【项目】Java API站内搜索引擎
- 1.项目目标
- 2.项目过程
-
- 2.1预处理
- 2.2构建索引
-
- 2.2.1正排索引
-
- 查询
- 添加
- 2.2.2倒排索引
-
- 查询
- 添加
- 2.2.3保存到本地
- 2.2.4从本地加载索引
- 2.2.5性能优化
-
- 多线程
- 解决线程安全问题
- 首次制作索引比较慢
- 缓存
- 2.3搜索模块
-
- 2.3.1划分关键词
-
- 加载索引、停用词
- 分词
- 2.3.2触发文档
- 2.3.3权重排序
-
- 权重合并
- 降序排序
- 2.3.4合并返回结果
-
- 生成概述
- 2.4前后端交互
- 2.5展示模块
- 3.开发问题
-
- 3.1索引构建模块
- 3.2搜索模块
- 4.项目难点
- 5.项目总结
搜索引擎是许多APP所需要的功能,对于我们来说,要想实现一个全网的搜索引擎是比较困难且复杂的。但是实现一个站内搜索引擎的逻辑却并不复杂,因为数据是垂直的,数据量也更小。在我们学习Java的过程中,想必大家不少查阅Java的API文档,那么下面我们就对Java API文档实现一个搜索引擎吧。
1.项目目标
Overview (Java Platform SE 8 ) (oracle.com)
什么?!Java官方文档居然没有搜索框,那我们搜索需要知道的类时岂不是很麻烦?既然没有,那我们就“无中生有”,造一个搜索功能出来。同时也考察一下自己对于搜索引擎背后的原理以及锻炼一下SpringBoot的相关技能。
2.项目过程

2.1预处理
Java API文档里面每一个类对应的是一个HTML文件,为了实现搜索功能,我们需要对其进行扫描。去除html文件中的标签并进行数据清洗。
Parser类
-
枚举html文件,放到arrayList集合里面。
private void enumFile(String inputPath, ArrayList<File> fileList){ File rootPath=new File(inputPath); File[] files=rootPath.listFiles(); for (File f:files) { //目录递归调用 if(f.isDirectory()){ enumFile(f.getAbsolutePath(),fileList); }else { if(f.getAbsolutePath().endsWith(".html")){ fileList.add(f); } } } }public void runByThread() throws InterruptedException { long beg = System.currentTimeMillis(); System.out.println("索引制作开始!"); //1.枚举出所有文件 ArrayList<File> files=new ArrayList<>(); enumFile(INPUT_PATH,files); //2.循环遍历文件 CountDownLatch latch=new CountDownLatch(files.size()); ExecutorService executorService= Executors.newFixedThreadPool(6); for(File f:files){ executorService.submit(new Runnable() { @Override public void run() { System.out.println("解析 " + f.getAbsolutePath()); parseHTML(f); latch.countDown(); } }); } latch.await(); executorService.shutdown(); //3.保存索引 index.save(); long end = System.currentTimeMillis(); System.out.println("索引制作完毕! 消耗时间: " + (end - beg) + "ms"); } -
解析每个html文件,得到标题、URL、正文。
-
URL:官方api路径 + 本地路径…/api/后面部分
-
正文:通过
isCopy标志去掉HTML中的标签:- 当前字符为’>',isCopy置为true
- 当前字符为’<',isCopy置为false
isCopy==false说明当前是标签,不予保存;isCopy==true说明当前是正文,进行保存
-
标题:HTML文件名去掉后缀
public String parseURL(File f) { String part1="https://docs.oracle.com/javase/8/docs/api/"; String part2=f.getAbsolutePath().substring(INPUT_PATH.length()); return part1+part2; } public String parseContent(File f) { try(BufferedReader fileReader=new BufferedReader( new FileReader (f),1024*1024)) { boolean isCopy=true; StringBuilder content=new StringBuilder(); while (true){ int ret=fileReader.read(); //非法字符 if(ret==-1){ break; } //合法字符 char c=(char) ret; if(isCopy){ //开关打开,普通字符拷贝到content if(c=='<'){ isCopy=false; continue; } if(c=='\n' || c=='\r'){ // \r是回车 //把换 行替换成空格 不然全是空白 c=' '; } //其他字符直接进行拷贝即可 content.append(c); }else { //如果是关闭的状态,就不拷贝,直到遇到> if(c=='>'){ isCopy=true; } } } return content.toString(); } catch (IOException e) { e.printStackTrace(); } return ""; } private String parseTitle(File f) { String name=f.getName(); return name.substring(0,name.length()-".html".length()); }正则表达式:
使用单个字符串来描述、匹配一系列匹配某个句法规则的字符串,通常被用来检索、替换那些符合某个模式(规则)的文本。
该链接包含了常用的正则表达式
//解析正文第二种方式 public String parseContentByRegex(File f){ String content=readFile(f); //2.替换掉script标签 content= content.replaceAll(" -
2.2构建索引
Index类
正排索引:根据文档ID寻找文档内容
倒排索引:根据关键字寻找文档ID
从正排索引和倒排索引的概念就能联想到整个过程:
输入内容 -> 构建倒排索引 ->得到文档ID -> 根据正排索引得到要查的内容
2.2.1正排索引
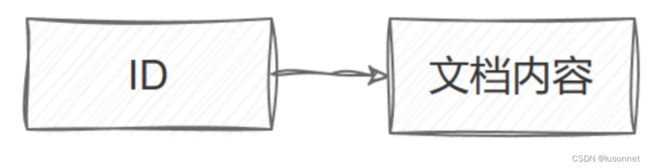
private ArrayList<DocInfo> forwardIndex =new ArrayList<>();
使用ArrayList存储文档集合
查询
public DocInfo getDocInfo(int docId){
return forwardIndex.get(docId);
}
添加
docId即为ArrayList长度。
private DocInfo buildForward(String title, String url, String content) {
DocInfo docInfo=new DocInfo();
docInfo.setTitle(title);
docInfo.setUrl(url);
docInfo.setContent(content);
synchronized (locker1){
docInfo.setDocId(forwardIndex.size());
forwardIndex.add(docInfo);
}
return docInfo;
}
2.2.2倒排索引
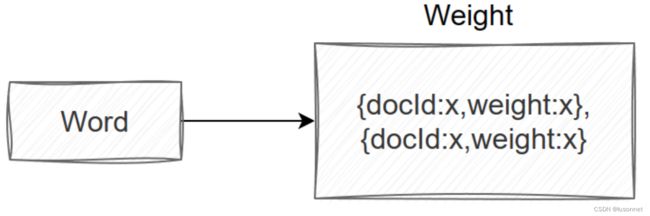
查询词与文章是一对多的关系,因此我们使用HashMap来存储倒排索引。
private HashMap<String,ArrayList<Weight>> invertedIndex=new HashMap<>();

查询词与文档是一对多的关系,因此我们使用HashMap来保存倒排索引。
查询
public List<Weight> getInverted(String term){
return invertedIndex.get(term);
}
添加
private void buildInverted(DocInfo docInfo) {
.....//
.....//
}
倒排索引的添加是整个项目中稍微复杂的一个功能,现在我们来介绍该功能:

首先建立一个类
WordCount记录每个查询词在title,content中出现的数量,以便遍历一次就能同时统计两种数量。HashMap<String,WordCount> wordCountHashMap=new HashMap<>();
-
分词:
对于输入内容进行分词,由于分词的代码实现较为复杂,在本次项目中并没有实现该功能,而是使用第三方库ansj来实现分词。
-
针对标题分词
List<Term> terms=ToAnalysis.parse(docInfo.getTitle()).getTerms(); -
针对正文分词
terms =ToAnalysis.parse(docInfo.getContent()).getTerms();
-
-
遍历分词结果,统计每个词出现次数,将结果存入wordCountHashMap里面
for(Term term:terms){ String word=term.getName(); WordCount wordCount= wordCountHashMap.get(word); if(wordCount==null){ WordCount newWordCount=new WordCount(); newWordCount.titleCount=1; newWordCount.contentCount=0; wordCountHashMap.put(word,newWordCount); }else { wordCount.titleCount+=1; } }for(Term term:terms){ String word=term.getName(); WordCount wordCount=wordCountHashMap.get(word); if(wordCount==null){ WordCount newWord=new WordCount(); newWord.titleCount=0; newWord.contentCount=1; wordCountHashMap.put(word,newWord); }else { wordCount.contentCount+=1; } } -
