Apache Doris 架构原理及特性(四)
目录
5、架构原理
5.1 Doris整体架构
5.2 FE 元数据管理
5.3 Doris数据组织
5.4 执行计划
6、特性
6.1 JOIN 两阶段聚合自适应
6.2 JOIN 优化 Colocation Join
6.3 向量化执行
6.4 动态添加 rollUp
6.5 物化视图-延迟物化
6.6 前缀索引
6.7 支持Roaring BitMap 索引
6.8 低基数的字典编码
6.9 MPP架构
6.10 两层区分与分级存储、动态分区
6.11 Doris On ES
7、 拓展
7.1、向量化
7.7.1 经典的 SQL 计算引擎
7.7.2 向量化执行
7.2 Roaring Bitmap
7.2.1 普通BitMap
7.2.2 Roaring Bitmap
7.3 Impala 原理
7.3.1 架构
7.3.2 工作流程
8、 推荐阅读
5、架构原理
5.1 Doris整体架构
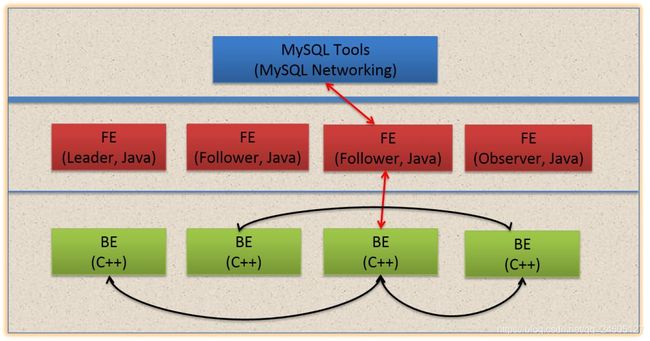
Doris主要分为FE和BE两个组件,FE主要负责查询的编译,分发和元数据管理(基于内存,类似HDFS NN);BE主要负责查询的执行和存储系统
1、这张图是Doris的整体架构。Doris的架构很简洁,只设FE(Frontend)、BE(Backend)两种角色、两个进程,不依赖于外部组件,方便部署和运维。
2、以数据存储的角度观之,FE存储、维护集群元数据;BE存储物理数据。
3、以查询处理的角度观之, FE节点接收、解析查询请求,规划查询计划,调度查询执行,返回查询结果;BE节点依据FE生成的物理计划,分布式地执行查询。
4、FE主要有有三个角色,一个是leader,一个是follower,还有一个observer。leader跟follower,主要是用来达到元数据的高可用,保证单节点宕机的情况下,元数据能够实时地在线恢复,而不影响整个服务。
5、右边observer只是用来扩展查询节点,就是说如果在发现集群压力非常大的情况下,需要去扩展整个查询的能力,那么可以加observer的节点。observer不参与任何的写入,只参与读取。
5.2 FE 元数据管理

元数据层面,Doris采用Paxos协议以及Memory + Checkpoint + Journal的机制来确保元数据的高性能及高可靠。
元数据的每次更新,都首先写入到磁盘的日志文件中(WAL溢血日志),然后再写到内存中,最后定期checkpoint到本地磁盘上。相当于是一个纯内存的一个结构,也就是说所有的元数据都会缓存在内存之中,从而保证FE在宕机后能够快速恢复元数据,而且不丢失元数据。Leader、follower和 observer它们三个构成一个可靠的服务,这样如果发生节点宕机的情况,在百度内部的话,我们一般是部署一个leader两个follower,外部公司目前来说基本上也是这么部署的。就是说三个节点去达到一个高可用服务。以我们的经验来说,单机的节点故障的时候其实基本上三个就够了,因为FE节点毕竟它只存了一份元数据,它的压力不大,所以如果FE太多的时候它会去消耗机器资源,所以多数情况下三个就足够了,可以达到一个很高可用的元数据服务。
5.3 Doris数据组织
数据主要都是存储在BE里面,BE节点上物理数据的可靠性通过多副本来实现,默认是3副本,副本数可配置且可随时动态调整,满足不同可用性级别的业务需求。FE调度BE上副本的分布与补齐。


