DNN硬件加速器设计3 -- DNN Accelerators(MIT)
3.1 Highly-Parallel Compute Paradigms
并行计算架构分为以下两类:
(1)Temporal Architecture (SIMD/SIMT)
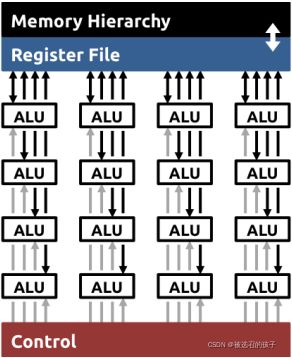
图 1 Temporal Architecture
图1所示为Temporal Architecture的基本结构。该结构的特点是有个公用的Register File, 统一的控制单元,用于并行计算的多条数据路径。
(2)Spatial Architecture (Dataflow Processing)

图 2 Spatial Architecture
图2所示为Spatial Architecture的基本结构,和Temporal Architecture相比,Spatial Architecture中的ALU运算单元具有独立的Register File和Control Unit. 数据以流的形式流过各个运算单元后产生最后的结果输出。
3.2 Memory Access is the Bottleneck
不论是Temporal Architecture 还是 Spatial Architecture,都有Memory Hierarchy结构,在计算机体系结构课程中,这被称为多级存储结构。
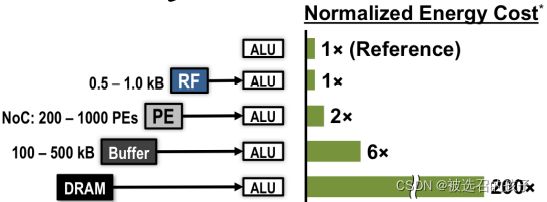
图 3
如图3所示为归一化后,各级存储单元读写数据的能耗比的对比图。可以清楚的知道,越靠近ALU(运算单元)的存储单元,存取相同大小数据的能耗越小,同时存取的速度也越快(在图中没有体现)。

图 4 ALU
图4所示为一个基本运算单元(ALU),其电路是一个乘加运算单元,相当于FPGA中简化版的DSP48硬核处理单元。
首先,在Memory Read阶段,从Memory中读取filter weight(权值参数),fmap activation(特征数据),partial sum(部分累加和);然后,在MAC中,将从Memory中读取的数据进行乘累加运算得到updated partial sum;最后,在Memory Write阶段,将updated partial sum写回Memory中。通过control控制单元持续迭代以上三个计算步骤,直到计算输出最终的sum.
根据图3所示的存储结构和存储局部性原理,将图4所示的ALU计算结构,更新为如下图5所示的运算结构。

图 5 Updated ALU
在片外的DRAM和MAC reg之间添加了额外一级的片上缓存。对于Temporal Architecture (SIMD)的硬件平台,典型的有CPU, GPU等。而使用ASIC,FPGA来设计实现硬件加速器更多采用Spatial Architecture(Dataflow Processing)【PS:个人目前认知水平的理解,欢迎大佬批评指正】
3.3 Types of Data Reuse in DNN

图 6 Data Reuse
图 6所示为DNN中的三种数据复用的方式。
第一种方式是Convolutional Reuse, 将一组卷积核权值参数核和输入特征参数同时进行复用,这样做的理论依据是在卷积层运算层中,卷积核数据在输入特征的各个滑动计算窗口中数据共享。因此,对于卷积运算层中数据复用可以使用权值参数和特征数据一起复用的方式。后续设计的DNN硬件加速器就是采用了这种数据复用方式实现的。尽管该种类型的数据复用从形式上只适用于卷积运算层。但是,对于全连接运算层,可以通过数据重排布,将全连接运算层转换为卷积运算层的形式,以达到Convolutional Reuse的目的。
第二种方式是Fmap Reuse, 只复用输入特征数据。该种方法从形式上看 ,既适用于卷积运算层,也适用于全连接运算层。
第三种方式是Filter Reuse, 只复用卷积核权值参数。该种方法从形式上看,既适用于卷积运算层,也适用于全连接运算层。
数据复用的目的就是为了减少从片外DRAM种,重复数据的反复读写,以提高访存效率,降低访存带来的数据延迟,通过减少对更下级存储单元的访存,降低能耗。在系统设计层面进行低功耗设计。
3.4 Dataflow Taxonomy(数据流结构分类)
依据之前所介绍的DNN中的三种数据复用方式,Spatial Architecture (Dataflow)有以下四种大类的硬件设计架构。
1) Weight Stationary (WS); 2) Output Stationary (OS); 3) No Local Reuse (NLR); 4) Row Stationary(RS) -> Energy-efficient Dataflow
(1)Weight Stationary (WS)

