Revisiting Stereo Depth Estimation From a Sequence-to Sequence Perspective with Transformer——阅读阶段
论文研读申明论文地址
仅作学术研究,如有疏忽,请联系修改或删除。
更偏向机器学习研究
经过指导,现阶段论文挑重点进行记录啦~
目录
Abstract
1 Introduction
2 Related Work
2.1 立体深度估计
2.2 STTR与先前工作的对比
2.3 Attention Mechanism and Transformer
3 The Stereo Transformer Architecture
3.1 Feature Extractor
3.2 Transformer
3.3. Context Adjustment Layer
3.4. Loss
3.5. Memory Effificient Implementation
4 Experiments,Results,and Discussion
数据集:
超参数:
4.1 消融实验
4.2 场景流基准测试结果
4.3 跨域泛化
4.4 KITTI基准结果
4.5 挑战设计中的缺点
4.6 与生物立体视觉的类比
5 Conclusion
Abstract
Stereo depth estimation relies on optimal correspon dence matching(最优对应匹配) between pixels on epipolar lines in the left and right image to infer depth(推断深度). Rather than match ing individual pixels(单个像素), in this work , we revisit the problem from a sequence-to-sequence correspondence perspec tive to replace cost volume construction with dense pixel matching(密集像素匹配) using position information and attention(位置信息和监督). This approach, named STereo TRansformer (STTR) , has sev eral advantages :
- 1) relaxes(放宽) the limitation of a fifixed disparity range(视差范围)
- 2) identififies occluded regions(遮挡区域) and provides confifidence of estimation
- 3) imposes uniqueness constraints(唯一性约束) during the matching process
We report promising results on both synthetic and real-world datasets(合成|真实数据) and demonstrate(证明) that STTR generalizes(推广) well across different domains, even without fifine-tuning(甚至不微调的情况下).
【个人小结】
【小背景】立体深度估计依赖于左右图像上极线像素之间的最优对应匹配推断深度
【本文研究角度】本文不从匹配单个像素的角度出发,而是重新从序列-序列对应的角度重新审视立体深度估计问题,利用带有位置信息和注意力的密集像素匹配代替cost volume construction。
【本文主要工作】STereo TRansformer (STTR)方法及其优点
- 放宽了固定视差范围的限制
- 识别被遮挡的区域,并提供估计的置信度
- 在匹配过程中施加唯一性约束
【本文结果】
- 在合成和真实数据集上实现预期结果。
- 证明了STTR即使没有微调,也可以很好地推广到的不同领域。
【知识点】
epipolar lines:
、
为两个相机中心,p为空间中的一点,p在
、
。
、
称为极点(Epipoles),
、
称为极线(Epipolar Lines),
cost volume construction:
