JVM学习笔记
class文件结构
class十六进制码的顺序就是按下面的顺序排列的,解析的时候也是按照这个顺序解析
- 魔数
- 次要版本
- 主要版本
- 常量池常量数量 constant_pool_count
- 常量池
- access_flags 类的修饰符,2个字节
- this_class 指向常量池中表示本类的class_info类型的常量项的索引
- super_class 指向常量池中的表示父类class_info类型的常量项的索引
- interfaces_count 接口的数量
- interfaces
- fields_count 字段的数量
- fields
- methods_count 方法的数量
- methods
- attributes_count 属性的数量
- attributes
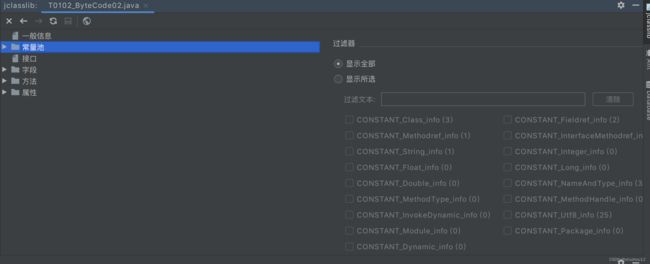
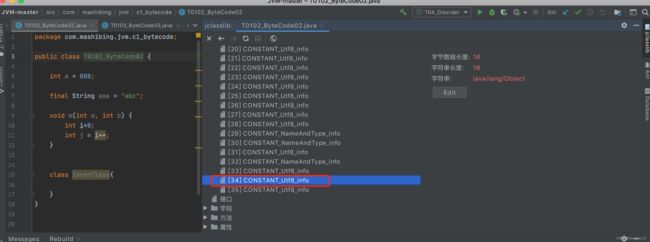
查看class文件的IDEA插件Jclasslib


常量池中的常量类型
- utf8_info
- tag: 常量类型,占一个字节,值为1
- length:表示uft8字符串的长度
- bytes: 存储长度为length的字符串
- integer_info
- tag: 值为3
- bytes: 4个字节,存储值
- float_info
- tag: 值为4
- bytes: 4个字节,存储值
- long_info
- tag: 值为5
- bytes: 8个字节,存储值
- double_info
- tag: 值为6
- bytes: 8个字节,存储值
- class_info
- tag: 值为7
- index: 2个字节,指向类的全限定名称的索引
- string_info
- tag: 值为8
- index: 2个字节,指向字符串字面量的索引
- Fieldref_info
- tag: 值为9
- index: 2个字节,指向声明字段的类或接口描述符class_info的索引
- index: 2个字节,指向字段描述符NameAndType_info的索引
- Methodref_info
- tag: 值为10
- index: 2个字节,指向声明方法的类或接口描述符class_info的索引
- index: 2个字节,指向字段描述符NameAndType_info的索引
- InterfaceMethodref_info
- tag: 值为11
- index: 2个字节,指向声明方法的类或接口描述符class_info的索引
- index: 2个字节,指向字段描述符NameAndType_info的索引
- NameAndType_info
- tag: 值为12
- index: 2个字节,指向该字段或方法名称常量项的索引
- index: 2个字节,指向该字段或方法描述符常量项的索引
- MethodHandle_info
- tag: 值为15
- reference_kind: 1个字节,1-9之间的一个值,决定了方法句柄的类型。方法句柄类型的值表示方法句柄的字节码行为
- reference_index: 2个字节,对常量池的有效索引
- MethodType_info
- tag: 值为16
- descriptor_index: 2个字节,指向utf8_info结构表示的方法描述符
- InvokeDynamic_info
- tag: 值为18
- bootstrap_method_attr_index: 2个字节,当前Class文件中引导方法表的bootstrap_methods[]数组的有效索引
- name_and_type_index: 2个字节,指向NameAndType_info表示的方法名和方法描述符
示例


access_flags
占用两个字节,access_flags的值和下面的每一项进行与操作,对应的二进制位上为1则表示该位为真。
- ACC_PUBLIC 0x0001 是否为public
- ACC_FINAL 0x0010 是否为final
- ACC_SUPER 0x0020 该位必须为真,jdk1.0.2之后编译出来的内容,指明invokespectial指令使用新语义。
- ACC_INTERFACE 0X0200 是否是接口
- ACC_ABSTRACT 0X0400 是否是抽象类
- ACC_SYNTHETIC 0X1000 编译器自动生成的
- ACC_ANNOTATION 0x2000 是否是注解
- ACC_ENUM 0X4000 是否是枚举
示例

methods
- name_index 2个字节,指向常量池中utf8_info类型的常量项,表示方法的名称
- descriptor_index 2个字节,指向常量池中utf8_info类型的常量项,表示方法的描述符
- access_flags 2个字节,方法的访问标志
- attributes_count 方法的属性数量
- attributes 方法的属性列表,属性中是可以嵌套属性的,最重要的属性就是Code属性,它里面包含了方法的代码,里面存的是jvm的字节码指令,这些指令的含义可以在jvm规范中查询,总共有两百多个指令。
方法descriptor的语法
先参数列表后返回值,参数放在小括号内, (参数)返回值。
void m() -> ()V
String toString() -> ()Ljava/lang/String
int add(int a, int b) -> (II)I
- B btye
- C char
- D double
- F float
- I int
- J long
- S short
- Z boolean
- V void
- L Object 例如Lcom/mashibing/jvm/Test
- [ 数组, 一维数组[B [Ljava/lang/String 多维数组 [[C [[Ljava/lang/String
方法的access_flags
- ACC_PUBLIC
- ACC_PRIVATE
- ACC_PROTECTED
- ACC_STATIC
- ACC_FINAL
- ACC_SYNCHRONIZED
- ACC_BRIDGE 编译器产生的桥接方法,子类继承泛型的父类或接口时,由于父类的泛型方法编译之后的方法参数类型是Object,而子类中没有参数是Object类型的方法,所以编译器会自动生成参数是Object类型的桥接方法,桥接方法会调用实际的方法。https://www.cnblogs.com/monianxd/p/16517435.html
- ACC_VARARGS
- ACC_NATIVE
- ACC_ABSTRACT
- ACC_STRICTFP
- ACC_SYNTHETIC 是编译器生成的
示例




fields 字段
- name_index 2个字节,指向常量池中utf8_info类型的常量项,表示字段的名称
- descriptor_index 2个字节,指向常量池中utf8_info类型的常量项,表示字段的描述符
- access_flags 2个字节,方法的访问标志
- attributes_count
- attributes
字段的access_flags
- ACC_PUBLIC
- ACC_PRIVATE
- ACC_PROTECTED
- ACC_STATIC
- ACC_FINAL
- ACC_VOLATILE
- ACC_TRANSIENT
- ACC_SYNTHETIC
- ACC_ENUM
示例


attributes 属性
类,方法表, 字段表,分别表示这个属性会在类文件、methods、fields中出现。
- Code,方法表,该方法编译成的字节码指令。
- ConstantValue, 字段表,final关键字定义的常量值
- Deprecated, 类、方法表、字段表
- Exceptions, 方法表
- EnclosingMethod, 类文件,局部类或匿名类的外部封装方法
- InnerClasses, 类文件,内部类列表
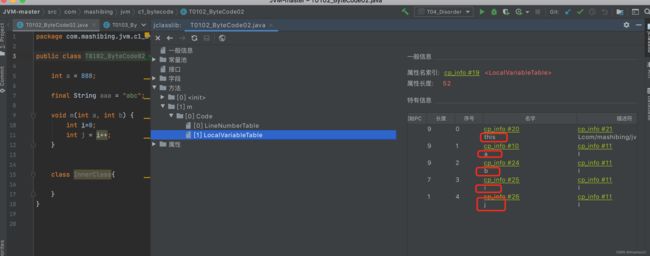
- LineNumberTable, Code的属性,java源码的行号与字节码指令的对应关系
- LocalVariableTable, Code的属性,方法的局部变量表
- SourceFile, 类文件-源文件的名称
code属性包含哪些部分
- attribute_name_index u2
- attribute_length u4
- max_stack u2
- max_locals u2
- code_length u4
- code
- exception_table_length u2
- exception_table
- attribute_count u2
- attributes
示例

类加载器
类加载过程
hello.java -> javac -> hello.class

JVM, JRE, JDK的关系
- JVM,ava虚拟机
- JRE = JVM + core lib。 core lib是指java的核心库,比如String,Object这些类所在的库。
- JDK = JRE + devlepment kit。 devlepment kit指java官方提供的开发工具。如java javac jps jstack
类加载器的双亲委派机制
从底向上询问类加载器是否已经加载了某个class,如果没有加载则继续向上询问父加载器,父加载器通过getParent()方法获得,如果询问到BootStrap类加载器都没有加载到这个class,则从上向下委派加载。每个classLoader内部都有一儿缓存,缓存加载过的类。
为什么需要双亲委派机制?主要是因为安全性,加载加载java.lang.String类,如果不向上面的类加载器询问,而是下面的类加载器直接加载,那么jdk中的类就可以被我们定义的类覆盖了。

