Ceph系列01-Ceph简介
Ceph的基本概念介绍和入门知识储备。
1、ceph简介
Ceph是一个开源项目,它提供软件定义的、统一的存储解决方案。Ceph是一个可大规模扩展、高性能并且无单点故障的分布式存储系统。从一开始它就运行在通用商用硬件上,具有高度可伸缩性,容量可扩展至EB级别,甚至更大。
Ceph的架构在设计之初就包含下列特性:
- 所有的组件必须可扩展
- 不能存在单点故障
- 解决方案必须是软件定义的、开源的并且可适配
- Ceph软件应该运行在通用商用硬件之上
- 所有组件必须尽可能自我管理
Ceph存储系统在同一个底层架构上提供了块、文件和对象存储,使得用户可以自主选择他们需要的存储方式。对象是Ceph的基础,也就是它的基本存储单元。任何格式的数据,不管是块、对象还是文件,都以对象的形式保存在Ceph集群的归置组(Placement Group,Pg)
中。使用对象存储,我们可以将平台和硬件独立开来。在Ceph中,由于对象没有物理存储路径绑定,使得对象非常灵活并且与位置无关。这也使得Ceph的规模能够近线性地从PB级别扩展到EB级别。
Ceph是圣克鲁兹加利福尼亚大学的Sage Weil在2003年开发的,也是他的博士学位项目的一部分。初始的项目原型是大约40000行C++代码的Ceph文件系统,并于2006年作为参考实现和研究平台遵循LGPL协议(Lesser GUN Public License)开源。美国劳伦斯利物莫国家实验室(Lawrence Livermore National Laboratory)资助了Sage的初始研究工作。2003~2007年是Ceph的研究开发时期。在这期间,它的核心组件逐步形成,并且社区对项目的贡献也已经开始逐渐变大。Ceph没有采用双重许可模式,也就不存在只针对企业版的特性。
Inktank是Ceph背后的公司,它的主要目的是给他们的企业客户提供专业知识、处理流程、工具和支撑,使他们能够有效地采用和管理Ceph存储系统。Sage是Inktank的CTO和创始人。
Ceph这个词是宠物章鱼的一个常见绰号。Ceph可以看作Cephalopod的缩写,它属于海洋软体类动物家族。Ceph以章鱼作为自己的吉祥物,表达了Ceph跟章鱼一样的并行行为。
Inktank这个词与章鱼有一定关系。渔民有时候也把章鱼称为墨鱼,因为它们可以喷射墨汁。这就解释了为什么章鱼(Ceph)跟墨鱼(Inktank)有一定关系。同样,Ceph和Inktank有很多共同点。你可以认为Inktank就是Ceph的智库。
开源Linux社区2008年就预见到Ceph的潜力,并将其加入Linux内核主线。这已经成为Ceph的里程碑事件。

2、Ceph与云
云环境要求其存储能够以低成本纵向和横向扩展,而且能够容易与云框架中其他组件集成。
OpenStack项目大力推动了公有云和私有云的发展。它已经证明了自己是一个端到端云解决方案。它自己的内部核心存储组件Swift提供基于对象的存储和Nova-Volume(也称为Cinder),而Cinder则为VM提供块存储。
与Swift(它仅提供对象存储)不同,Ceph是一个包含块存储、文件存储和对象存储的统一存储解决方案,这样可以通过单一存储集群为OpenStack提供多种存储类型。因此,你可以轻松而高效地为OpenStack云管理存储。OpenStack和Ceph社区已经一起合作了许多年,致力于为OpenStack云开发一个完全支持的Ceph存储后端。从Folsom(OpenStack第6个主要版本)开始,Ceph已经完全与OpenStack集成。Ceph开发人员确保Ceph能够适用于OpenStack的最新版,同时贡献新特性以及修正bug。OpenStack通过它的cinder和glance组件使用Ceph最苛刻的特性RADOS块设备(RBD)。Ceph RBD通过提供精简配置的快照复制(snapshotted-cloned)卷帮助OpenStack快速配置数百个VM实例,这种方式既减少空间需求,又非常快速。