设置权重:
title * 10 + contentfor(Map.Entry<String,WordCount> entry : wordCountHashMap.entrySet()){ Weight weight = new Weight(); weight.setDocID(docInfo.getDocID()); weight.setWeight(entry.getValue().titleCount*10+entry.getValue().contentCount); ArrayList<Weight> invertWeight = invertIndex.get(entry.getKey()); if(invertWeight == null){ // 不存在:构建一个新的键值对 ArrayList<Weight> weightList = new ArrayList<>(); weightList.add(weight); invertIndex.put(entry.getKey(),weightList); }else{ // 存在:将当前文档的权重加在倒排索引的后面 invertWeight.add(weight); }
2.2.3保存到本地
使用两个文件分别保存正排、倒排。由于Java API文档并不是经常改动,同时为了加快启动速度,不拖慢服务器的启动,我们可以事先构建好索引,让构建索引成为一个独立的行动。
保存到本地需要进行序列化,将索引结构变成字符串写入文件。在本次方法中,使用JSON格式来进行序列化或反序列化。
public void save(){
long beg = System.currentTimeMillis();
System.out.println("保存索引开始!");
File indexPathFile=new File(INDEX_PATH);
if(!indexPathFile.exists()){
indexPathFile.mkdirs();
}
File forwardIndexFile=new File(INDEX_PATH+"forward.txt");
File invertedIndexFile=new File(INDEX_PATH+"inverted.txt");
try {
objectMapper.writeValue(forwardIndexFile, forwardIndex);
objectMapper.writeValue(invertedIndexFile,invertedIndex);
} catch (IOException e) {
e.printStackTrace();
}
long end = System.currentTimeMillis();
System.out.println("保存索引完成! 消耗时间: " + (end - beg) + " ms");
}
2.2.4从本地加载索引
public void load(){
long beg = System.currentTimeMillis();
System.out.println("加载索引开始");
File forwardIndexFile=new File(INDEX_PATH+"forward.txt");
File invertedIndexFile=new File(INDEX_PATH+"inverted.txt");
try {
forwardIndex =objectMapper.readValue(forwardIndexFile,new TypeReference<ArrayList<DocInfo>>(){});
invertedIndex=objectMapper.readValue(invertedIndexFile, new TypeReference<HashMap<String, ArrayList<Weight>>>() {});
}catch (IOException e){
e.printStackTrace();
}
long end = System.currentTimeMillis();
System.out.println("加载索引结束! 消耗时间: " + (end - beg) + " ms");
}
2.2.5性能优化
多线程
在进行数据预处理的时候,我们解析HTML文件时发现时间过久,而解析文件这一动作是可以不分时间先后,也就是说是可以异步执行的,因此我们引入线程池ExecutorService,在设定线程池的线程数目时通常采用压测和经验结合的方式来设定。
值得注意的是:
ExecutorService在使用完毕时,我们应该要关闭它才能保证线程不会继续保持运行状态,否则会引发一些并发风险。在通过mian()方法启动程序时,如果主线程已经走到最后了,但是此时还有ExecutorService存在于程序中,程序会继续保持运行状态,存在于ExecutorService中的线程会阻止虚拟机关闭。为了关闭需要调用shutdown()方法,当然仅仅是用这个方法是不行的,因为ExecutorService并不会马上关闭,只是不再接收新的任务,只有等到所有的线程结束执行当前任务,才会真正关闭。
为了实现立刻关闭ExecutorService,其实还可以使用shutdownNow() 方法,不过该方法会强制关闭,跳过所有已经提交但是没有运行的任务。这其实不符合我们的期望,因此我们就引入了CountDownLatch。
CountDownLatch用法:初始化时,指定有多少个文件,每一个文件解析完都调用
.countDown()方法通知CountDown(CountDown - 1)。调用await()方法实现阻塞等待,作用是直到所有任务都执行结束,阻塞等待结束。
线程是否需要关闭?
