8,4,5], listB = [5,0,1,8,4,5], skipA = 2, skipB = 3
输出:Reference of the node with value = 8
输入解释:相交节点的值为 8 (注意,如果两个列表相交则不能为 0)。从各自的表头开始算起,链表 A 为 [4,1,8,4,5],链表 B 为 [5,0,1,8,4,5]。在 A 中,相交节点前有 2 个节点;在 B 中,相交节点前有 3 个节点。
示例 2:
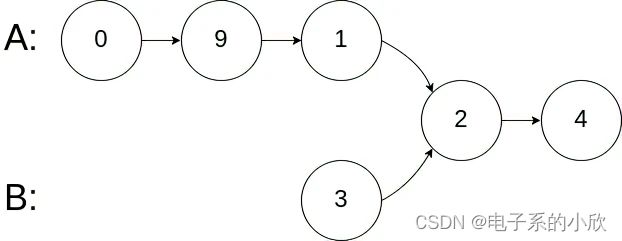
输入:intersectVal = 2, listA = [0,9,1,2,4], listB = [3,2,4], skipA = 3, skipB = 1
输出:Reference of the node with value = 2
输入解释:相交节点的值为 2 (注意,如果两个列表相交则不能为 0)。从各自的表头开始算起,链表 A 为 [0,9,1,2,4],链表 B 为 [3,2,4]。在 A 中,相交节点前有 3 个节点;在 B 中,相交节点前有 1 个节点。
示例 3:
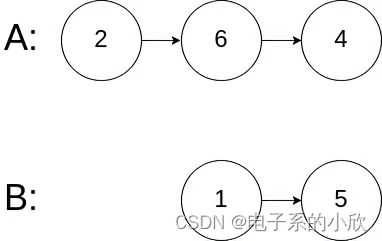
输入:intersectVal = 0, listA = [2,6,4], listB = [1,5], skipA = 3, skipB = 2
输出:null
输入解释:从各自的表头开始算起,链表 A 为 [2,6,4],链表 B 为 [1,5]。由于这两个链表不相交,所以 intersectVal 必须为 0,而 skipA 和 skipB 可以是任意值。
解释:这两个链表不相交,因此返回 null。
注意:
如果两个链表没有交点,返回 null.
在返回结果后,两个链表仍须保持原有的结构。
可假定整个链表结构中没有循环。
程序尽量满足 O(n) 时间复杂度,且仅用 O(1) 内存。
我的代码(栈)
class Solution {
public:
ListNode *getIntersectionNode(ListNode *headA, ListNode *headB) {
ListNode* interNode= NULL,tmp =NULL;
stack<ListNode*> stackA,stackB;
while(headA!=NULL){
stackA.push(headA);
headA = headA->next;
}
while(headB!=NULL){
stackB.push(headB);
headB = headB->next;
}
while(!stackA.empty() && !stackB.empty()&& stackA.top() == stackB.top()){
interNode = stackA.top();
stackA.pop();
stackB.pop();
}
return interNode;
}
};
思路:如果相交,则两个链表都后半段将是一样的,所以我先把他们用栈存起来,然后一个一个top比较下,当比较到不一样时,就找到了第一次相交的地方。
示例代码(双指针)
class Solution {
public:
ListNode *getIntersectionNode(ListNode *headA, ListNode *headB) {
if(!headA || !headB) return nullptr;
ListNode *pa=headA;
ListNode *pb=headB;
while(pa!=pb){
if(pa==nullptr){
pa=headB;
}else{
pa=pa->next;
}
if(pb==nullptr){
pb=headA;
}else
pb=pb->next;
}
return pa;
}
};
思路:官方解释。
- 当两个链表情况属于示例1时,pa会提前遍历完headA,然后它开始遍历headB。pb遍历完headB开始遍历headA时,pa准备查看headB的第二个节点。所以,他们可以在交点处相遇,然后推出while循环。
- 示例2和示例1是同个道理的。
- 示例3,pa遍历完headA和headB的时候,pb也刚好遍历完headB和headA。所以它们同时指向了NULL,将推出循环,返回NULL。
这个做法交双指针,看到这个真的感觉牛逼。它的复杂度应该跟我的方法是差不多的,不过它不需要浪费两个栈的存储空间,所以还是比我的方法好一点。