Python刷题系列(8)_Pandas_Dataframe
文章目录
- Pandas_Dataframe
-
- 1、按元素获取数组值的幂
- 2、从具有索引标签的字典数据创建数据帧
- 3、显示有关指定数据帧及其数据的基本信息摘要
- 4、获取给定数据帧的前 3 行
- 5、从给定的数据帧中选择两个指定的列
- 6、从给定的数据帧中选择指定的列和行
- 7、选择检查中尝试次数大于 2 的行
- 8、计算数据帧的行数和列数
- 9、打印数据缺失的行
- 10、打印行,数据在15到20之间
- 11、打印某一列的平均值
- 12、打印数据帧中多条件的行
- 13、将数据帧的数据更改
- 13、按“名称”降序,然后按升序按“分数”排序。
-
-
- 【1】pandas sort_values()方法的使用
-
- 14、添加新行和新列并删除新行和新列
- 15、从 DataFrame 列标题中获取列表
- 16、重命名给定数据帧的列
-
-
- 【2】rename()方法的使用
-
- 17、更改数据帧列的顺序
- 18、使用制表符分隔符将数据帧写入CSV文件
- 19、将所有 NaN 值替换为数据帧列中的 Zero
- 20、重置数据帧的索引
-
-
- 【3】Pandas reset_index()用法
-
- 21、对一列或多列中的 NaN 值进行计数
- 22、以给定的比率划分数据帧
- 23、将两个系列组合成一个数据帧
- 24、将数据帧列类型从字符串转换为日期时间
- 25、检查数据帧中是否存在给定列
- 26、将数据追加到空数据帧
- 27、转换给定列的数据类型(浮点型到整数型)
- 28、将给定数据帧中列的连续值转换为分类
- 29、给定数据帧的反向顺序
- 30、为给定数据帧的所有列添加前缀或后缀
Pandas_Dataframe

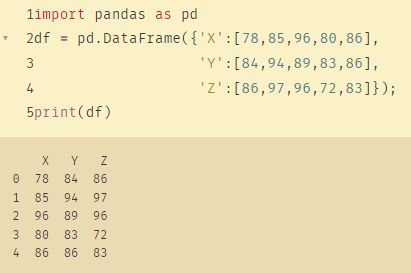
1、按元素获取数组值的幂
编写一个 Pandas 程序,以从元素上获取数组值的幂。
- 注意:第一个数组元素从第二个数组提升为幂
- 示例数据:
{'X':[78,85,96,80,86],
'Y':[84,94,89,83,86],
'Z':[86,97,96,72,83]}
- 预期输出:
X Y Z
0 78 84 86
1 85 94 97
2 96 89 96
3 80 83 72
4 86 86 83
解答:
import pandas as pd
df = pd.DataFrame({'X':[78,85,96,80,86],
'Y':[84,94,89,83,86],
'Z':[86,97,96,72,83]});
print(df)

2、从具有索引标签的字典数据创建数据帧
编写一个 Pandas 程序,以从具有索引标签的指定字典数据创建和显示 DataFrame。
示例数据帧:
exam_data =
{‘name’: [‘Anastasia’, ‘Dima’, ‘Katherine’, ‘James’, ‘Emily’, ‘Michael’, ‘Matthew’, ‘Laura’, ‘Kevin’, ‘Jonas’],
‘score’: [12.5, 9, 16.5, np.nan, 9, 20, 14.5, np.nan, 8, 19],
‘trys’: [1, 3, 2, 3, 2, 3, 1, 1, 2, 1],
‘qualify’: [‘yes’, ‘no’, ‘no’, ‘yes’, ‘yes’, ‘no’, ‘yes’, ‘no’, ‘yes’]}
labels = [‘a’, ‘b’, ‘c’, ‘d’, ‘e’, ‘f’, ‘g’, ‘h’, ‘i’, ‘j’]
import pandas as pd
import numpy as np
exam_data = {'name': ['Anastasia', 'Dima', 'Katherine', 'James', 'Emily', 'Michael', 'Matthew', 'Laura', 'Kevin', 'Jonas'],
'score': [12.5, 9, 16.5, np.nan, 9, 20, 14.5, np.nan, 8, 19],
'attempts': [1, 3, 2, 3, 2, 3, 1, 1, 2, 1],
'qualify': ['yes', 'no', 'yes', 'no', 'no', 'yes', 'yes', 'no', 'no', 'yes']}
labels = ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j']
df = pd.DataFrame(exam_data , index=labels)
print(df)