通过查阅资料,ExecutorService创建出来的线程,都默认是非守护线程。为了不影响进程结束,可以使用两种方法:
- 使用
setDaemon方法手动设置,变成守护线程 - 调用
shutdown(),手动将线程池的所有线程都干掉
代码实现:
public void runByThread() throws InterruptedException {
long beg = System.currentTimeMillis();
System.out.println("索引制作开始!");
//1.枚举出所有文件
ArrayList<File> files=new ArrayList<>();
enumFile(INPUT_PATH,files);
//2.循环遍历文件
CountDownLatch latch=new CountDownLatch(files.size());
ExecutorService executorService= Executors.newFixedThreadPool(6);
for(File f:files){
executorService.submit(new Runnable() {
@Override
public void run() {
System.out.println("解析 " + f.getAbsolutePath());
parseHTML(f);
latch.countDown();
}
});
}
latch.await();
executorService.shutdown();
//3.保存索引
index.save();
long end = System.currentTimeMillis();
System.out.println("索引制作完毕! 消耗时间: " + (end - beg) + "ms");
}
解决线程安全问题
多个线程同时操作同一个对象时,会引发线程安全问题。进一步分析代码得知,在parseHTML方法中,最后一步是将解析的内容加到索引中,在往正排索引和倒排索引中加入值时,不同的线程会同时操作正排索引和倒排索引。因此,需要对其加锁。创建两个锁对象,完成加锁。
//创建两个锁对象
private Object locker1 = new Object();
private Object locker2 = new Object();
for(Map.Entry<String,WordCount>entry : wordCountHashMap.entrySet()){
//先根据这个词,去倒排索引中查一查
//倒排拉链
synchronized (locker2){
//....
//....
}
}
private DocInfo buildForward(String title, String url, String content) {
///....
synchronized (locker1){
///....
}
}
首次制作索引比较慢
在开机之后,首次制作索引非常慢。但是第二次、第三次制作索引就快了。重启之后,第一次制作又会特别慢。计算机读取文件,是个开销比较大的操作,简单猜测。是否开机之后,首次运行时读取文件的数据特别慢呢?
通过给parserContent和addDoc,都加上时间,来观察一下这里的时间变化。
定义两个时间,计算读文件和addDoc的执行时间。由于parserContent和addDoc方法是在循环中调用,只计算一次的执行时间很短,就需要计算累计和。由于这块涉及到多线程环境,在进行时间累加时,要注意线程安全问题。使用AtomicLong可以避免线程安全问题。
// 使用AtomicLong可以避免线程安全问题,也可以不必加锁(加锁本身也会有不小的开销)
private AtomicLong t1 = new AtomicLong(0);
private AtomicLong t2 = new AtomicLong(0);
获取读文件和addDoc操作执行的时间差,将其累加到t1和t2中。
long beg = System.nanoTime(); // 纳秒级别。
String content = parserContent(file);
long mid = System.nanoTime();
// 将解析的内容加到索引中
index.addDoc(title,content,url);
long end = System.nanoTime();
t1.addAndGet(mid-beg);
t2.addAndGet(end-mid);
先重启电脑再运行,通过分析运行时间,我们可以明显的看到解析正文的时间要比addDoc的时间长很多。
接着运行第二次和第三次,我们可以观察到,解析正文的时间变短了。
缓存
解析正文的核心操作是读取文件。
首次运行时,当前的文件都没有在内存上缓存,读取时只能直接从硬盘上读取,比较低效。由于操作系统会对经常读取的文件进行缓存。后面再运行的时候,这些文档在操作系统中已经有了一份缓存(内存中),直接读内存的缓存,而不是直接读硬盘,因此速度会快很多。
每次操作都可能会触发磁盘IO。由于读磁盘是一个比较耗时的操作。我们可以使用BufferedReader标准库中提供的一个FileReader的辅助类。BufferedReader内部内置了缓冲区,可以将FileReader的数据提前放到缓存区中,减少了读磁盘的次数。假设现在有100个字节,使用FileReader.read,是每次读一个字节,读100次。使用bufferedReader.read()就可以理解为一次读100个字节,分一次读。bufferedReader.read()可以读取的文件大小是可以自定义的。