图 7 Weight Stationary
图7所示为Weight Stationary架构的数据通路。其结构的设计思想是:
1)复用权值参数数据,最小化读权值参数数据的次数
2)以广播的方式给各个PE单元写入相同activations,可以降低片外memory的访存带宽要求,充分发挥片内高带宽的优势,同时将各PE单元的部分和结果通过级联结构累加输出。
下图8和图9所示为两种WS结构中3x3大小的2D Convolution Engine的电路结构图。

图 8

图 9
图10为采用WS结构设计的硬件加速器,参考论文为:Gokhale, Vinayak , et al. "A 240 G-ops/s Mobile Coprocessor for Deep Neural Networks." IEEE IEEE, 2014.
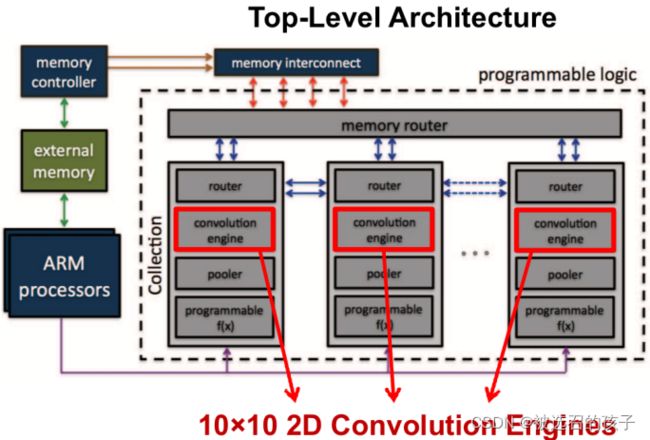
图 10
(2)Output Stationary (OS)

图 11 Output Stationary
图11所示为Output Stationary (OS)的计算数据通路结构图。其结构的设计思想是:
1) 最小化部分累加和的访存次数,最大化利用片上缓存进行部分和的累加计算,以此降低访存能耗
2)广播传输filter weights 和复用activations数据在级联的每个PE中传输
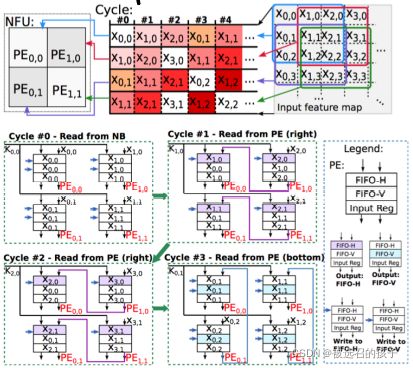
图 12 ShiDianNao
图12所示为ShiDianNao中一个只有4个PE单元组成的NFU的数据流示意图。
4个PE单元分别对同一个input feature map进行3x3大小的卷积运算,NFU中的数据流加载分成三个阶段。
第一个阶段是在刚开始启动的第一个时钟阶段。NFU中所有的PE单元都需要从外部(片上)DRAM中,独自加载所需要的权值参数和输入特征数据。
第二个阶段是在第一个阶段到k-1大小的时钟周期中,左边的PE单元的Input feature map参数可以使用来自右边相邻的PE其上一个时钟周期所使用过的Input feature map, 这样的结构,使得对片外DRAM的活动(active)访存带宽减小了一半,也减小了对重复Input feature map数据的多次读取,这样就降低了动态功耗。
第三个阶段是在第k个时钟开始后的阶段,在NFU中,排布在上方的PE单元可以复用来自其相邻下方的input feature map数据。这样的结构,同样使得对片外DRAM的活动(active)访存带宽减小了一半,也减小了对重复input feature map数据的多次读取,起到了降低动态功耗的作用。
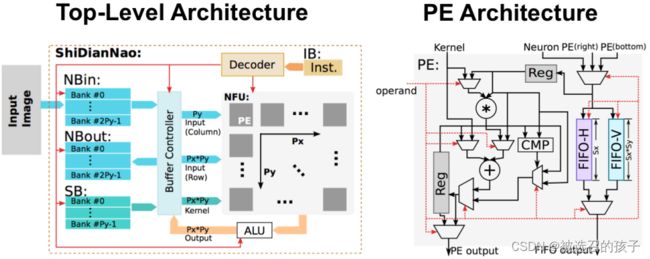
图 13 ShiDianNao top-level Architecture and PE Architecture
上图13所示为ShiDianNao的Top-level Architecture和PE Architecture。和之前只做MAC运算的PE结构不同,在ShiDianNao的PE中还加入了缓存输入input feature map数据的FIFO-H和FIFO-V,用于控制数据纵横走向的比较器,选择器等控制电路逻辑。
参考论文为: ShiDianNao: Shifting Vision Processing Closer to the Sensor
(3)No Local Reuse (NLR)
图 14 No Local Reuse
图14所示为NLR计算数据通路结构图,其结构的设计思路为:
1)依据数据局部性原理,使用一个很大的片上全局缓存来存储数据,减少对片外DRAM的数据读取次数,以减少系统能耗
2)多个PE单元共享activations数据,每个PE单元独立加载自己的weights数据,部分累加和在级联结构的PE中传输,完成累加运算后写入到全局缓存中。