在Multi-view Stereo中,cost volume表示pixel-wise matching cost。
reference image 中的一个pixel(记作
),在其拍摄方向给定的深度
对应着一个三维点
,它投影到matching image会打在某个pixel(
)的位置,
对于已知相对位姿两帧图像,reference image中的一个pixel只可能对应于matching image中epipolar line上的pixel。在拍摄方向上取不同的点(
,
, ...,
)分别对应于不同pixel。每个pixel根据其邻域信息计算matching cost,也就是它与reference image中那个pixel的匹配程度。
每个pixel可以用一个vector来记录不同深度上的matching cost。所有的pixel就构成了一个tensor,也就是所谓的cost volume。



1 Introduction
Stereo depth estimation因为其重建3D信息能力热度很高;
disparity视差,可以用来进行深度估计和三维场景的重构;
现阶段,基于深度学习的方法应用于立体深度估计证明了一定的可能性,但仍具有挑战。
目前,许多性能好的方法仅限于手动预先指定的视差范围。
原因在于这些方法依赖于“cost volumn”,其多个候选由匹配成本计算得出,并且计算一个最后预测的视差值作为聚合和值。
但是,为了以一种记忆合理的方式构建成本量,需要手动设置一个固定的视差范围。
例如:大多数现有的基于学习的架构将最大差异限制在192个。
虽然这个视差范围在很多情况下被认为是足够的,但它取决于立体相机的配置、相机分辨率和物体的接近程度,具有一定的保守性。
此外,在自动驾驶和内窥镜摄像机操作的情况下,识别接近的物体,以避免碰撞是非常重要的,这就意味着需要放弃假设的固定的视差范围。
此外,几何特性和约束条件,如遮挡和匹配唯一性,促进了基于非学习的方法的成功。
对于立体深度估计,遮挡区域没有有效的视差。
先前的算法通常通过分段平滑假设来推断遮挡区域的差异,但并不总是有效的。
提供置信度估计和视差值将有利于下游分析,如配准或场景理解算法,以使加权或拒绝遮挡和不置信度估计。
然而,大多数以前的方法并不提供这样的信息。最后,一个图像中的像素不应该与另一个图像中的多个像素相匹配(高达图像分辨率),因为它们对应于物理世界中的同一位置。
虽然这种约束在大型无纹理区域解决模糊性显然很有用,但大多数现有的基于学习的方法并没有强加它。
上述问题在很大程度上源于当代对试图构建成本量的特征匹配的观点的不足。
从极线的序列到序列匹配的角度考虑视差估计的方法可以避免这些挑战。
据悉,这些方法并不新鲜,使用动态规划的第一次尝试是在1999年提出的。然而,它只使用像素强度之间的相似性作为匹配标准,这限制了其性能。
【研究动机】最近,基于注意力的网络获得了特征描述符之间的长期关联,这促使我们重新审视这一观点。
【研究思路】本文利用最近提出的用于语言处理的Transformer架构,提出了一种新的端到端训练的立体声深度估计网络STereo Transformer(STTR)。
STTR的主要优点是它密集地计算像素级相关性,而不构建成本量(a cost volume)。所以,STTR可以减轻大多数当代方法上述的缺点,且性能几乎可以保持。作者总结了在合成和真实图像基准上的竞争性能,并证明了仅在合成图像上训练的STTR可以很好地推广到其他领域,而没有细化。
虽然目前STTR实现的性能被降采样过程所抑制,但作者通过实验确定了可能的改进方向。
以下技术促进了STTR得以实现:
- 作者使用自我注意和交叉注意交替的机制代替补丁相关性,计算像素相似性,这有助于定义匹配过程中的区分特征。
- 通过最优传输理论施加匹配唯一性约束,并向特征描述符提供相对像素距离信息,以解决大的无纹理区域的模糊性。
- 使用左右图像上的各种不对称增强来训练网络,以适应常见的立体伪影,如校正误差和左右视图的外观差异。
- 设计实现了一个STTR的内存和参数效率(表1)。为了无缝分发和可再现性,作者所谓·代码可以在线使用,并且只使用现有的PyTorch函数。
表1 当代建筑中用于立体深度估计的参数的数量。
2 Related Work
2.1 立体深度估计
通常,立体深度估计任务包括2个关键的步骤:特征匹配 and 匹配成本聚合。