public String readFile(File f){
try (BufferedReader bufferedReader=new BufferedReader(new FileReader(f))){
StringBuilder content=new StringBuilder();
while (true){
int ret=bufferedReader.read();
if(ret==-1){
break;
}
char c=(char)ret;
if(c=='\n'||c=='\r'){
c=' ';
}
content.append(c);
}
return content.toString();
}catch (IOException e){
e.printStackTrace();
}
return "";
}
2.3搜索模块
主要流程
- 分词:对输入的内容进行划分
- 触发:对每个分词建立倒排索引
- 排序:对查询出来的内容进行降序排序
- 包装:将排序后的结果进行正排索引,获取到每个文档的详细信息后包装返回
2.3.1划分关键词
划分关键词并不是单单去掉空格,同时还要去掉关键词里面没有具体含义的单词。比如a,aaa,wow…去除思路:使用HashSet存储停用词,判断分词结果的词是否在HashSet中存在。
private HashSet<String> stopWords = new HashSet<>();
加载索引、停用词
网络上有许多停用词文档,我们从中拷贝一份即可。
public DocSearcher(){
index.load();
loadStopWords();
}
public void loadStopWords(){
try (BufferedReader reader=new BufferedReader(new FileReader(STOP_WORD))) {
while (true) {
String line = reader.readLine();
if (line == null) {
//读完了
break;
}
stopWords.add(line);
}
}catch (IOException e){
e.printStackTrace();
}
}
分词
public List<Result>search(String query){
//1。针对查询词分词
List<Term> oldTerms= ToAnalysis.parse(query).getTerms();
List<Term> terms=new ArrayList<>();
//针对分词结果,使用暂停词过滤
for(Term term:oldTerms){
if(stopWords.contains(term.getName())){
continue;
}
terms.add(term);
}
}
2.3.2触发文档
-
针对分词结果查倒排
一个词对应一个ArrayList,多个词使用List

List<List<Weight>> TermResult=new ArrayList<>();for(Term term:terms){ String word=term.getName(); List<Weight>invertedList=index.getInverted(word); if(invertedList==null){ //说明这个词在所有文档中都不存在 continue; } TermResult.add(invertedList);
2.3.3权重排序
假设我们输入的查询语句是Spring and Java,分词结果是Spring 和Java,Spring和Java都在文档1中出现,调用invertByTerm()方法,查询Spring在文档1的权重是2,Java在文档1的权重是5.将文档1显示多次不太合理,我们需要得到文档1与整个查询语句的权重关系,查询语句在文档1的权重是7。因此,需要将分词结果触发出的相同文档, 进行权重合并。
List<List<Weight>> TermResult = new ArrayList<>(); List<Weight> allTermResult = mergeResult(TermResult);
可以看到,合并时操作的对象是List类型,因此我们需要通过操作二维数组来获取每一个元素。

通过新建一个Pos类,获取元素的位置:
static class Pos{
public int row;
public int col;
public Pos(int row,int col){
this.row = row;
this.col = col;
}
}
权重合并
合并思路:
使用target 表示合并结果。
List<Weight> target = new ArrayList<>();
-
对每一个单词的查询结果按照id升序排行
for(List<Weight> curRow:source){ curRow.sort(new Comparator<Weight>() { @Override public int compare(Weight o1, Weight o2) { return o1.getDocId() - o2.getDocId(); } }); } -
多路归并,使用优先队列进行合并,比较规则按照docId小的优先
-
将第一列元素放到优先级队列中