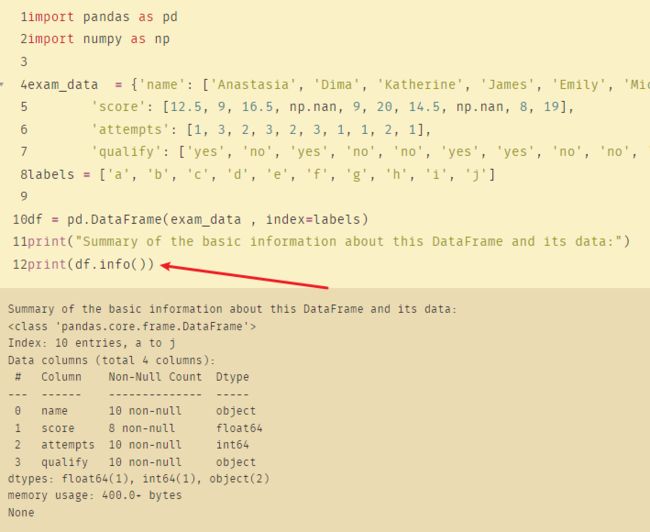
3、显示有关指定数据帧及其数据的基本信息摘要
编写 Pandas 程序以显示有关指定数据帧及其数据的基本信息的摘要。转到编辑器
- 示例Python字典数据和列表标签:
exam_data = {‘name’: [‘Anastasia’, ‘Dima’, ‘Katherine’, ‘James’, ‘Emily’, ‘Michael’, ‘Matthew’, ‘Laura’, ‘Kevin’, ‘Jonas’],
‘score’: [12.5, 9, 16.5, np.nan, 9, 20, 14.5, np.nan, 8, 19],
‘trys’: [1, 3, 2, 3, 2, 3, 1, 1, 2, 1],
‘qualify’: [‘yes’, ‘no’, ‘no’, ‘no’, ‘yes’, ‘no’, ‘yes’, ‘no’, ‘no’, ‘’ ‘yes’]}
标签 = [‘a’, ‘b’, ‘c’, ‘d’, ‘e’, ‘f’, ‘g’, ‘h’, ‘i’, ‘j’]
- 预期输出:
有关此 DataFrame 及其数据的基本信息摘要:
<类 ‘pandas.core.frame.DataFrame’>
索引: 10 个条目, a to j
数据列 (总共 4 列):
…dtypes: float64(1), int64(1), object(2)
内存使用情况: 400.0+ 字节
无
4、获取给定数据帧的前 3 行
- 示例Python字典数据和列表标签:
exam_data = {‘name’: [‘Anastasia’, ‘Dima’, ‘Katherine’, ‘James’, ‘Emily’, ‘Michael’, ‘Matthew’, ‘Laura’, ‘Kevin’, ‘Jonas’],
‘score’: [12.5, 9, 16.5, np.nan, 9, 20, 14.5, np.nan, 8, 19],
‘trys’: [1, 3, 2, 3, 2, 3, 1, 1, 2, 1],
‘qualify’: [‘yes’, ‘no’, ‘no’, ‘no’, ‘yes’, ‘no’, ‘yes’, ‘no’, ‘no’, ‘’ ‘yes’]}
标签 = [‘a’, ‘b’, ‘c’, ‘d’, ‘e’, ‘f’, ‘g’, ‘h’, ‘i’, ‘j’]
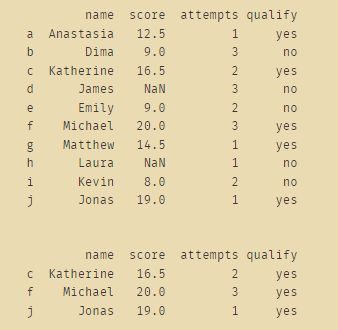
- 预期输出:
a 1 Anastasia yes 12.5
b 3 Dima no 9.0
c 2 Katherine yes 16.5
import pandas as pd
import numpy as np
exam_data = {'name': ['Anastasia', 'Dima', 'Katherine', 'James', 'Emily', 'Michael', 'Matthew', 'Laura', 'Kevin', 'Jonas'],
'score': [12.5, 9, 16.5, np.nan, 9, 20, 14.5, np.nan, 8, 19],
'attempts': [1, 3, 2, 3, 2, 3, 1, 1, 2, 1],
'qualify': ['yes', 'no', 'yes', 'no', 'no', 'yes', 'yes', 'no', 'no', 'yes']}
labels = ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j']
df = pd.DataFrame(exam_data , index=labels)
print(df)
print("\n")
print(df.iloc[:3])
print("\n")
print(df.head(3))
print("\n")
print(df.iloc[0:1,1:3])