5.4 执行计划
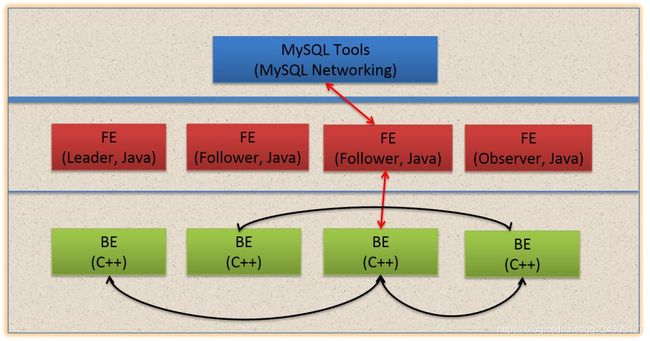
doris最早是借鉴了Impala的查询引擎,把它改造了一下引入到Doris里面形成一个分布式的查询引擎。因为Impala是一个完全的P2P的结构,每个节点都缓存元数据,对于一个高性能的报表分析来说,它有可能会面临着元数据落后的问题。所以我们把Impala查询规划所有的部分,都放到了一个FE里面,都会由FE来完成。FE来根据用户的查询生成一个完整的逻辑规划,然后这个逻辑规划最后生成一个分布式的逻辑规划,会发给整个集群去执行

Doris的FE 主要负责SQL的解析,语法分析,查询计划的生成和优化。查询计划的生成主要分为两步:
-
生成单节点查询计划 (上图左下角)
-
将单节点的查询计划分布式化,生成PlanFragment(上图右半部分)
第一步主要包括Plan Tree的生成,谓词下推, Table Partitions pruning,Column projections,Cost-based优化等;第二步 将单节点的查询计划分布式化,分布式化的目标是最小化数据移动和最大化本地Scan,分布式化的方法是增加ExchangeNode,执行计划树会以ExchangeNode为边界拆分为PlanFragment,1个PlanFragment封装了在一台机器上对同一数据集的部分PlanTree。如上图所示:各个Fragment的数据流转和最终的结果发送依赖:DataSink。
当FE生成好查询计划树后,BE对应的各种Plan Node(Scan, Join, Union, Aggregation, Sort等)执行自己负责的操作即可。
6、特性
6.1 JOIN 两阶段聚合自适应
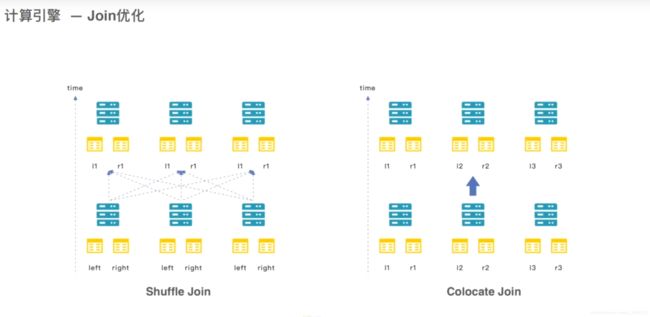
doris 不仅自适应Broadcast/Shuffle Join 方式,也可手动进行 Colocation Join ,也能在这些join 基础上自适应的进行两阶段聚合。
运行时会对数据进行采样,来判断是否进行两阶段聚合

6.2 JOIN 优化 Colocation Join
6.3 向量化执行


6.4 动态添加 rollUp
6.5 物化视图-延迟物化

6.6 前缀索引

6.7 支持Roaring BitMap 索引

6.8 低基数的字典编码

6.9 MPP架构

6.10 两层区分与分级存储、动态分区
略略略~
6.11 Doris On ES
CREATE EXTERNAL TABLE `es_table` (
`id` bigint(20) COMMENT "",
`k1` bigint(20) COMMENT "",
`k2` datetime COMMENT "",
`k3` varchar(20) COMMENT "",
`k4` varchar(100) COMMENT "",
`k5` float COMMENT ""
) ENGINE=ELASTICSEARCH
PARTITION BY RANGE(`id`)
()
PROPERTIES (
"hosts" = "http://192.168.0.1:8200,http://192.168.0.2:8200",
"user" = "root",
"password" = "root",
"index" = "tindex”,
"type" = "doc"
);
select * from es_table where esquery(k4, '{ "match": { "k4": "doris on elasticsearch" } }');
7、 Doris相关拓展
7.1、向量化
假如有个sql :
select c1 , c2 from t where c1 < 100 and c4 = 10
用户通过 SQL 语句向数据库发起计算请求,SQL 中的计算主要包括两类:expression 级别的计算和 operator 级别的计算。该 SQL 包含了 3 个 operator:tablescan,Filter 和 projection,而每个 operator 内部又包含了各自的 expression,例如 Filter 内部的 expression 为c1 < 100 and c4 = 10,projection 内部的 expression 则为c1 和c2`。
7.7.1 经典的 SQL 计算引擎
7.7.1.1 解析原理
在 expression 层面一般采用 expression tree 的模型来解释执行,而在 operator 层面则大多采用火山模型。
上述 SQL 中的 filter 条件对应的 expression tree 就如下图所示:

与 Expression tree 类似,在火山模型中,operator 也被组织为 operator tree 的形式,operator 之间则通过迭代器来串联。Operator 一般有如下定义:
class Operator {
Row next();
void open();
void close();
Operator children[];
}在具体的 operator 中一般包含其需要计算的 expression,例如
class Projection extends Operator {
Expression projectionExprs[];
Row next() {
Row output = new Row(projectionExprs.length);
Row input = children[0].next();
for (int i = 0; i < projectionExprs.length; i++) {
output.set(i, projectionExprs[i].eval(input));
}
return output;
}
}这样上述 SQL 在数据库中实际上会被编译为如下的 operator tree:

7.7.1.2 优缺点
1、 优点
火山模型的最大好处是实现简单,每个 operator 都只需要完成其自身特定的功能,operator 之间是完全解耦合的,SQL complier 只需要根据 SQL 的逻辑构造对应的 operator 然后将 operator 串联起来即可。
2、缺点:
Expression层面:基于 expression tree 的解释执行往往使得一些看上去很简单的表达式执行起来很复杂,以上述 SQL 的 filter 条件为例:c1 < 100 and c4 = 10 这个过滤条件在数据库中会被转换为包含 7 个节点的 expression tree,对于表中的每行数据,这 7 个节点的 eval 函数都会被触发一次。
Operator 层面面临的问题与 Expression 类似,火山模型虽然带来了实现简单、干净的好处,但是每次计算一行结果都会有一个很长的 next 虚函数调用链(而且 operator next 函数中一般还会有一个 expression eval 的虚函数调用链)。虽然虚函数调用本身开销并不算特别大,但是仍需要花费一定的时间,而虚函数内部的操作可能就是一个简单的轻量级计算,而且每一行数据都需要若干次的虚函数调用,当数据量非常大的时候,这个开销就会变得十分可观。
除了虚函数带来的计算框架开销外,经典计算引擎还有一些其他缺点,试想上述 SQL 在火山模型中生成相应的 plan 后,其运行时的代码如下:
for(; Row row = plan.next(); row != null) {
// send to client
}
其中 plan 即 operator tree 的 root 节点,对上述 SQL 来说就是 projection。
而如果手动写一段代码来实现上述 SQL 的话,其代码大概如下:
for(Row row in scanBuffer) {
int c1 = row.getInt(0);
int c3 = row.getInt(2);
if (c1 < 100 && c3 == 10) {
// construct new row and send to the client
}
}
上述两段代码虽然都是一个 for 循环,但是对于第一段代码来说,for 循环里面是很深的虚函数调用,而第二段代码 for 循环里做的事则要简单的多。对 compiler 来说,越简单的代码越容易优化,在这个例子中,compiler 就可以通过将c1和c3放在寄存器中来实现提速。
7.7.2 向量化执行
7.7.2.1 优化思想
从上面的介绍来看,经典 SQL 的计算引擎一个很大问题就是无论是 expression 还是 operator ,其计算的时候都大量使用到虚函数,由于每行数据都需要经过这一系列的运算,导致计算框架开销比较大,而且由于虚函数的大量使用,也影响了编译器的优化空间。在减小框架开销方面,两个常用的方法就是
-
均摊开销
-
消除开销
向量化执行与代码生成正是数据库从业者们在这两个方向上进行的努力。
7.7.2.2 向量化执行
向量化执行的思想就是均摊开销:假设每次通过 operator tree 生成一行结果的开销是 C 的话,经典模型的计算框架总开销就是 C * N,其中 N 为参与计算的总行数;如果把计算引擎每次生成一行数据的模型改为每次生成一批数据的话,因为每次调用的开销是相对恒定的,所以计算框架的总开销就可以减小到C * N / M,其中 M 是每批数据的行数,这样每一行的开销就减小为原来的 1 / M,当 M 比较大时,计算框架的开销就不会成为系统瓶颈了。除此之外,向量化执行还能给 compiler 带来更多的优化空间,因为引入向量化之后,实际上是将原来数据库运行时的一个大 for 循环拆成了两层 for 循环,内层的 for 循环通常会比较简单,对编译器来说也存在更大的优化可能性。
举例来说,对于一个实现两个 int 相加的 expression,在向量化之前,其实现可能是这样的:
class ExpressionIntAdd extends Expression {
Datum eval(Row input) {
int left = input.getInt(leftIndex);
int right = input.getInt(rightIndex);
return new Datum(left+right);
}
}在向量化之后,其实现可能会变为这样:
class VectorExpressionIntAdd extends VectorExpression {
int[] eval(int[] left, int[] right) {
int[] ret = new int[input.length];
for(int i = 0; i < input.length; i++) {
ret[i] = new Datum(left[i] + right[i]);
}
return ret;
}
}
显然对比向量化之前的版本,向量化之后的版本不再是每次只处理一条数据,而是每次能处理一批数据
7.2 Roaring Bitmap
7.2.1 普通BitMap
Bitmap 会有两个问题,一个是内存和存储占用,一个是 Bitmap 输入只支持 Int 类型。解决内存和存储占用的思路就是压缩,业界普遍采用的 Bitmap 库是 Roaring Bitmap;
7.2.2 Roaring Bitmap
Roaring Bitmap 的核心思路很简单,就是根据数据的不同特征采用不同的存储或压缩方式。 为了实现这一点,Roaring Bitmap 首先进行了分桶,将整个 int 域拆成了 2 的 16 次方 65536 个桶,每个桶最多包含 65536 个元素。 所以一个 int 的高 16 位决定了,它位于哪个桶,桶里只存储低 16 位。以图中的例子来说,62 的前 1000 个倍数,高 16 位都是 0,所以都在第一个桶里。

