Python基于cq-http协议端,使用nonebot2框架制作属于自己的智能机器人
1. 快速创建QQ机器人
WebQQ介绍
WebQQ腾讯公司推出的使用网页方式上QQ的服务,特点是无需下载和安装QQ软件,只要能打开WebQQ的网站就可以登录QQ与好友保持联系。具有Web产品固有的便利性,同时在Web上最大限度的保持了客户端软件的操作习惯。
通过WebQQ利用爬虫类的脚本,我们能够接受已登录用户所有好友信息,并且相应的聊天信息。但是2018年12月12日,QQ发布公告,称由于业务调整,webQQ已经于2019年1月1日停止服务,并提示用户下载QQ客户端。
采用Python语言制作方案
要实现用python发送 / 接收消息,要用requests发送http请求之外,还要用flask在本地搭建一个flask服务端,告知插件flask服务器的地址和端口,这样所有的qq消息都会自动传递给flask,我们可以根据消息的来源,内容,自动判断是否要回复即可。
1.1 相关官方文档介绍
官方参考文档介绍
nonebot框架官方文档:https://v2.nonebot.dev/docs/api
go-cqhttp通信规范API参考文档:
https://docs.go-cqhttp.org/
go-cqhttp安装下载网址:https://github.com/Mrs4s/go-cqhttp/releases/tag/v1.0.0-beta2
在github下载go-cqhttp,根据你的操作系统选择相应的版本
windows64位选择:go-cqhttp_windows_amd64.exe
linux选择:go-cqhttp_0.9.40-fix5_linux_amd64.deb
1.2 go-cqhttp安装部署操作
配置 CQHTTP 协议端(以 QQ 为例)
单纯运行 NoneBot 实例并不会产生任何效果,因为此刻 QQ 这边还不知道 NoneBot 的存在,也就无法把消息发送给它,因此现在需要使用一个无头 QQ 来把消息等事件上报给 NoneBot。
这里以 go-cqhttp (opens new window)为例
如果下载的zip压缩包,那么需要进行解压:
将go-cqhttp.exe可执行文件用Powershell窗口进行执行
Powershell窗口怎么打开呢?按住shift切换键键,然后鼠标右击,选中在此处打开Powershell窗口。
Windows PowerShell 是一种命令行外壳程序和脚本环境,使命令行用户和脚本编写者可以利用 .NETFramework的强大功能。它引入了许多非常有用的新概念,从而进一步扩展了在 Windows 命令提示符和 Windows Script Host 环境中获得的知识和创建的脚本。
powershell是一个shell,定义好了一些命令操作系统,特别是与文件系统交互,能够启动应用程序,甚至操纵应用程序。PowerShell还能允许将几个命令组合起来放到文件里执行,实现文件级的重用,PowerShell 能够充分利用copy.Net类型和 COM 对象,来简单地与各种系统交互,完成各种复杂的、自动化的操作。
执行go-cqhttp.exe
PS [go-cqhttp_windows_amd64解压后的目录]>.\go-cqhttp.exe
执行go-cqhttp.exe文件,会出现如下的选择:
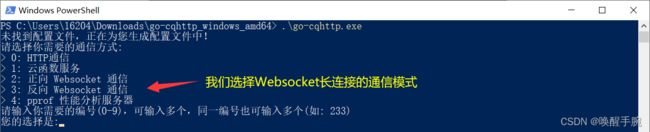
执行完成后,再go-cqhttp.exe的同级目录下会生成config.yml配置文件
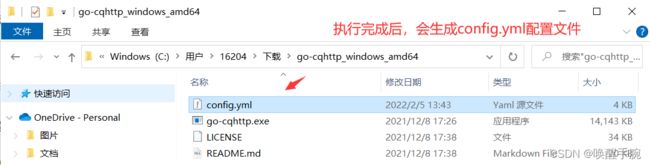
通过vscode打开可以看见,是QQ登录连接相关的配置,我们需要对其部分根据我们的需求进行修改,部分截取如下:
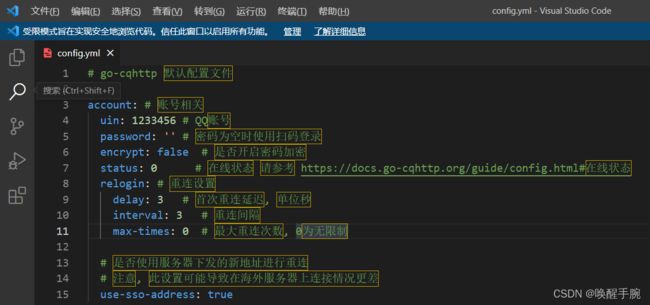
配置文件config.yml的最后几行是关于Server服务相关的配置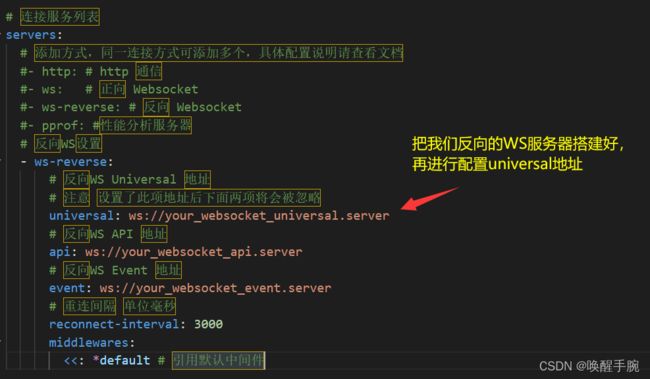
1.3 go-cqhttp协议端配置
配置go-cqhttp的config.yml文件,登录QQ机器人
account:
uin: 机器人QQ号
password: "机器人密码"
message:
post-format: array
servers:
- ws-reverse:
universal: ws://127.0.0.1:8080/cqhttp/ws
其中 ws://127.0.0.1:8080/cqhttp/ws 中的 127.0.0.1 和 8080 应分别对应 nonebot 配置的 HOST 和 PORT。
cqhttp 是前述 register_adapter 时传入的第一个参数,代表设置的 CQHTTPBot 适配器的路径,你可以对不同的适配器设置不同路径以作区别。
配置QQ号与密码如下:
uin: 1233456 # QQ账号 改成你的QQ机器人的号码
password: '' # 密码为空时使用扫码登录
我们先启动测试下:继续打开Powershell窗口,进行运行go-cqhttp.exe,然后会出现相应的授权登录的二维码,我们把需要制作成QQ机器人的QQ号进行扫码授权登录。

扫码成功后出现的结果如下所示:

1.4 nonebot搭建反向服务器
搭建Websocket Universal 反向服务器
我们可以借助安装nonebot脚手架,方便搭建反向服务器。
官方教程网址:https://v2.nonebot.dev/docs/start/installation
如果安装后执行,提示报错缺少nonebot依赖的其他第三方库,自行根据提示进行安装即可。
安装nonebot脚手架
PS [你的项目目录]> pip install nonebot2
安装驱动器
NoneBot 在默认安装情况下内置了 fastapi 服务端驱动器,其他驱动器如 httpx, aiohttp 则需要额外安装。
PS C:\Users\16204\PycharmProjects\wristqq> nb driver list
FastAPI () - FastAPI 驱动器
Quart (quart) - Quart 驱动器
HTTPX (httpx) - HTTPX 驱动器
websockets (websockets) - websockets 驱动器
AIOHTTP (aiohttp) - AIOHTTP 驱动器
安装nonebot相关的第三方库之后,pip list,看到如下的相应的库,就可以满足条件了。