5、从给定的数据帧中选择两个指定的列
编写一个 Pandas 程序,从以下数据帧中选择“名称”和“评分”列。
- 示例Python字典数据和列表标签:
exam_data = {'name': ['Anastasia', 'Dima', 'Katherine', 'James', 'Emily', 'Michael', 'Matthew', 'Laura', 'Kevin', 'Jonas'],
'score': [12.5, 9, 16.5, np.nan, 9, 20, 14.5, np.nan, 8, 19],
'trys': [1, 3, 2, 3, 2, 3, 1, 1, 2, 1],
'qualify': ['yes', 'no', 'no', 'no', 'yes', 'no', 'yes', 'no', 'no', '' 'yes']}
标签 = ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j']
- 预期输出:
a Anastasia 12.5
b Dima 9.0
c Katherine 16.5
...h Laura NaN
i Kevin 8.0
j Jonas 19.0
解答:
import pandas as pd
import numpy as np
exam_data = {'name': ['Anastasia', 'Dima', 'Katherine', 'James', 'Emily', 'Michael', 'Matthew', 'Laura', 'Kevin', 'Jonas'],
'score': [12.5, 9, 16.5, np.nan, 9, 20, 14.5, np.nan, 8, 19],
'attempts': [1, 3, 2, 3, 2, 3, 1, 1, 2, 1],
'qualify': ['yes', 'no', 'yes', 'no', 'no', 'yes', 'yes', 'no', 'no', 'yes']}
labels = ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j']
print(df)
print("\n")
df = pd.DataFrame(exam_data , index=labels)
print(df[['name', 'score']])

6、从给定的数据帧中选择指定的列和行
编写一个 Pandas 程序,从给定的数据帧中选择指定的列和行。转到编辑器
- 示例 Python 字典数据并列出标签:
从以下数据框中选择第 1、3、5、6 行中的“name”和“score”列。
exam_data = {'name': ['Anastasia', 'Dima', 'Katherine', 'James', 'Emily', 'Michael', 'Matthew', 'Laura', 'Kevin', 'Jonas'],
'score': [12.5, 9, 16.5, np.nan, 9, 20, 14.5, np.nan, 8, 19],
'trys': [1, 3, 2, 3, 2, 3, 1, 1, 2, 1],
'qualify': ['yes', 'no', 'yes', 'yes', 'no', 'yes', 'no', 'yes', 'yes']}
labels = ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j']
- 预期输出:
b 9.0 no
d NaN no
f 20.0 yes
g 14.5 yes
解答:
import pandas as pd
import numpy as np
exam_data = {'name': ['Anastasia', 'Dima', 'Katherine', 'James', 'Emily', 'Michael', 'Matthew', 'Laura', 'Kevin', 'Jonas'],
'score': [12.5, 9, 16.5, np.nan, 9, 20, 14.5, np.nan, 8, 19],
'attempts': [1, 3, 2, 3, 2, 3, 1, 1, 2, 1],
'qualify': ['yes', 'no', 'yes', 'no', 'no', 'yes', 'yes', 'no', 'no', 'yes']}
labels = ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j']
df = pd.DataFrame(exam_data , index=labels)
print(df)
print("\n")
print(df.iloc[[1, 3, 5, 6], [1, 3]])

7、选择检查中尝试次数大于 2 的行
编写 Pandas 程序,选择考试中尝试次数大于 2 的行。
- 示例Python字典数据和列表标签:
exam_data = {'name': ['Anastasia', 'Dima', 'Katherine', 'James', 'Emily', 'Michael', 'Matthew', 'Laura', 'Kevin', 'Jonas'],
'score': [12.5, 9, 16.5, np.nan, 9, 20, 14.5, np.nan, 8, 19],
'trys': [1, 3, 2, 3, 2, 3, 1, 1, 2, 1],
'qualify': ['yes', 'no', 'no', 'no', 'yes', 'no', 'yes', 'no', 'no', '' 'yes']}
标签 = ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j']
- 预期输出:
考试中的尝试次数大于 2,且名称分数尝试次数合格。
b Dima 9.0 3 no
d James NaN 3 no
f Michael 20.0 3 是
解答:
import pandas as pd
import numpy as np
exam_data = {'name': ['Anastasia', 'Dima', 'Katherine', 'James', 'Emily', 'Michael', 'Matthew', 'Laura', 'Kevin', 'Jonas'],
'score': [12.5, 9, 16.5, np.nan, 9, 20, 14.5, np.nan, 8, 19],
'attempts' : [1, 3, 2, 3, 2, 3, 1, 1, 2, 1],
'qualify': ['yes', 'no', 'yes', 'no', 'no', 'yes', 'yes', 'no', 'no', 'yes']}
labels = ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j']
df = pd.DataFrame(exam_data , index=labels)
print("Number of attempts in the examination is greater than 2:")
print(df[df['attempts'] > 2])
关键:df[df['attempts'] > 2]:df['attempts'] > 2判断每行是否满足该条件,若满足,则是True,我的理解是布尔索引。