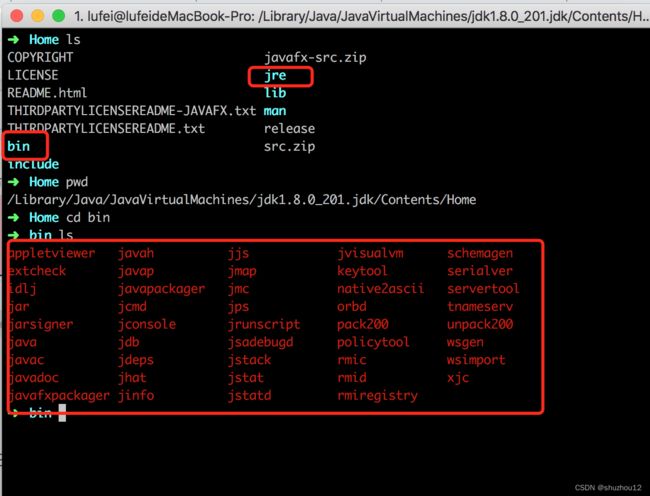
加载器加载class文件的位置
-
AppClassLoader类加载器加载class的位置
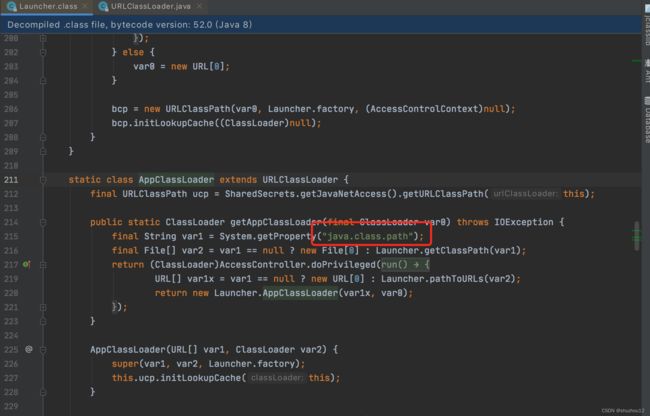
-
ExtClassLoader类加载器加载class的位置
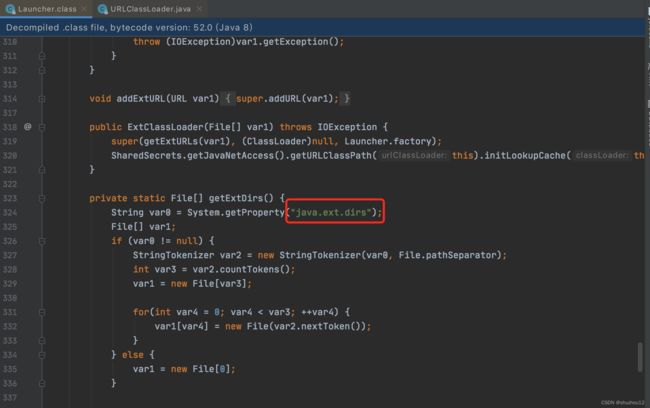
-
BootStrapClassLoader类加载器加载class的位置