nb-cli选择0.5.0版本即可,如果要使用nb-cli==0.6.5版本,那么nonebot2要使用beta.1的版本。
nonebot22.0.0a16可能会与nb-cli0.6.5版本不匹配:nb-cli 0.6.5 requires nonebot2<3.0.0,>=2.0.0-beta.1, but you have nonebot2 2.0.0a16 which is incompatible.
借助nonebot框架,创建项目
在terminal窗口启动,创建nonebot工程
如果你已经按照推荐方式安装了 nb-cli,使用它创建一个空项目:
PS [你的项目目录]>> nb create
根据引导进行项目配置,完成后会在当前目录下创建一个项目目录,项目目录内包含 bot.py。
如果未安装 nb-cli,使用你最熟悉的编辑器或 IDE,创建一个名为 bot.py 的文件,内容如下(这里以 CQHTTP 适配器为例):
import nonebot
from nonebot.adapters.cqhttp import Bot as CQHTTPBot
nonebot.init()
driver = nonebot.get_driver()
driver.register_adapter("cqhttp", CQHTTPBot)
nonebot.load_builtin_plugins()
if __name__ == "__main__":
nonebot.run()
在上方 bot.py 中,这几行高亮代码将依次:
-
使用默认配置初始化 NoneBot
-
加载 NoneBot 内置的 CQHTTP 协议适配组件
register_adapter 的第一个参数我们传入了一个字符串,该字符串将会在后文 配置 CQHTTP 协议端 时使用。
-
加载 NoneBot 内置的插件
-
在地址 127.0.0.1:8080 运行 NoneBot
在命令行使用如下命令即可运行这个 NoneBot 实例:
nb run # nb-cli
python bot.py # 其他
运行后会产生如下日志:
09-14 21:02:00 [INFO] nonebot | Succeeded to import "nonebot.plugins.base"
09-14 21:02:00 [INFO] nonebot | Running NoneBot...
09-14 21:02:00 [INFO] uvicorn | Started server process [1234]
09-14 21:02:00 [INFO] uvicorn | Waiting for application startup.
09-14 21:02:00 [INFO] uvicorn | Application startup complete.
09-14 21:02:00 [INFO] uvicorn | Uvicorn running on http://127.0.0.1:8080 (Press CTRL+C to quit)
1.5 创建nonebot客户端项目
友情提示:有同学可能会遇到,nb-cli==0.5.0的版本,再创建项目的时候遇到adapter协议适配器选择时候发生报错,可能是版本原因
解决方案,先安装beta.1,安装nb-cli==0.6.5,用0.6.5创建项目,然后卸载beta.1版本,重装nonebot2仍然使用a16。(最主要原因beta.1版本在加载cq-http时候会出现版本问题,beta.1使用的是bot11
我们通过控制台终端进行创建:
[?] Project Name: wrist
[?] Where to store the plugin? 2) In a "src" folder
[?] Which builtin plugin(s) would you like to use? echo
[?] Which adapter(s) would you like to use?
[?] You haven't chosen any adapter. Please confirm. y
创建完成之后可以看到有项目的文件夹生成:
然后修改下我们的bot.py,引入我们的cq-http协议适配器:
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import nonebot
from nonebot.adapters.cqhttp import Bot as CQHTTPBot
nonebot.init()
app = nonebot.get_asgi()
driver = nonebot.get_driver()
driver.register_adapter("cqhttp", CQHTTPBot)
nonebot.load_builtin_plugins()
# 加载我们的插件(一般是自定义的插件)
if __name__ == "__main__":
nonebot.logger.warning("Always use `nb run` to start the bot instead of manually running!")
nonebot.run(app="__mp_main__:app")
生成的项目文件夹中,会有一个env.dev文件,bot.py运行启动的配置文件:
HOST=127.0.0.1 # 运行主机的ip地址
PORT=8080 # 反向服务器的端口号
LOG_LEVEL=DEBUG
FASTAPI_RELOAD=true
1.6 运行项目测试
接下来,我们启动运行bot.py文件,开启我们的反向服务器,根据之前cq-http的目录,打开Powershell窗口,进行运行go-cqhttp.exe,开启协议端的服务,让两者成功连接。运行结果如下所示:
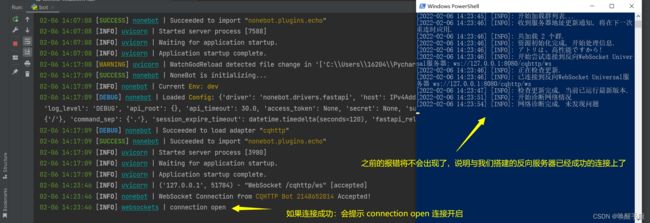
接下来我们简单测试下:用另一个QQ打开与机器人的聊天窗口,测试如下:

1.7 自定义Plugins插件
在运行bot.py文件的时候在控制台会出现如下日志:这个就是插件,echo是nonebot内置插件,我们可以直接使用,如果想加强我们的机器人的功能,则需要我们自定义插件去实现。
02-06 14:07:08 [SUCCESS] nonebot | Succeeded to import "nonebot.plugins.echo"
我们在项目目录src/plugins下开发自己的插件:
举例让机器人发送语音:
from nonebot.adapters.cqhttp import Message
from nonebot import on_keyword
from nonebot.typing import T_State
from nonebot.adapters import Bot, Event
test = on_keyword({'语音'})
# on_keyword是接收某关键词的意思,api
@test.handle()
async def send_audio(bot: Bot, event: Event, state: T_State):
audio = "[CQ:record,file=http://music.163.com/song/media/outer/url?id=504924216.mp3]"
await test.send(Message(audio))
当我们自定义的插件写完之后,并没有直接被调用,所以我们要在我们的启动文件bot.py中进行引入,方法如下:
nonebot.load_plugins('src/plugins')
效果图如下所示:

然后打开与机器人的会话窗口,进行测试:

2. QQ机器人插件拓展
在上节已经介绍了QQ机器人的开发,已经简单小案例的测试,接下来我们要加强它的功能,学习方式是查看官方文档的规范来进行拓展它的功能。
也可以借助我们以往的知识,Python的web开发,以及爬虫的实现进行整合到我们的QQ机器人中,让它的功能更加的丰富。
CQ码官方文档:https://docs.go-cqhttp.org/cqcode/
2.1 插件开发知识点
首先介绍下基本插件开发的固定格式,展示如下所示:
from nonebot.adapters.cqhttp import Message
from nonebot import on_keyword
from nonebot.typing import T_State
from nonebot.adapters import Bot, Event
test = on_keyword({'[关键词]'})
@test.handle()
async def test_fun(bot: Bot, event: Event, state: T_State):
test_msg = "[CQ码]"
await test.send(Message(test_msg))
介绍下event事件对象的相关参数与方法:
print(event.get_message())
# 本次事件接受到的消息内容,只有内容包含关键词就会执行test_fun事件处理函数
print(event.get_user_id())
# 本次事件接受到的消息内容的发送者id,这边指的就是发送者的QQ号
print(event.get_session_id())
# 本次事件接受到的消息当前会话id
# 如果私聊就是发送者的QQ号
# 如果是群聊的接收就是 group_群号_QQ号
接下介绍下,问答形式的轮询事件的定义,当发送者发送命令后,QQ机器人进行回复,再次接收先前发送者的回答进行判断抉择。
@eng.got("key", prompt="请问你要翻译的句子是?")
async def res_test(bot: Bot, event: Event, state: T_State):
translate = state["key"]
print(translate)
print(event.get_message())
# 上面两者的输出结果是一致的。
2.2 发送QQ表情与图片
QQ机器人发送QQ表情的实现
QQ表情CQ码文档:QQ表情CQ码官方文档
为了减少试验,这里总结了一个 QQ 表情的 CQ 码对应表情的表格,对应的是 [CQ:face,id={id}]
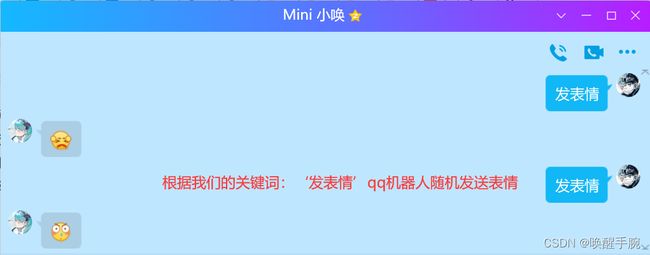
实现随机发送QQ表情,CQ码的范围是0~221(其中小黄脸的范围是0 ~ 39),随机获取整数来发送CQ编号对应的QQ表情。
random.random() : 生成一个随机的浮点数,在0 ~ 1之间
random.randint() : 随机生成一个int类型的数,可以指定这个数的范围。
from nonebot.adapters.cqhttp import Message
from nonebot import on_keyword
from nonebot.typing import T_State
from nonebot.adapters import Bot, Event
emoji = on_keyword({'发表情'})
@emoji.handle()
async def send_emoji(bot: Bot, event: Event, state: T_State):
emoji_msg = "[CQ:face,id=12]"
await emoji.send(Message(emoji_msg))
开启与QQ机器人的聊天窗口,运行测试如下所示:
QQ机器人发送QQ图片的实现
关于发送QQ图片CQ码的相关参数,展示如下所示:

示例: [CQ:image,file=http://baidu.com/1.jpg,type=show,id=40004]
图片最大不能超过30MB,PNG格式不会被压缩, JPG可能不会二次压缩, GIF非动图转成PNG,GIF动图原样发送(总帧数最大300张, 超过无法发出, 无论循不循环)
随机图片API免费接口网站:https://img.r10086.com/
from nonebot.adapters.cqhttp import Message
from nonebot import on_keyword
from nonebot.typing import T_State
from nonebot.adapters import Bot, Event
import requests
import random
picture = on_keyword("图片")
@picture.handle()
async def send_emoji(bot: Bot, event: Event, state: T_State):
img_url = await get_random_img()
msg = f"[CQ:image,file={img_url},type=show,id=40004]"
await get_random_img()
await picture.send(Message(msg))
async def get_random_img():
API_URL = 'https://api.r10086.com/王者荣耀.php'
data = requests.get(API_URL)
return data.url
await : 等待异步函数执行完毕,如果不加await,那就是还没有获取异步函数的返回值就发送,会发生报错。
开启与QQ机器人的聊天窗口,运行测试如下所示:

2.3 英语翻译功能
代码原理借助翻译接口进行翻译:https://api.vvhan.com/api/fy?text=?
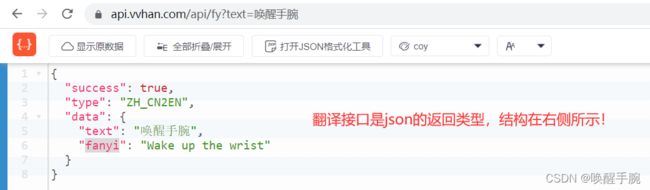
代码实现如下所示:
from nonebot import on_command
from nonebot.adapters.cqhttp import Bot, MessageEvent, Message, Event
from nonebot.typing import T_State
from aiocqhttp.exceptions import Error as CQHttpError
from nonebot.rule import Rule
import requests
async def _checker(bot: Bot, event: Event, state: T_State) -> bool:
return isinstance(event, MessageEvent)
tran = on_command('翻译', aliases={"英语"}, priority=1, rule=Rule(_checker))
@tran.handle()
async def handle_first_receive(bot: Bot, event: Event, state: T_State):
args = str(event.get_message()).strip()
if args:
state["translate"] = args
@tran.got("res", prompt="请问你要翻译的句子是?")
async def handle_city(bot: Bot, event: Event, state: T_State):
translate = state["res"]
url = f'https://api.vvhan.com/api/fy?text={translate}'
resp = requests.get(url).json()
result = resp['data']['fanyi']
id = event.get_user_id()
result = "[CQ:at,qq={}]".format(id) + '翻译结果:' + result
result = Message(result)
try:
await tran.send(result)
except CQHttpError:
pass
开启与QQ机器人的聊天窗口,运行测试如下所示:

当然朗读功能也非常容易实现:
from nonebot import on_command
from nonebot.adapters.cqhttp import Bot, MessageEvent, Message, Event
from nonebot.typing import T_State
from aiocqhttp.exceptions import Error as CQHttpError
from nonebot.rule import Rule
async def _checker(bot: Bot, event: Event, state: T_State) -> bool:
return isinstance(event, MessageEvent)
Tran = on_command('朗读', aliases={"发音"}, priority=1, rule=Rule(_checker))
@Tran.handle()
async def handle_first_receive(bot: Bot, event: Event, state: T_State):
args = str(event.get_message()).strip()
if args:
state["Translate"] = args
@Tran.got("res", prompt="请问你要朗读的句子是?")
async def handle_city(bot: Bot, event: Event, state: T_State):
Translate = state["res"]
result = "[CQ:tts,text={}]".format(Translate)
result = Message(result)
try:
await Tran.send(result)
except CQHttpError:
pass
2.4 安装ffmpeg音视频转换工具
FFmpeg项目最初是由Fabrice Bellard发起的,从2004年起由Michael Niedermayer领导进行维护。许多FFmpeg的开发者同时也是MPlayer项目的成员,FFmpeg在MPlayer项目中是被设计为服务器版本进行开发。
为了支持任意格式的语音发送, 你需要安装 ffmpeg
window下载安装包:https://www.gyan.dev/ffmpeg/builds/ffmpeg-release-full.7z
然后在 cmd 输入 (不能使用 powershell)
setx /M PATH "C:\Program Files\ffmpeg\bin;%PATH%"
其实就是设置path环境变量,也可以手动设置:

Ubuntu / Debian : 终端执行
apt install -y ffmpeg
# Centos7 及之前
yum install ffmpeg ffmpeg-devel
# CentOS8 及之后
dnf install ffmpeg ffmpeg-devel
2.5 发送QQ语音与视频
QQ机器人发送QQ语音
如果发送本地的音频文件作为语音发送:
CQ码:[CQ:record,file=http://baidu.com/1.mp3]
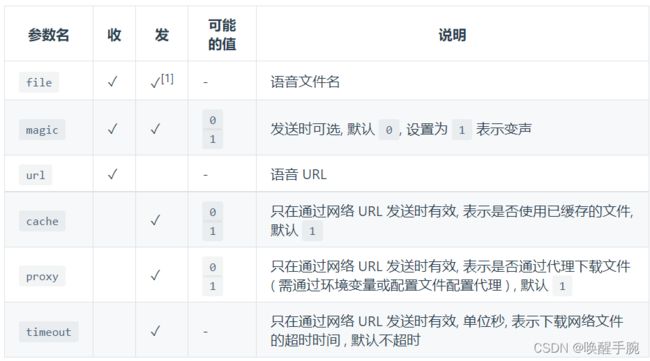
发送时, file 参数除了支持使用收到的语音文件名直接发送外, 还支持其它形式
当然我们也可以发送语音,通过文字转换成语音,当然是系统生成语音形式。
CQ码介绍:[CQ:tts,text=文字转换成语音的内容]
案例介绍,随机讲笑话的功能实现:
免费的随机笑话API接口:https://api.vvhan.com/api/xh?type=json
import json
import requests
from nonebot.adapters.cqhttp import Message
from nonebot import on_keyword
from nonebot.typing import T_State
from nonebot.adapters import Bot, Event
test = on_keyword({'笑话'})
@test.handle()
async def send_audio(bot: Bot, event: Event, state: T_State):
msg_text = await get_random_happySaying()
msg = f"[CQ:tts,text={msg_text}]"
await test.send(Message(msg))
async def get_random_happySaying():
API_URL = 'https://api.vvhan.com/api/xh?type=json'
data = requests.get(API_URL)
return json.loads(data.text)['joke']
开启与QQ机器人的聊天窗口,运行测试如下所示:

QQ机器人发送媒体视频
go-cqhttp-v0.9.38 起开始支持发送,需要依赖ffmpeg,等会会给大家讲解安装这个ffmpeg
CQ码:[CQ:video,file=http://baidu.com/1.mp4]

from nonebot.adapters.cqhttp import Message
from nonebot import on_keyword
from nonebot.typing import T_State
from nonebot.adapters import Bot, Event
video = on_keyword({'视频'})
@video.handle()
async def send_video(bot: Bot, event: Event, state: T_State):
video_msg = r"[CQ:video,file=https://img-baofun.zhhainiao.com/market/133/2366564fa6b83158208eb3181752a8d6_preview.mp4]"
await video.send(Message(video_msg))
开启与QQ机器人的聊天窗口,运行测试如下所示:

2.6 英语题目小测试
首先这个案例是结合数据库的,用非关系型数据库mongodb作为题库,Mongodb数据库是安装在服务器上的。
在本地测试的时候,需要修改Mongodb的配置文件BindIP,以及开启Mongodb的默认端口对应防火墙TCP==27017。
//查看运行状态
firewall-cmd --state
// 开放27017的端口
firewall-cmd --add-port=27017/tcp --permanent
// 重载生效刚才的端口设置
firewall-cmd --reload
另外python连接操作Mongodb需要的第三方库是pymongo,我们需要用pip3进行安装。
mongodb随机返回集合user中的10条数据
db.user.aggregate( [ { $sample: { size: 10 } } ] )
Mongodb数据库创建集合与文档,对应来存储我们的英语题目:
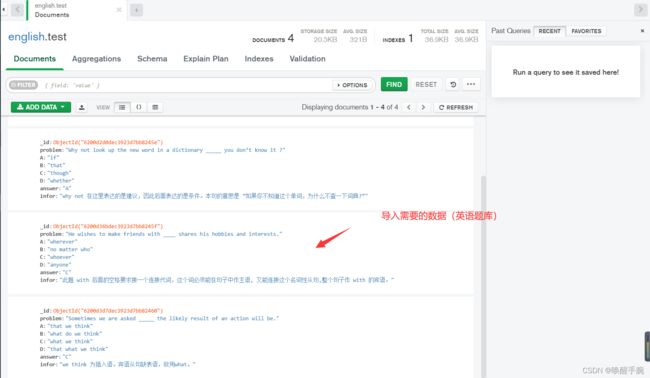
详细的插件开发代码如下:
from nonebot.adapters.cqhttp import Message
from nonebot import on_keyword
from nonebot.typing import T_State
from nonebot.adapters import Bot, Event
import pymongo
cli = pymongo.mongo_client.MongoClient("mongodb://root:[email protected]:27017")
eng = on_keyword({'测试'})
@eng.handle()
async def send_eng(bot: Bot, event: Event, state: T_State):
db = cli["english"]
# 选择数据库库
collection = db.test
data = collection.aggregate([{'$sample': {'size': 1}}])
res = data
for item in res:
problem = item.get("problem")
state['answer'] = item.get("answer")
choose = "\n\nA:" + item.get("A") + "\nB:" + item.get("B") + "\nC:" + item.get("C") + "\nD:" + item.get("D")
state['infor'] = item.get('infor')
id = event.get_user_id()
result = "[CQ:at,qq={}]".format(id) + '测试题目:' + problem + choose
await eng.send(Message(result))
@eng.got("res")
async def handle_city(bot: Bot, event: Event, state: T_State):
id = event.get_user_id()
if str(event.get_message()) == state['answer']:
result = "[CQ:at,qq={}]".format(id) + "恭喜你回答正确!" + "\n\n解析:" + state['infor']
await eng.send(Message(result))
else:
result = "[CQ:at,qq={}]".format(id) + "很抱歉回答错误!"
await eng.send(Message(result))
开启与QQ机器人的聊天窗口,运行测试如下所示:

2.7 数学公式作图
对应数学公式作图的,这边给出两种方案,第一种是matplotlib库进行数据可视化绘图,第二种就是调用第三方的API,这边推荐是 wolfram alpha 数学搜索引擎来制作。
wolfram alpha搜索引擎:https://www.wolframalpha.com/
经过测试我们发现这个网页是动态的,在使用requests进行爬取的时候,js的代码是不会被执行的,那么就需要动态网页爬取技术来实现,selenium通过控制浏览器搜索来实现。
Selenium 测试脚本可以使用任何支持的编程语言进行编码,并且可以直接在大多数现代 Web 浏览器中运行。在爬虫领域 selenium 同样是一把利器,能够解决大部分的网页的反爬问题,但也不是万能的,它最明显的缺点就是速度慢。
selenium安装:pip install -i https://pypi.douban.com/simple selenium
针对不同的浏览器,需要安装不同的驱动。下面列举了常见的浏览器与对应的驱动程序下载链接,部分网址需要 “科学上网” 才能打开,点击下载Chrome版驱动
在新标签页输入 chrome://settings/ 进入设置界面,然后选择 【关于 Chrome】查看自己的版本信息。这样在下载对应版本的 Chrome 驱动即可。
特别注意:将 chromedriver.exe保存到任意位置,并把当前路径保存到环境变量中(我的电脑>>右键属性>>高级系统设置>>高级>>环境变量>>系统变量>>Path)
from selenium import webdriver
# 不自动关闭浏览器
option = webdriver.ChromeOptions()
option.add_experimental_option("detach", True)
# 注意此处添加了chrome_options参数
driver = webdriver.Chrome(chrome_options=option)
driver.get('https://www.csdn.net/')
Wolfram alpha API调用:https://www.programmableweb.com/api/wolfram-alpha-rest-api
需要注册账号,选择API get start,具体过程略,大家查看文档就可以使用了。
开启与QQ机器人群聊的聊天窗口,运行测试如下所示:
2.8 群聊英语背词测试
效果是达到英语单词的抽测,每个群成员的积分可以持久化存储,这就需要数据库来完成数据存储。这边采用的是MySQL数据库进行持久化的存储。
数据库内容的展示,就是单词测试需要的词库,展示如下:
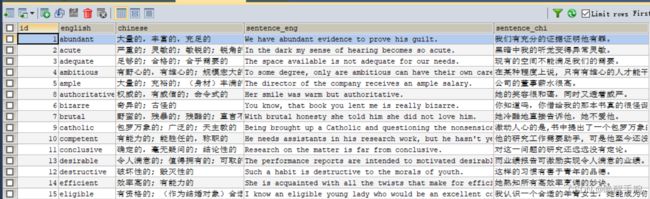
加载MySQL的配置文件的配置项,代码如下所示:
import os
import pymysql
import configparser
def conn_mysql_database():
path = os.path.join(os.path.dirname(os.path.abspath(__file__)) + '/conf/mysql.ini')
db_config = configparser.ConfigParser()
db_config.read_file(open(path, encoding='utf-8', mode='rt'))
conn = pymysql.connect(
host=db_config.get('mysql', 'host'),
# 连接名称,默认127.0.0.1
user=db_config.get('mysql', 'user'),
# 用户名
passwd=db_config.get('mysql', 'passwd'),
# 密码
port=int(db_config.get('mysql', 'port')),
# 端口,默认为3306
db=db_config.get('mysql', 'db'),
# 数据库名称
charset=db_config.get('mysql', 'charset'),
# 字符编码
)
return conn
为了让数据库的配置在源代码进行解耦的操作,那么我们需要单独的配置ini配置文件,然后采用Configparser第三方库进行导入配置项。

对于新的用户需要检查是否存在于MySQL数据库中,如果不在数据库中则需要进行添加用户,对于用户的ID这边采用的是uuid库生成的绝对id,uuid1()函数生成的随机字符串是32位16进制数,如:9352ad78-8a55-11ec-b57b-18cc18368a07
检查用户是否存在代码(不存在进行添加到数据库)展示如下:
import uuid
def check_user_exist(event: Event, conn: Connection):
cursor = conn.cursor()
sql = "SELECT * FROM USER WHERE qq = %s"
cursor.execute(sql, event.get_user_id())
if cursor.fetchone():
return
else:
sql = "insert into user values (%s, %s, 0)"
cursor.execute(sql, (uuid.uuid1(), event.get_user_id()))
conn.commit()
测试需要的单词选项是A、B、C三个选项,需要在数据库中随机抽取:
def test_english_word(conn: Connection):
cursor = conn.cursor()
sql = "SELECT * FROM word ORDER BY RAND() LIMIT 3"
cursor.execute(sql)
return cursor.fetchall()
对于主要 event propagation 事件处理的代码:
import random
from pymysql import Connection
from nonebot.adapters.cqhttp import Message
from nonebot import on_command
from nonebot.typing import T_State
from nonebot.adapters import Bot, Event
problem = on_command("eng")
@problem.handle()
async def send_problem(bot: Bot, event: Event, state: T_State):
conn = conn_mysql_database()
check_user_exist(event, conn)
point = find_user_point(event, conn)[2]
if str(event.get_message()) == 'my points':
cont = "Username : {}\nYour points : {}\nYour levels : LV.{}".format(event.get_user_id(), point,
int(point / 100) + 1)
msg = "[CQ:at,qq={}]".format(event.get_user_id()) + cont
await problem.finish(Message(msg))
else:
words = test_english_word(conn)
chinese_list = []
for item in words:
chinese_list.append(item[2])
eng_random_index = random.choice([0, 1, 2])
state['answer'] = ['A', 'B', 'C'][eng_random_index]
english_cont = "【{}】".format(words[eng_random_index][1]) + "请选择正确的解释?"
# 单词的答案添加到 T_state 临时状态量中
state['english'] = words[eng_random_index]
choose_cont = "\n[A] : " + chinese_list[0] + "\n[B] : " + chinese_list[1] + "\n[C] : " + chinese_list[2]
# 单词中文的选择
msg = "[CQ:at,qq={}]".format(event.get_user_id()) + english_cont + choose_cont
await problem.send(Message(msg))
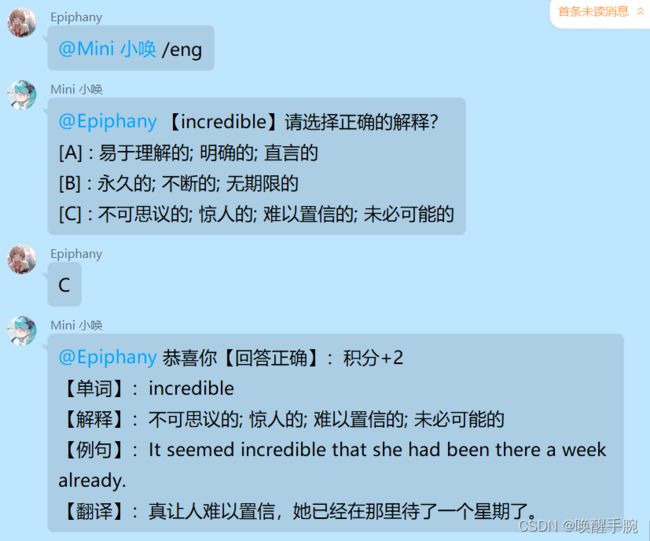
QQ机器人发起测试后,对于群员提问者的作答进行判断,调用 @got装饰器:
@problem.got("test")
async def test_english_word(bot: Bot, event: Event, state: T_State):
conn = conn_mysql_database()
cursor = conn.cursor()
word = state['english']
cont = "\n【单词】:{}\n【解释】:{}\n【例句】:{}\n【翻译】:{}".format(word[1], word[2], word[3], word[4])
if str(event.get_message()) == state['answer']:
sql = "UPDATE USER SET POINT = POINT + 2 WHERE qq = %s"
cursor.execute(sql, event.get_user_id())
msg = "[CQ:at,qq={}]".format(event.get_user_id()) + "恭喜你【回答正确】:积分+2" + cont
else:
sql = "UPDATE USER SET POINT = POINT - 1 WHERE qq = %s"
cursor.execute(sql, event.get_user_id())
msg = "[CQ:at,qq={}]".format(event.get_user_id()) + "很抱歉【回答错误】:积分-1" + cont
await problem.send(Message(msg))
conn.commit()
对于用户去查询自己的积分与等级编写函数,这个函数在@handle装饰器所装饰的主要事件驱动函数中会被调用,具体如上已经代码展示出来了。
def find_user_point(event: Event, conn: Connection):
cursor = conn.cursor()
sql = "SELECT * FROM USER WHERE qq = %s"
cursor.execute(sql, event.get_user_id())
return cursor.fetchone()
开启与QQ机器人群聊的聊天窗口,运行测试如下所示:
查询分数的效果展示如下所示:

排名功能的增加,这边有同学想增加排名功能,那么这边添加一下排名的功能:
def sort_user_points(event: Event, conn: Connection):
cursor = conn.cursor()
sql = "SELECT * FROM USER ORDER BY POINT DESC limit 5"
cursor.execute(sql)
return cursor.fetchall()
"""
@handle事件函数增加内容参数的判断
elif str(event.get_message()) == 'sort':
users = sort_user_points(event, conn)
cont = "最新排名展示:\n"
for index, user in enumerate(users):
cont = cont + "第{}名[{}]【{}分】\n".format(index + 1, user[1], user[2])
msg = "[CQ:at,qq={}]".format(event.get_user_id()) + cont
await problem.finish(Message(msg))
"""
在聊天中调用/eng sort 查询排名的状况:

结合mysql进行数据持久化的操作,完整的代码展示如下所示:
import random
import uuid
import os
import pymysql
from pymysql import Connection
import configparser
from nonebot.adapters.cqhttp import Message
from nonebot import on_command
from nonebot.typing import T_State
from nonebot.adapters import Bot, Event
problem = on_command("eng")
@problem.handle()
async def send_problem(bot: Bot, event: Event, state: T_State):
conn = conn_mysql_database()
check_user_exist(event, conn)
point = find_user_point(event, conn)[2]
if str(event.get_message()) == 'my points':
cont = "NAME : {}\nPOINTS : {}\nLEVEL : LV.{}".format(event.get_user_id(), point, int(point / 100) + 1)
msg = "[CQ:at,qq={}]".format(event.get_user_id()) + cont
await problem.finish(Message(msg))
elif str(event.get_message()) == 'sort':
users = sort_user_points(event, conn)
cont = "最新排名展示:"
for index, user in enumerate(users):
cont = cont + "\n第{}名[{}]【{}分】".format(index + 1, user[1], user[2])
msg = "[CQ:at,qq={}]".format(event.get_user_id()) + cont
await problem.finish(Message(msg))
else:
words = test_english_word(conn)
chinese_list = []
for item in words:
chinese_list.append(item[2])
eng_random_index = random.choice([0, 1, 2])
state['answer'] = ['A', 'B', 'C'][eng_random_index]
english_cont = "【{}】".format(words[eng_random_index][1]) + "请选择正确的解释?"
# 单词的答案添加到 T_state 临时状态量中
state['english'] = words[eng_random_index]
choose_cont = "\n【A】" + chinese_list[0] + "\n【B】" + chinese_list[1] + "\n【C】" + chinese_list[2]
# 单词中文的选择
msg = "[CQ:at,qq={}]".format(event.get_user_id()) + english_cont + choose_cont
await problem.send(Message(msg))
conn.close()
@problem.got("test")
async def test_english_word(bot: Bot, event: Event, state: T_State):
conn = conn_mysql_database()
cursor = conn.cursor()
word = state['english']
iciba_url = f"http://www.iciba.com/word?w={word[1]}"
cont = "\n【单词】:{}\n【解释】:{}\n【例句】:{}\n【翻译】:{}\n【详细】:{}".format(word[1], word[2], word[3], word[4], iciba_url)
if str(event.get_message()).upper() == state['answer']:
sql = "UPDATE user SET POINT = POINT + 2 WHERE qq = %s"
cursor.execute(sql, event.get_user_id())
msg = "[CQ:at,qq={}]".format(event.get_user_id()) + "恭喜你【回答正确】:积分+2" + cont
else:
sql = "UPDATE user SET POINT = POINT - 1 WHERE qq = %s"
cursor.execute(sql, event.get_user_id())
msg = "[CQ:at,qq={}]".format(event.get_user_id()) + "很抱歉【回答错误】:积分-1" + cont
await problem.send(Message(msg))
conn.commit()
conn.close()
def check_user_exist(event: Event, conn: Connection):
cursor = conn.cursor()
sql = "SELECT * FROM user WHERE qq = %s"
cursor.execute(sql, event.get_user_id())
if cursor.fetchone():
return
else:
sql = "insert into user values (%s, %s, 0)"
cursor.execute(sql, (uuid.uuid1(), event.get_user_id()))
conn.commit()
def find_user_point(event: Event, conn: Connection):
cursor = conn.cursor()
sql = "SELECT * FROM user WHERE qq = %s"
cursor.execute(sql, event.get_user_id())
return cursor.fetchone()
def sort_user_points(event: Event, conn: Connection):
cursor = conn.cursor()
sql = "SELECT * FROM user ORDER BY POINT DESC limit 10"
cursor.execute(sql)
return cursor.fetchall()
def test_english_word(conn: Connection):
cursor = conn.cursor()
sql = "SELECT * FROM word ORDER BY RAND() LIMIT 3"
cursor.execute(sql)
return cursor.fetchall()
def conn_mysql_database():
path = os.path.join(os.path.dirname(os.path.abspath(__file__)) + '/conf/mysql.ini')
db_config = configparser.ConfigParser()
db_config.read_file(open(path, encoding='utf-8', mode='rt'))
conn = pymysql.connect(
host=db_config.get('mysql', 'host'),
# 连接名称,默认127.0.0.1
user=db_config.get('mysql', 'user'),
# 用户名
passwd=db_config.get('mysql', 'passwd'),
# 密码
port=int(db_config.get('mysql', 'port')),
# 端口,默认为3306
db=db_config.get('mysql', 'db'),
# 数据库名称
charset=db_config.get('mysql', 'charset'),
# 字符编码
)
return conn
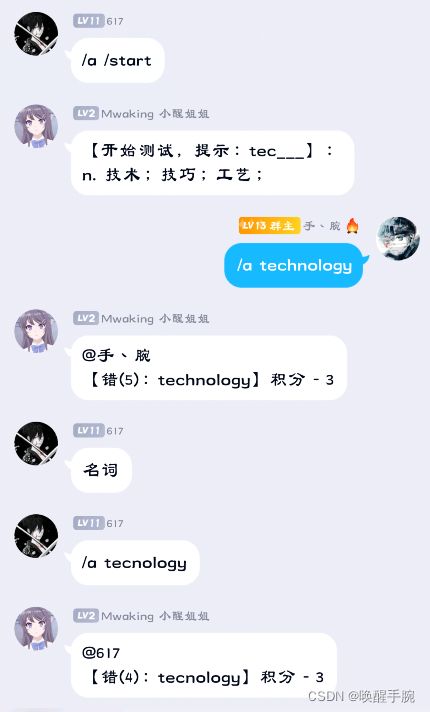
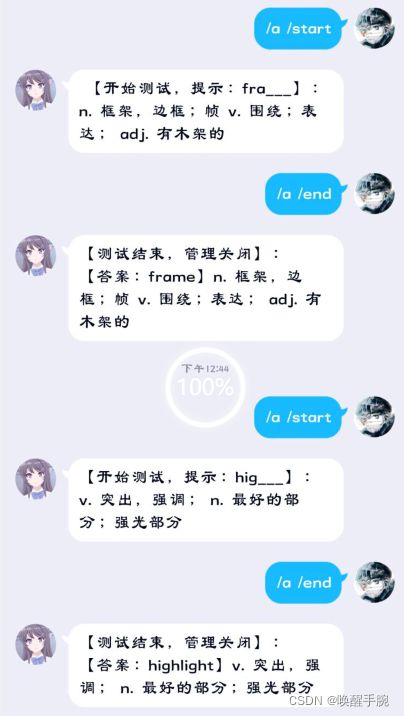
2.9 群聊互动式猜词答题
上面讲的一下案例都是对应1对1的互动模式,就算在群里的时候,照样还是群聊的模式,那么我们制作多人参与的案例:
对于事件的处理采用了on_command(),但是对应变量采用的是全局变量的模式,当然全局变量是非线程安全的,后期进行优化。
数据库采用的是redis数据库,速度比mysql的效率更高:
from nonebot.adapters.cqhttp import Message
from nonebot import on_message, on_startswith, on_command
from nonebot.typing import T_State
from nonebot.adapters import Bot, Event
from redis import StrictRedis
test = on_command("a")
global temp
global test_state
global test_answer
global test_chinese
test_state = False
temp = 5
@test.handle()
async def handle_first_receive(bot: Bot, event: Event, state: T_State):
global temp, test_state, test_answer, test_chinese, pool
if str(event.get_message()) != "/start":
# 开启答题的状态
if test_state:
temp = temp - 1
if temp == 0:
# 超时作答
test_state = False
await test.send(Message("【测试结束,超时作答】:\n" + test_chinese))
return
if str(event.get_message()) == "/end" and (
event.get_user_id() == "1620***902" or event.get_user_id() == "2196***850"):
# 手动关闭
test_state = False
await test.send(Message("【测试结束,管理关闭】:\n【答案:{}】".format(test_answer) + test_chinese))
return
if str(event.get_message()) == test_answer:
# 正确作答
test_state = False
redis = StrictRedis(host='118.***.***.156', port=6379, password='***', decode_responses=True)
redis.incrby(f"qq{event.get_user_id()}", 5)
redis.close()
await test.send(Message(
"【测试结束,成功作答】:\n" + "【恭喜QQ:{} 积分+5】".format(event.get_user_id()) + "\n【答案:{}】".format(
test_answer) + test_chinese))
return
else:
redis = StrictRedis(host='118.***.***.156', port=6379, password='***', decode_responses=True)
redis.decrby(f"qq{event.get_user_id()}", 3)
redis.close()
await test.send(Message("[CQ:at,qq={}]".format(event.get_user_id()) + "\n【错({}):{}】".format(temp + 1, str(event.get_message())) + "积分 - 3"))
return
else:
return
else:
if not test_state:
import requests
data = requests.get("http://118.***.***.156:8081/bot/1")
words = data.json()
problem = words[0]
test_answer = problem["english"]
test_chinese = chinese(problem["chinese"])
pro_show = test_answer[0:3] + '___'
temp = 5
test_state = True
await test.send(
Message(f"【开始测试,提示:{pro_show}】:\n" + test_chinese))
else:
return
def chinese(chi_list):
meaning = ""
for item in chi_list:
for key in item:
meaning = meaning + key + ' ' + item[key] + ' '
return meaning
开启与QQ机器人的聊天窗口,运行测试如下所示:
左边的是群聊的展示,右边是私聊的展示,都是可以使用的:
3. 云服务器部署QQ机器人
我们可以在本地开启我们的项目,但是我们的电脑不会一直开着,所以我们要借助服务器,服务器可以以保护进程的模式一直开启着我们的程序。
这里我们以腾讯云为例介绍
3.1 服务器端go-cqhttp安装
go-cqhttp安装下载网址:https://github.com/Mrs4s/go-cqhttp/releases/tag/v1.0.0-beta2

借助宝塔面板进行管理服务器面板(如果不使用宝塔,也可以进行SSH连接进行操作),展示如下:

Linux解压缩命令:
tar -xzvf file.tar.gz // 解压tar.gz
Linux解压缩 cq-http 的压缩包(宝塔面板)