8、计算数据帧的行数和列数
编写一个 Pandas 程序来计算 DataFrame 的行数和列数。转到编辑器
- 示例Python字典数据和列表标签:
exam_data = {‘name’: [‘Anastasia’, ‘Dima’, ‘Katherine’, ‘James’, ‘Emily’, ‘Michael’, ‘Matthew’, ‘Laura’, ‘Kevin’, ‘Jonas’],
‘score’: [12.5, 9, 16.5, np.nan, 9, 20, 14.5, np.nan, 8, 19],
‘trys’: [1, 3, 2, 3, 2, 3, 1, 1, 2, 1],
‘qualify’: [‘yes’, ‘no’, ‘no’, ‘no’, ‘yes’, ‘no’, ‘yes’, ‘no’, ‘no’, ‘’ ‘yes’]}
标签 = [‘a’, ‘b’, ‘c’, ‘d’, ‘e’, ‘f’, ‘g’, ‘h’, ‘i’, ‘j’]
- 预期输出:
行数: 10
列数: 4
关键:
【1】计算数据帧的行数:len(df.axes[0])
【2】计算数据帧的列数:len(df.axes[1])
import pandas as pd
import numpy as np
exam_data = {'name': ['Anastasia', 'Dima', 'Katherine', 'James', 'Emily', 'Michael', 'Matthew', 'Laura', 'Kevin', 'Jonas'],
'score': [12.5, 9, 16.5, np.nan, 9, 20, 14.5, np.nan, 8, 19],
'attempts': [1, 3, 2, 3, 2, 3, 1, 1, 2, 1],
'qualify': ['yes', 'no', 'yes', 'no', 'no', 'yes', 'yes', 'no', 'no', 'yes']}
labels = ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j']
df = pd.DataFrame(exam_data , index=labels)
total_rows=len(df.axes[0])
total_cols=len(df.axes[1])
print(df)
print("\n")
print("Number of Rows: "+str(total_rows))
print("Number of Columns: "+str(total_cols))

9、打印数据缺失的行
打印分数列中含有缺失数值的行
关键点:df[df['score'].isnull()]
import pandas as pd
import numpy as np
exam_data = {'name': ['Anastasia', 'Dima', 'Katherine', 'James', 'Emily', 'Michael', 'Matthew', 'Laura', 'Kevin', 'Jonas'],
'score': [12.5, 9, 16.5, np.nan, 9, 20, 14.5, np.nan, 8, 19],
'attempts': [1, 3, 2, 3, 2, 3, 1, 1, 2, 1],
'qualify': ['yes', 'no', 'yes', 'no', 'no', 'yes', 'yes', 'no', 'no', 'yes']}
labels = ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j']
df = pd.DataFrame(exam_data , index=labels)
print("Rows where score is missing:")
print(df[df['score'].isnull()])

10、打印行,数据在15到20之间
打印分数列中,数据在15到20之间的(含)
关键:df[df['score'].between(15, 20)]
import pandas as pd
import numpy as np
exam_data = {'name': ['Anastasia', 'Dima', 'Katherine', 'James', 'Emily', 'Michael', 'Matthew', 'Laura', 'Kevin', 'Jonas'],
'score': [12.5, 9, 16.5, np.nan, 9, 20, 14.5, np.nan, 8, 19],
'attempts': [1, 3, 2, 3, 2, 3, 1, 1, 2, 1],
'qualify': ['yes', 'no', 'yes', 'no', 'no', 'yes', 'yes', 'no', 'no', 'yes']}
labels = ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j']
df = pd.DataFrame(exam_data , index=labels)
print(df)
print("\n")
print(df[df['score'].between(15, 20)])
11、打印某一列的平均值
打印分数列的平均值
关键:df['score'].mean()
import pandas as pd
import numpy as np
exam_data = {'name': ['Anastasia', 'Dima', 'Katherine', 'James', 'Emily', 'Michael', 'Matthew', 'Laura', 'Kevin', 'Jonas'],
'score': [12.5, 9, 16.5, np.nan, 9, 20, 14.5, np.nan, 8, 19],
'attempts': [1, 3, 2, 3, 2, 3, 1, 1, 2, 1],
'qualify': ['yes', 'no', 'yes', 'no', 'no', 'yes', 'yes', 'no', 'no', 'yes']}
labels = ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j']
df = pd.DataFrame(exam_data , index=labels)
print(df)
print("\n")
print(df['score'].mean())