传统上,该任务是通过动态编程技术解决的,其中匹配由像素强度计算得出、costs在一维水平聚合或在二维多方向聚合。
近段时间以来,提出了针对立体声深度估计任务的端到端可训练网络。网络,如通过连接不同差异下的特征来构建特征卷,并学习通过三维卷积计算匹配成本。
在[38],为了提高性能,提出了额外的半全局成本聚合层和局部成本聚合层。
遵循通过学习的三维卷积计算匹配成本的相同想法,其他工作如[17,35]试图通过多分辨率的方法实现高分辨率推理和减轻内存约束。
但是,所有这些基于三维卷积的匹配网络都存在隐式相似性implicit similarity计算的问题。
与此同时,其他基于学习,通过点乘积的相关性(dot-product correlation)进行特征匹配的方法已经出现。
如[5]基于特征计算特征相似性,并将匹配作为a Markov Random Field。
[23,19,34]]利用基于学习的特征提取器,计算每个像素的特征描述符之间的相似性。
[13]Hybrid(混合)方法,分别结合显式相关性explicit correlation和三维卷积来进行匹配和成本聚合。
但是,上述方法没有利用立体匹配的顺序性质和几何性质,立体匹配的顺序性质和几何性质能够促进基于非学习的工作相关成功的工作有[2][14]。
在上述所有基于学习的方法中,无论匹配是显式计算还是学习匹配,都设置了最大视差来减轻内存和计算需求。对于每个像素,都有一组固定的和有限的离散位置,保证了一个像素可以映射到对应位置,从而产生匹配的成本体积。
对于超出这个预定义范围的差异,基于成本体积的方法根本无法推断出正确的匹配,这限制了不同场景和立体摄像机配置的泛化。
此外,大多数基于学习的方法并不能明确地处理遮挡,即使遮挡区域的差异在理论上可以是任意的。
最后,在匹配过程中没有施加显式的唯一性约束,这可以抑制性能(特别是在大的无纹理区域)。
2.2 STTR与先前工作的对比
作者使用一个卷积神经网络(CNN)作为特征提取器,它馈入一个transformer,以捕获像素之间的长距离关联。
STTR vs. 3D Convolution-based Stereo Depth Networks:
- STTR显式而密集地计算左右图像中像素之间的相关性。
- 不是使用三维卷积来汇总成本卷,而是首先沿着外极线进行匹配,然后通过二维卷积跨外极线来汇总信息。
STTR vs. Correlation-based Stereo Depth Networks
- STTR在匹配过程中施加唯一性约束,以解决歧义
- STTR还在图像内和图像间相关操作之间交替进行,称为自我注意和交叉注意,并通过同时考虑图像上下文和位置信息来更新特征表示。
2.3 Attention Mechanism and Transformer
注意力是自然语言处理的有效工具。
近年来,基于注意的体系结构在计算机视觉任务中得到了应用,如目标检测、全光分割、同时定位和映射,提高了纯CNN体系结构的结果。
这可能是因为注意力可以捕捉到长期的关联,这对这里提出的工作也很重要。
3 The Stereo Transformer Architecture
在下面的部分中,将校正后的左右两对图像的高度和宽度表示为
和
,特征描述符的信道维度表示为C。
3.1 Feature Extractor
使用了一个类似[21]的沙漏形状架构:
- encoding path编码路径更改为残余连接和空间金字塔池模块,实现更有效的全局上下文获取。
- decoding path解码路径由转置卷积、密集块[15]和最终的卷积层组成。
每个像素的特征描述符,表示为大小为
的向量
,对本地和全局上下文同时编码。最终的特征图与输入图像的空间分辨率spatial resolution相同。
3.2 Transformer
图2是本文的Transformer架构的概述。使用了2种attention模块:自注意力和交叉注意力。
- 自我注意:计算同一图像中沿上极线的像素之间的注意
- 交叉注意:计算左右图像中沿对应的上极线的像素的注意。(细节见3.2.1)
图2 自注意和交叉注意力的Transformer模块概述
请注意,在最后一个交叉注意层中,添加了 最佳的传输和注意掩模。如图2所示, 在计算N−1层的自我注意和交叉注意之间交替。这种交替方案根据图像的上下文和相对位置不断更新特征描述符,如3.2.2讨论。
