playwright基础入门解析
前言:
本文本着最小必要知识点原则,主要介绍playwright入门常用知识点,通过本文学习可以基本熟悉playwright语法,其他具体需求跟着官网学习即可
playwright介绍
Playwright是一个用于自动化Web浏览器测试的开源库。它支持跨浏览器平台,包括Chrome、Firefox、Safari和Edge。 Playwright提供了一个简单但功能强大的API,使开发人员可以轻松地编写和运行浏览器测试。
Playwright可以帮助您实现跨浏览器的兼容性测试、集成测试和端到端测试。它还提供了一些方便的功能,如网络拦截、页面截屏、媒体录制和调试。 Playwright的优点包括可靠的自动化测试、更快的测试执行速度和更好的测试结果质量。
Playwright是由Microsoft开发和维护,其代码托管在GitHub上,接受全球开发者的贡献。除了Playwright外,该团队还开源了Puppeteer和Playwright for Python两个自动化测试库。
官网地址:https://playwright.dev
GitHub地址:https://github.com/microsoft/playwright
playwright和selenium对比
底层通信:Playwright 在 Chromium、Firefox 和 WebKit 三种浏览器上都使用自己的协议 (Playwright protocol) 进行与浏览器底层通信。而 Selenium 则使用 WebDriver 协议进行通信,WebDriver 是有限制的,只能访问 DOM 树,而 Playwright 可以访问 DOM tree 和浏览器内部 API。
内置断言:Playwright 带有内置的断言机制 (Assertions),可以轻松地判断页面展示是否正确,如页面是否加载完成、元素是否存在、元素是否可见等。而 Selenium 没有内置断言机制,需要使用第三方库来进行断言。
等待机制:在页面元素加载完毕之前或者页面跳转导致元素失效时,需要等待一段时间后再进行下一步操作。Playwright 提供了更加灵活的等待机制,可以通过指定在特定时间内轮询特定条件来等待。而 Selenium 的等待机制比较简单,只提供了固定时间间隔和固定次数的等待机制。
定位灵活性:Playwright 具有更好的定位元素灵活性。除了基本的 CSS 选择器之外,Playwright 还支持更强大的选择器,如 XPath、Text 和 Accessibility 等。而 Selenium 只提供基本的 CSS 选择器和部分 XPath。Playwright 还支持 shadow DOM 元素的定位,而 Selenium 不支持。
性能方面:Playwright 的性能比 Selenium 更优秀。由于 Playwright 直接与浏览器底层通信,因此可以更快地定位元素和执行操作。Playwright 还提供了单独的进程池和并发执行来提高测试执行速度。而 Selenium 通常需要通过机制来处理元素查找和操作执行时可能遇到的阻塞和同步问题。
整体来看playwright可能比selenium表现更优秀
环境准备
Playwright 是专门为满足端到端测试的需要而创建的。Playwright 支持所有现代渲染引擎,包括 Chromium、WebKit 和 Firefox。在 Windows、Linux 和 macOS 上进行本地测试或在 CI 上进行测试.python 版本要求 python3.7+ 版本。
安装 playwright:
pip install playwright
安装所需的浏览器 chromium,firefox 和 webkit:
playwright install
仅需这一步即可安装所需的浏览器,并且不需要安装驱动包了。
访问百度示例代码
from playwright.sync_api import sync_playwright
import time
with sync_playwright() as playwright:
# 使用 Chromium 浏览器进行测试
browser_type = playwright.chromium
start_time = time.time()
# 启动浏览器并创建一个新的上下文
browser = browser_type.launch(headless=False)
context = browser.new_context()
# 创建一个新的页面并访问百度网站
page = context.new_page()
page.goto("https://www.baidu.com")
# 检查页面是否成功加载
assert page.title() == "百度一下,你就知道"
end_time = time.time()
print(f"Time taken: {end_time - start_time:.2f}s")
# 关闭浏览器
browser.close()
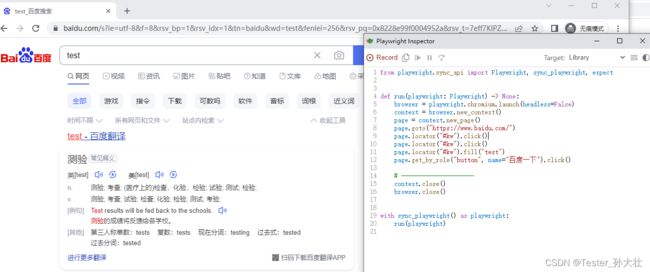
使用playwright的录制功能
使用录制功能只需在终端敲入如下命令
playwright codegen 网址

敲入命令后会自动打开网址,随后根据自己的操作可以自动生成代码,最后根据自己的需求修改即可
playwright常用元素定位方式
在UI自动化中最重要的是元素定位,以下是playwright常见的几种元素定位方式
- 通过CSS选择器定位:可以使用CSS选择器来定位元素,例如
page.locator('#element-id')可以选择id为“element-id”的元素。 - 通过XPath定位:可以使用XPath表达式来定位元素,例如