注:如果是求总和的话就把mean()改成sum()即可
12、打印数据帧中多条件的行
编写一个 Pandas 程序,以选择考试中尝试次数小于 2 且分数大于 15 的行。
关键:df[(df[‘attempts’] < 2) & (df[‘score’] > 10)]
注:多条件则必须要在条件外添加括号
import pandas as pd
import numpy as np
exam_data = {'name': ['Anastasia', 'Dima', 'Katherine', 'James', 'Emily', 'Michael', 'Matthew', 'Laura', 'Kevin', 'Jonas'],
'score': [12.5, 9, 16.5, np.nan, 9, 20, 14.5, np.nan, 8, 19],
'attempts': [1, 3, 2, 3, 2, 3, 1, 1, 2, 1],
'qualify': ['yes', 'no', 'yes', 'no', 'no', 'yes', 'yes', 'no', 'no', 'yes']}
labels = ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j']
df = pd.DataFrame(exam_data , index=labels)
print("attempts列小于2并且score列大于10的行:")
print(df[(df['attempts'] < 2) & (df['score'] > 10)])

13、将数据帧的数据更改
编写一个 Pandas 程序,将行 “d” 中的分数更改为 11.5。
关键:df.loc['d', 'score'] = 11.5
import pandas as pd
import numpy as np
exam_data = {'name': ['Anastasia', 'Dima', 'Katherine', 'James', 'Emily', 'Michael', 'Matthew', 'Laura', 'Kevin', 'Jonas'],
'score': [12.5, 9, 16.5, np.nan, 9, 20, 14.5, np.nan, 8, 19],
'attempts': [1, 3, 2, 3, 2, 3, 1, 1, 2, 1],
'qualify': ['yes', 'no', 'yes', 'no', 'no', 'yes', 'yes', 'no', 'no', 'yes']}
labels = ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j']
df = pd.DataFrame(exam_data , index=labels)
print("\nOriginal data frame:")
print(df)
print("\nChange the score in row 'd' to 11.5:")
df.loc['d', 'score'] = 11.5
print(df)

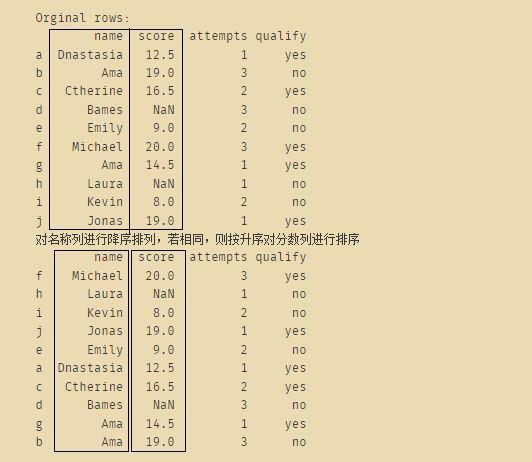
13、按“名称”降序,然后按升序按“分数”排序。
编写一个 Pandas 程序,首先按“名称”降序对 DataFrame 进行排序,然后按升序按“分数”排序。
关键:df.sort_values(by=['name', 'score'], ascending=[False, True])
表示对df这个数据帧进行排列,其中以'name', 'score'进行排列,并且name列是降序,score是升序。
【1】pandas sort_values()方法的使用
sort_values()是pandas中比较常用的排序方法,其主要涉及以下三个参数:
- by : 字符或者字符列表
当需要按照多个列排序时,可使用列表 - ascending : bool or list of bool, default True
(是否升序排序,默认为true,降序则为false。如果是列表,则需和by指定的列表数量相同,指明每一列的排序方式) - na_position : {‘first’, ‘last’}, default ‘last’。
(如果指定排序的列中有nan值,则指定nan值放在第一个还是最后一个)
import pandas as pd
import numpy as np
exam_data = {'name': ['Dnastasia', 'Ama', 'Ctherine', 'Bames', 'Emily', 'Michael', 'Ama', 'Laura', 'Kevin', 'Jonas'],
'score': [12.5, 19, 16.5, np.nan, 9, 20, 14.5, np.nan, 8, 19],
'attempts': [1, 3, 2, 3, 2, 3, 1, 1, 2, 1],
'qualify': ['yes', 'no', 'yes', 'no', 'no', 'yes', 'yes', 'no', 'no', 'yes']}
labels = ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j']
df = pd.DataFrame(exam_data , index=labels)
print("Orginal rows:")
print(df)
df1=df.sort_values(by=['name', 'score'], ascending=[False, True])
print("对名称列进行降序排列,若相同,则按升序对分数列进行排序")
print(df1)
14、添加新行和新列并删除新行和新列
- 添加新行: df.loc[‘k’] = [1, ‘Suresh’, ‘yes’, 15.5]
- 添加新列: df[‘k’] = [1, ‘Suresh’, ‘yes’, 15.5]
- 删除新行: df = df.drop(‘k’)
- 删除新列: df = df.drop(‘k’,axis=1)
注:这里删除新列使用的是drop,默认是axis=0,表示删除行,如果删除列的话则需要使用参数axis=1,否则会报错。
import pandas as pd
import numpy as np
exam_data = {'name': ['Anastasia', 'Dima', 'Katherine'],
'score': [12.5, 9, np.nan,],
'attempts': [1, 3, 2,],
'qualify': ['yes', 'no', 'yes', ]}
labels = ['a', 'b', 'c',]
df = pd.DataFrame(exam_data , index=labels)
print("初始数据帧:")
print(df)
print("\n增加新行:")
df.loc['k'] = [1, 'Suresh', 'yes', 15.5]
df['k'] = [1, 'Suresh', 'yes', 15.5]
print(df)
print("\n删除新行之后")
df = df.drop('k')
print(df)
print("\n删除新列之后:")
df = df.drop('k',axis=1)
print(df)