在最后一个交叉注意层中,使用被注意程度最多的像素来估计原始视差。在这一层中添加了唯一的操作,包括符合唯一性约束的optimal transport (第3.2.3节)和用于减少搜索空间的注意掩码attention mask(第3.2.4节)。
3.2.1 Attention
注意力模块[32]使用点积相似性计算一组 query 向量和 key 向量之间的注意,然后用来加权一组值向量。
采用多头注意力机制增加特征描述的表达率,其将特征描述大小
组
,其中
为每个头的通道维数。因此,每个头可以有不同的语义意义,每个头可以计算相似性。
对于每个注意头h,使用一组线性投影计算查query量
、key向量
:
其中,
、
、
在
;
、
、
在
中。
通过softmax将相似性归一化,得到
为
输出值向量
可计算为:
其中,
然后将输出值向量
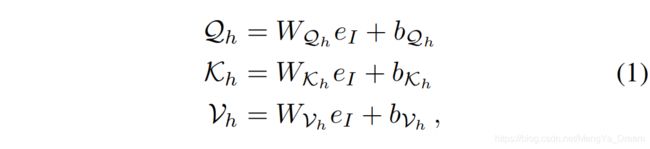




3.2.2 Relative position Encoding
在较大的无纹理区域中,像素之间的相似性可能是模糊的。然而,这种模糊性可以通过考虑与突出特征相关的相对位置信息来解决,如边缘。因此,作者通过位置编码提供与数据相关的空间信息
。作者选择编码相对的像素距离代替绝对的像素位置,因为它的位移不变性。在普通的变压器[32]中,绝对位置编码
在这种情况下,方程2中第i和第j像素之间的注意力可以扩展为
通过扩展术语,可以看到术语(a)是数据-数据分量,术语(b)(c)是数据-位置分量,术语(d)是位置-位置分量。术语(d)完全忽略了图像内容,因此应该被忽略,因为差异从根本上取决于图像内容。
相反,我们使用相对位置编码,并删除术语(d)作为
其中
表示第i像素和第j像素之间的位置编码。注意,
。直观地说,注意力同时取决于内容的相似性和相对距离。
然而,相对距离的计算成本在图像宽度
受[10]的启发,作者提出了一个有效的降低线性成本的方法。实施情况详见附录A。

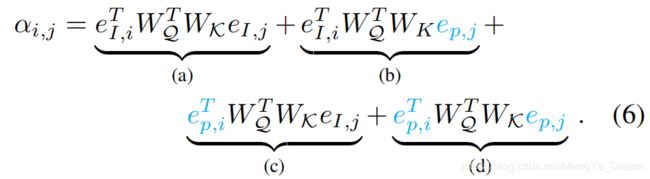
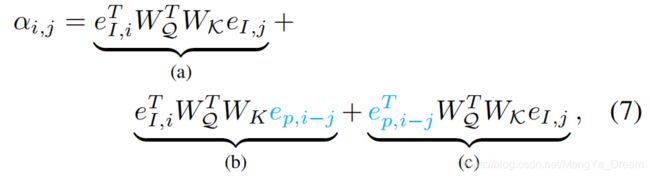
3.2.3 Optimal Transport
强制执行立体匹配的唯一性约束首次出现在[2]中,其将右侧图像中的每个像素被分配给左侧图像中最多一个像素。然而,这种硬的分配禁止梯度流动。相比之下,[9]中熵正则化的最优传输entropy-regularized optimal transport由于其软分配和可微性,是一种理想的替代选择。
给定两个长度为
其中,
是熵正则化。如果两个边际分布a、b是均匀的,那么T对于分配问题也是最优的,这强加了软唯一性约束[29],减轻了模糊性[30,22]。方程8的解可以通过迭代的Sinkhorn算法[9]找到。直观地说,T表示成对匹配概率,类似于方程2中的软最大注意。
由于遮挡的原因,某些像素无法匹配。参考学习[30],作者通过添加一个可学习参数φ的dustbins箱来增加成本矩阵,该参数直观地代表了设置不匹配像素的成本。
在STTR中,成本矩阵M设置为公式2中交叉注意模块计算的注意的负,但没有softmax,因为最优传输将注意值归一化。

3.2.4 Attention Mask
由于立体设备中摄像机的空间布置,左图像比右图像更会出现相同的物体。因此,在最后一个交叉注意层中,左侧图像中的每个像素只关注更右侧更远的像素就足够了。为了施加这种约束,作者对注意力引入了一个对角线二进制掩模a diagonal binary mask,如图2所示。
3.2.5 Raw Disparity and Occlusion Regression
在之前的大多数工作中,都使用了所有候选视差值的加权和。相反,作者使用改进的winner-take-all方法回归视差,它对多模态分布是鲁棒的。
原始视差是通过从最优传输分配矩阵T中找到最可能匹配的位置来计算的,表示为k,并在其周围建立一个3px的窗口。对3px窗口内的匹配概率进行重新归一化步骤,使和为1。候选差异的加权和是回归的原始差异和原始视差
。t表示分配矩阵T中的匹配概率:
以逆遮挡概率an inverse occlusion probability的形式,在这个3px窗口内的概率之和表示网络与当前分配的置信度。因此,可以使用相同的信息来回归遮挡概率

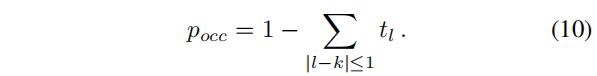
3.3. Context Adjustment Layer