测试程序
String pathBoot = System.getProperty("sun.boot.class.path");
System.out.println(pathBoot.replaceAll(":", System.lineSeparator()));
System.out.println("--------------------");
String pathExt = System.getProperty("java.ext.dirs");
System.out.println(pathExt.replaceAll(":", System.lineSeparator()));
System.out.println("--------------------");
String pathApp = System.getProperty("java.class.path");
System.out.println(pathApp.replaceAll(":", System.lineSeparator()));
//运行结果
/Library/Java/JavaVirtualMachines/jdk1.8.0_201.jdk/Contents/Home/bin/java -javaagent:/Applications/IntelliJ IDEA.app/Contents/lib/idea_rt.jar=55565:/Applications/IntelliJ IDEA.app/Contents/bin -Dfile.encoding=UTF-8 -classpath /Library/Java/JavaVirtualMachines/jdk1.8.0_201.jdk/Contents/Home/jre/lib/charsets.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_201.jdk/Contents/Home/jre/lib/deploy.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_201.jdk/Contents/Home/jre/lib/ext/cldrdata.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_201.jdk/Contents/Home/jre/lib/ext/dnsns.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_201.jdk/Contents/Home/jre/lib/ext/jaccess.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_201.jdk/Contents/Home/jre/lib/ext/jfxrt.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_201.jdk/Contents/Home/jre/lib/ext/localedata.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_201.jdk/Contents/Home/jre/lib/ext/nashorn.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_201.jdk/Contents/Home/jre/lib/ext/sunec.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_201.jdk/Contents/Home/jre/lib/ext/sunjce_provider.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_201.jdk/Contents/Home/jre/lib/ext/sunpkcs11.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_201.jdk/Contents/Home/jre/lib/ext/zipfs.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_201.jdk/Contents/Home/jre/lib/javaws.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_201.jdk/Contents/Home/jre/lib/jce.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_201.jdk/Contents/Home/jre/lib/jfr.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_201.jdk/Contents/Home/jre/lib/jfxswt.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_201.jdk/Contents/Home/jre/lib/jsse.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_201.jdk/Contents/Home/jre/lib/management-agent.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_201.jdk/Contents/Home/jre/lib/plugin.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_201.jdk/Contents/Home/jre/lib/resources.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_201.jdk/Contents/Home/jre/lib/rt.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_201.jdk/Contents/Home/lib/ant-javafx.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_201.jdk/Contents/Home/lib/dt.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_201.jdk/Contents/Home/lib/javafx-mx.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_201.jdk/Contents/Home/lib/jconsole.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_201.jdk/Contents/Home/lib/packager.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_201.jdk/Contents/Home/lib/sa-jdi.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_201.jdk/Contents/Home/lib/tools.jar:/Users/lufei/development/git_repository/JVM-master/out/production/JVM com.mashibing.jvm.c2_classloader.T003_ClassLoaderScope
/Library/Java/JavaVirtualMachines/jdk1.8.0_201.jdk/Contents/Home/jre/lib/resources.jar
/Library/Java/JavaVirtualMachines/jdk1.8.0_201.jdk/Contents/Home/jre/lib/rt.jar
/Library/Java/JavaVirtualMachines/jdk1.8.0_201.jdk/Contents/Home/jre/lib/sunrsasign.jar
/Library/Java/JavaVirtualMachines/jdk1.8.0_201.jdk/Contents/Home/jre/lib/jsse.jar
/Library/Java/JavaVirtualMachines/jdk1.8.0_201.jdk/Contents/Home/jre/lib/jce.jar
/Library/Java/JavaVirtualMachines/jdk1.8.0_201.jdk/Contents/Home/jre/lib/charsets.jar
/Library/Java/JavaVirtualMachines/jdk1.8.0_201.jdk/Contents/Home/jre/lib/jfr.jar
/Library/Java/JavaVirtualMachines/jdk1.8.0_201.jdk/Contents/Home/jre/classes
--------------------
/Users/lufei/Library/Java/Extensions
/Library/Java/JavaVirtualMachines/jdk1.8.0_201.jdk/Contents/Home/jre/lib/ext
/Library/Java/Extensions
/Network/Library/Java/Extensions
/System/Library/Java/Extensions
/usr/lib/java
--------------------
/Library/Java/JavaVirtualMachines/jdk1.8.0_201.jdk/Contents/Home/jre/lib/charsets.jar
/Library/Java/JavaVirtualMachines/jdk1.8.0_201.jdk/Contents/Home/jre/lib/deploy.jar
/Library/Java/JavaVirtualMachines/jdk1.8.0_201.jdk/Contents/Home/jre/lib/ext/cldrdata.jar
/Library/Java/JavaVirtualMachines/jdk1.8.0_201.jdk/Contents/Home/jre/lib/ext/dnsns.jar
/Library/Java/JavaVirtualMachines/jdk1.8.0_201.jdk/Contents/Home/jre/lib/ext/jaccess.jar
/Library/Java/JavaVirtualMachines/jdk1.8.0_201.jdk/Contents/Home/jre/lib/ext/jfxrt.jar
/Library/Java/JavaVirtualMachines/jdk1.8.0_201.jdk/Contents/Home/jre/lib/ext/localedata.jar
/Library/Java/JavaVirtualMachines/jdk1.8.0_201.jdk/Contents/Home/jre/lib/ext/nashorn.jar
/Library/Java/JavaVirtualMachines/jdk1.8.0_201.jdk/Contents/Home/jre/lib/ext/sunec.jar
/Library/Java/JavaVirtualMachines/jdk1.8.0_201.jdk/Contents/Home/jre/lib/ext/sunjce_provider.jar
/Library/Java/JavaVirtualMachines/jdk1.8.0_201.jdk/Contents/Home/jre/lib/ext/sunpkcs11.jar
/Library/Java/JavaVirtualMachines/jdk1.8.0_201.jdk/Contents/Home/jre/lib/ext/zipfs.jar
/Library/Java/JavaVirtualMachines/jdk1.8.0_201.jdk/Contents/Home/jre/lib/javaws.jar
/Library/Java/JavaVirtualMachines/jdk1.8.0_201.jdk/Contents/Home/jre/lib/jce.jar
/Library/Java/JavaVirtualMachines/jdk1.8.0_201.jdk/Contents/Home/jre/lib/jfr.jar
/Library/Java/JavaVirtualMachines/jdk1.8.0_201.jdk/Contents/Home/jre/lib/jfxswt.jar
/Library/Java/JavaVirtualMachines/jdk1.8.0_201.jdk/Contents/Home/jre/lib/jsse.jar
/Library/Java/JavaVirtualMachines/jdk1.8.0_201.jdk/Contents/Home/jre/lib/management-agent.jar
/Library/Java/JavaVirtualMachines/jdk1.8.0_201.jdk/Contents/Home/jre/lib/plugin.jar
/Library/Java/JavaVirtualMachines/jdk1.8.0_201.jdk/Contents/Home/jre/lib/resources.jar
/Library/Java/JavaVirtualMachines/jdk1.8.0_201.jdk/Contents/Home/jre/lib/rt.jar
/Library/Java/JavaVirtualMachines/jdk1.8.0_201.jdk/Contents/Home/lib/ant-javafx.jar
/Library/Java/JavaVirtualMachines/jdk1.8.0_201.jdk/Contents/Home/lib/dt.jar
/Library/Java/JavaVirtualMachines/jdk1.8.0_201.jdk/Contents/Home/lib/javafx-mx.jar
/Library/Java/JavaVirtualMachines/jdk1.8.0_201.jdk/Contents/Home/lib/jconsole.jar
/Library/Java/JavaVirtualMachines/jdk1.8.0_201.jdk/Contents/Home/lib/packager.jar
/Library/Java/JavaVirtualMachines/jdk1.8.0_201.jdk/Contents/Home/lib/sa-jdi.jar
/Library/Java/JavaVirtualMachines/jdk1.8.0_201.jdk/Contents/Home/lib/tools.jar
/Users/lufei/development/git_repository/JVM-master/out/production/JVM
/Applications/IntelliJ IDEA.app/Contents/lib/idea_rt.jar
父加载器
双亲委派中的概念,加载器的父加载器。
测试程序
//加载器是BootStrap
System.out.println(String.class.getClassLoader());
//加载器是BootStrap
System.out.println(sun.awt.HKSCS.class.getClassLoader());
//加载器是Ext
System.out.println(sun.net.spi.nameservice.dns.DNSNameService.class.getClassLoader());
//加载器是App
System.out.println(T002_ClassLoaderLevel.class.getClassLoader());
//加载App和Ext类加载器的类加载器都是BootStrap
System.out.println(sun.net.spi.nameservice.dns.DNSNameService.class.getClassLoader().getClass().getClassLoader());
System.out.println(T002_ClassLoaderLevel.class.getClassLoader().getClass().getClassLoader());
//自定义类加载器的父加载器是App
System.out.println(new T006_MSBClassLoader().getParent());
System.out.println(ClassLoader.getSystemClassLoader());
//运行结果
null
null
sun.misc.Launcher$ExtClassLoader@5e2de80c
sun.misc.Launcher$AppClassLoader@18b4aac2
null
null
sun.misc.Launcher$AppClassLoader@18b4aac2
sun.misc.Launcher$AppClassLoader@18b4aac2
自定义类加载器
使用场景,加密源码,使用自定义类加载器解密
源码
测试代码
//调用classLoader的loadClass()方法
Class clazz = T005_LoadClassByHand.class.getClassLoader().loadClass("com.mashibing.jvm.c2_classloader.T002_ClassLoaderLevel");
System.out.println(clazz.getName());
protected Class<?> loadClass(String name, boolean resolve)
throws ClassNotFoundException
{
synchronized (getClassLoadingLock(name)) {
// First, check if the class has already been loaded
Class<?> c = findLoadedClass(name);
if (c == null) {
long t0 = System.nanoTime();
try {
//如果自己没有加载过,则委托父加载器递归调用这个方法,递归结束的条件是父加载器加载过这个此class或者父加载器是BootStrap。
if (parent != null) {
c = parent.loadClass(name, false);
} else {
//如果当前是BootStrap加载器,则停止递归,直接加载class,但是可能加载不到此class,返回null
c = findBootstrapClassOrNull(name);
}
} catch (ClassNotFoundException e) {
// ClassNotFoundException thrown if class not found
// from the non-null parent class loader
}
//如果父加载器没有加载到此class,则调用自己覆写父类的findClass(name)方法
if (c == null) {
// If still not found, then invoke findClass in order
// to find the class.
long t1 = System.nanoTime();
//子类覆写这个方法
c = findClass(name);
// this is the defining class loader; record the stats
sun.misc.PerfCounter.getParentDelegationTime().addTime(t1 - t0);
sun.misc.PerfCounter.getFindClassTime().addElapsedTimeFrom(t1);
sun.misc.PerfCounter.getFindClasses().increment();
}
}
if (resolve) {
resolveClass(c);
}
return c;
}
}
实现自定义类加载器
通过分析源码,自定义类加载器只需要继承ClassLoader类,然后覆写findClass()方法即可。
public class T006_MSBClassLoader extends ClassLoader {
@Override
protected Class<?> findClass(String name) throws ClassNotFoundException {
File f = new File("c:/test/", name.replace(".", "/").concat(".class"));
try {
FileInputStream fis = new FileInputStream(f);
ByteArrayOutputStream baos = new ByteArrayOutputStream();
int b = 0;
while ((b=fis.read()) !=0) {
baos.write(b);
}
byte[] bytes = baos.toByteArray();
baos.close();
fis.close();//可以写的更加严谨
return defineClass(name, bytes, 0, bytes.length);
} catch (Exception e) {
e.printStackTrace();