15、从 DataFrame 列标题中获取列表
关键:df.columns.values
import pandas as pd
import numpy as np
exam_data = {'name': ['Anastasia', 'Dima', 'Katherine', 'James', 'Emily', 'Michael', 'Matthew', 'Laura', 'Kevin', 'Jonas'],
'score': [12.5, 9, 16.5, np.nan, 9, 20, 14.5, np.nan, 8, 19],
'attempts': [1, 3, 2, 3, 2, 3, 1, 1, 2, 1],
'qualify': ['yes', 'no', 'yes', 'no', 'no', 'yes', 'yes', 'no', 'no', 'yes']}
labels = ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j']
df = pd.DataFrame(exam_data , index=labels)
print(df)
print("\n")
print(list(df.columns.values))

16、重命名给定数据帧的列
关键:df.rename(columns={‘col1’: ‘Column1’, ‘col2’: ‘Column2’, ‘col3’: ‘Column3’})
这里的columns使用的是字典,键对应的是数据帧的原数据,值对应的是新命名的列名。
import pandas as pd
import numpy as np
d = {'col1': [1, 4, 3, 4, 5], 'col2': [4, 5, 6, 7, 8], 'col3': [7, 8, 9, 0, 1]}
df = pd.DataFrame(data=d)
print("Original DataFrame")
print(df)
print('After altering col1 and col3')
df = df[['col3', 'col2', 'col1']]
print(df)

【2】rename()方法的使用
df.rename(index=None
,columns=None
,axis=None
,inplace=False)
| 参数名 | 功能解释 |
|---|---|
| index | 以字典形式,赋予索引新的值 { 0 : “第一行”} |
| columns | 以字典形式,赋予列名新的值 { A : “第一列”} |
| axis | 指定坐标轴 “index” or “columns” |
| inplace | 是否用新生成的列表替换原列表 |
17、更改数据帧列的顺序
关键: df[[‘col3’, ‘col2’, ‘col1’]]
直接在列表当中交换次序即可
import pandas as pd
import numpy as np
d = {'col1': [1, 4, 3, 4, 5], 'col2': [4, 5, 6, 7, 8], 'col3': [7, 8, 9, 0, 1]}
df = pd.DataFrame(data=d)
print(df)
print('\n')
df = df[['col3', 'col2', 'col1']]
print(df)

18、使用制表符分隔符将数据帧写入CSV文件
关键:df.to_csv(‘new_file.csv’, sep=‘\t’, index=False)
sep就表示使用的分隔符
import pandas as pd
import numpy as np
d = {'col1': [1, 4, 3, 4, 5], 'col2': [4, 5, 6, 7, 8], 'col3': [7, 8, 9, 0, 1]}
df = pd.DataFrame(data=d)
print("Original DataFrame")
print(df)
print('\nData from new_file.csv file:')
df.to_csv('new_file.csv', sep='\t', index=False)
new_df = pd.read_csv('new_file.csv')
print(new_df)

19、将所有 NaN 值替换为数据帧列中的 Zero
关键:df = df.fillna(0),表示将缺失值填充为0
使用fillna
import pandas as pd
import numpy as np
exam_data = {'name': ['Anastasia', 'Dima', 'Katherine', 'James', 'Emily', 'Michael', 'Matthew', 'Laura', 'Kevin', 'Jonas'],
'score': [12.5, 9, 16.5, np.nan, 9, 20, 14.5, np.nan, 8, 19],
'attempts': [1, 3, 2, 3, 2, 3, 1, 1, 2, 1],
'qualify': ['yes', 'no', 'yes', 'no', 'no', 'yes', 'yes', 'no', 'no', 'yes']}
df = pd.DataFrame(exam_data)
print("Original DataFrame")
print(df)
df = df.fillna(0)
print("\nNew DataFrame replacing all NaN with 0:")
print(df)