原始视差和遮挡图在外极线上回归,因此缺乏跨多个外极线的背景。为了减轻这种情况,使用卷积来捆绑调整基于输入图像的估计值。上下文调整层的概述如图3所示。
图3 上下文调整层的概述
原始的视差和遮挡图首先沿着通道尺寸与左侧图像连接起来。两个卷积块用于聚合遮挡信息,然后是ReLU。最终的遮挡是通过一个信号的激活来估计的。视差通过残余块进行细化,这些块在ReLU激活之前扩展通道尺寸,然后将其恢复到原始通道尺寸。在ReLU之前的扩展是为了鼓励更好的信息流[37]。原始的视差被重复地连接到残差块上,以获得更好的调节。剩余块的最终输出通过长时间跳过连接添加到原始视差中。
3.4. Loss
对于匹配像素M和由于遮挡引起的不匹配像素U的集合,对分配矩阵T采用[21]中提出的相对响应损失Lrr。该网络的目标是最大限度地关注真正的目标位置。由于视差是子像素,使用最近的整数像素之间的线性插值来找到匹配的概率
。具体来说,对于具有地面真实视差
的左图像的第 i 个像素:
其中,插值p表示线性插值。对原始和最终的视差都使用平滑的L1损失[12],表示为
,
。最终的遮挡图是通过一个二元熵
损失来监督的。总损失为以下总和:
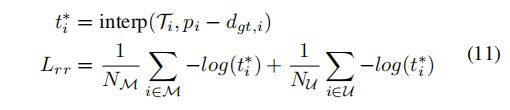

3.5. Memory Effificient Implementation
注意力机制的记忆消耗在序列长度方面是二次的。具体来说,对于一个浮点32精度计算
例如,给定
此外,对每个自我注意力层和交叉注意层采用梯度检查点[8],其中中间变量在正向传递期间不保存。在向后传递过程中,再次运行检查点层以重新计算梯度。因此,内存消耗受到单个注意层的需求的限制,在理论上,这使网络能够根据注意层的数量进行无限的扩展。
最后,使用混合精度训练[27]来提高更快的训练速度和减少内存消耗。
4 Experiments,Results,and Discussion
数据集:
- Sence Flow:FlyingThings3D子集是一个合成数据集(包含随机对象且包含25466张分辨率为960×540的图像),视差范围1~468。
Sceneflow数据集是CVPR 2016提出的,其目的就是构建一个大规模的合成数据集,用来训练深度立体匹配网络。以往的数据集(如kitti和middlebury)的训练图像都太少了,而sceneflow数据集提供了3万多对训练图像,这使得更深的深度网络能够得到充分的训练。尽管sceneflow数据集是一个合成图像的数据集,但是却可以作为深度网络的预训练数据。近几年主流的训练方法往往采用在sceneflow数据集上作pre-train,再在真实数据集上作finetune。
- KITTI 2015:街道场景数据集(包含200张分辨率为1242×375的图像),视差范围4~230。
- Middlebury 2014:quarter-resolution子集是一个室内场景数据集(包含15张不同分辨率从347×277到741×497的图像),视差范围8~161。
- SCARED:一个医疗场景数据集(包含7个腹腔镜手术内镜视频)。
实验提取了315张分辨率为640×512的图像,视差从0到295不等。预训练时,使用默认的场景流分割(split of Scene Flow);跨域泛化评估时,实验使用来自每个数据集提供的所有数据。对于KITTI2015年的基准评估,在KITTI2012年和2015年的数据集上进行了训练,并留下了20张图像以供验证。
【知识点】待充实
split of Scene Flow:场景流分割
Scene Flow:场景流是密集的3D几何和动态场景的运动。
超参数:
使用6个自交叉注意力层(self- and cross-attention layers),![]() ;
;
利用Sinkhorn algorithm跑了10次迭代;
使用AdamW作为优化器;
设置所有的损失权重为1;
场景流的预训练使用了一个学习率固定为1e-4的特征提取器(feature extractor)和Transformer以及学习率为2e-4的上下文调整(context adjustment layer)层进行了15个epochs。
使用不对称(如左右图像不一致)的外观增强(appearance augmentation)(包括HSV位移、对比度位移和高斯噪声),来模拟真实的立体声伪影;
利用了空间增强,包括随机作物、水平翻转、最大1.5px的随机垂直位移和最大0.2度的随机旋转。