3、Ceph与软件定义存储(SDS)
Ceph是一个真正的SDS解决方案,它是开源软件,运行在商用硬件上,因此不存在厂商锁定,并且能提供低成本存储。SDS方案提供了客户急需的硬件选择的灵活性。客户可以根据自身的需要选择任意制造商的商用硬件,并自由地设计异构的硬件解决方案。在此硬件解决方案之上的Ceph的软件定义存储可以很好地工作。它可以从软件层面正确提供所有的企业级存储特性。低成本、可靠性、可扩展性是Ceph的主要特点。
从存储厂商的角度来看,统一存储的定义就是在单一的平台上同时提供基于文件和基于块的访问。
Ceph底层中并不存在块和文件的管理,而是管理对象并且在对象之上支持基于块和文件的存储。在传统基于文件的存储系统中,文件是通过文件目录进行寻址的。类似地,Ceph中的对象通过唯一的标识符进行寻址,并存储在一个扁平的寻址空间中。剔除了元数据操作之后,对象提供了无限的规模扩展和性能提升。Ceph通过一个算法来动态计算存储和获取某个对象的位置。
传统的存储系统并不具备更智能地管理元数据的方法。元数据是关于数据的信息,它决定了数据将往哪里存储,从哪里读取。传统的存储系统通过维护一张集中的查找表来跟踪它们的元数据。也就是说,客户端每次发出读写操作请求时,存储系统首先要查找这个巨大的元数据表,得到结果之后它才能执行客户端请求的操作。对于一个小的存储系统而言,你或许不会感觉到性能问题,但对于一个大的存储集群来说,你将会受制于这种方法的性能限制。它也会限制系统的扩展性。
4、Ceph中的数据副本
Ceph没有采用传统的存储架构,而是用下一代架构完全重塑了它。Ceph引入了一个叫CRUSH的新算法,而不是保存和操纵元数据。CRUSH是Controlled Replication Under Scalable Hashing的缩写。
CRUSH算法在后台计算数据存储和读取的位置,而不是为每个客户端请求执行元数据表的查找。通过动态计算元数据,Ceph也就不需要管理一个集中式的元数据表。现代计算机计算速度极快,能够非常快地完成CRUSH查找。另外,利用分布式存储的功能可以将一个小的计算负载分布到集群中的多个节点。CRUSH清晰的元数据管理方法比传统存储系统的更好。
**CRUSH会以多副本的方式保存数据,以保证在故障区域中有些组件故障的情况下数据依旧可用。**用户在Ceph的CRUSH map中可以自由地为他们的基础设施定义故障区域。这也就使得Ceph管理员能够在自己的环境中高效地管理他们的数据。CRUSH使得Ceph能够自我管理和自我疗愈。当故障区域中的组件故障时,CRUSH能够感知哪个组件故障了,并确定其对集群的影响。无须管理员的任何干预,CRUSH就会进行自我管理和自我疗愈,为因故障而丢失的据数执行恢复操作。CRUSH根据集群中维护的其他副本来重新生成丢失的数据。在任何时候,集群数据都会有多个副本分布在集群中。
使用RAID技术修复多个大硬盘是一个很繁琐的过程。另外,RAID需要很多整块的磁盘来充当备用盘。这也会影响到TCO,如果你不配置备用盘,将会将会遇到麻烦。RAID机制要求在同一个RAID组中的磁盘必须完全相同。如果你改动了磁盘容量、转速和磁盘类型,则你可能要面临惩罚。这样做将会对于存储系统的容量和性能产生不利影响。
TCO (Total Cost of Ownership ),即总拥有成本,包括产品采购到后期使用、维护的成本。这是一种公司经常采用的技术评价标准。由于常见的RAID5、6、10等阵列方式需要使用磁盘作为镜像盘或者热备盘,因此如果你买了10块10T的硬盘共计100T空间,使用阵列后会导致最后可以使用的硬盘容量小于100T。当然你也可以使用诸如RAID0之类的不损失空间的阵列方式,但是这样会导致数据的安全性大大地降低。
