真正的云原生大数据平台,让Kubernetes又牛了一把
作为一款开源的容器编排引擎,始于2014年的 Kubernetes 一经推出就受到了开发者的喜爱,谁也不曾想到它会取得如此大的成功。如今,在云原生技术发展的浪潮中,Kubernetes 作为容器编排领域的事实标准和云原生领域的关键项目,已经成为了云原生的标配。
— 1 —
Kubernetes 横空出世:改写容器编排市场格局
谈到 Kubernetes,就绕不开 Docker。
2010 年,一家名叫 dotCloud 的公司,基于 Google 公司推出的 Go 语言开发的一套内部工具,之后被命名为 Docker。作为一个用于开发、发布和运行应用程序的开放平台,Docker人气攀升速度之快,连Google、微软、Amazon这样的巨头们都对它青睐有加。
但随着业务规模逐渐扩大,容器越来越多,出现了一系列新问题,如何协调和调度这些容器?如何在升级应用程序时不会中断服务?如何监视应用程序的运行状况?如何批量重新启动容器里的程序……
解决这些问题需要的是容器编排技术,可以将众多机器抽象,对多个容器进行部署、管理和监控,作为真正的PaaS平台,让用户把自己的容器应用部署上来。
原来,容器本身没有“价值”,有价值的是容器编排。
于是,在2014年左右,Docker、Mesos、Google相继发布自己的PaaS平台,容器编排之争正式开始。
Docker携其在容器引擎市场的巨大成功,进入容器编排领域是顺理成章之事。2015年初 Docker 发布 Swarm,Swarm平台擅长与Docker生态无缝集成,用户可以低成本过渡。
Mesos在2014年成为首批支持Docker容器的容器编排框架之一,其最大优势是它在运行关键任务时的成熟度,比其他容器技术更成熟、更可靠,因而被Twitter、苹果、Netflix等公司所采用。
2014年6月,Google发布了Kubernetes,作为谷歌严格保密十几年的秘密武器—Borg的一个开源版本。也就是说,从一开始Kubernetes就站上了他人难以企及的高度,每一个核心特性的提出,几乎都脱胎于已经在Google内部运行了多年的 Borg/Omega 系统的设计与经验,在开源社区落地后,得益于整个社区的贡献,改进并修复了很多当年遗留在 Borg 体系中的缺陷和问题。
更为可贵的是,Kubernetes并未直接延用Borg,而是在这些宝贵经验的基础上从零开始设计,采用最先进的设计理念而没有任何历史包袱。
正是Kubernetes所体现出的独有的先进性与完备性,与“稚嫩”的Docker 技术栈和“老迈” 的 Mesos 社区相比,Kubernetes虽然出道晚,但后发优势明显。
2015 年 5 月,Kubernetes 在 Google 上的搜索热度远远超过 Mesos 和 Docker Swarm,之后一路飙升,容器编排引擎领域的三足鼎立时代结束。
2017年9月,Mesos宣布支持Kubernetes。
2017年10月,Docker官方支持Kubernetes。
2018年3月正式从CNCF毕业,开始坐上容器编排一哥之位。
如今,云原生大数据领域再出两大标志性事件,即2021年3月,Apache的Spark支持了Kubernetes;同年5月,Kafka也公开支持Kubernetes,标志着最核心的大数据组件现在都支持K8s。
— 2 —
Kubernetes 市场现状:超53%的企业将大数据应用程序迁移其上
或许,很多人认为Kubernetes是一款难以监控和管理的复杂软件,但在过去几年里,Kubernetes 经历了不可思议的发展,随着越来越多的企业投身使用,它已经从科研课题成为了 IT 行业的主流技术,这里的好处完全压倒了缺点。
据 Dimensional Research 最新研究发现,Kubernetes 正在成为主流技术的一个最明显迹象是要部署的集群数量出现快速增长。2020年提出此问题时,30% 的公司所拥有的集群数不超过 5 个,只有 15% 的公司拥有 50 个以上的集群。2022 年调查显示,只有 12% 的公司拥有不超过 5 个 集群,而 29% 的公司拥有 50 个以上的集群,且根据未来规划,来年可能出现更具爆炸性的增长。
关注公众号回复关键字【Clearpath】获取《2022年Kubernetes大数据报告(中文版)》
在Pepperdata的报告中显示,一半以上(53%)的受访者表示他们正在“将大数据应用程序迁移到Kubernetes,以降低整体支出。”77%的受访者表示,预计将50%或更多的大数据应用程序迁移到Kubernetes;约10%的受访者表示会将所有应用程序迁移过去。(回复关键字【Pepperdata】获取该报告完整中文版)
