百度工程师眼中的云原生可观测性追踪技术

作者 | daydreamer
一、概念介绍
在云原生领域,可观测性指从外部输出推断和衡量系统内部状态,描述系统中所发生情况的理解程度。常见的可观测性的三大基础是Metrics、Tracing和Logging:
-
监控指标(Metrics): 监控指标的定义特征是可聚合的,是在一段时间内组成单个逻辑指标、计数器或直方图的原子。例如:传入的http请求的数量可以建模为一个计数器,其更新聚合为简单的加法。
-
追踪(Tracing): 它定义特征是它处理请求范围内的信息,任何可以绑定到系统中单个事务对象的生命周期的数据或元数据。例如:发送到数据库的实际sql查询的文本。
-
日志(Logging): 日志的定义特征是它处理离散事件。例如:应用程序调试或错误消息通过一个可切割的文件发送到集群统一处理。
在这三个领域中,监控指标往往需要最少的资源来管理,因为从本质上来说,它们“压缩”得相当好;日志记录往往是压倒性的超过它所报告的生产流量。从数据量开销的量级来看,从监控(低)到日志(高),追踪技术tracing可能位于中间的某个地方。

当然,可观测性的意义在于更好的服务于业务系统,在实践中的应用往往是贴合业务需要,对其分析抽象,可以看到几种可观测系统的功能和特性,例如,开源的prometheus项目最初只是作为一个监控系统启动的,随着时间的推移,它可能会向跟踪方向发展,从而进入请求范围(request-scope)内的监控,但很可能不会深入到日志空间。
二、追踪技术数据模型(以OpenTelemetry标准为例)
我们以OpenTelemetry标准[1]为例,简单介绍tracing的通用数据模型。
追踪数据的经典模型最初来源于Google的经典论文[2],其中定义了一套通用的数据上报接口,要求各个分布式追踪系统都来实现这套接口,从而适配各种遵循此标准的分布式追踪系统,而对于开发者来说,可以根据业务需要,随意切换不同的分布式追踪系统。
OpenTelemetry标准中的跟踪由它们的 Span 隐式定义。特别是,可以将 Trace 视为 Spans 的有向无环图(DAG),其中 Spans 之间的边称为 References。