基于RAID的企业级存储系统通常都需要昂贵的硬件RAID卡,这也增加了系统总成本。
RAID系统最大的限制因素是它只能防止磁盘故障,而不能为网络、服务器硬件、OS、交换设备的故障或者区域灾害提供保护措施。
RAID最多能为你提供防止两个磁盘故障的措施。在任何情况下你无法容忍超过两个的磁盘故障。
Cpeh是一个软件定义的存储,因此它不需要任何特殊硬件来提供数据副本功能。另外,数据副本级别可以通过命令高度定制化。这也就意味着Ceph存储管理员能够轻松地根据自身需要和底层基础设施特点来管理副本策略。
这样的恢复操作不需要任何热备磁盘;数据只是简单地复制到Ceph集群中其他的磁盘上。
除了数据副本方法外,Ceph还支持其他用于保证数据可靠性的方法,比如纠删码技术。纠删码方式下,毁损的数据借助纠删码计算通过算法进行恢复或再次生成。
5、Ceph的存储兼容性
Ceph是一个完备的企业级存储系统,它支持多种协议以及访问方式,主要可以分为块、文件和对象存储三大类。
5.1 Ceph块存储
块存储是存储区域网络中使用的一个数据存储类别。在这种类型中,数据以块的形式存储在卷里,卷会挂接到节点上。它可以为应用程序提供更大的存储容量,并且可靠性和性能都更高。这些块形成的卷会映射到操作系统中,并被文件系统层控制。
Ceph引入了一个新的RBD协议,也就是Ceph块设备(Ceph Block Device)。
RBD块呈带状分布在多个Ceph对象之上,而这些对象本身又分布在整个Ceph存储集群中,因此能够保证数据的可靠性以及性能。
几乎所有的Linux操作系统发行版都支持RBD。除了可靠性和性能之外,RBD也支持其他的企业级特性,例如完整和增量式快照,精简的配置,写时复制(copy-on-write)式克隆,以及其他特性。RBD还支持全内存式缓存,这可以大大提高它的性能。Ceph RBD支持的最大镜像为16EB。在OpenStack中,可以通过cinder(块)和glance(image)组件来使用Ceph块设备。这样做可以让你利用Ceph块存储的copy-on-write特性在很短的时间内创建上千个VM。
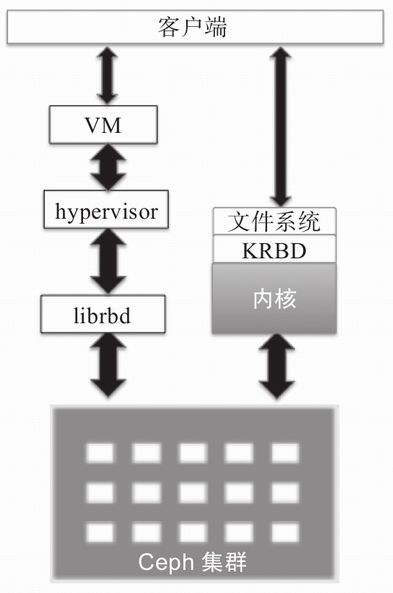
5.2 Ceph文件存储
Ceph文件系统(也就是CephFS)是一个兼容POSIX的文件系统,它利用Ceph存储集群来保存用户数据。CephFS将数据和元数据分开存储,为上层的应用程序提供较高的性能以及可靠性。
Linux内核驱动程序支持CephFS,这也使得CephFS高度适用于各大Linux操作系统发行版。
在Cpeh集群内部,Ceph文件系统库(libcephfs)运行在RADOS库(librados)之上,后者是Ceph存储集群协议,由文件、块和对象存储共用。要使用CephFS,你的集群节点上最少要配置一个Ceph元数据服务器(MDS)。然而,需要注意的是,单一的MDS服务器将成为Ceph文件系统的单点故障。MDS配置后,客户端可以采用多种方式使用CephFS。如果要把Ceph挂载成文件系统,客户端可以使用本地Linux内核的功能或者使用Ceph社区提供的ceph-fuse(用户空间文件系统)驱动。除此之外,客户端可以使用第三方开源程序,例如NFS的Ganesha和SMB/CIFS的Samba。

5.3 Ceph对象存储
对象存储是一种以对象形式而不是传统文件和块形式存储数据的方法。
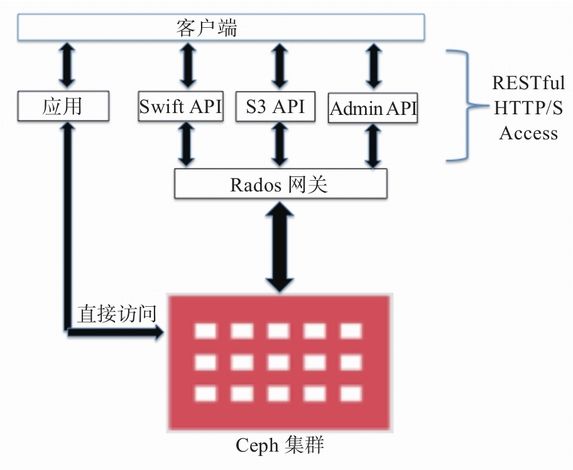
Ceph是一个分布式对象存储系统,通过它的对象网关(object gateway),也就是RADOS网关(radosgw)提供对象存储接口。RADOS网关利用librgw(RADOS网关库)和librados这些库,允许应用程序跟Ceph对象存储建立连接。