20、重置数据帧的索引
关键:df.reset_index(level=0, inplace=True)
import pandas as pd
import numpy as np
exam_data = {'name': ['Anastasia', 'Dima', 'Katherine', 'James', 'Emily', 'Michael', 'Matthew', 'Laura', 'Kevin', 'Jonas'],
'score': [12.5, 9, 16.5, np.nan, 9, 20, 14.5, np.nan, 8, 19],
'attempts': [1, 3, 2, 3, 2, 3, 1, 1, 2, 1],
'qualify': ['yes', 'no', 'yes', 'no', 'no', 'yes', 'yes', 'no', 'no', 'yes']}
df = pd.DataFrame(exam_data)
print("初始数据帧:")
print(df)
print("\n重置索引之后,会将旧索引变成index列:")
df.reset_index(inplace=True)
print(df)
print("\n隐藏行索引:")
print( df.to_string(index=False))

【3】Pandas reset_index()用法
函数作用:重置索引或其level。
重置数据帧的索引,并使用默认索引。如果数据帧具有多重索引,则此方法可以删除一个或多个level。
函数主要有以下几个参数:reset_index(level=None, drop=False, inplace=False, col_level=0, col_fill='')
各个参数介绍:
-
level:可以是int, str, tuple, or list, default None等类型。作用是只从索引中删除给定级别。默认情况下删除所有级别。
-
drop:bool, default False。不要尝试在数据帧列中插入索引。这会将索引重置为默认的整数索引。
-
inplace:bool, default False。修改数据帧(不要创建新对象)。
-
col_level:int or str, default=0。如果列有多个级别,则确定将标签插入到哪个级别。默认情况下,它将插入到第一层。
-
col_fill:object, default。如果列有多个级别,则确定其他级别的命名方式。如果没有,则复制索引名称。
返回: DataFrame or None。具有新索引的数据帧,如果inplace=True,则无索引。
21、对一列或多列中的 NaN 值进行计数
关键:
【1】df.isnull().values.sum()
【2】df.isnull().sum():得到的是series类型的
【3】df.isnull().count():不能使用count,得不到正确的结果
import pandas as pd
import numpy as np
exam_data = {'name': ['Anastasia', 'Dima', 'Katherine', 'James', 'Emily', 'Michael', 'Matthew', 'Laura', 'Kevin', 'Jonas'],
'score': [12.5, 9, 16.5, np.nan, 9, 20, 14.5, np.nan, 8, 19],
'attempts': [1, 3, 2, 3, 2, 3, 1, 1, 2, 1],
'qualify': ['yes', 'no', 'yes', 'no', 'no', 'yes', 'yes', 'no', 'no', 'yes']}
df = pd.DataFrame(exam_data)
print("Original DataFrame")
print(df)
print("\ndf.isnull().values.sum():得到的是单个值")
print(df.isnull().values.sum())
print("\ndf.isnull().sum():得到的是series类型")
print(df.isnull().sum())
print("\n不能使用count,count会将所有行都计数")
print(df.isnull().count())
22、以给定的比率划分数据帧
关键:使用随机函数sample划分比率
【1】df.sample(frac=0.7,random_state=10)
【2】df.drop(part_70.index):将得到的70%数据的index删除,即可得到剩下部分的数据帧
【3】df = df.sample(frac=1):表示将df的行排列重新打乱,重新排列
import pandas as pd
import numpy as np
df = pd.DataFrame(np.random.randn(10, 2))
print("Original DataFrame:")
print(df)
part_70 = df.sample(frac=0.7,random_state=10)
part_30 = df.drop(part_70.index)
print("\n70% of the said DataFrame:")
print(part_70)
print("\n30% of the said DataFrame:")
print(part_30)

23、将两个系列组合成一个数据帧
axis=1:表示从列方向进行相连
import pandas as pd
import numpy as np
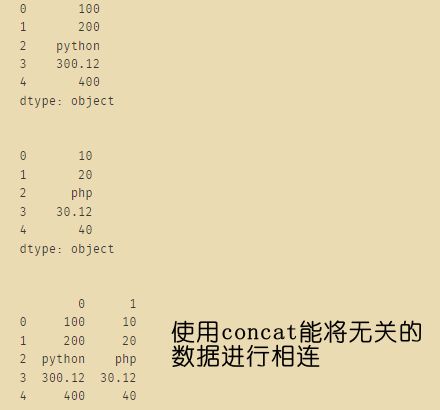
s1 = pd.Series(['100', '200', 'python', '300.12', '400'])
s2 = pd.Series(['10', '20', 'php', '30.12', '40'])
print(s1)
print("\n")
print(s2)
df = pd.concat([s1, s2], axis=1)
print("\n")
print(df)
24、将数据帧列类型从字符串转换为日期时间
import pandas as pd
import numpy as np
s = pd.Series(['3/11/2000', '3/12/2000', '3/13/2000'])
print(s)
r = pd.to_datetime(s)
print("\n")
print(r)

25、检查数据帧中是否存在给定列
import pandas as pd
d = {'col1': [1, 2, 3, 4, 7], 'col2': [4, 5, 6, 9, 5], 'col3': [7, 8, 12, 1, 11]}
df = pd.DataFrame(data=d)
print("Original DataFrame")
print(df)
if 'col4' in df.columns:
print("Col4 is present in DataFrame.")
else:
print("Col4 is not present in DataFrame.")
if 'col1' in df.columns:
print("Col1 is present in DataFrame.")
else:
print("Col1 is not present in DataFrame.")