}
return super.findClass(name); //throws ClassNotFoundException
}
}
打破双亲委派机制
自定义类加载器直接覆写loadClass()方法
loading linking initialization
运行时常量池
JVM会为每一个class或interface创建运行时常量池。
运行时常量池中的东西主要是从class或interface二进制文件中的constant_pool中提取出各种类型的符号引用,存到内存中以便程序运行时使用。有以下类型的符号引用:
- 表示class or interface的符号引用,从CONSTANT_Class_info中获取。此符号引用中保存了class或interface的名称,这个名称和Class.getName()方法返回的一样。如果class是数组,假设是n维数组,则返回的名称是 n个[ + 数组元素的类名 + ;
- field of a class or an interface -> CONSTANT_Fieldref_info
- method of a class -> CONSTANT_Methodref_info
• a method of an interface -> CONSTANT_InterfaceMethodref_info
• method handle -> CONSTANT_MethodHandle_info。这种类型的符号引用可能指向a field of a class or interface, or a method of a class, or a method of an interface取决于是哪种类型的method handle
• method type -> CONSTANT_MethodType_info,这种类型的符号引用保存了method descriptor。method descriptor指定了一个方法的所有参数的类型和返回值的类型。比如一个方法Object m(int i, double d, Thread t) {…}的method descriptor是(IDLjava/lang/Thread;)Ljava/lang/Object;
• call site specifier -> CONSTANT_InvokeDynamic_info,这种类型的符号引用保存的内容略。
运行时常量池中有些东西不是符号引用,但是也是从字节码文件中的constant_pool中提取的,如下所示
• A string literal is a reference to an instance of class String, and is derived from a CONSTANT_String_info structure。java编程语言需要同样的字符串必须指向同一个String类的实例。
• Run-time constant values are derived from CONSTANT_Integer_info,
CONSTANT_Float_info, CONSTANT_Long_info, CONSTANT_Double_info。
顺序
类加载过程就是指类加载器加载class文件的过程。
- loading, 加载
- linking 连接
- verification 验证
- preparation 准备
- resolution 解析
- initialzing 初始化
- using 使用
- unloading 卸载
加载,连接, 验证,准备,初始化这五个阶段的会按顺序开始,注意只是按顺序开始,并不是按顺序完成或结束。一个阶段执行的过程中可能会交叉执行另一个阶段的执行。解析阶段在某些情况下可以在初始化阶段之后再开始,这是为了支持java语言的动态绑定。
初始化阶段开始的触发条件
- 遇到new,getstatic,putstatic,invokestatic这四条字节码指令时,如果类没有进行过初始化,则需要先触发其初始化。
- 使用new关键字实例化对象的时候
- 读取或设置一个类的静态字段的时候,被final修饰,已在编译器把结果放入常量池的静态字段除外。
- 调用一个类的静态方法的时候
- 使用java.lang.reflect包的方法对类进行反射调用的时候
- 初始化一个类的时候,如果发现其父类还没有进行过初始化,要先触发其父类的初始化
- 当虚拟器启动时,需要用户指定一个要执行的主类,虚拟机会先初始化这个主类。
jvm规范中并没有进行强制约束什么情况下需要开始类加载过程的第一个阶段,但是以上四种条件触发初始化阶段开始之前, 加载,验证,准备需要在此之前开始。
方法的细节
初始化过程其实就是执行方法
- 这个方法是由编译器自动收集类中的所有类变量的赋值动作和静态语句块中的语句合并产生的,编译器收集的顺序是由语句在源文件中出现的顺序所决定的,静态语句块中只能访问到定义在静态语句块之前的变量。
- 父类的方法先执行。但是接口的方法不需要先执行父接口的方法,只有当父接口中定义的变量使用时,父接口才会初始化。另外,接口的实现类在初始化的时候也一样不会执行接口的方法。
- 方法对于类或接口来说并不是必须的,如果一个类中没有静态语句块,也没有对静态变量的赋值操作,那么编译器可以不为这个类生成此方法。
- 接口中不能使用静态语句块,但仍然有变量初始化的赋值操作,因此接口与类一样都会生成方法。
加载
加载阶段,虚拟机需要完成以下三件事情:
- 通过一个类的全限定名来获取定义此类的二进制字节流
jvm规范并没有指明必须从一个Class文件中获取二进制字节流,准确的说是根本没有指明要从哪里获取怎样获取。许多举足轻重的java技术都建立在这一基础上,例如:
- 从zip包中读取,这很常见,最终成为日后jar,ear,war格式的基础
- 从网络中获取,这种场景最典型的应用就是Applet
- 运行时计算生成,这种场景使用的最多的就是动态代理技术。在java.lang.reflect.Proxy中,就是用了ProxyGenerator.generateProxyClass来为特定接口生成形式为"*$Proxy"的代理类的二进制字节流。
- 由其它文件生成,典型场景是jsp应用,即由jsp文件生成对应的Class类。
- 将这个字节流所代表的静态存储结构转化为方法区的运行时数据结构
- 在内存中生成一个代表这个类的Class对象,作为方法区这个类的各种数据的访问入口。Class对象比较特殊,它虽然是对象,但是存放在方法区里面。
Loading Constraints
jvm要确保在有多个类加载器的的情况下进行class的安全linking。虽然同一个符号引用N,被不同的类加载器加载的class有可能是不同class。
但是当在类C =
linking
linking一个class或interface包含验证和准备这个class或interface,以及它的父类,它的父接口。符号引用的解析是可选的,不一定在linking阶段发生。
jvm规范并没有规定linking阶段什么时候发生,只要满足以下条件即可:
- linking之前class或interface已经loading完毕
- 初始化之前,class或interface已经验证和准备完毕,这时解析是否完成不要求。
例如如果jvm参数配置的解析阶段是"lazy" or “late”,jvm会分别解析class或interface中的符号引用,如果配置的是"eager" or “static” ,jvm会一次性解析class或interface中所有的符号引用。
因为linking阶段涉及分配内存,所以这个阶段可能会抛出OutOfMemoryError
验证
验证可能会load别的class或interface,但是不会需要验证和准备别的class或interface。
验证阶段大致上会完成下面4个阶段的检验动作: 文件格式验证,元数据验证,字节码验证,符号引用验证。
- 文件格式验证
验证字节流是否符合Class文件格式的规范,比如是否已魔数0xCAFEBABE开头,主次版本号是否在当前虚拟机处理范围内,常量池的常量中是否有不被支持的常量类型等等。该阶段验证的主要目的是保证输入的字节流能正确的解析并存储于方法区之内,格式上符合描述一个java类型信息的要求。只有这个阶段的验证通过后,字节流才会进入内存的方法区中进行存储,所以后面的3个验证阶段全部是基于方法区的存储结构进行的,不会再直接操作字节流。 - 元数据验证
对字节码描述的信息进行语义分析,以保证其描述的信息符合java语言规范的要求。
- 这个类是否有父类
- 这个类的父类是否继承了不允许被继承的类(被final修饰的类)
- 如果这个类不是抽象类,是否实现类其父类或接口中要求实现的所有方法
- 类中的字段,方法是否与父类产生矛盾(例如覆盖了父类的final字段,或者出现不符合规则的方法重载,例如方法参数都一致,但返回值类型却不同等)
- 字节码验证 (对方法体的验证)
这个阶段是验证过程中最复杂的一个阶段,主要目的是通过数据流和控制流分析,确定程序语义是合法的符合逻辑的。在上个阶段对元数据信息中的数据类型做完校验后,这个阶段将对类的方法体进行校验分析,保证被校验类的方法体在运行时不会做出危害虚拟机安全的事件,例如:
- 保证任意时刻操作数栈的数据类型与指令代码序列都能配合工作,例如不会出现在操作数栈放置了一个int类型的数据,使用时却按long类型在加载入本地变量表中。
- 保证跳转指令不会跳转到方法体以外的字节码指定上
- 保证方法体重的类型转换是有效的,例如不能把父类对象赋值给子类引用上。
- 符号引用验证 (对引用外部信息的验证)
最后一个阶段的校验法伤在虚拟机将符号引用转化为直接引用的时候,这个转化动作将在解析阶段中发生。符合引用验证可以看做是类对自身以外(常量池中的各种符号引用)的信息进行匹配性校验,通常需要校验下列内容:
- 符号引用中通过字符串描述的全限定名是否能找到对应的类
- 在指定类中是否存在符合方法的字段描述符以及简单名称所描述的方法和字段
- 符号引用中的类,字段,方法的访问性(private, protected,public,default)是否可以被当前类访问。
符号引用验证的目的是确保解析动作能正常执行。如果所运行的全部代码都已经被反复使用和验证过,那么可以考虑使用-Xverify:none参数来关闭大部分的类验证措施,以缩短虚拟机类加载的时间。
准备
准备阶段是正式为类变量分配内存并设置类初始值的阶段,这些变量所使用的内存都将在方法区中进行分配。准备阶段必须在初始化之前结束。
解析
解析阶段是虚拟机将常量池内的符号引用替换为直接引用的过程,符号引用在Class文件中它以CONSTANT_Class_info, fieldref_info,methodref_info等类型的常量出现。
虚拟机规范中并未规定解析阶段发生的具体时间,只要求了在执行这16个用于操作符号引用的字节码指令之前,先对它们所使用的符号引用进行解析。所以虚拟机实现可以根据需要来判断是在类加载器加载时就对常量池中的符号引用进行解析,还是等到一个符号引用将要被使用前才去解析它。
- anewarray
- checkcast
- getfield
- getstatic
- instanceof
- invokedynamic
- invokeinterface
- invokespecial
- invokestatic
- invokevirtual
- ldc
- ldc_w
- multianewarray
- new
- putfield
- putstatic
解析动作主要针对类或接口,字段,类方法,接口方法,方法类型,方法句柄和调用点这7类符号引用进行,分别对应常量池的 - class_info
- fieldref_info
- methodref_info
- interfaceMethodref_info
- methodType_info
- mehtodHandle_info
- invokeDynamic_info
具体解析过程参考链接解析过程描述
Class and Interface Resolution
- 使用当前类的classLoader load符号引用对应的class或interface。
- 如果加载的class是一个数组类型的,并且它的元素类型是reference类型,则继续解析数组元素类型。
- 最后校验当前类是否有访问符号引用对应的class的访问权限
Field Resolution
假设当前类是D,要解析的field的符号引用中指定的class或interface是C。
- 在解析field之前,先要解析field_info中对应的class或interface的符号引用,按照Class and Interface Resolution的步骤解析即可,假设这个类为C
- 如果C中声明了一个和filed符号引用中的name and descriptor完全一样的字段,则使用这个字段
- 否则,到C的父接口中找
- 否则,到C的父类中找
- 否则,解析失败
然后 - 如果解析失败,则抛出NoSuchFieldError
- 否则,判断当前类对filed的访问权限,如果没有权限则抛出IllegalAccessError
- 否则,假设前面找到的最终包含该field的class是
Method Resolution
要在一个class D中解析class C的method,需要先解析C的符号引用,这一步参考Class and Interface Resolution。解析方法的步骤如下:
- 如果C是一个interface, 则抛出IncompatibleClassChangeError
- 否则,如果C声明了一个和method reference的name和descriptor都一样的方法,则查找成功
- 否则,递归向C的父类中查找方法
- 否则,递归向C的父接口中查找方法,如果查找到某个父接口中声明了这个方法,并且方法的ACC标记不是ACC_ABSTRACT,并且ACC_PRIVATE和ACC_STATIC都没有设置,则查找成功。ACC_STATIC表示该方法是一个class initial方法,只有方法的这个标记才会设置
- 否则,如果任意父接口中声明了这个方法,并且这个方法的ACC_PRIVATE和ACC_STATIC都没有设置,则任意选择一个方法,查找成功。
- 否则,方法解析失败,抛出NoSuchMethodError。
如果方法解析成功,还要执行如下校验: - 解析的方法对类D是否是可以访问的,如果不是的,则抛出IllegalAccessError
- 假设
Interface Method Resolution
要在一个class D中解析interface C的method,需要先解析C的符号引用,这一步参考Class and Interface Resolution。解析方法的步骤如下:
- 如果C是一个class, 则抛出IncompatibleClassChangeError
- 否则,如果C声明了一个和method reference的name和descriptor都一样的方法,则查找成功
- 否则,如果Object声明了一个和method reference的name和descriptor都一样的方法,则查找成功
- 否则,递归向C的父接口中查找方法,如果查找到某个父接口中声明了这个方法,并且方法的ACC标记不是ACC_ABSTRACT,并且ACC_PRIVATE和ACC_STATIC都没有设置,则查找成功。ACC_STATIC表示该方法是一个class initial方法,只有方法的这个标记才会设置
- 否则,如果任意父接口中声明了这个方法,并且这个方法的ACC_PRIVATE和ACC_STATIC都没有设置,则任意选择一个方法,查找成功。
- 否则,方法解析失败,抛出NoSuchMethodError。
如果方法解析成功,还要执行如下校验: - 解析的方法对类D是否是可以访问的,如果不是的,则抛出IllegalAccessError
- 假设
Method Type and Method Handle Resolution
对method type和method handle的作用还不清楚,忽略。
Call Site Specifier Resolution
对Call Site Specifier的作用还不清楚,忽略
确定执行哪个方法(多态)
在执行invokeinterface指令或invokevirtual指令时,会根据当前操作数栈中的对象和invokeinterface或invokevirtual指令之前解析的method对象,确定执行哪个method,假设操作数栈中的对象的类型是C, C是一个class或interface,之前指令解析的method是mR,确定执行哪个class中的方法的规则如下:
实际代码执行时,可能变量声明的类型是C的父类D,而实际的对象也就是操作数栈中的对象的类型是C,那么虽然method_info中class_info指向的是D,但是解析具体要执行的方法时应该先找C中有没有这个方法,这就是多态。
- 如果method_info中被标记为ACC_PRIVATE,那这个中的方法就是要执行的方法。
- 否则,如果C中有这个method,并且是可以覆写mR的,则使用C中的这个method。
- 否则,依次向上找C的父类,直到找到父类中有可以覆写mR的method
- 否则,找C的父接口,如果接口中有和mR相同描述的method,并且不是abstract的,则使用这个method。
- 否则,找不到方法报错。
停止jvm
当security manager允许exit或halt操作时,调用Runtime或System的exit方法,或者调用Runtime的halt方法时,就会停止jvm。
对象创建过程
- class loading
- class linking(验证,准备,解析)
- class initializing
- 申请对象内存
- 成员变量赋默认值
- 调用方法
对象的内存布局(以64位机器为例)
普通对象的内存布局
- 对象头(markword), 8个字节
- class指针, -xx:+useCompressedClassPointers 开启则是4个字节,否则是8个字节
- 对象数据(各种类型的属性), 基本类型属性就是对应大小,引用类型属性如果-xx:+UseCompressedOops开启,则是4个字节,否则8个字节。 oops全称是普通对象引用。
- padding,字节补齐,使整个对象的大小为8字节的倍数。因为cpu读取内存的时候是整块读取的。
数组对象的内存布局
- 对象头(markword), 8个字节
- class指针, -xx:+useCompressedClassPointers 开启则是4个字节,否则是8个字节
- 数组长度,4个字节,这就是数组数量的上限
- 数据数据
- padding
对象的大小(使用javaagent 做实验测试)
思路:写一个javaagent获取对象大小。
-
新建项目ObjectSize(1.8)
-
创建文件ObjectSizeAgent
package com.mashibing.jvm.agent;
import java.lang.instrument.Instrumentation;
public class ObjectSizeAgent {
private static Instrumentation inst;
public static void premain(String agentArgs, Instrumentation _inst) {
inst = _inst;
}
public static long sizeOf(Object o) {
return inst.getObjectSize(o);
}
}
- src目录下创建META-INF/MANIFEST.MF
Manifest-Version: 1.0
Created-By: mashibing.com
Premain-Class: com.mashibing.jvm.agent.ObjectSizeAgent
注意Premain-Class这行必须是新的一行(回车 + 换行),确认idea不能有任何错误提示
-
打包jar文件
-
在需要使用该Agent Jar的项目中引入该Jar包
project structure - project settings - library 添加该jar包 -
运行时需要该Agent Jar的类,加入参数:
-javaagent:C:\work\ijprojects\ObjectSize\out\artifacts\ObjectSize_jar\ObjectSize.jar
- 如何使用该类:
package com.mashibing.jvm.c3_jmm;
import com.mashibing.jvm.agent.ObjectSizeAgent;
public class T03_SizeOfAnObject {
public static void main(String[] args) {
System.out.println(ObjectSizeAgent.sizeOf(new Object()));// 8 + 4 + padding = 16个字节
System.out.println(ObjectSizeAgent.sizeOf(new int[] {}));// 8 + 4 + 4 + padding = 16个字节
System.out.println(ObjectSizeAgent.sizeOf(new P()));// 8 + 4 + (4 + 4 + 4 + 1 + 1 + 4 + 1) + padding = 32
}
private static class P {
//8 _markword
//4 _oop指针
int id; //4
String name; //4
int age; //4
byte b1; //1
byte b2; //1
Object o; //4
byte b3; //1
}
}
markword结构
下面是32位的结构的例子, 64位markword的例子参考下Hotspot源码。
对象的hashcode是调用未覆写的hashCode()方法或者System.identityHashCode()方法时才会生成的,如果对象是无锁态,生成的hashCode会放在markword中,如果是轻量级锁,重量级锁状态则放在对象的monitor中,如果是偏向锁状态,markword没有地方存hashCode所以锁必须升级,升级成轻量级锁状态。