RADOS网关提供RESTful接口让用户的应用程序将数据存储到Ceph集群中。RADOS网关接口满足以下特点。
- 兼容Swift:这是为OpenStack Swift API提供的对象存储功能。
- 兼容S3:这是为Amazon S3 API提供的对象存储功能。
- Admin API:这也称为管理API或者原生API,应用程序可以直接使用它来获取访问存储系统的权限以管理存储系统。
要访问Ceph的对象存储系统,也可以绕开RADOS网关层,这样更灵活并且速度更快。librados软件库允许用户的应用程序通过C、C++、Java、Python和PHP直接访问Ceph对象存储。Ceph对象存储具备多站点(multisite)的能力,也就是说它能为灾难恢复提供解决方案。通过RADOS或者联合网关可以配置多站点的对象存储。
6、其他存储方案
6.1 GPFS/通用并行文件系统
GPFS(General Parallel File System,通用并行文件系统)是一个分布式文件系统,由IBM开发及拥有。这是一个专有、闭源的存储系统,这使得它缺少吸引力并且难以适应。存储硬件加上授权以及支持成本使得它非常昂贵。另外,它提供的存储访问接口非常有限;它既不能提供块存储,也不能提供RESTful接口来访问存储系统,因此这是一个限制非常严格的系统。甚至最大的数据副本数都限制只有3个,这在多个组件同时故障的情形下降低了系统的可靠性。
6.2 iRDOS
iRDOS是面向规则的数据系统的代表,它是依据第三条款(3-clause)BSD协议发布的开源数据管理软件。iRDOS不是一个高度可靠的存储系统,因为它的iCAT元数据服务器是单点(single point of failure,SPOF),并且它不提供真正的HA。另外,它提供的存储访问接口很有限;既不能提供块存储,也不能提供RESTful接口来访问存储系统,因此这是一个限制非常严格的系统。它更适合于存储少量大文件,而不是同时存储小文件和大文件。iRdos采用传统的工作方式,维护一个关于物理位置(与文件名相关联)的索引。由于多个客户端都需要从元数据服务器请求文件位置,使得元数据服务器需要承受更多的计算负载,从而导致单点故障以及性能瓶颈。
6.3 HDFS
HDFS是一个用Java写的并且为Hadoop框架而生的分布式可扩展文件系统。HDFS不是一个完全兼容POSIX的文件系统,并且不支持块存储,这使得它的适用范围不如Ceph。HDFS的可靠性不需要讨论,因为它不是一个高度可用的文件系统。HDFS中的单点故障以及性能瓶颈主要源于它单一的NameNode节点。它更适合于存储少量大文件,而不是同时存储小文件和大文件。
6.4 Lustre
Lustre是一个由开源社区推动的并行分布式文件系统,依据GNU(General Public License,通用公共许可证)发布。在Lustre中,由单独一个服务器负责存储和管理元数据。因此,从客户端来的所有I/O请求都完全依赖于这个服务器的计算能力,但对企业级计算来说通常这个服务器的计算能力都比较低。与iRDOS和HDFS类似,Lustre适合于存储少量大文件,而不是同时存储小文件和大文件。与iRDOS类似,Lustre管理一个用于映射物理位置和文件名的索引文件,这就决定了它是一个传统的架构,而且容易出现性能瓶颈。Lustre不具备任何节点故障检测和纠正机制。在节点出现故障时,客户端只能自行连接其他节点。
6.5 Gluster
GlusterFS最初由Gluster公司开发,该公司2011年被Red Hat收购。GlusterFS是一个横向扩展的网络附加(network-attached)文件系统。在Gluster中,管理员必须明确使用哪种安置策略来将数据副本存储到不同地域的机架上。Gluster本身不内置块访问、文件系统和远程副本,而是以扩展(add-ons)的方式支持。