对于KITTI2015基准确定(benchmark submission),使用指数学习率调度器对预先训练的模型进行微调,300个epochs的衰减为0.99。
实验环境:single Nvidia Titan RTX GPU
评估指标:使用3px误差(大于3px的误差百分比)和EPE(绝对误差)、IOU(评估遮挡估计)
【注意】本节其余部分报告的所有定量指标仅参考非闭塞区域;
【知识点】
self- and cross-attention layers
Sinkhorn algorithm
feature extractor
context adjustment layer
appearance augmentation
benchmark submission
4.1 消融实验
使用场景流合成数据集(the Scene Flow synthetic dataset)进行消融实验。在之前工作的基础上,直接对测试分割进行验证,因为场景流只用于预训练(表2 总结了大量结果)。
表2 在场景流数据集上的消融研究
AM:attention mask
OT:optimal transport
CAL:context adjustment layer.
PE:positional encoding
 实现位置编码可视化的效果。如图4(a)所示:给定一个具有较大无纹理区域的图像;如图4(b)所示:直接从特征提取器中提取的特征(大区域内拥有相似的纹理)。如图4(c-d)所示,在没有位置编码的情况下,随着层的深入,特征图仅在整个过程中发生变化。如图4(e)所示,通过向所有层提供相对的位置编码,就出现了平行于第四层边缘的(stride)步幅。如图(f)所示,步幅最终传播到第6层的整个区域。 这表明transformer需要相关位置信息来解决无文本区域的模糊情况。事实上,随着向所有层添加位置编码,所有三个指标的结果都大大改善。
实现位置编码可视化的效果。如图4(a)所示:给定一个具有较大无纹理区域的图像;如图4(b)所示:直接从特征提取器中提取的特征(大区域内拥有相似的纹理)。如图4(c-d)所示,在没有位置编码的情况下,随着层的深入,特征图仅在整个过程中发生变化。如图4(e)所示,通过向所有层提供相对的位置编码,就出现了平行于第四层边缘的(stride)步幅。如图(f)所示,步幅最终传播到第6层的整个区域。 这表明transformer需要相关位置信息来解决无文本区域的模糊情况。事实上,随着向所有层添加位置编码,所有三个指标的结果都大大改善。
图4 特征可视化
第二行是 没有位置编码的Transformer的特征
第三行是 带有位置编码的Transformer的特征
特征的完整演变情况见附录C。
4.2 场景流基准测试结果
表3 场景流估计(定量研究)
4.3 跨域泛化
比较STTR的域泛化与已开源且模型仅在场景流合成数据集训练的先前工作。具体来说,作者没有将模型细化到测试数据集。和之前一样,作者评估了3px误差和EPE,并在表4中记录了相关发现。除了2014年Middlebury的EPE外,STTR的表现始终优于其他网络。
表4 在KITTI2015、Middlebury2014和恐惧数据集上没有微调的生成。
仅在场景流数据集上进行训练。
Feature Distribution: 如图6所示,使用图中的UMAP将来自不同图像域的Transformer可视化。其中,降维嵌入只对场景流数据进行训练。每个数据点表示Transformer运行的一个像素。观察到,STTR集群学习到的表现形式,无论哪个领域,进入不同的区域——纹理,无纹理和封闭区域。假设,这种隐式学习的特征聚类改进了STTR的泛化,使Transformer匹配过程更容易。(其他图可见附录B)
图6 特征地图的UMAP可视化
【知识点】
UMAP
4.4 KITTI基准结果
由于KITTI基准测试为微调提供了合理数量的图像,并且它在以前的工作中经常使用,因此选择KITTI基准测试在微调后进行比较。KITTI2015基准测试的结果见表5。STTR的性能与竞争方法相当,甚至与为高分辨率图像设计的多分辨率网络相比,也不逊色。
表5 KITTI2015的3px error评估
bg:background
fg:foreground
multi-res: networks operate on multiple resolutions.