javaagent
Instrumentation 接口(插桩)

插桩一般指的是获取计算机软件或者硬件状态的数据的技术。
这个类提供了插桩java代码的方法,Instrumentation的目的是为了帮助一些工具能够收集数据,这些工具的例子: 监控代理, 分析工具, 代码覆盖率分析, event loggers。
有两种方式可以获取一个Instrumentation的实例:
- 当启动jvm时指定了agent class,则jvm会把Instrumentation的实例传给agent class的premain()方法的参数中。
- 当jvm提供了jvm启动之后再启动agent的机制时, Instrumentation的实例会传给agent的agentmain()方法中,猜测arthas就是使用这种方式在jvm启动以后绑定代理程序的。
这两种机制在jvm规范中有描述。
- void addTransformer(ClassFileTransformer transformer, boolean canRetransform);
添加一个transformer,同时指定这个transformer是否可以重复执行 - void addTransformer(ClassFileTransformer transformer);
添加一个transformer - boolean removeTransformer(ClassFileTransformer transformer);
移除一个transformer - boolean isRetransformClassesSupported();
返回当前jvm是否支持retransformClasses - void retransformClasses(Class… classes)
当class第一次load的时候或者被redefineClasses()方法redefine时,class file bytes会被ClassFileTransformer处理, 这个方法会重复执行ClassFileTransformer,这个方法简化了对已经加载了的class的插桩操作。执行步骤:
- 先获取初始的class file bytes
- 对于canRetransform为false的ClassFileTransformer,transform()方法返回的字节码会复用上次class load or redefine时该方法执行的结果, 相当于重新执行了上次的transformation,唯一的区别是transform()方法没有实际被调用。
- 对于canRetransform为true的ClassFileTransformer会被调用
- 被转换过的class重新加载到jvm中
注意点: - ClassFileTransformer执行的顺序参考ClassFileTransformer#transform()方法的描述。
- 初始的class file bytes是指传给ClassLoader.defineClass方法或者redefineClasses()方法的字节码。也就是说初始字节码是指没有经过任何ClassFileTransformer处理的字节码。
- 如果一个被retransformed的method还有活动的栈帧,那么这些栈帧还是会运行之前的字节码。被retransformed的method的字节码会在下次调用时生效。
- retransforme不会执行class的初始化,也就是说不会修改statistic的值
- retransformed class实例不会受影响
- retransformation可以修改方法体,常量池和属性,但是不能增加,移除或重命名字段或方法,不能修改方法的签名或者继承关系。
- boolean isRedefineClassesSupported()
当前jvm是否支持RedefineClasses - void redefineClasses(ClassDefinition… definitions)
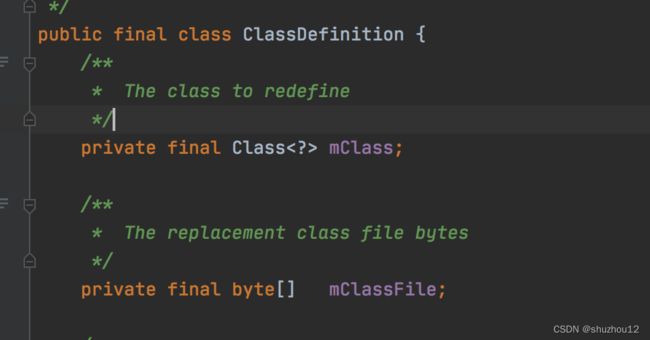
使用参数中的提供的字节码属性替换参数中对应的class。当获取不到已存在的字节码时,使用这个方法,如果要对已存在的字节码修改应该使用retransformClasses()方法。
- 如果一个被redefine的method还有活动的栈帧,那么这些栈帧还是会运行之前的字节码。被redefine的method的字节码会在下次调用时生效。
- redefine不会执行class的初始化,也就是说不会修改statistic的值
- redefine class实例不会受影响
- redefine可以修改方法体,常量池和属性,但是不能增加,移除或重命名字段或方法,不能修改方法的签名或者继承关系。
- boolean isModifiableClass(Class theClass)
返回一个类是否被retransformClasses或者redefine了。 - Class[] getAllLoadedClasses()
- Class[] getInitiatedClasses(ClassLoader loader)
返回被指定classLoader加载的class - long getObjectSize(Object objectToSize)
返回对象的字节大小 - void appendToBootstrapClassLoaderSearch(JarFile jarfile)
把一个jarfile添加到BootstrapClassLoader的加载路径中。 - void appendToSystemClassLoaderSearch(JarFile jarfile)
ClassFileTransformer接口
一个agent会提供这个接口的实现,用于transform class。transformation发生在classLoader defined class之前。