Array Container: 默认会采用 16 位的 Short 数组来存储低 16 位数据;
BitMap Container: 当元素个数超过 4096 时,会采用 Bitmap 来存储数据。 为什么是 4096 呢? 我们知道, 如果用 Bitmap 来存,65526 个 bit, 除以 8 是 8192 个字节,而 4096 个 Short 就是 4096 * 2 = 8192 个字节。 所以当元素个数少于 4096 时,Array 存储效率高,当大于 4096 时,Bitmap 存储效率高。
Run Container: 是优化连续的数据, Run 指的是 Run Length Encoding(RLE),比如我们有 10 到 1000 折连续的 991 个数字,那么其实不需要连续存储 10 到 1000,这 991 个整形,我们只需要存储 1 和 990 这两个整形就够了。
7.3 Impala 原理
7.3.1 架构
首先需要知道Impala的三个核心组件以及其对应的实例:
– Statestore Daemon —–>statestored
对impalad做一个健康检查:资源信息,节点状态等,且负责query的调度。
– Catalog Daemon —–>catalogd
同步元数据信息,当hive中数据发生更改的时候,会同步到各个impala中。但是不够智能,比如你在hive创建了一个表之后,实时查询impala是没有同步的,需要手工刷新。
– Impala Daemon —–>impalad
最核心的,真正用于查询的工作节点。会接收client、hue、jdbc或者odbc请求、执行查询并返回给中心协调节点,且与statestore保持通信,汇报工作。
7.3.2 工作流程
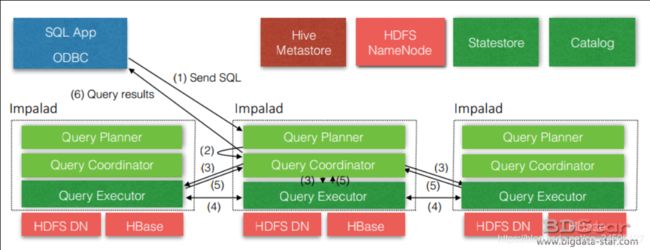
-
由Client发送一个执行SQL到任意一台Impalad
-
QueryPlanner接受到客户端Sql后解释为真正的执行计划
-
Query Coordinator 是中心协调节点,调度任务,Query Coordinator分配任务到Impalad的所有节点。(请求的时候可以指定请求哪一台impalad,假如你请求第二台,那么第二台就作为中心协调节点)
-
各个Impalad节点的Query Executor 进行执行SQL工作
-
执行SQL结束以后,将结果返回给Query Coordinator
-
再由Query Coordinator汇总之后将结果返回给Client(所以要注意一个问题,如果要做聚合操作的话,一般是选择内存最大的那台作为中心协调节点
8、 推荐阅读
http://doris.apache.org/master/zh-CN/getting-started/basic-usage.html
https://blog.bcmeng.com/post/apache-kylin-vs-baidu-palo.html
https://blog.bcmeng.com/post/apache-doris-query.html
https://blog.bcmeng.com/post/doris-bitmap.html
https://blog.bcmeng.com/post/doris-colocate-join.html
https://blog.bcmeng.com/post/kafka-to-doris.html
https://blog.csdn.net/qihoo_tech/article/details/96472699
官方公众号:
