Activation Function 激活函数 ---非饱和激活函数
Activation Function
饱和与非饱和
右饱和:
当x趋向于正无穷时,函数的导数趋近于0,此时称为右饱和。
左饱和:
当x趋向于负无穷时,函数的导数趋近于0,此时称为左饱和。
饱和函数和非饱和函数:
- 当一个函数既满足右饱和,又满足左饱和,则称为饱和函数
- 否则称为非饱和函数。
非饱和激活函数
(以ReLU、ReLU6及变体P-R-Leaky、ELU、Swish、Mish、Maxout、hard-sigmoid、hard-swish为主)
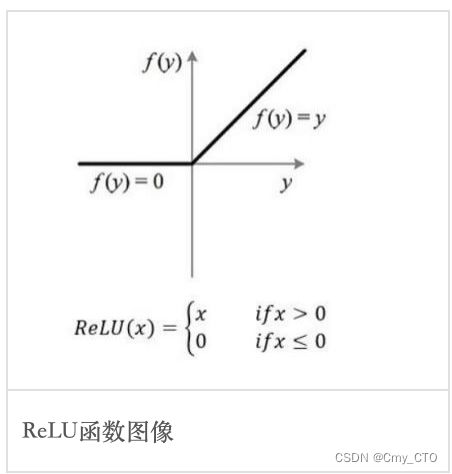
ReLU函数
- Relu激活函数(The Rectified Linear Unit),用于隐层神经元输出,即hidden layer
- 在输入小于0时,输出均为0值,
- 在输入大于0时,输出y=x,
- 可见该函数并非全区间可导的函数,so 非饱和
表达式
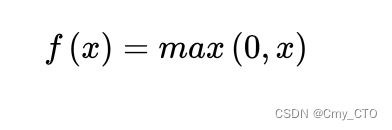
函数图像
优点:
- 相较于sigmoid函数以及Tanh函数来看,在输入为正时,Relu函数不存在饱和问题,即解决了gradient vanishing问题,使得深层网络可训练,梯度不会过早消失则收敛速度不会过慢
- 计算速度非常快,只需要判断输入是否大于0值;
- 收敛速度远快于sigmoid以及Tanh函数;
- Relu输出会使一部分神经元为0值,在带来网络稀疏性的同时,也减少了参数之间的关联性,一定程度上缓解了过拟合的问题;
缺点:
- Relu函数的输出也不是以0为均值的函数;
- 存在Dead Relu Problem,即某些神经元可能永远不会被激活,进而导致相应参数一直得不到更新,产生该问题主要原因包括参数初始化问题以及学习率设置过大问题;
- 当输入为正值,导数为1,在“链式反应”中,不会出现梯度消失,但梯度下降的强度则完全取决于权值的乘积,如此可能会导致梯度爆炸问题;
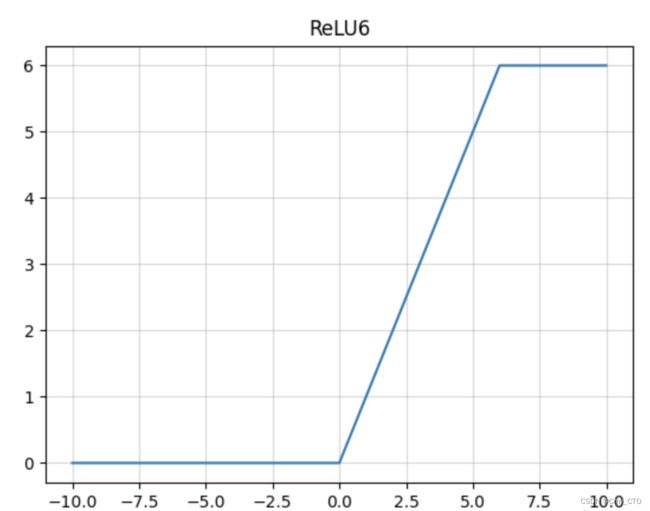
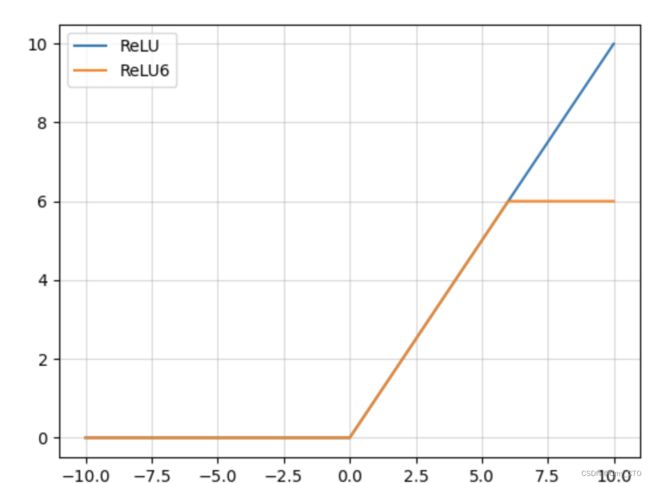
ReLU6函数
- ReLU6就是普通的ReLU但是限制最大输出为6,
- 用在MobilenetV1网络当中。
- 目的是为了适应float16/int8 的低精度需要。
表达式
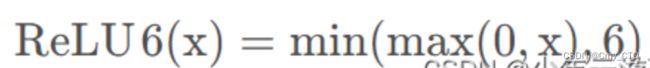
函数图像
(在x大于等于6时,y的值会被限定)
优点:
- ReLU6具有ReLU函数的优点;
- 该激活函数可以在移动端设备使用float16/int8低精度的时候也能良好工作。
- 如果对 ReLU 的激活范围不加限制,激活值非常大,则低精度的float16/int8无法很好地精确描述如此大范围的数值,带来精度损失。
缺点:
与ReLU缺点类似。
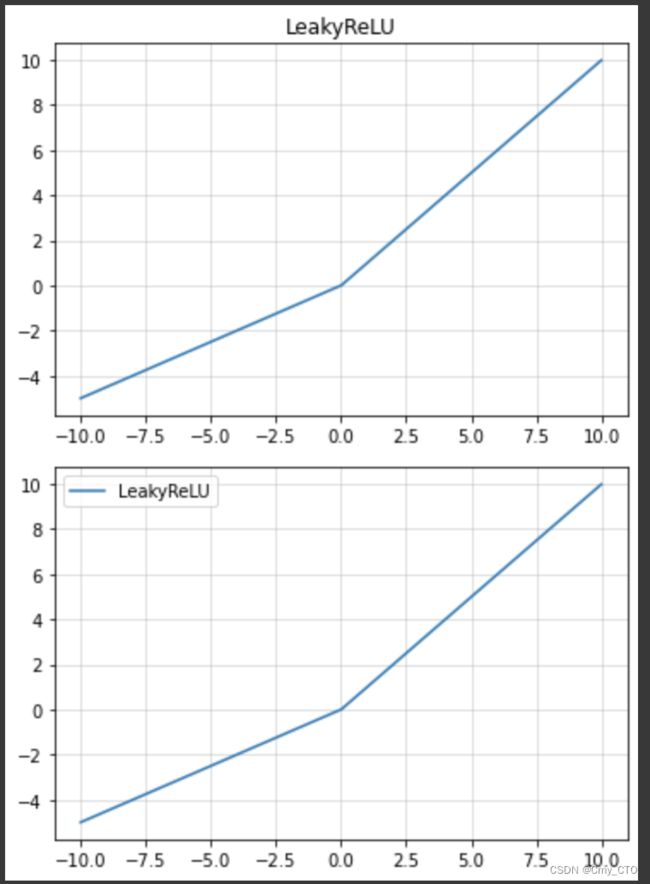
LeakyReLU
- x大于等于0时,y=x,
- x小于0时,y=α*x
表达式
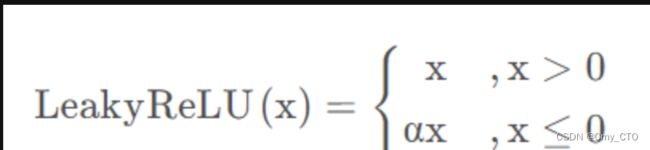
函数图像
优点:
- 针对Relu函数中存在的Dead Relu Problem,LeakyRelu函数在输入为负值时,给予输入值一个很小的斜率,在解决了负输入情况下的0梯度问题的基础上,也很好的缓解了Dead Relu问题;
- 该函数的输出为负无穷到正无穷,即leaky扩大了Relu函数的范围,其中α的值一般设置为一个较小值,如0.01;
缺点:
- 理论上来说,该函数具有比Relu函数更好的效果,但是大量的实践证明,其效果不稳定,故实际中该函数的应用并不多。
- 由于在不同区间应用的不同的函数所带来的不一致结果,将导致无法为正负输入值提供一致的关系预测。
ELU
Relu函数的一种变体
- x大于0时,y=x
- x小于等于0时,y=α(exp(x)-1)
- 可看作介于Relu与Leaky Relu之间的函数
表达式
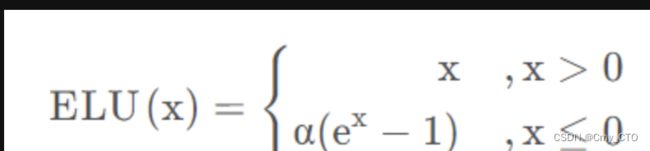
函数图像
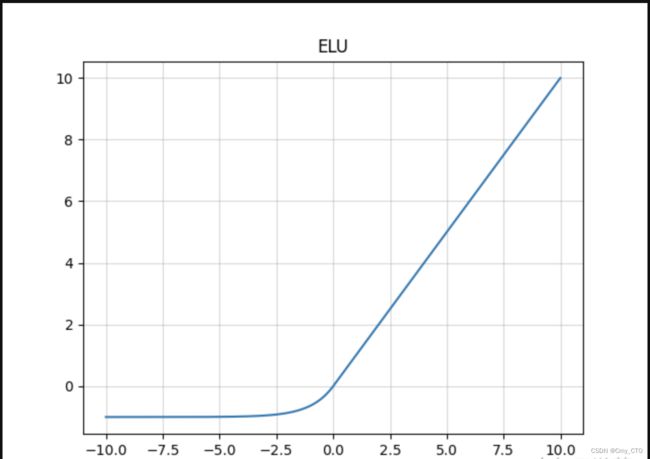
优点:
- ELU具有Relu的大多数优点,不存在Dead Relu问题,输出的均值也接近为0值;
- 该函数通过减少偏置偏移的影响,使正常梯度更接近于单位自然梯度,从而使均值向0加速学习;
- 该函数在负数域存在饱和区域,从而对噪声具有一定的鲁棒性;
缺点:
- 计算强度较高,含有幂运算;
- 在实践中同样没有较Relu更突出的效果,故应用不多。
Swish
- Swish是Sigmoid和ReLU的改进版
- 类似于ReLU和Sigmoid的结合,
- β是个常数或可训练的参数。
- Swish 具备无上界有下界、平滑、非单调的特性。
- Swish 在深层模型上的效果优于 ReLU。
表达式

函数图像
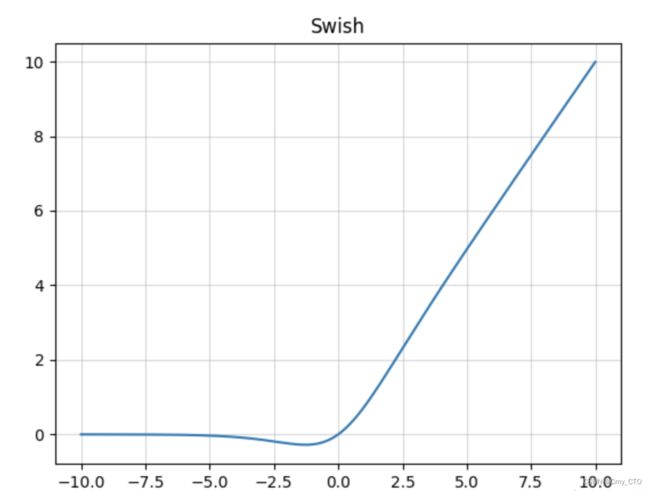
优点:
- Swish具有一定ReLU函数的优点;
- Swish具有一定Sigmoid函数的优点;
- Swish函数可以看做是介于线性函数与ReLU函数之间的平滑函数。
缺点:
运算复杂,速度较慢。
Mish
- Mish与Swish激活函数类似,
- Mish具备无上界有下界、平滑、非单调的特性。
- Mish在深层模型上的效果优于 ReLU。
- 无上边界可以避免由于激活值过大而导致的函数饱和。
表达式
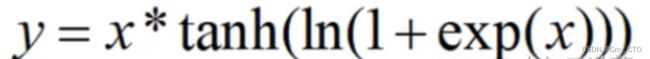
函数图像
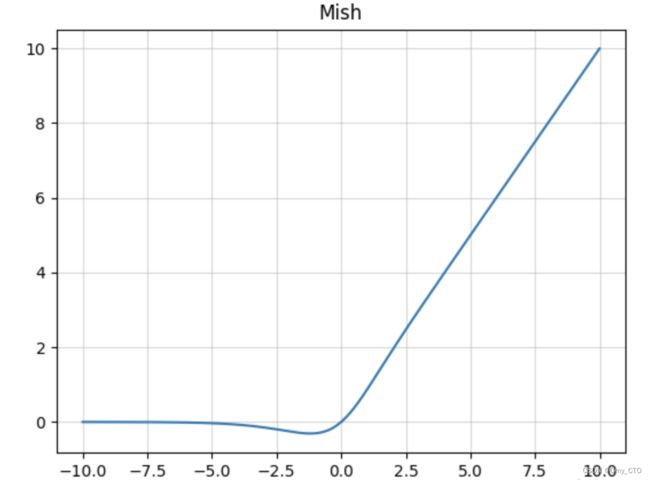
优点:
- 正值以上无边界(即正值可以达到任何高度)避免了由于封顶而导致的饱和。理论上对负值的轻微允许允许更好的梯度流,而不是像ReLU中那样的硬零边界。
- 平滑的激活函数允许更好的信息深入神经网络,从而得到更好的准确性和泛化。
缺点:
计算量肯定比relu大,占用的内存也多了不少;
Maxout
- maxout激活函数其本质是对所有out作max操作,又被称为大一统的激活函数,
- 因为maxout网络能够近似任意连续函数,且当w2,b2,…,wn,bn为0时,退化为ReLU。
- Maxout能够缓解梯度消失,同时又规避了ReLU神经元死亡的缺点,但增加了参数和计算量。
此外maxout激活函数并不是一个固定的函数,不像Sigmod、Relu、Tanh等函数,是一个固定的函数方程。
它是一个可学习的激活函数,因为我们 W 参数是学习变化的。
Maxout单元不但是净输入到输出的非线性映射,而是整体学习输入到输出之间的非线性映射关系,可以看做任意凸函数的分段线性近似,并且在有限的点上是不可微的。
表达式
![]()
优点:
- Maxout的拟合能力非常强,可以拟合任意的凸函数。
- Maxout具有ReLU的所有优点,线性、不饱和性。
- 同时没有ReLU的一些缺点。如:神经元的死亡。
缺点:
激活函数公式中可以看出,每个神经元中有两组(w,b)参数,那么参数量就增加了一倍,这就导致了整体参数的数量激增。
hard_sigmoid
Hard sigmoid 是一种对于 sigmoid 的近似,主要优势是计算速度快,无需幂计算,所以当对对于速度要求高的情况下,hard sigmoid 是一种选择。
在具体的实现形式上有多种方式,比如 pytorch 和 tensorflow 中的实现方式就有差别,但是总之都是对于 sigmoid 的一种近似。总的来说计算速度比sigmoid快,因为没有指数运算。
表达式

函数图像

优点:
输出为(0,1),可以表示为概率单调、连续。
缺点:
- 梯度软饱和。
- 输出不为0均值,不利于优化。
- 包含指数计算,速度慢。
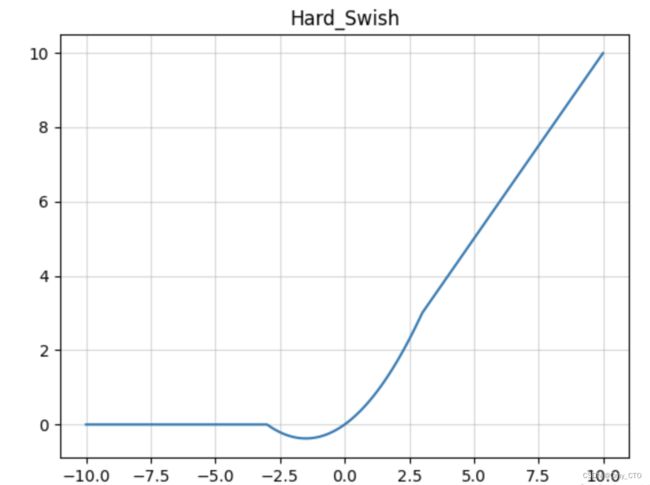
hard_swish
最早MobileNetV3 作者使用hard-Swish和hard-Sigmoid替换了ReLU6和SE-block中的Sigmoid层,但是只是在网络的后半段才将ReLU6替换为h-Swish,因为Swish函数只有在更深的网络层使用才能体现其优势。
解决的问题
- 用分段线性函数代替Swish,提高了计算效率。
- 在MobileNetV3网络的深层用Hard-Swish代替了ReLU6,保证模型低计算量的同时,提高了模型精度。
表达式

函数图像
import matplotlib.pyplot as plt
import numpy as np
class ActivateFunc():
def __init__(self, x, b=1, lamb=2, alpha=1, a=2):