- byte[] transform(ClassLoader loader,String className,Class classBeingRedefined,
ProtectionDomain protectionDomain,byte[] classfileBuffer);
transform class并返回一个新的字节码数组。 - 根据Instrumentation.addTransformer(ClassFileTransformer,boolean)方法的canRetransform参数为true还是false,transformers分为两类。
transformer的执行时机: - 一旦transformer通过这个方法注册了,每次新的class被definition之前或者class被redefinition之前transformer都会被调用。每次retransformation被执行时,canRetransform为true的transformer也会被调用。transformer会在这些动作执行的过程中被调用,在class file的loading之后,verified之前执行。
- 新的class被definition是由ClassLoader.defineClass触发的。
- class被redefinition是由Instrumentation.redefineClasses触发的。
- retransformation是由Instrumentation.retransformation()触发的
transformer的执行顺序
当有多个transformers时, transformations会把多个transformations按链式执行,前一个transformer返回的字节码会作为下一个transformer的参数。执行顺序:
- Retransformation incapable transformers 不能重复运行的transformer
- Retransformation incapable native transformers
- Retransformation capable transformers 可以重复运行的transformer
- Retransformation capable native transformers
- retransformations执行时,incapable transformers不会被调用,但是逻辑上还是在链上的,只是返回的是上次调用返回的结果。
- 在每组的顺序中,transformers按注册的顺序执行。
- Native transformers是由Java Virtual Machine Tool Interface的ClassFileLoadHook event提供的。
transform方法执行时classfileBuffer入参是从哪来的
有以下三种情况:
- new class definition
ClassLoader.defineClass()方法的参数 - class redefinition
Instrumentation.redefineClasses()方法的ClassDefinition类型参数的getDefinitionClassFile()方法的返回值。 - class retransformation
如果没有被redefined过,入参就是class第一次被load的时候的字节码
如果被redefined过,入参就是最后一次被redefined的字节码
实现方法注意点
如果实现方法不准备执行任何transformations,直接返回null即可,否则就要把classfileBuffer参数的字节码拷贝到新的字节码数组中,然后执行想要的修改,返回新的字节码数组,一定不能直接修改classfileBuffer数组
如果一个transformer抛出异常没有捕获,剩下的transformer仍然会继续执行,相当于transformer返回了null。为了避免不可预知的行为,transformer可以在内部捕获异常并返回null。
java agent规范
参考链接
Command-Line Interface
- 使用方式: -javaagent:jarpath[=options]
- command line可以指定多次-javaagent:jarpath[=options],从而启动多个java agent,多个javaagent可以指向同一个jarpath,options是agent的参数
- agent jar中的manifest中必须包含Premain-Class,这个属性的值是agent class的类名。
- agent class必须实现一个public static premain方法,和main方法类似,jvm启动之后,premain方法会按command line中声明的java agent顺序执行。
- premain有两种形式:
public static void premain(String agentArgs, Instrumentation inst);
public static void premain(String agentArgs);
如果jvm找不到第一种形式的方法,则会执行第二种形式的方法 - agent class将会被system class loader加载,也就是ClassLoader.getSystemClassLoader返回的类加载器,所以java agent的文件必须在system class loader加载的classpath中。
- command line中执行的options,会被传到premain方法的agentArgs参数中,具体怎么解析,由java agent自己实现。
- 如果java agent不能被解析,比如agent class不能被loaded,或者agent class没有premain方法,那么jvm启动会失败
Starting Agents After VM Startup(在jvm启动之后启动agent)
- java agent实现支持在jvm启动之后再启动
- agent jar的manifest必须指定Agent-Class属性,属性的值是agent class的名字
- agent class必须实现agentmain方法
- 系统类加载器( ClassLoader.getSystemClassLoader)必须支持添加agent jar到system class path中。agent jar会被追加到system class path。
- agent class被load到jvm中后,jvm会尝试调用agentmain方法。
- agentmain方法有下面两种形式:
public static void agentmain(String agentArgs, Instrumentation inst);
public static void agentmain(String agentArgs);
Manifest Attributes
- Premain-Class
- Agent-Class
- Boot-Class-Path,指定bootstrap class loader.查找的路径列表,可以是目录或者jar包,中间用空格分隔,当bootstrap class loader加载class失败时,会去这个属性配置的路径加载,查找顺序和声明顺序一致。如果path以’/'开头就是绝对路径,否则是相对路径,相对路径相对于agent jar包的绝对路径。如果java agent在jvm启动之后启动,则此属性中指定的非jar包的路径会被忽略。
- Can-Redefine-Classes,这个agent是否需要redefine classes的能力,默认是false
- Can-Retransform-Classes,这个agent是否需要 retransform classes的能力,默认是false
- Can-Set-Native-Method-Prefix,这个agent是否需要设置native method前缀的能力,默认是false。
jvm解释执行class二进制码的混合模式
-
解释器, bytecode intepreter
-
JIT, Just In-Time compiler, 热点代码编译
-
混合模式(-Xmixed): 混合使用解释器 + JIT, 起始节点采用解释执行,然后随着程序的执行进行热点代码检测,把热点代码编译成本地cpu直接可以执行的汇编指令。热点代码是指多次被调用的方法(方法计数器,检测方法执行频率), 多次被调用的循环(循环计数器: 检测循环执行的频率)。启动速度较快。
-
-Xint, 解释模式,启动很快,执行稍慢
-
-Xcomp, 使用纯编译模式,执行很快,启动很慢
jvm运行时内存
pc register(Program counter)
每个线程都有自己的pc register, 任何时刻一个线程都只会执行某一个方法,如果这个方法不是native的,则pc register包含了当前正在执行的jvm 指令。pc register足够大可以保存一个return address。比如这个方法体执行完时,pc register中保存的就是栈帧中的return address,如果此时cpu切换到另外一个线程上了,那么线程切换回来时,还可以从pc register中取出return address,继续执行下一个栈帧。
jvm stacks
- 每一个线程都有一个jvm stack, 这个jvm stack和线程一起创建。jvm stack中是一个一个的栈帧,每个栈帧包含本地变量表,操作数栈,return address。
- jvm stacks 的内存不是连续的。
- jvm规范允许jvm stacks的大小是固定的或者是可以动态扩展和收缩的,如果是固定的,那每一个jvm stack创建的时候栈的大小的选择是相互独立的。
- jvm实现可能会提供一个initial size of Java Virtual Machine stacks,如果jvm stacks是可以动态扩展和收缩的,还会提供一个maximum和minimum sizes。
- 如果一个线程执行方法时需要的jvm stack内存比允许的大,jvm会抛出StackOverflowError
- 如果jvm stacks可以动态扩展但是扩展的时候没有足够的内存了,或者没有足够的内存为一个新的线程创建一个initial jvm stack了,jvm会抛出OutOfMemoryError。
栈帧
- 栈帧的作用是存储方法运行过程中的数据和中间结果、执行动态链接、返回方法结果、分发异常。
- 每次调用一个方法时,一个新的栈帧就会被创建。当方法执行结束时,栈帧被销毁。
- 每个栈帧都拥有自己的本地变量表和操作数栈,以及栈帧对应方法的类的常量池的引用。
- 当一个方法被执行时,一个新的栈帧会被创建并且成为current frame。当这个方法return时,current frame会把方法的结果返回给前一个栈帧,然后前一个栈帧重新成为current frame。
本地变量表
- 本地变量表的长度是在编译时就确定了的,长度存放在对应method的code属性中。
- 本地变量表可以保存以下类型的值,boolean, byte, char, short, int,
float, reference, or returnAddress - 当方法执行时, jvm用本地变量表来传递参数。参数从本地变量表的0号位置开始存放,当调用的是实例方法时,0号位置存的是this,然后从1号位置开始存其它参数。
操作数栈
- 操作数栈是一个后进先出的栈。
- 操作数栈的最大深度在编译时就确定了,这个最大深度存在method的code属性中。栈中的可以存放任意类型的数据,long和double类型的数据贡献两个单位的深度,其它类型的数据贡献一个单位的深度。
- jvm提供了一些指令从本地变量表中或fields中取数据放到操作数栈中。其它的jvm指令从操作数栈中取出数据,然后执行操作,然后把结果push到栈顶。
- 操作数栈也用来准备调用其它方法的参数以及接收方法执行的结果。
- 举个例子, iadd指令的作用是把两个int类型的值相加。这个指令需要前一个指令把两个int类型的数值添加到栈顶, 然后iadd指令把栈顶的两个值pop出来,然后把两个值求和,然后把结果push到栈顶。后面的指令需要用到结果值的,再把栈顶的值pop出来即可。
dynamic linking
- 为了支持动态链接,每个栈帧都持有一个当前方法的类的运行时常量池的引用。
- 方法的code属性中有对调用其它方法和变量的符号引用。
- 动态链接会把方法的符号引用解析为具体的方法引用,解析方法的符号引用时需要loading对应方法的class。
- 动态链接会把变量的符号引用解析成变量运行时内存结构中的offsets。
heap
- heap是线程共享的,heap是存放所有实例对象和数组对象的运行时数据区。heap是在jvm启动的时候创建的。存储对象的空间会被垃圾回收器回收,对象不会显示的被释放。
- 堆内存的内存不是连续的
- heap可以是固定大小的,也可以是可以动态扩展和收缩的。jvm实现可能会提供一个initial size参数,如果heap可以动态扩展和收缩,jvm还会提供maximum and minimum heap size。
- 如果程序运行需要更多的堆内存,而垃圾回收器不能回收足够的空间时,jvm会抛出OutOfMemoryError。
method area
- 方法区是线程共享的,方法区存储每一个class中的结构,如运行时常量池, 字段和方法数据,方法和构造方法的code属性。
- 方法区是在jvm启动时创建的。虽然方法区逻辑上是heap的一部分,但是简单的jvm实现可以选择不回收这部分区域。
- jvm规范不规定方法区内存的位置和管理编译代码的策略。
- 方法区可以是固定大小的也可以是可以动态扩展和收缩的,jvm实现可能会提供initial size参数,如果是大小是可变的,还会提供 maximum and minimum 参数。方法区内存不需要连续。
- 如果方法区的内存够了,jvm会抛出OutOfMemoryError。
- hotspot jvm实现,jdk 1.8之前,方法区叫perm space,FGC不会清理这部分区域,大小启动时指定不能变。
- hotspot jvm实现,jdk1.8及以后, 方法区叫meta space, FGC会触发这部分区域的回收, 如果不设定,最大是物理内存。
运行时常量池
- 运行时常量池代表了class文件中的constant_pool,保存的是class中的constant_pool中的东西。
- 每一个运行时常量池的内存都分配在方法区中。运行时常量池是在class或interface被创建时创建的。
- 当创建一个class或interface时,如果构建运行时常量池需要的内存比方法区可用的内存大,jvm会抛出OutOfMemoryError。
native method stacks
jvm常见的字节码指令
i++

