你真的懂insert or update?
在业务系统开发过程中,作为一个“curd boy”,经常会对数据库进行新增和修改,新增操作相对简单,直接执行insert 操作即可,而对于更新操作,就比较复杂一点了,主要是因为被更新的字段不是固定的,有的业务需要更新满足条件数据行的A字段,有的需要更新B字段,有的A字段和B字段都要更新。难不成写三个实现,分别用来更新A,B和A,B? 如果字段少的话,这种做法未尝不可,但是如果需要更新的字段很多话,这种做法是就有点要命了。
1.无差别更新
使用mybatis的读者,对于这个问题有一个比较好用的解决方案,那就是无差别的更新:对所有字段进行更新。如果最新值相比原值发生了变化,那么就更新为最新值,如果没有发生变化,即使进行了更新操作,那么对业务也没有影响。
具体代码如下:
<update id="update" parameterType="xxxPO">
update table1
<set>
<if test="id != null">
id = #{id,jdbcType=BIGINT},
</if>
<if test="prop1 != null">
column1 = #{prop1,jdbcType=VARCHAR},
</if>
<if test="prop2 != null">
column2 = #{prop2,jdbcType=VARCHAR},
</if>
...
</set>
<where>
id=#{id,jdbcType=BIGINT}
</where>
</update>
仔细对比xxxMapper.java中插入和更新的方法入参,会发现这两个方法的入参类型是一样的:
void insert(@Param("xxpo") xxPO xxpo);
void update(@Param("xxpo") xxPO xxpo);
那能否将两者合二为一呢?
void insertOrUpdate(@Param("xxpo") xxPO xxpo);
2.新增和修改合二为一
要实现新增和修改合二为一,需要解决一个问题:如何区分新增和更新操作,也就是:什么时候执行新增,什么时候执行插入。带着这个问题,来进入我们今天的正题。目前在sql层面实现“不存在时进行插入,存在时更新”的方式有两种:insert into ... on duplicate key update ...; 和 replace into ... values ...;
replace into … 实现的语义:被插入的数据,不存在的话,进行插入操作,存在的话,执行"替换"操作。
insert into … on duplicate key update … 实现的语义:被插入的数据,不存在的话,进行插入操作,存在的话,执行"更新"操作。
这里的"存在"如何定义,"替换"和"更新"具体的操作又是什么,我们在后面讨论。
为了方便下面的演示和描述,这里建立如下的表结构
CREATE TABLE `test_insert_update` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT COMMENT '主键',
`a` int(11) NOT NULL,
`b` int(11) NOT null,
`c` int(11) NOT null,
PRIMARY KEY (`id`) USING BTREE,
UNIQUE KEY `uk_a` (`a`) USING BTREE,
UNIQUE KEY `uk_b` (`b`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin ;
创建test_insert_update表,定义自增主键id和三个 int型字段 a,b,c。并在a和b字段上,建立唯一索引。向表中插入如下数据:
insert into test_insert_update (a,b,c) VALUES(1,1,1);
insert into test_insert_update (a,b,c) VALUES(2,2,2);
insert into test_insert_update (a,b,c) VALUES(3,3,3);
insert into test_insert_update (a,b,c) VALUES(4,4,4);
replace into
replace into 判断数据是否"存在"的机制是:被插入的数据是否违反主键索引或者唯一键索引约束。如果两者都没有违反的话,就进行插入操作,如果有违反的话,就会执行"替换"操作,这里的替换所做的事情是:先删除,在插入。
删除:删除所有会产生以上所说的冲突的数据行。
插入:此时可以将 replace into 看成 insert into 语句。
为了验证以上结论,我们进行一下实验:
1.正常插入数据
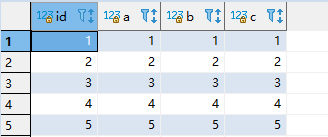
插入一条和现有数据没有冲突的数据,数据可以正常插入
replace into test_insert_update (id,a,b,c) values(5,5,5,5);
结果如下:
2.插入一条违反主键约束的数据
replace into test_insert_update (id,a,b,c) values(5,6,6,6);
插入一条和主键id=5的数据行存在主键冲突的数据。
结果如下:
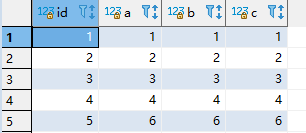
其实这里并不好确定是replace into在遇到重复数据时,是先删除后再插入,还是直接更新。这个在后面进行验证。
3.插入一条违反唯一键约束到的数据。
replace into test_insert_update (id,a,b,c) values(6,6,7,8);
插入一条和id=5的数据行存在,唯一键a冲突的数据。
结果如下:

4.插入一条,违反多个唯一键和主键的的数据。
replace into test_insert_update (id,a,b,c) values(3,1,2,3);
在这个语句中,被插入的数据和表中主键id为1,2,3的数据行都存在唯一键或者主键冲突。该语句执行后的结果如下:

通过多个唯一键和主键冲突的数据插入操作,可以验证:replace into 遇到数据冲突时,执行的操作:是先删除,再插入。而且这里的删除,是把所有有冲突数据行全部删除,也就是主键id为1,2,3的数据行。
insert into on duplicate key update
insert into on duplicate key update 判断数据是否存在的机制:需要插入的数据是否违反主键或者唯一键约束。如果两个都没有违反的话,就进行插入操作。如果存在违反的话,就会执行"更新"操作,这里更新所做的事情是将有冲突的数据行,执行"update"后的操作。
这里需要注意的是:被更新的数据行,只有一行,也就是说,即使需要插入的数据和现有数据中的多行存在唯一键冲突和主键冲突,也只会对多行数据中的一行数据执行更新操作。
更新多行数据中的哪一行?
在插入一行数据时,会验证这行数据和现有主键,唯一键是否存在冲突,因为验证的过程中,每个键的被验证的优先级是不同的,在使用某个键验证时,检查到存在某行数据和待插入数据存在冲突时,那么就更新被检查的这行数据。剩余的其他键,不会再被验证。所以这里被更新的数据行,和检验冲突时被检验的键的优先级定义有很大关系。
在mysql中,主键的优先级最高,其他各个唯一键的优先级,取决于创建表的时候,唯一键定义的先后顺序,顺序靠前的,被优先验证,顺序靠后的唯一键,被验证的优先级也就比较低。
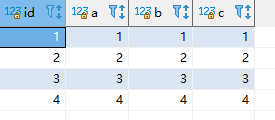
为了验证以上结论,我们进行以下实验,在进行实现前,我们重新初始化一下表中的数据,初始化后,表中数据如下:
1.正常插入数据
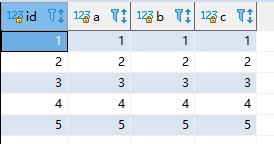
insert into test_insert_update (id,a,b,c) values (5,5,5,5) on duplicate key update a = 10, b=10;
结果如下:
2.插入一条违反主键约束的数据
insert into test_insert_update (id,a,b,c) values (5,6,6,6) on duplicate key update a = 11, b=11,c=11;
插入一条和主键id=5的数据行,存在主键冲突的数据。
结果如下:
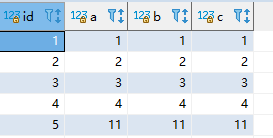
3.插入一条违反唯一键约束的数据
insert into test_insert_update (id,a,b,c) values (10,1,10,10) on duplicate key update a = 12, b=12,c=12;
插入一条和主键id=1的数据行,存在唯一键a冲突的数据。
执行结果:
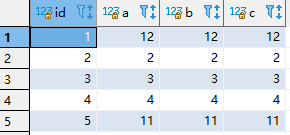
4.违反多个唯一键约束和主键约束
insert into test_insert_update (id,a,b,c) values (1,2,3,4) on duplicate key update a = 13, b=13,c=13;
插入一条和主键id为1,2,3,4的数据行,存在主键和唯一键冲突的数据。不过,这里只会对数据库中id=1行进行更新。

3.两种实现方式比较
上面详细介绍了 replace into 和 insert into on duplicate key update 的实现原理和使用方式。那么在工作中,在两者中如何进行选择呢?
在进行选择前,我们选对两者进行一下对比,以及各自的优缺点,这样,才能更清楚,如何进行选择。
相同点
首先两者在判断何时进行插入操作,何时进行更新操作的机制是一样的,都是利用是否存在主键或者唯一键冲突决定的。如果不存在冲突,就进行插入操作,否则就执行更新或者"替换"。
不同点
不过两者的差异也是很明显的,主要体现在:当存在主键或者唯一键冲突时的处理机制是截然不同的。
当存在冲突时,replace into的做法是将所有冲突的数据删除,然后再插入一条新的数据。
这种做法的好处在于,删除冲突的数据,在进行插入的数据,不会触发唯一性约束了。而不足之处在于,当存在重复数据时,进行删除,然后在进行插入,那么在数据层面,就无法感知"变化"了.比如,如果在在数据表中定义的ctime和mtime(分别表示数据创建时间和修改时间),永远都是一样的。
而对于 insert into duplicate 的实现方式,会对其中一行数据进行更新,但是更新操作仍然有可能会违反唯一性约束,导致更新操作失败。但是它本身就是一个更新操作,更新时间会记录到mtime中,可以体现出修改。
4.总结
replace into 和 insert into on duplicate key update 都可以实现当存在数据重复时,进行数据"更新"操作,两者的差异和各自的优缺点上文也进行了阐述。在使用时可以根据具体业务进行选择。
这里还要一点需要提醒,如果数据表中的主键是自增的话,无论使用 replace into还是 insert into on duplicate update 都会导致主键不连续的问题。问题产生的原因:在进行数据插入前,auto_increment的值已经自增过了,即使最终数据插入失败,auto_increment也不会在回滚了。具体细节可以参考"你真的懂自增主键吗"