super(ActivateFunc, self).__init__()
self.x = x
self.b = b
self.lamb = lamb
self.alpha = alpha
self.a = a
def __init__(self, x, b=1, lamb=2, alpha=1, a=2):
super(ActivateFunc, self).__init__()
self.x = x
self.b = b
self.lamb = lamb
self.alpha = alpha
self.a = a
def Sigmoid(self):
y = np.exp(self.x) / (np.exp(self.x) + 1)
y_grad = y*(1-y)
return [y, y_grad]
def Tanh(self):
y = np.tanh(self.x)
y_grad = 1 - y * y
return [y, y_grad]
def Swish(self): #b是一个常数,指定b
y = self.x * (np.exp(self.b*self.x) / (np.exp(self.b*self.x) + 1))
y_grad = np.exp(self.b*self.x)/(1+np.exp(self.b*self.x)) + self.x * (self.b*np.exp(self.b*self.x) / ((1+np.exp(self.b*self.x))*(1+np.exp(self.b*self.x))))
return [y, y_grad]
def ELU(self): # alpha是个常数,指定alpha
y = np.where(self.x > 0, self.x, self.alpha * (np.exp(self.x) - 1))
y_grad = np.where(self.x > 0, 1, self.alpha * np.exp(self.x))
return [y, y_grad]
def SELU(self): # lamb大于1,指定lamb和alpha
y = np.where(self.x > 0, self.lamb * self.x, self.lamb * self.alpha * (np.exp(self.x) - 1))
y_grad = np.where(self.x > 0, self.lamb*1, self.lamb * self.alpha * np.exp(self.x))
return [y, y_grad]
def ReLU(self):
y = np.where(self.x < 0, 0, self.x)
y_grad = np.where(self.x < 0, 0, 1)
return [y, y_grad]
def PReLU(self): # a大于1,指定a