- ipush
- 把一个byte类型的数值扩展为int类型,然后push到操作数栈顶
- istore
把操作数栈顶的int类型的值,存到本地变量表1号位置,0号位置存的是方法参数args - iinc index constant
对本地变量表index号位置的int类型的值加上constant的值 - iload_index
把本地变量表index位置的值load到操作数栈 - istore_n
把栈顶的结果存到本地变量表的n号位置 - getstatic indexbyte1 indexbyte2
从class中获取static字段,indexbyte1和indexbyte2用来构建指向运行时常量池的index, 这个index对应的常量池的元素必须是一个Fieldref_info类型的符号引用,这个Fieldref_info类型的常量池元素包含了class info和NameAndType_info。然后jvm开始解析这个符号引用为直接引用,解析完成后,会执行field对应class的初始化阶段,然后这个字段的值会被push到栈顶。 - invokevirtual indexbyte1 indexbyte2
执行实例的方法。indexbyte1和indexbyte2用来构建指向运行时常量池的index, 这个index对应的常量池的元素必须是一个Method_info类型的符号引用,这个Method_info类型的常量池元素包含了class info和NameAndType_info。
这条指令会先根据class选择出具体执行哪个方法,这个过程参考类加载过程的解析章节的选择方法。
开始执行这个指令之前,操作数栈中第0个元素必须是要执行方法的实例对象,后面的元素是方法的参数,参数的顺序、个数、类型必须和method_info中描述的一致。如果被执行的方法是synchronized的,那么和this对象关联的moniter被进入,并且如果同一个线程再次执行monitorenter指令,moniter可以重复进入。
开始执行方法,把实例对象和方法的参数从操作数栈中被pop出来,然后新建一个栈帧,并且把实例对象和参数放到新的栈帧的本地变量表中,实例对象放到0号位置,参数从1号位置开始依次存放。新创建的栈帧成为current frame并且pc指向要执行的方法的code的第一条字节码指令,然后开始执行字节码指令。
递归调用

- new indexbyte1 indexbyte2
创建实例。indexbyte1和indexbyte2用来构建指向运行时常量池的index, 这个index对应的常量池的元素必须是一个class或interface的符号引用。然后解析这个符号引用,使用当前类的类加载器加载class,然后在堆中为实例对象分配内存,并且实例的变量赋默认的初始值。然后把实例的引用push到栈顶。 - dup
复制栈顶的元素并且也push到栈顶 - invokespecial indexbyte1 indexbyte2
执行实例方法, 执行方法或者current class或current class的父类的实例方法。
indexbyte1 indexbyte2组合指向的运行时常量池的元素必须是method_info。
解析method的过程如下,先确定从哪个class开始解析方法,假设这个class是C。
如果以下三个条件都为true,
- method不是方法
- method_info指向的class是current class的父类
- current class 的class file的ACC_SUPER为true
则C为current class的父类
否则C为method_info指向的class。确定C后就可以解析具体要执行的method了, 解析过程如下:
- 如果C中包含和method_info符号引用的方法描述一样的方法,则执行执行这个方法。
- 否则如果C有父类,则从C的父类开始一直向上查找,知道找到和method_info符号引用的方法描述一样的方法,如果找到了,则执行那个方法。
- 否则如果C是一个接口,并且Object中有符合条件的方法,则执行Object中的那个方法
- 否则如果C的父接口中,有符合条件的方法,并且不是abstract的,则执行那个方法。
确定执行哪个方法后,然后创建栈帧,弹出栈顶的objectRef引用和参数,执行方法。
invokespecial和invokevirtual的区别是:
invokevirtual解析方法是基于栈帧中的objectRef的class,而invokespecials是解析方法是基于method_info中指定的class的方法或者栈帧的current class或current class的父类中的实例方法。 - astore_
把栈顶的元素弹出,存放到本地变量表的n号位置,栈顶元素必须是returnAddress或reference类型。 - iconst_
把一个int类型的常量push到栈顶 - return
Return void from method, 当前方法的返回值类型必须是Void。如果当前方法是一个synchronized方法,则objectref上的monitor会被更新,就好像执行了monitorexit指令一样。然后执行的控制权交给调用这个栈帧的栈帧。