List<Weight> target=new ArrayList<>(); PriorityQueue<Pos> queue=new PriorityQueue<>(new Comparator<Pos>() { @Override public int compare(Pos o1, Pos o2) { Weight w1=source.get(o1.row).get(o1.col); Weight w2=source.get(o2.row).get(o2.col); return w1.getDocId()-w2.getDocId(); } }); for(int row=0;row<source.size();row++){ queue.offer(new Pos(row,0)); } -
将堆顶元素弹出,判断与target中最后一个元素的id关系,如果相等就合并,不相等就将其加到target中
if(target.size()>0){ Weight lastWeight = target.get(target.size()-1); if(lastWeight.getDocId() == curWeight.getDocId()){ //合并 lastWeight.setWeight(lastWeight.getWeight() + curWeight.getWeight()); }else { //文档id不同,就直接把curweight插入到target末尾 target.add(curWeight); } }else { //target没东西直接插入就行 target.add(curWeight); } -
当前元素处理完后,移动到该行的下一个元素。如果超过这一行的列数,进入下一次循环
Pos newPos=new Pos(minPos.row, minPos.col+1); if(newPos.col>=source.get(newPos.row).size()){ continue; } -
如果没超过,就将该元素加入到优先级队列中
queue.offer(newPos);
-
降序排序
allTermResult.sort(new Comparator<Weight>() {
@Override
public int compare(Weight o1, Weight o2) {
return o2.getWeight()-o1.getWeight();
}
});
2.3.4合并返回结果
List<Result> results=new ArrayList<>();
for(Weight weight:allTermResult){
DocInfo docInfo= index.getDocInfo(weight.getDocId());
Result result=new Result();
result.setTitle(docInfo.getTitle());
result.setUrl(docInfo.getUrl());
result.setDesc(GenDesc(docInfo.getContent(),terms));
results.add(result);
}
return results;
在用户查询时要提高用户体验,查出来的每个结果都要在前端页面中显示一段概述。因此,我们设定:
在根据content生成desc时,遍历分词结果,看哪个词在content中出现。找到这个词第一次出现的位置。以第一次出现的位置为基准,向前找60个字符,向后找160个字符,作为desc。
生成概述
分词表对词转小写了。因此,需要将content转为小写再查询。
为了避免查询List出现ArrayList这样的情况,查询时要进行全字匹配。使用List周围加空格方式去查询,就能避免这种情况。
为了能在前端的展示页面中体现出查询词,可以使用正则表达式给查询词加上标红标签。
private String GenDesc(String content, List<Term> terms) {
//遍历分词结果
int firstPos = -1;
for(Term term : terms){
String word = term.getName();
content = content.toLowerCase().replaceAll("\\b" + word + "\\b", " " + word + " ");
firstPos = content.toLowerCase().indexOf(" "+word+" ");
if(firstPos >= 0){
break;
}
}
if(firstPos == -1){
if (content.length() > 160) {
return content.substring(0, 160) + "...";
}
return content;
}
String desc = "";
int descBeg=firstPos < 60 ? 0 : firstPos - 60;
if(descBeg+160 > content.length()){
desc = content.substring(descBeg);
}else {
desc = content.substring(descBeg,descBeg + 160) + "....";
}
for(Term term : terms){
String word = term.getName();
desc = desc.replaceAll("(?i) "+word+" "," "+word+" ");
}
return desc;
}
2.4前后端交互
请求格式:
GET /search?query=xxx HTTP/1.1
成功响应格式
HTTP/1.1 200 OK
Content-Type: application/json; charset=UTF-8;
[
{
"title":xxx,
"url":xxx,
"desc":xxx,
},
{
...
},
...