y = np.where(self.x < 0, self.x / self.a, self.x)
y_grad = np.where(self.x < 0, 1 / self.a, 1)
return [y, y_grad]
def LeakyReLU(self): # a大于1,指定a
y = np.where(self.x < 0, self.x / self.a, self.x)
y_grad = np.where(self.x < 0, 1 / self.a, 1)
return [y, y_grad]
def Mish(self):
f = 1 + np.exp(x)
y = self.x * ((f*f-1) / (f*f+1))
y_grad = (f*f-1) / (f*f+1) + self.x*(4*f*(f-1)) / ((f*f+1)*(f*f+1))
return [y, y_grad]
def ReLU6(self):
y = np.where(np.where(self.x < 0, 0, self.x) > 6, 6, np.where(self.x < 0, 0, self.x))
y_grad = np.where(self.x > 6, 0, np.where(self.x < 0, 0, 1))
return [y, y_grad]
def Hard_Swish(self):
f = self.x + 3
relu6 = np.where(np.where(f < 0, 0, f) > 6, 6, np.where(f < 0, 0, f))
relu6_grad = np.where(f > 6, 0, np.where(f < 0, 0, 1))
y = self.x * relu6 / 6
y_grad = relu6 / 6 + self.x * relu6_grad / 6
return [y, y_grad]
def Hard_Sigmoid(self):
f = (2 * self.x + 5) / 10
y = np.where(np.where(f > 1, 1, f) < 0, 0, np.where(f > 1, 1, f))
y_grad = np.where(f > 0, np.where(f >= 1, 0, 1 / 5), 0)
return [y, y_grad]
def PlotActiFunc(x, y, title):
plt.grid(which='minor', alpha=0.2)
plt.grid(which='major', alpha=0.5)
plt.plot(x, y)
plt.title(title)
plt.show()
def PlotMultiFunc(x, y):
plt.grid(which='minor', alpha=0.2)
plt.grid(which='major', alpha=0.5)