low-res: networks operate on downsampled resolution.
4.5 挑战设计中的缺点
虽然STTR的性能与以前的方法相当,但值得一提的是,所考虑的真实数据集中的测试集相当小。特别是,2015年KITTI、2014年Middlebury和SCARED的测试集分别包含200张、15张和315张图像。对于性能的性能估计,需要充分观察整个图像空间,这实际上是不可能的。同样,很难估计测试集覆盖的所有可能图像中的哪些部分,这抑制了适当的功率分析。
即使假设测试数据集很好地覆盖了整个图像空间,这些数据集上竞争模型的性能差异在细化后<1%,跨域泛化后的占比很少。这个微小的差异表明,需要更多的测试实例来可靠地得出方法排名的结论。因此,不能得出所提出的方法之间是否存在显著的性能差异的结论。
4.6 与生物立体视觉的类比
研究表明,生物立体视觉系统(例如,人类的立体视觉系统)通过依赖于低水平的皮层线索,从立体图像中感知深度。证明这种效应的案例:随机点立体图实验,其中在图像中没有有意义的纹理,只有随机点,然而,人类仍然可以感知到这些3D物体。与此同时,生物视觉系统对物体施加了几何假设,作为一个分段光滑的先验,这涉及到中层皮层处理。在某种程度上,STTR模拟了生物立体系统,即Transformer在低级级别处理图像,以查找特征之间的匹配。然后,STTR使用上下文调整层局部细化原始差异,这与中层视觉loose analogy。
【知识点】
loose analogy
【个人小结】
- 首先说明数据集和超参数设置
【消融实验】
- Attention Mask:由于不允许使用负视差,attention map可以帮助减少存在潜在匹配的搜索空间,这能够在减少3px和EPE的同时,不会显著影响遮罩预测。
- Optimal Transport:考虑同一极线上的像素之间的相互作用,给最优传输施加了一个soft唯一性约束。最优传输优化了所有度量值中的结果。
【场景流基准测试结果】
- 评估3px误差和EPE,除2014年Middlebury的EPE外,STTR的表现始终优于其他网络。
- STTR集群学习到的表现形式,无论哪个领域,进入不同的区域——纹理,无纹理和封闭区域。
【KITTI的基准结果】
- STTR的性能与竞争方法相当,甚至与为高分辨率图像设计的多分辨率网络相比,也不逊色。
【挑战设计的缺陷】
- 对于性能的性能估计,需要充分观察整个图像空间,这实际上是不可能的
- 同样,很难估计测试集覆盖的所有可能图像中的哪些部分,这抑制了适当的功率分析。
- 不能得出所提出的方法之间是否存在显著的性能差异的结论。
【与生物立体视觉的类比】
- 在某种程度上,STTR模拟了生物立体系统,即Transformer在低级级别处理图像,以查找特征之间的匹配。
- STTR使用上下文调整层局部细化原始差异,这与中层视觉loose analogy。
5 Conclusion
总之,本文提出了一种名为STereo TRansformer的端到端网络架构,它综合了CNN和Transformer架构的优势。从序列到序列匹配的角度重新审视立体深度估计,克服了在计算上昂贵的成本体积构建的需要。更重要的是,这种方法
- 避免了需要预先指定一个固定的视差范围
- 显式地处理遮挡
- 施加了各种约束,包括匹配唯一性。
通过实验证明,STTR可以很好地推广到不同的领域,并在基准上报告了有希望的结果。未来的工作将包括通过多分辨率技术在推理过程中提高空间分辨率。