page.locator('//div[@class="selected"]')可以选择class为“selected”的div元素。 - 通过属性值定位:可以使用元素属性值来定位元素,例如
page.locator('[name="username"]')可以选择name属性值为“username”的元素。 - 通过文本内容定位:可以使用元素的文本内容来定位元素,例如
page.locator(':text("Submit")')可以选择文本内容为“Submit”的元素。 - 通过元素位置定位:可以使用元素在页面中的位置来定位元素,例如
page.locator('div:nth-child(3)')可以选择第三个div元素。 - 通过标签名定位:可以使用标签名来定位元素,例如
page.locator('input[type="checkbox"]')可以选择type为“checkbox”的input元素。
可见常用元素定位方式与selenium类似。
playwright常用API操作
- 处理表单
可以使用page.fill()方法填充表单,例如:
await page.fill('#username', 'my-username')
await page.fill('#password', 'my-password')
也可以使用page.click()方法模拟按钮点击事件,例如:
await page.click('#submit-button')
- 截图操作
使用page.screenshot()方法可以对当前页面进行截图,例如:
await page.screenshot(path='example.png')
也可以使用page.pdf()方法将页面转换为PDF格式,例如:
await page.pdf(path='example.pdf')
- 处理请求和响应
可以使用page.route()方法来拦截发出的请求,并进行相应的处理,例如:
async def handle_request(route, request):
print(request.url)
if request.url == 'https://example.com':
await route.continue_()
else:
await route.abort()
async def main():
async with async_playwright() as p:
browser = await p.chromium.launch()
page = await browser.new_page()
await page.route('**/*', handle_request)
await page.goto('https://example.com')
await browser.close()
asyncio.run(main())
也可以使用page.on('response')方法来拦截接收到的响应,并进行相应的处理,例如:
async def handle_response(response):
print(response.url)
print(await response.text())
async def main():
async with async_playwright() as p:
browser = await p.chromium.launch()
page = await browser.new_page()
await page.on('response', handle_response)
await page.goto('https://example.com')
await browser.close()
asyncio.run(main())
了解过基本元素定位方式和常用API操作后,工作中大部分需求可被解决。
同步和异步
Python Playwright 支持同步和异步两种操作方式。
同步操作方式:在代码执行时,程序会阻塞等待每个操作执行的结果,直到该操作执行结束才能继续执行后面的代码。同步代码容易理解和编写,但如果在网络请求等 I/O 操作时会造成大量的等待时间,影响程序的执行效率。
异步操作方式:在代码执行时,当遇到需要等待操作执行的时候,程序不会被阻塞,而是继续执行其他的代码。当该操作执行的结果返回时,程序会自动跳回去接着执行之前被暂停的代码。异步操作虽然需要一定的学习成本,但可以提升程序的执行效率。
Python Playwright 默认使用异步操作方式。可以通过使用 await 关键字或 async with 语法来定义异步操作,或者使用 sync 关键字来定义同步操作。例如:
import asyncio
from playwright.sync_api import Playwright, sync_playwright
with sync_playwright() as playwright:
browser = playwright.chromium.launch(headless=False)
page = browser.new_page()
page.goto('https://www.baidu.com')
browser.close()
async def main(playwright: Playwright) -> None:
browser = await playwright.chromium.launch(headless=False)
page = await browser.new_page()
await page.goto('https://www.baidu.com')
await browser.close()
asyncio.run(main())