plt.plot(x, y)
if __name__ == '__main__':
x = np.arange(-10, 10, 0.01)
activateFunc = ActivateFunc(x)
activateFunc.b = 1
PlotActiFunc(x, activateFunc.Sigmoid()[0], title='Sigmoid')
PlotActiFunc(x, activateFunc.Tanh()[0], title='Tanh')
PlotActiFunc(x, activateFunc.ReLU()[0], title='ReLU')
PlotActiFunc(x, activateFunc.LeakyReLU()[0], title='LeakyReLU')
PlotActiFunc(x, activateFunc.ReLU6()[0], title='ReLU6')
PlotActiFunc(x, activateFunc.Swish()[0], title='Swish')
PlotActiFunc(x, activateFunc.Mish()[0], title='Mish')
PlotActiFunc(x, activateFunc.ELU()[0], title='ELU')
PlotActiFunc(x, activateFunc.Hard_Swish()[0], title='Hard_Swish')
PlotActiFunc(x, activateFunc.Hard_Sigmoid()[0], title='Hard_Sigmoid')
plt.figure(1)
PlotMultiFunc(x, activateFunc.Swish()[0])
PlotMultiFunc(x, activateFunc.Mish()[0])
plt.legend(['Swish', 'Mish'])
plt.figure(2)
PlotMultiFunc(x, activateFunc.Swish()[0])
PlotMultiFunc(x, activateFunc.Hard_Swish()[0])
plt.legend(['Swish', 'Hard-Swish'])
plt.figure(3)
PlotMultiFunc(x, activateFunc.Sigmoid()[0])
PlotMultiFunc(x, activateFunc.Hard_Sigmoid()[0])
plt.legend(['Sigmoid', 'Hard-Sigmoid'])
plt.figure(4)
PlotMultiFunc(x, activateFunc.ReLU()[0])
PlotMultiFunc(x, activateFunc.ReLU6()[0])
plt.legend(['ReLU', 'ReLU6'])
plt.show()