解压成功后展示如下所示:
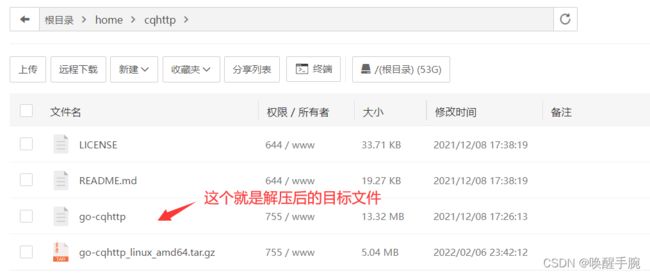
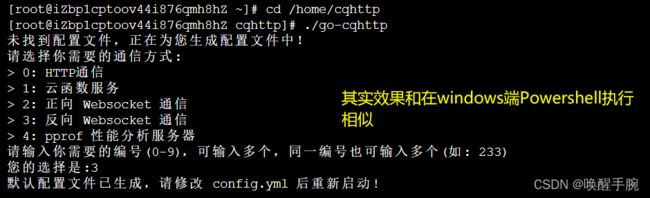
接下来,cd到解压目录,输入 ./go-cqhttp, Enter运行 , 此时将提示:
[WARNING]: 尝试加载配置文件 config.yml 失败: 文件不存在
[INFO]: 默认配置文件已生成,请编辑 config.yml 后重启程序.
参照 config.md (opens new window)和你所用到的插件的 README 填入参数,再次输入 ./go-cqhttp,Enter运行。(如出现需要认证的信息,请自行认证设备)
3.2 服务器端go-cqhttp配置
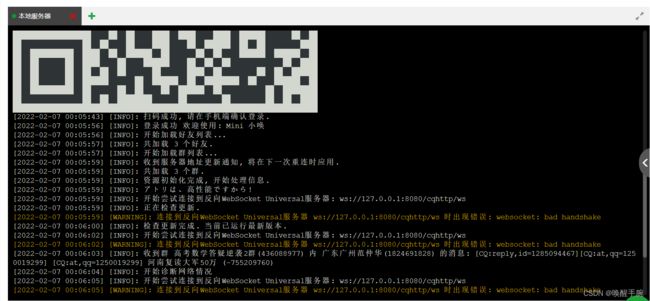
如上所述,再次./go-cqhttp结束后会发现生成了config.yml配置文件。

我这边借助是宝塔在线编辑器,如果你们使用的是SSH服务,那么可以通过vim进行编辑,具体配置项上面和win一样,这里略···
配置config.yml完成后,再次执行./go-cqhttp启动协议端服务。
3.3 服务器端python环境
选择要安装python的目录,获取下载最新python的安装压缩包:
cd /home/python
wget https://www.python.org/ftp/python/3.10.2/Python-3.10.2.tgz
下载完成后解压缩:

说明:tar是Linux系统的解压命令,这句话是把文件解压到文件所在的文件夹。如果是土星话操作界面可以向在WIN上一样解压文件。同样也可以像在win上一样下载Python源文件放置在指定文件夹。
tar -zxvf Python-3.10.2.tgz
进入解压缩后的目录,安装配置:
cd Python-3.10.2/
./configure
执行 ./configure 时,如果报错:configure: error: no acceptable C compiler found in $PATH
说明没有安装合适的编译器。这时,需要安装/升级 gcc 及其它依赖包。
sudo apt-get install make gcc gcc-c++
安装编译Python3源文件所需的编译环境
$ yum install -y gcc
$ yum install -y zlib*
$ yum -y install zlib-devel bzip2-devel openssl-devel ncurses-devel sqlite-devel readline-devel tk-devel gdbm-devel db4-devel libpcap-devel xz-devel
说明:这里功能很简单,要说的是yum命令。虽然linux也可以像win上一样在指定的软件的官网下载软件,但是有一些常用且公用的软件会被放置在特定的远程仓库里面,可以通过使用yum命令来安装。而且yum命令还可以主动帮用户解决软件的依赖问题。所以想要学好linux的话了解一下yum也是必须的。此外还有anaconda也是类似的软件。
进入Python3 源文件文件夹
cd Python-3.10.2/
指定安装python的目录:说明:不要忘记最前面的“.”,如下所示:/usr/local/python3就是安装的目录
./configure --prefix=/usr/local/python3 --with-ssl
编译源文件,正式安装
make
make install
建立软连接(配置环境变量)
$ ln -s /usr/local/python3/bin/python3 /usr/bin/python3
$ ln -s /usr/local/python3/bin/pip3 /usr/bin/pip3
在执行ln -s /usr/python/bin/python3(python 安装目录) /usr/bin/python
的时候有可能会报错
报错信息如下:
ln: failed to create symbolic link '/usr/bin/python': File exists
解决方法:ln -sf 加一个 f 即可
ln -sf /usr/python/bin/python3(python 安装目录) /usr/bin/python
建立软连接说明:
很多教程都有最后一步,但是很少有网站会告诉你为什么会有最后一步。所谓软连接就相当于win下的快捷方式。
你可以通过快捷方式打开你想要使用的软件。但是为什么要把快捷方式放在/usr/bin/呢。这就涉及到环境变量的问题了,你当然可以不使用最后的软连接而直接把/usr/local/python3/bin加到环境变量里面,那随你喜好。
但是在这里/usr/bin/是默认已经在环境变量里面的,把快捷方式放到这个文件夹相当于间接的把该Python3加入环境变量,这样你才可以直接在终端输入“python3”打开Python。
3.4 服务器端搭建反向服务器
我们之前在window下载的nonebot相关的python第三方库,同样也需要在服务器上进行下载,否则启动会报错。
pip3 install nonebot2==2.0.0a16
pip3 install nonebot-adapter-cqhttp==2.0.0a16
pip3 nonebot-plugin-apscheduler==0.1.2
# 相关需要安装的库,非bot本身所需,而是plugins插件的所需
pip3 pymysql
pip3 install dbutils
服务器端 pip 显示未安装的解决方案:
这里,我发现centos7.5的自带python2.7,且bin目录下并没有安装pip,因此在这里问题不是环境变量的问题,从而不能单纯从增加环境变量的角度去解决。我们应该做得是直接安装pip工具。过程如下,也比较简洁:
https://bootstrap.pypa.io/pip/[python版本号]/get-pip.py
python get-pip.py
如果出现以下的报错:解决方案是:pip3 install aiocqhttp
ModuleNotFoundError: No module named ‘aiocqhttp’
pip3 install aiocqhttp
把我们的项目文件上传到服务器上进行运行:
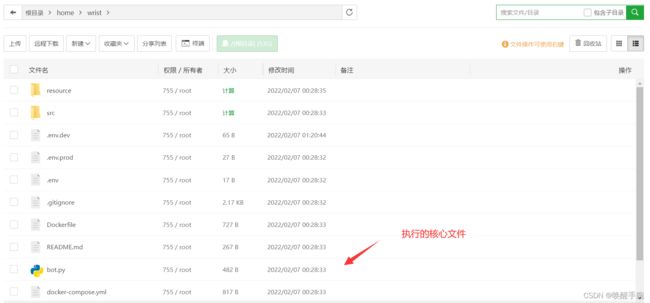
3.5 服务器端运行测试
如何运行我们的项目,还有我们的协议端cq-http文件,因为我们是要将程序在后台一直执行的,所以要以守护进程的形式进行执行文件:
nohup 文件名称 &
当我们成功以守护进程方式启动我们的bot.py和cq-http,可以查看进程看到如下所示:
反向服务器 bot.py 后台进程

协议端 cq-http文件 后台进程
![]()
接下来,我们可以开启我们和QQ机器人的会话,发现可以进行交互聊天了,注意点就是如果启动bot.py报错,可能是插件加载的需要第三方库没有安装,比如 requests
当然如果想要停止(杀死)进程:kill PID
3.6 linux安装ffmpeg工具
如果想要在liunx端进行发送任意格式的视频或者音频,那么就需要借助ffmpeg音视频转换工具,在linux安装比在windows端安装过程要复杂,接下来就详细的介绍下。
官网下载:http://ffmpeg.org/download.html
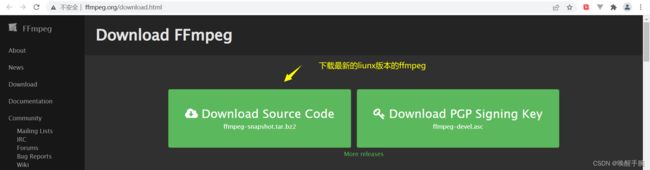
下载之后上传至Linux任意的文件夹(一般是home下)准备安装,首先解压安装包
tar -xjvf ffmpeg-snapshot.tar.bz2
执行上述的命令,会在压缩包的同级目录下,生成解压后的文件夹。
如果现在执行configure配置的话,可能会报如下的错误:

错误的意思是 yasm/nasm 包不存在或者很旧,可以使用–disable-yasm禁用这个选项编译,yasm是一款汇编器,并且是完全重写了nasm的汇编环境,接收nasm和gas语法,支持x86和amd64指令集,所以这里安装一下yasm即可。
安装yasm过程介绍如下所示:
官网下载:http://yasm.tortall.net/Download.html
下载之后上传至Linux准备安装,首先解压安装包,然后依次进行如下的操作:
tar -xvzf yasm-1.3.0.tar.gz
cd yasm-1.3.0/
./configure
make
make install
编译参数都是默认的,直接安装到系统中即可。
继续安装ffmpeg,接下来就是编译安装,配置环境变量操作
安装成功之后继续回到ffmpeg解压后的目录,执行下面命令编译并安装
./configure --enable-shared --prefix=/usr/local/ffmpeg
make
make install
--prefix=[安装地址],make编译过程有点长,耐心等待。
make install会把ffmpeg相关执行程序、头文件、lib库安装在/usr/local/ffmpeg/下 耐心等待完成之后执行。
耐心等待完成之后执行:
cd /usr/local/ffmpeg/
进入安装目录,查看一下发现有bin, include, lib, share这4个目录
bin是ffmpeg主程序二进制目录
include是C/C++头文件目录
lib是编译好的库文件目录
share是文档目录
接下来cd 到 bin 目录:执行./ffmpeg -version,正常情况出现如下报错:原因是lib目录未加载到链接到系统库中。