]
失败响应格式
HTTP/1.1 404
交互模块
@RestController
public class docSearcherController {
private static DocSearcher searcher=new DocSearcher();
private ObjectMapper mapper=new ObjectMapper();
@RequestMapping(value = "/searcher",produces = "application/json;charset=utf-8")
@ResponseBody
public String search(@RequestParam("query")String query) throws JsonProcessingException {
List<Result> resultList=searcher.search(query);
return mapper.writeValueAsString(resultList);
}
}
2.5展示模块
使用ajax构造get请求
<script src="/js/jquery.js">script>
<script>
let input = document.querySelector(".header input");
input.onfocus = function(){
if(input.value == "请输入需要搜索的内容")
input.value = "";
input.style.color = "black";
}
input.onblur = function(){
if(input.value == "")
input.value = "请输入需要搜索的内容";
input.style.color = "#999";
}
let button = document.querySelector("#search-btn");
button.onclick = function(){
let input = document.querySelector(".header input");
let query = input.value;
console.log("query=" + query);
$.ajax({
type: "get",
url: "searcher?query=" + query,
success: function(data,status){
//console.log(data);
buildResult(data);
}
})
}
function buildResult(data){
let result = document.querySelector('.result');
result.innerHTML = '';
//显示搜索结果条数
let countDiv = document.createElement('div');
countDiv.innerHTML='当前找到 '+ data.length + '个结果!';
countDiv.className = 'count';
result.appendChild(countDiv);
for(let item of data){
let itemDiv = document.createElement('div');
itemDiv.className = 'item';
let title = document.createElement('a');
title.href = item.url;
title.innerHTML = item.title;
title.target = '_blank';
itemDiv.appendChild(title);
let desc = document.createElement('div');
desc.className = 'desc';
desc.innerHTML = item.desc;
itemDiv.appendChild(desc);
let url = document.createElement('div');
url.className = 'url';
url.innerHTML = item.url;
itemDiv.appendChild(url);
result.appendChild(itemDiv);
}
}
script>
3.开发问题
3.1索引构建模块
-
直接迭代遍历map无法成功,map没有实现Iterable接口,不可以迭代。遍历Map的四种方式:
-
for-each循环中使用
Map.entry实现Map的遍历,该方法比较常用,也是项目中倒排索引添加使用到的。通过此方法可以获得Map集合的键值对。for(Map.Entry<String,WordCount>entry:wordCountHashMap.entrySet()){ //String mapKey = entry.getKey(); //String mapValue = entry.getValue(); } } -
将Map集合中所有的键拿出来,组成一个Set集合,使用 for-each 循环遍历 key 或者 values,一般适用于只需要 Map 中的 key 或者 value 时使用。性能上比 entrySet 较好
Map<Student, String> map = new LinkedHashMap<>(); Set<Student> students = map.keySet(); for (Student s: students ) { System.out.println(s + ":" + map.get(s)); } -
将刚才的Set集合转化为Iterator迭代器对象,然后使用迭代器的迭代方法进行迭代
Iterator<Student> iterator = students.iterator(); while (iterator.hasNext()) { Student student = iterator.next(); System.out.println(student + ":" + map.get(student)); } -
将Map集合中所有的键拿出来组成一个Set的键的集合,然后将所有的值拿出来组成一个集合,然后分别将两个集合转化为数组,可以使用简单for循环遍历,也可以使用增强for循环遍历。
Collection<String> values = map.values(); Object[] objects = students.toArray(); Object[] objects1 = values.toArray(); for (int i = 0; i < objects.length; i++) { System.out.println(objects[i] + ":" + objects1[i]); }Map集合直接转换为数组不怕元素乱序?
Map集合使用的是HashMap的实现类LinkedhashMap,在自己的内部维护了一个双向链表,可以记录元素插入的顺序,以便进行迭代
-
3.2搜索模块
非贪婪匹配
<.*?>:去掉普通的标签(不去掉内容)
4.项目难点
-本项目的难点在于正排索引以及倒排索引的设计,首先需要记录每一篇文章的标题以及各个文章之间的分词,文章利用正则表达式进行单词的挑选,在设计正则表达式时是挺不容易的,最后通过查询搞清了正则表达式的一些相关用法。同时在搜索模块中使用缓存加快查询的速度,对多词查询的结果的展示进行了权重的聚合排序展示
5.项目总结
通过本次项目,最大的提升莫过于技术方面的提升,自己对于servlet和springboot框架的基本流程更加清楚。对于每一个数据背后所存在的意义,数据结构该怎么使用,在中间碰到了许许多多的错误,通过一点点的摸索,解决相关的问题,处理问题的能力以及手段有了进一步的提升。在索引模块利用正则表达式、HashMap、ArrayList等数据结构,结合多线程,实现了正排索引和倒排索引的制作,以及两种索引的保存和加载。