另外,在2022年春季,研究公司 Clearpath Strategies的调查报告中显示,83% 的受访者将超过 10% 的营业收入归功于在Kubernetes 上运行数据,三分之一的企业注意到企业生产力提高了两倍。
企业正在拥抱容器,因为它们可以更好地利用资源。
Dimensional Research报告显示,99% 的受访者表示,他们已经意识到部署Kubernetes 带来的优势。排在前两位的优势保持不变,依然是提高了资源利用率(59%),以及简化了应用升级和维护(49%)。第三是实现了向云环境的迁移(42%) ,第四是实现了混合云模式 (40%)。选择降低公有云成本(34%) 的受访者比例也比去年增加了 6%。
有三分之一左右的受访者选择了今年新增的两个选项:让运维团队成员更高效地工作和运用技能 (32%),以及消除之前孤立团队的低效 (28%)。Kubernetes 能够减少可能减缓运维的摩擦,帮助最大限度地提高 IT 资源利用率,让各个团队更高效、更紧密地协同工作。
— 3 —
Kubernetes 大有可为:对传统大数据平台进行改造
回顾Kubernetes发展史,分析其市场现状,无疑不说明K8s在企业的应用已相当广泛。但就目前来看,国内企业在使用K8s时,大多是在做云计算方面的相关调度,针对大数据领域,企业还在管理另一套纷繁复杂的系统,即传统大数据平台。
起初,企业如果想使用大数据平台,需要购买至少十几台服务器,找专业人员安装大数据的每个组件,安装后还需要一个开发平台、运维平台,以及购买各种各样的工具,建设和使用成本、门槛和决策风险比较高。
随后,传统大数据平台的短板和种种弊端慢慢显现。例如,多个部门共用集群,没有资源隔离和限制,且互相影响;系统依赖复杂的手动部署,且运维运营成本较高;资源利用率低,且难以集成既有数字化系统;没有标准的大数据组件发布流程,无法形成客户的自主数据能力。
现在,将这样的大数据平台迁移至K8s上,以上问题将迎刃而解,基于这个需求和背景之后,就出来一个名词叫做Data on Kubernete。
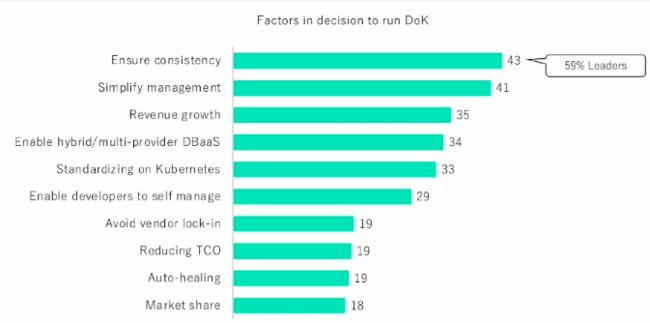
去年10月份北美的KubeCon刚刚结束,第一次组织了Data on Kubernetes专场,就是在讲如何在Kubernetes跑数据应用,这也从侧面说明了这一新兴热门领域得到了极大的关注。在DoK社区组织的行业报告中,展示的就是这些使用Data on Kubernetes的企业,为什么要把这些应用迁移到Kubernetes上,基于前两位的是保证管理的统一性以及简化管理。
至此,一款常常被客户称为“活的”“纯正的”云原生大数据平台浮出水面,它就是智领云自主研发的,作为市场上首个可完全在Kubernetes上部署的容器化云原生大数据平台--Kubernetes Data Platform (简称KDP)。
— 4 —
Kubernetes 改造思路:所有组件用K8s进行改造,做真正的云原生大数据平台
KDP能够称为纯正的K8s云原生大数据平台,是因为行业内很多企业在做,但大家的区别主要在于采取的路线不一样,KDP目前是市场上第一款公开的完全基于K8s搭建的容器大数据平台。
完全基于K8s搭建的大数据平台,目前在硅谷已经有很多实践,趋势比较明显。但在国内很多厂家还在处理原来传统大数据平台问题,总体来看,国内用户更希望能够从现有架构平稳地迁移,厂商也更谨慎些。
比如,某些厂商是基于自己的调度系统和分布式计算体系开发的大数据平台,虽然现在也在做 K8s 改造,把一部分调度工作移到了 K8s,但是绝大部分组件还是基于原来的大数据平台体系运行,并未真正地实现了云原生架构下的数据平台。
所以,多数大数据企业在K8s方面尽管做了很多工作,但智领云的差异化在于,其构建的是首个真正的K8s云原生大数据平台。之所以强调“真正”二字,是因为平台中的所有组件,都通过容器进行了重构,并纳入K8s的标准管理体系,而不仅仅是一部分。
这样做的价值是显而易见的,即使跨越不同的环境,只要底层基础设施是K8s环境,就无需反复处理物理基础架构的配置,也无需代码改造,大数据平台就可顺利地部署。
此外,“云原生大数据平台”的底层支撑,是一个全局共享的平台。用户可以将既有的系统迁移至资源池,实现更高的资源利用率。同时,云原生的存算分离架构,还可以分别管理冷热数据存储,即针对不同的应用场景,选择机械硬盘、固态硬盘、对象存储等不同的存储介质,以降低存储成本。
当然,KDP让用户完全去除了对Hadoop的依赖,可以直接在K8s环境中运行所有工作负载,统一资源管理,便于多租户计费管理,大幅降低运维成本。
综上,云原生大数据平台常听说,这次终于见到活的了。
- FIN -

更多精彩推荐
Kubernetes已经成为主流
智领云彭锋深度探讨“云原生时代的数据赋能”
智领云彭锋:云原生数据平台的最佳实践 | 甲子引力
“纯K8s”才是大数据的味道
明日黄花Hadoop方兴未艾——传统大数据平台的云原生化改造