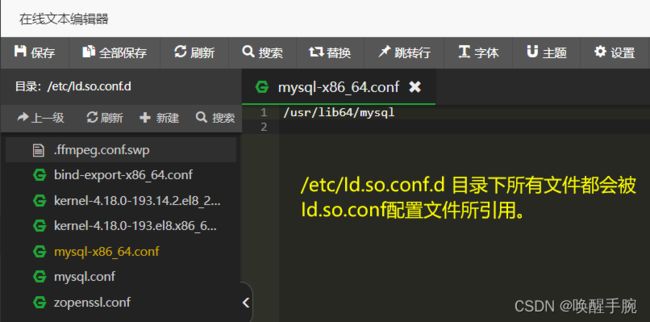
系统ld目录列表在/etc/ld.so.conf中,打开文件,在底部插入/usr/local/ffmpeg/lib,之后保存并退出,然后执行 ldconfig 使配置生效,现在再次执行 ./ffmpeg -version 显示就正常了。
第二种方式:系统ld目录列表在/etc/ld.so.conf中,打开文件会发现,里面引用了/etc/ld.so.conf.d/下面所有的.conf文件,比如mysql-x86_64.conf,创建一个文件并写入lib路径即可,执行命令: vim /etc/ld.so.conf.d/ffmpeg.conf,然后添加一行内容: /usr/local/ffmpeg/lib,然后执行 ldconfig 使配置生效,现在再次执行 ./ffmpeg -version 显示就正常了。
执行结果如下所示:
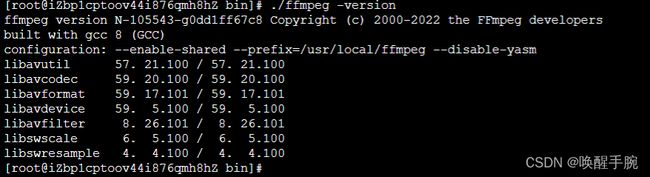
ffmpeg相关的库主要是以下7个
libavutil:用于多媒体编程,主要包含安全合适的字符串操作函数、数学运算函数、随机数字生产器、数据结构、多媒体处理的相关函数(如对像素和采样格式的计数)等,但它不是libavcodec和libavformat所需的库代码;
libavcodec、libavformat:有些视频文件格式(如AVI)没有指出应该使用哪种编码(如h.264)来解析音频和视频数据,它们只是按视频格式封装音视频数据,所以经常碰到打开视频文件只能听到声音而没有画面,则用libavformat来解析视频文件并将编码流分离出来,libavcodec对流进行解码;
libavdevice:为一些常见的多媒体输入或输出设备提供了抓取和渲染的通用架构,并且很多输入和输出设备,如Video4Linux2, VfW, DShow, and ALSA;
libavfilter:提供了一个通用规定音视频过滤架构,包括一些过滤器、源、汇(什么是源、汇,我也没搞清楚,待研究)
libswscale:执行高度优化的图像缩放、色彩、像素格式转换操作
libswresample:执行高度优化的音频重采样、重换算、样本格式转换操作
在环境变量中添加ffmpeg
为了在任何目录在都能使用ffmpeg,则需要在环境变量中添加,打开/etc/profile文件,添加新的环境变量,展示如下:
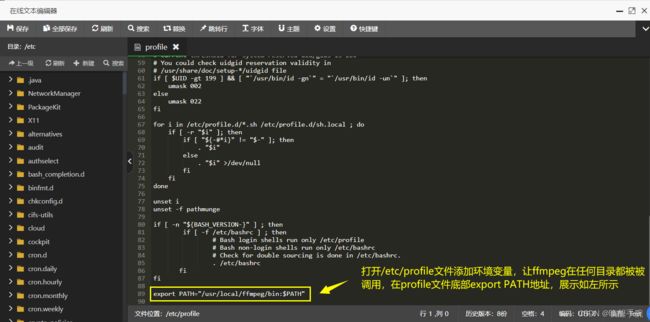
为了让服务器不重启就生效修改后的profile配置文件,执行source /etc/profile
测试ffmpeg,转换视频格式,比如:将mp4格式转换成avi格式
ffmpeg -i /home/apple.mp4 -acodec copy -vcodec copy /home/apple2.avi
4. 机器人第三方API调用
这边介绍下,对于第三方的调用接口的测试
4.1 wolfram数学搜索引擎
Wolfram alpha API调用官网:https://www.programmableweb.com/api/wolfram-alpha-rest-api
需要注册账号,选择API get start,具体过程略,大家查看文档就可以使用了。官方API文档
注册成功后就登录到自己控制页:https://developer.wolframalpha.com/portal/myapps/index.html

因为Wolfram提供的API有很多的类型,大家可以根据自己的需求进行调用,每种API都有对应的参考文档,接下来我这边是机器人的开发,所以就调用问答API做案例测试:

use the i parameter to specify the URL-encoded input for your query. For instance, here is a query for “How much does the Earth weigh?”:
http://api.wolframalpha.com/v1/conversation.jsp?appid=DEMO&i=How+much+does+the+earth+weigh%3f
上面是官方文档的介绍,就是API链接要提供两个参数,第一个就是你的AppID,第二个就是你的查询语句:
http://api.wolframalpha.com/v1/conversation.jsp?appid=【你的AppID】&i=【你的查询语句】
当使用有效的 AppID 执行时,此 URL 将返回一行对话文本,其中包含对您的查询的计算响应,以及用于继续对话的标识符和主机 URL。在极少数情况下,还会返回一个额外的 s 参数:
{"result" : "The answer is about 5.97 times 10 to the 24th power kilograms.",
"conversationID" : "MSP6171ce6c8h9c1d8941900003cc43ebfa8972fg3",
"host" : "www4b.wolframalpha.com",
"s" : "3"}
另一种语音回复response的API,也非常好用:
http://api.wolframalpha.com/v1/spoken?appid=你的AppID&i=How+far+is+Los+Angeles+from+New+York%3f
4.2 wolfram智能问答API
由于Wolfram是不支持中文作为参数进行调用的,所以我们需要提前把中文转换成英文,当然Wolfram调用的结果也是英文的,也需要把结果转换成中文。
这边采用的是Wolfram回复API接口:
http://api.wolframalpha.com/v1/spoken?appid=你的AppID&i=How+far+is+Los+Angeles+from+New+York%3f
接下来,就是测试环节,我们编写我们的插件:
from nonebot.adapters.cqhttp import Message
from nonebot import on_command
from nonebot.typing import T_State
from nonebot.adapters import Bot, Event
import requests
infor = on_command("呼叫小唤")
@infor.handle()
async def send_answer(bot: Bot, event: Event, state: T_State):
resp = await get_wolfram_resp(event.get_message())
result = {
"type": "tts",
"data": {
"text": resp
}
}
await infor.send(Message(result))
async def get_wolfram_resp(cont:str):
TRANS_URL = f'https://api.vvhan.com/api/fy?text={cont}'
resp = requests.get(TRANS_URL).json()
cont = resp['data']['fanyi']
# 此时的cont是翻译后的`发送者的问题`(英文的)
API_URL = 'http://api.wolframalpha.com/v1/spoken?appid=你的AppID&i={}'.format(cont)
data = requests.get(API_URL)
# 此时的data是Wolfram调用后的`回复答案`,是英文的
TRANS_URL = f'https://api.vvhan.com/api/fy?text={data.text}'
resp = requests.get(TRANS_URL).json()
cont = resp['data']['fanyi']
# 需要把Wolfram回答转换成中文,如上再次调用翻译的接口
return cont
开启与QQ机器人的聊天窗口,运行测试如下所示:
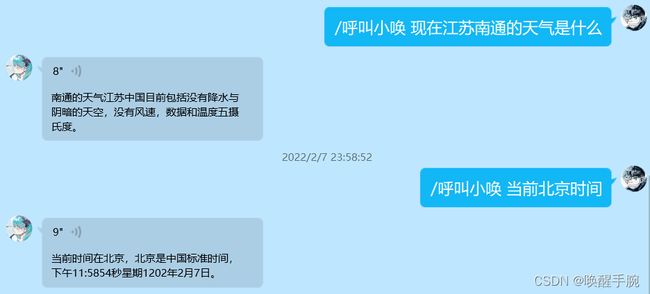
4.3 wolfram计算搜索API
在人工智能篇没有提到的部分,我这边再写下案例,就是首先你必须有APPID,首先去Wolfram的官网,滑动到最底部,点击如下所示的地方,去Wolfram开发者那边申请:

反正1个月2000次免费调用的机会,大家如果次数用完了,多注册几个账号就行,你父母、爷爷奶奶、外公外婆、舅舅舅妈、姑姑叔叔都是申请资源呀。
Next, use the i parameter to specify the URL-encoded input for your query. For instance, here is a query for “What airplanes are flying overhead?”:
http://api.wolframalpha.com/v1/simple?appid=DEMO&i=What+airplanes+are+flying+overhead%3F
记住返回值是张图片,这个路径映射到是张图片的资源目录:

所以在编写我们QQ机器人插件的时候,展示如下所示:
from nonebot.adapters.cqhttp import Message
from nonebot import on_command
from nonebot.typing import T_State
from nonebot.adapters import Bot, Event
search = on_command("math")
async def send_math(bot: Bot, event: Event, state: T_State):
txt = str(event.get_message())
img_url = f"http://api.wolframalpha.com/v1/simple?appid=你的AppID&i={txt}"
result = f"[CQ:image,file={img_url}]"
await search.send(Message(result))
最后我们演示一下,结果如下所示:输入指令:/math