每个 Span 都封装了以下状态:
-
Name
-
Start and End Timestamps
-
Span Context
-
跨度上下文使用两个标识符提供有关跟踪和跨度的特定上下文:Trace ID 和Span ID。每个 Span 由一个在 Trace 中唯一的 ID 标识,称为 Span ID。Span 使用 Trace ID 来标识 span 与其跟踪之间的关系。Span Context 以此描述跨越服务和流程边界关系。
-
Attributes
-
包含元数据的键值对(key-value),您可以使用元数据来注释 Span 以携带有关它正在跟踪的操作的信息。
-
Span Events
-
被认为是 Span 上的结构化日志消息(或注释),通常用于表示 Span 持续时间内有意义的单点。
-
Span Links
-
可以将一个span与一个或多个span相关联,从而描述执行上的上下游关系。例如,假设我们有一个分布式系统,为了响应其中一些操作(称其为操作a),一个额外的操作(称其为操作b)被排队等待执行,操作b的执行是异步的。我们希望将操作b与操作a相关联,但我们无法预测操作b何时开始。此时将操作a最后一个span链接到操作b第一个span,从而描述他们的上下游关系。
-
Span Status
-
状态码
三、业界tracing落地Uber Jaeger
Uber公司于2016年开源了云原生领域优秀的tracing平台Jaeger[3]。当时该项目提出的背景是,Uber公司面对业务呈指数级增长微服务数量增长,而对于大型分布式微服务架构的可观测性,还缺乏一套完善的追踪平台支撑。该项目开源后,一直受到行业追捧,2017年被CNCF接纳成为毕业项目。该平台的特色是将单一API 时代的设计转变为分布式设计,实现统一的上下文传播的context,以及采样策略的决策转移到跟踪后端,允许后端动态调整采样率。该平台全面支持OpenTelemetry标准,一直是云原生领域的事实标准产品。
Jaeger的整体架构如下所示:
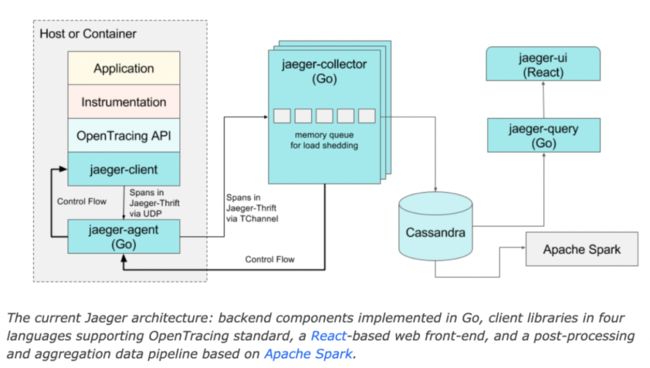
其中jaeger-client是客户端采集组件,支持动态流量模拟,对存储压力可感知。jaeger-agent负责采样相关策略。jaeger-collector负责tracing数据的收集,整理和转存工作。jaeger-ui和jaeger-query负责平台UI交互。接入方式支持中间件埋点,支持HTTP 等多种协议,底层存储采用Cassandra,Elasticsearch等开源存储平台。
对于Jaeger的介绍详见官网:https://www.jaegertracing.io/
阿里鹰眼平台
鹰眼是阿里为双十一等大流量活动打造的新一代基于日志的分布式调用跟踪系统。解决了故障定位难,容量预估难,资源浪费多,链路梳理难等线上问题。该平台有如下特点:
-
架构迭代逐渐轻量,数据呈现更加实时,从批量升级为流式计算
-
将监控流程搭建可视化,降低接入成本,搭建设计交给使用方
-
根据分析场景对数据进行抽样,如对链路形态的分析不需要全量数据
该平台通过统一的日志打印形式和衡量标准,可以发现热点和容量预估,支持压测,非法流量。实现全局调用统计,trace查询和实时监控等功能。支持http/tcp等协议,接入方式支持中间件埋点,字节码增强等方式,底层采用了HDFS/HBASE/HSTORE/MPP等存储数据库。下图是该平台的全局调用拓扑示意图。
关于该平台的介绍可以参考阿里云的介绍文章《打造立体化监控体系的最佳实践》。
四、实际工作遇到的难点及解决方案
在百度的实际生产系统中,我们也大量应用追踪技术来实现全链路实时监控、流量性能统计以及请求trace查询和case排查等功能。在应用过程中,我们也有一些实践经验:
1. 追踪的数据量大,主要表现在:
-
采集压力高,要求SDK高性能,由于请求分散上报和传输的压力不大
-
优化实现合理的抽样策略
-
深度优化编码及映射算法
-
数据根据类型和使用场景分类,选择不同的底层存储
2. 接入成本非常重要,需要保持极低成本。主要表现在:
-
开发人员对于非业务代码接入的主动性不高,这种情况下需要接口设计简单、易用,大量埋点可以依赖底层框架,自定义埋点简单易用
-
SDK使用文档表述的简洁、精准,有比较好的已有实践场景可以直接复用
-
投入的性价比要高,能看到系统切实解决的实际问题
3. 稳定性要求高,主要经验有:
-
采用本地持久化作为缓冲
-
流量与任务的的结合,插入trick task等
4. 实现一些高级特性的需求,例如:
-
指标的置信度分析,和数据科学的结合
-
多种聚合窗口实时分析,兼顾短时间的时效性和较长时间的趋势分析
-
更加直观的展现形式,如何用尽量少的指标直观展示尽量多的信息
总的来说,随着OpenTelemetry标准的落地,云原生可观测性追踪技术也在不断发展,在生产环境中也得到了广泛的应用,有力支持了大型分布式微服务系统的稳定性,性能,效率等各个方面。我们从一个百度工程师的视角出发,也能管中窥豹,一见可观测性的博大精深之妙。
---------- END ----------
参考资料:
[1] OpenTelemetry:https://opentelemetry.io/docs/concepts/signals/traces/#spans-in-opentelemetry
[2] Benjamin H. Sigelman Luiz André Barroso, et. al. 2010, Dapper, a Large-Scale Distributed Systems Tracing Infrastructure
[3] Uber Jaeger:https://eng.uber.com/distributed-tracing/
推荐阅读【技术加油站】系列:
使用百度开发者工具 4.0 搭建专属的小程序 IDE
百度工程师教你玩转设计模式(观察者模式)
揭秘百度智能测试在测试自动执行领域实践
H.265编码原理入门
小程序启动性能优化实践
百度工程师教你玩转设计模式(单例模式)