26、将数据追加到空数据帧
关键:使用append:将数据帧添加到空数据帧
import pandas as pd
import numpy as np
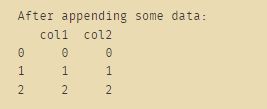
df = pd.DataFrame()
data = pd.DataFrame({"col1": range(3),"col2": range(3)})
print("After appending some data:")
df = df.append(data)
print(df)
27、转换给定列的数据类型(浮点型到整数型)
关键使用astype:df.score = df.score.astype(int)
import pandas as pd
import numpy as np
exam_data = {'name': ['Anastasia', 'Dima', 'Katherine', 'James', 'Emily', 'Michael', 'Matthew', 'Laura', 'Kevin', 'Jonas'],
'score': [12.5, 9.1, 16.5, 12.77, 9.21, 20.22, 14.5, 11.34, 8.8, 19.13],
'attempts': [1, 3, 2, 3, 2, 3, 1, 1, 2, 1],
'qualify': ['yes', 'no', 'yes', 'no', 'no', 'yes', 'yes', 'no', 'no', 'yes']}
df = pd.DataFrame(exam_data)
print(df)
print("\nDataFrame中每列的类型:")
print(df.dtypes)
print("\n将score的浮点型变成int型")
df.score = df.score.astype(int)
print(df)
print("\nDataFrame中每列的类型:")
print(df.dtypes)

28、将给定数据帧中列的连续值转换为分类
编写一个 Pandas 程序,将给定数据帧中列的连续值转换为分类值。
- 输入:
{ ‘姓名’: [‘Alberto Franco’, ‘Gino Mcneill’, ‘Ryan Parkes’, ‘Eesha Hinton’, ‘Syed Wharton’], ‘Age’: [18, 22, 40, 50, 80, 5] } - 输出:
年龄组:
0 孩子
1 成人
2 老人
3 成人
4 老人
5 孩子
姓名: age_groups, dtype: 类别
类别 (3, 对象): [儿童 < 成人 < 老年人]
关键:使用cut函数进行分桶
import pandas as pd
df = pd.DataFrame({
'name': ['Alberto Franco','Gino Mcneill','Ryan Parkes', 'Eesha Hinton', 'Syed Wharton', 'Kierra Gentry'],
'age': [18, 22, 85, 50, 80, 5]
})
print("Original DataFrame:")
print(df)
print('\nAge group:')
df["age_groups"] = pd.cut(df["age"], bins = [0, 18, 65, 99], labels = ["kids", "adult", "elderly"])
print(df["age_groups"])

关于cut函数:
df['age_group'] = pd.cut(df['age'], bins=[0, 12, 19, 61, 100])
df['age_group']
0 (0, 12]
1 (61, 100]
2 (19, 61]
3 (19, 61]
4 (0, 12]
5 (12, 19]
6 (61, 100]
7 (61, 100]
8 (19, 61]
9 (19, 61]
Name: age_group, dtype: category
Categories (4, interval[int64, right]): [(0, 12] < (12, 19] < (19, 61] < (61, 100]]
29、给定数据帧的反向顺序
import pandas as pd
df = pd.DataFrame({'W':[68,75,86,80,66],'X':[78,85,96,80,86], 'Y':[84,94,89,83,86],'Z':[86,97,96,72,83]});
print("Original DataFrame")
print(df)
print("\nReverse column order:")
print(df.loc[:, ::-1])
print("\nReverse row order:")
print(df.loc[::-1])
print("\nReverse row order and reset index:")
print(df.loc[::-1].reset_index(drop = True))

30、为给定数据帧的所有列添加前缀或后缀
关键:使用iloc切片的方式
import pandas as pd
d = {'col1': [1, 2, 3, 4, 7, 11], 'col2': [4, 5, 6, 9, 5, 0], 'col3': [7, 5, 8, 12, 1,11]}
df = pd.DataFrame(data=d)
print("Original DataFrame")
print(df)
print("\nAfter removing last 3 rows of the said DataFrame:")
df1 = df.iloc[:3]
print(df1)