4.4 青云客智能聊天API
上面的Wolfram的接口,其实主要用于科学计算上比较多,比较好的对话API技术免费的API推荐是青云客,无需注册就能够免费调用,每个主机IP,10分钟内有200次的上线次数。
青云客的API官方网站:http://api.qingyunke.com/

青云客智能聊天请求的API接口:
http://api.qingyunke.com/api.php?key=free&appid=0&msg=【问题】
接口的response是json格式,展示如下所示:
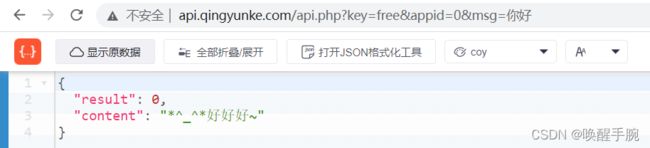
接下来,就是测试环节,我们依旧使用QQ机器人来测试,编写我们的插件:
import json
from nonebot.adapters.cqhttp import Message
from nonebot import on_command
from nonebot.typing import T_State
from nonebot.adapters import Bot, Event
import requests
saying = on_command("小唤同学")
@saying.handle()
async def send_saying(bot: Bot, event: Event, state: T_State):
resp = await get_saying_resp(event.get_message())
result = {
"type": "tts",
"data": {
"text": resp
}
}
await saying.send(Message(result))
async def get_saying_resp(cont: str):
QYK_URL = f"http://api.qingyunke.com/api.php?key=free&appid=0&msg={cont}"
data = requests.get(QYK_URL).text
answer = json.loads(data)['content']
return answer
开启与QQ机器人的聊天窗口,运行测试如下所示:

4.5 百度云二维码生成API
百度云人工智能:二维码生成识别
二维码API官方网站:https://apis.baidu.com/store/detail/581576df-bc52-4e4a-8a3a-2abd6035e7ae
按照设定的参数、模板生成二维码,自动检测图片中的二维码,并解析识别出二维码中包含的文字信息。

新人注册能够免费的进行购买,购买后在百度云的个人控制台可以查看,具体如下:

二维码生成的代码测试案例如下所示:
import requests
# 二维码生成 Python示例代码
if __name__ == '__main__':
url = 'http://qrcode.api.bdymkt.com/qrcode/generate'
headers = {
'Content-Type': 'application/json;charset=UTF-8',
'X-Bce-Signature': 'AppCode/【你的AppCode】'
}
data = {
"data": "文本或 URL",
# 字符串表示(URL地址,或者链接资源等)
"size": 20,
# 图片大小 整数类型:1-20 ,图片大小为:84+24*(size-1).如 size 为 1 时,图片的像素为 84px * 84px。 默认为10。
"level": "L",
# 纠错级别,取值为 L/M/Q/H。 默认为 Q。
"format": "jpg",
# 生成图片的格式,支持jpeg、jpg、png、gif。 默认为 jpg。
"logo": "二维码中间的LOGO图片"
# 生成二维码中间 logo 图片的 URL 地址,用正方形或近似正方形的图片。
}
r = requests.post(url, headers=headers, json=data)
print(r.content) # 生成二维码的地址
相应的结果是生成二维码的地址,展示如下:
b'{"imageUrl":"https://bj.bcebos.com/qr-code/220211151f19e445695f.jpg"}'
4.6 讯飞语音识别API
首先登录讯飞开放平台的官网进行注册账号:https://www.xfyun.cn/
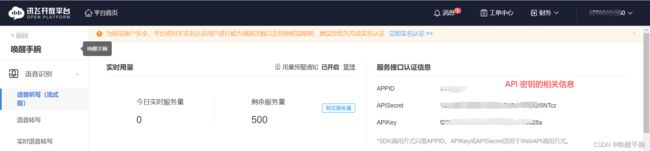
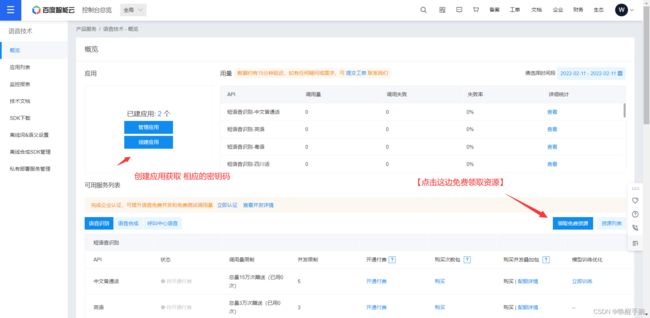
创建应用,获取API授权密钥进行测试:
待更新 ······略
4.7 百度云智能语音生成API
Python实现变声器功能:点击访问官方API地址
在本地调用API进行测试前,下载百度智能云API的模块库:
该函数在baidu-aip模块下
模块安装:在cmd窗口输入:pip install baidu-aip
from aip import AipSpeech
详细的代码展示:运行结束会在当前目录生成相应的mp3文件
代码测试展示如下:
from aip import AipSpeech
app_id = "你的app_id"
api_key = "你的api_key"
secret_key = "你的secret_key"
client = AipSpeech(app_id, api_key, secret_key) # 实例化
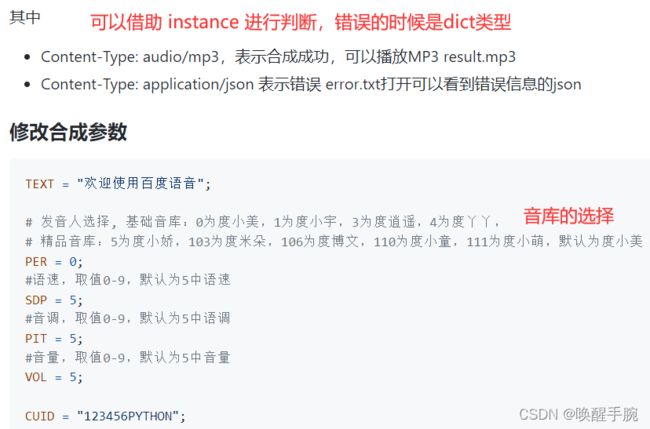
result = client.synthesis("天空一无所有,为何给我安慰!", "zh", "1", {
"vol": 5, # 音量
"spd": 5, # 语速
"pit": 5, # 语调
"per": 4,
# 发音人选择, 基础音库:0为度小美,1为度小宇,3为度逍遥,4为度丫丫,
# 精品音库:5为度小娇,103为度米朵,106为度博文,110为度小童,111为度小萌,默认为度小美
})
with open("audio.mp3", "wb") as f:
f.write(result)
print("语音已生成成功!")
4.8 百度云机器翻译API
百度云机器翻译API文档:https://cloud.baidu.com/doc/MT/s/nkqrzmbpc
词典资源
词典分中英词典,由于每个词属性不同,词典结果不一定包含所有部分。 如源语言为中文,词典数据包括:拼音、词性、中文释义、英文释义、近义词等资源。 如源语言为英文,词典数据包括:英文释义、中文释义、音标、核心词汇类别等。 注:单个 query 需为词、词组或短语,如 query 为句子,则 dict 字段为空。
语音合成资源:
语音合成资源包含 query 原文、译文的发音,以 mp3 文件格式提供。 注:单个query内不支持分段,只有1段且字符数量不超过200的query才会返回tts字段。
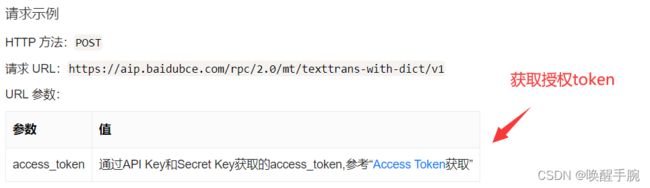
百度AIP开放平台使用OAuth2.0授权调用开放API,调用API时必须在URL中带上access_token参数,获取Access Token的流程如下:

代码方式获取token的方式如下:
# encoding:utf-8
import requests
# client_id 为官网获取的AK, client_secret 为官网获取的SK
host = 'https://aip.baidubce.com/oauth/2.0/token?grant_type=client_credentials&client_id=【官网获取的AK】&client_secret=【官网获取的SK】'
response = requests.get(host)
if response:
print(response.json())
服务器返回的JSON文本参数如下:
- access_token: 要获取的Access Token;
- expires_in: Access Token的有效期(秒为单位,有效期30天);
- 其他参数忽略,暂时不用;
代码调用测试如下所示:(百度智能云翻译API测试)
import requests
import random
import json
token = '【调用鉴权接口获取的token】'
url = 'https://aip.baidubce.com/rpc/2.0/mt/texttrans-with-dict/v1?access_token=' + token
q = '输入query'; # example: hello
# For list of language codes, please refer to `https://ai.baidu.com/ai-doc/MT/4kqryjku9#语种列表`
from_lang = '源语种方向'; # example: en
to_lang = '目标语种方向'; # example: zh
term_ids = ''; #术语库ID,多个逗号隔开
# Build request
headers = {'Content-Type': 'application/json'}
payload = {'q': q, 'from': from_lang, 'to': to_lang, 'termIds' : term_ids}
# Send request
r = requests.post(url, params=payload, headers=headers)
result = r.json()
# Show response
print(json.dumps(result, indent=4, ensure_ascii=False))
# 返回说明
返回的结果是JSON字符串,然后读取读取转换成Python对象后的具体内容即可。