图 15 UCLA
图15所示的UCLA结构是采用了NLR设计的硬件加速器架构。在UCLA架构中,在片上有两块用于缓存来自片外DRAM中数据的片上缓存单元(Input Buffer Set0, Input Buffer Set1),这两组Buffer可以构成乒乓buffer,形成两级流水线结构,提高有效访存带宽。运算单元(Compute Engine)是乘累加树结构。两个输出片上缓存单元(Output Buffer Set0, Output Buffer Set1)用于缓存中间数据(部分和)以及最终计算结果。

图 16 DianNao
图16所示为以NLR为基础设计的硬件加速器电路:DianNao
从总体结构上看,UCLA架构和DianNao架构有着高度相似的结构。
参考论文:DianNao: A Small-Footprint High-Throughput Accelerator for Ubiquitous Machine-Learning
(4)Row Stationary (RS)
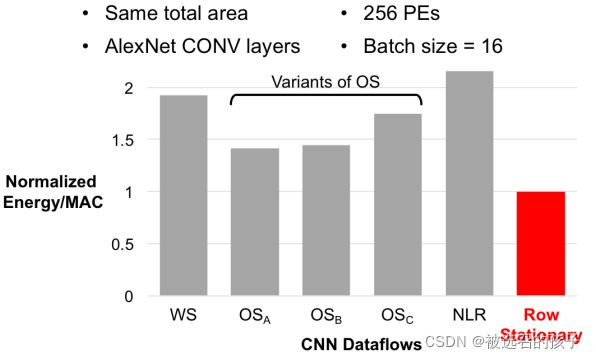
图 17 Energy Efficiency Comparison
图17归一化对比了在相同个数PE硬件资源,加速相同网络结构,不同类型Dataflows硬件结构在能耗比上的对比。这里有个突出的红色柱状图,称为Row Stationary的Data flow结构。从图中可以看出,该种Dataflow类型结构的硬件加速结构的能耗比最低。
Row Stationary能效利用率表现最好的原因主要有以下两点:
1)在RS中,最大化实现了Psum, input feature map, weight三种数据的复用
2)对系统整体进行能耗优化而不是仅仅只针对特定数据类型
Row Stationary的原因就是进行运算时,以Row数据为基本单位。

图 18 1D Row Convolution in PE
图18所示为在PE中1D Row Convolution的示意图。
从图18所示的1D Row Convolution in PE的示意图可以知道:
1)保持filter row和input fmap数据,在PE中以滑动窗口来计算,最大化复用行卷积运算数据
2)循环累加控制来最大化复用行卷积运算的部分和结果数据
图19所示为将1D Convolution in PE 推广成 2D Convolution in PE的结构图。

图 19 2D Convolution in PE
从图19所示的2D Convolution阵列图,可以看到RS对数据复用的三种方式:
1)在水平方向上,各个PE可以复用Filter rows数据
2)在对角线方向上,各个PE可以复用Fmap rows数据
3)在垂直方向上,各个PE的部分和可以直接通过级联结构传递累加得到最终的输出结果
3.5 Dataflow Comparison
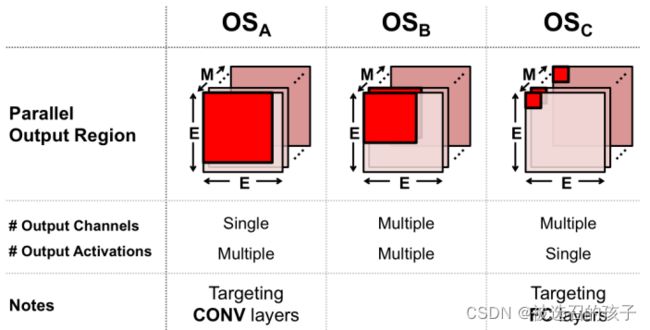
图 20 Types of OS
图20所示为OS Dataflow的数据复用的三种方式。
1)OSA是单输出通道,一次多个数据输出
2)OSB是多输出通道,每个通道是多个数据输出
3)OSC是多输出通道,每个通道是单数据输出
这里注意的是,在相同访存带宽的情况下,都充分使用访存带宽,则这三种OS Dataflow在总线上的数据排列方式不同。
(1)Conv Layers

图 21
图21所示为Dataflows Architecture下,六种硬件加速平台,在Conv Layer中三种类型数据psums, weights, activations归一化后的能耗比示意图。可以看到RS结构在整体上具有最好的能耗比。

图 22
图22所示为在Conv Layer中各硬件单元ALU, RF, NOC, buffer, DRAM的能耗占比。可以看到RS比其他Dataflows结构的energy低1.4x - 2.5x
(2)FC Layers
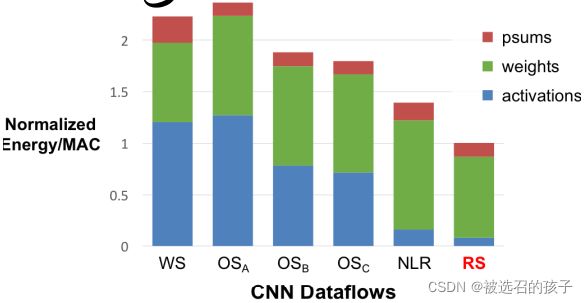
图 23
图23所示为几种Dataflows Architecture在FC Layers中的比较,可以看到RS比其它Dataflows结构的能耗比低至少 1.3x
(3)Row Stationary: Layer Breakdown
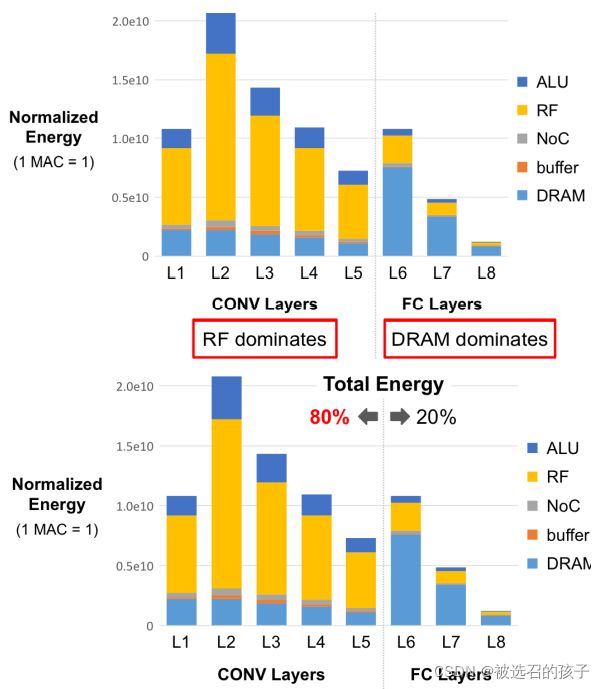
图 24
图24是对RS结构的单独分析,有图中数据有以下两点:
1)在Conv Layers中, RF硬件在功耗中占了主导地位;在FC Layers中,DRAM硬件在功耗中占了主导地位;
2)在Total Energy中,CONV Layers在能耗中占了主导地位。
3.6 Summary of DNN Dataflows
1) Weight Stationary
最小化对filter weights参数的存取,就是尽可能的复用filter weights数据;该结构更多的出现在存内计算架构中。
2)Output Stationary
最小化对partial sums参数的存取,有三种子类型的OS
3)No Local Reuse
PE中没有memory,需要一个很大的全局缓存。
4)Row Statinary
对数据进行重排布,在系统整体层面上进行能耗优化。