- if_acmp branchbyte1 branchbyte2
这条指令有两种形式if_acmpeq(如果等于)和if_acmpne(如果不等于)
把栈顶的两个操作数pop出来,这两个操作数必须是reference类型的。
如果指令比较的结果为succeeds,则使用branchbyte1和branchbyte2组合计算得到要执行的指令的行号,然后跳到对应的行号执行指令。否则顺序执行下一条指令。 - ireturn
如果当前方法是synchronized方法,则先释放锁。把当前栈帧的操作数栈顶的元素pop出来,然后把这个数push到上一个栈帧的操作数栈顶,在这之前还要做一个类型转换,如果上一个栈帧的方法的返回值类型是byte, char, or short那么要先把int类型转换为这些类型,和分别执行i2b, i2c, or i2s指令是一个效果。如果返回值类型是boolean,那么会把int类型缩小成boolean类型,把值和1做AND操作。然后把控制权交给上一个栈帧。
垃圾收集器
垃圾标记算法
- 引用计数法,自己持有一个引用计数,有一个引用指向自己,就加1。无法解决循环引用问题。
- 根可达算法(RootSearching),从GCRoots开始遍历可达对象。不能遍历到的对象就是垃圾。
GCRoots
- 线程栈变量(局部变量)
- 静态变量
- 常量池
- JIN指针
常见的垃圾回收算法
- 标记清除(mark sweep) - 位置不连续 产生碎片 效率偏低(两遍扫描),存活对象多的时候效率会高一点,因为需要清除的对象少。
- 拷贝算法 (copying) - 没有碎片,浪费空间,适合存活对象少的区域。
- 标记压缩(mark compact) - 没有碎片,效率偏低(两遍扫描,指针需要调整)
JVM内存分代模型(用于分代垃圾回收算法)
-
新生代使用标记-复制算法,老年代使用标记-清除/标记压缩算法。
部分垃圾回收器使用的模型 -
除Epsilon ZGC Shenandoah之外的GC都是使用逻辑分代模型。G1是逻辑分代,物理不分代。除此之外不仅逻辑分代,而且物理分代。
-
新生代 + 老年代 + 永久代(1.7)Perm Generation/ 元数据区(1.8) Metaspace
- 永久代 元数据 - Class
- 永久代必须指定大小限制 ,元数据可以设置,也可以不设置,无上限(受限于物理内存)
- 字符串常量 1.7 - 永久代,1.8 - 堆
- MethodArea逻辑概念 - 永久代、元数据
- 新生代 = Eden + 2个suvivor区
- YGC回收之后,大多数的对象会被回收,活着的进入s0
- 再次YGC,活着的对象eden + s0 -> s1
- 再次YGC,eden + s1 -> s0
- 年龄足够 -> 老年代 (15 CMS 6)
- s区装不下 -> 老年代
- 老年代
- 顽固分子
- 老年代满了FGC Full GC
- GC Tuning (Generation)
- 尽量减少FGC
- MinorGC = YGC
- MajorGC = FGC
-
动态年龄:(不重要) https://www.jianshu.com/p/989d3b06a49d
-
分配担保:(不重要) YGC期间 survivor区空间不够了 空间担保直接进入老年代 参考:https://cloud.tencent.com/developer/article/1082730
分代收集实现
文档连接


- 大多数应用内存的使用状态都是大部分对象存活时间都很短,小部分对象存活时间长,基于这种经验,除了ZGC外,其它的垃圾回收器都采用分代回收策略。
- 绝大多数对象都分配在年轻代,并且大多数对象都死在那里。当年轻代填满时,会发生Minor GC,Minor GC的成本与年轻代存活的对象数量成正比,如果存活对象很少那么收集的会很快。通常,年轻代的幸存者会在minor GC期间被移到老年代。最终,老年代被填满,就会发生Major GC,Major GC会收集整个堆。Major GC的时间通常比minor GC持续时间长得多,因为涉及的对象数量要多得多。
- 年轻代由一个eden和两个survivor空间组成。大多数对象最初是在eden中分配的。任何时候总会有一个survivor是空的,并且在YGC期间充当eden中存活对象和另一个survivor的目的地;YGC后,eden和源survivor为空。在下一次YGC中,两个survivor的用途被交换。以这种方式在survivor空间之间复制对象,直到它们被复制了一定次数,或者survivor中没有足够的空间。这些对象将被直接复制到老年代中。
常见的垃圾回收器
- JDK诞生 Serial追随 提高效率,诞生了PS,为了配合CMS,诞生了PN,CMS是1.4版本后期引入,CMS是里程碑式的GC,它开启了并发回收的过程,但是CMS毛病较多,因此目前任何一个JDK版本默认是CMS,并发垃圾回收是因为无法忍受STW
- Serial 年轻代,单线程串行回收
- PS 年轻代 并行回收
- ParNew 年轻代 配合CMS的并行回收
- SerialOld
- ParallelOld
- ConcurrentMarkSweep 老年代 并发的, 垃圾回收和应用程序同时运行,降低STW的时间(200ms)
CMS问题比较多,所以现在没有一个版本默认是CMS,只能手工指定,CMS既然是MarkSweep,就一定会有碎片化的问题,碎片到达一定程度,CMS的老年代分配对象分配不下的时候,使用SerialOld 进行老年代回收
想象一下:
PS + PO -> 加内存 换垃圾回收器 -> PN + CMS + SerialOld(几个小时 - 几天的STW)
几十个G的内存,单线程回收 -> G1 + FGC 几十个G -> 上T内存的服务器 ZGC
算法:三色标记 + Incremental Update - G1(10ms)
算法:三色标记 + SATB - ZGC (1ms) PK C++
算法:ColoredPointers + LoadBarrier - Shenandoah
算法:ColoredPointers + WriteBarrier - Eplison
- PS 和 PN区别的延伸阅读:
▪https://docs.oracle.com/en/java/javase/13/gctuning/ergonomics.html#GUID-3D0BB91E-9BFF-4EBB-B523-14493A860E73 - 垃圾收集器跟内存大小的关系
- Serial 几十兆
- PS 上百兆 - 几个G
- CMS - 20G
- G1 - 上百G
- ZGC - 4T - 16T(JDK13)
G1的吞吐量小于CMS,但是G1的响应时间比CMS快。
1.8默认的垃圾回收:PS + ParallelOld
常见垃圾回收器组合参数设定:(1.8)
- -XX:+UseSerialGC = Serial New (DefNew) + Serial Old
- 小型程序。默认情况下不会是这种选项,HotSpot会根据计算及配置和JDK版本自动选择收集器
- -XX:+UseParNewGC = ParNew + SerialOld
- 这个组合已经很少用(在某些版本中已经废弃)
- https://stackoverflow.com/questions/34962257/why-remove-support-for-parnewserialold-anddefnewcms-in-the-future
- -XX:+UseConc(urrent)MarkSweepGC = ParNew + CMS + Serial Old
- -XX:+UseParallelGC = Parallel Scavenge + Parallel Old (1.8默认) 【PS + SerialOld】
- -XX:+UseParallelOldGC = Parallel Scavenge + Parallel Old
- -XX:+UseG1GC = G1
- Linux中没找到默认GC的查看方法,而windows中会打印UseParallelGC
- java +XX:+PrintCommandLineFlags -version
- 通过GC的日志来分辨
java命令支持的参数
java命令
- Standard Options
- 所有jvm都支持的参数
- -Dproperty=value, 设置系统属性,如果value中带有空格,需要用双引号包起来。
- -verbose:gc, 显示每一个GC event的信息
- -javaagent:jarpath[=options], 加载指定路径的java agent。java agent
- -jar filename, 执行JAR,JAR里面必须要有一个MANIFEST.MF文件,该文件中有一行Main-Class:classname,指定了带有main方法的启动类,当使用-jar执行时,用户需要的所有class都在jar里面,其它的classpath设置会被忽略。参考资料:
jar
The Java Archive (JAR) Files guide
Lesson: Packaging Programs in JAR Files
- Non-Standard Options
- 针对hotspot jvm的一般参数, -X开头
- -Xloggc:filename, 设置verbose GC events信息存放的日志文件的名称,如果这个命令和-verbose:gc同时指定了,这个命令优先。例子:-Xloggc:garbage-collection.log
- -Xmnsize, 同时设置新生代的初始值和最大值。oracle建议新生代的大小在整个堆大小的四分之一到二分之一之间。除了同时用-Xmn命令设置新生代的初始值和最大值,还可以用-XX:NewSize设置初始值,用-XX:MaxNewSize设置最大值。例子:
-Xmn256m
-Xmn262144k
-Xmn268435456 - -Xmssize,同时设置jvm堆的最小值和初始值,如果不设置,则堆的初始值为新生代和老年代之和。-XX:InitalHeapSize也可以设置堆的初始值,如果-XX:InitalHeapSize出现在-Xmssize之后,则以-XX:InitalHeapSize为准。例子:
-Xms6291456
-Xms6144k
-Xms6m - -Xmxsize,设置jvm堆的最大值,如果不设置,默认值在运行时根据机器配置自动确定,-Xms和 -Xmx 一般配置成相同的值,参考垃圾回收调优
此配置和-XX:MaxHeapSize作用相同。例子:
-Xmx83886080
-Xmx81920k
-Xmx80m - -Xsssize,设置线程栈的大小,该配置和-XX:ThreadStackSize作用相同。默认值根据不同的平台确定:
Linux/ARM (32-bit): 320 KB
Linux/i386 (32-bit): 320 KB
Linux/x64 (64-bit): 1024 KB
OS X (64-bit): 1024 KB
Oracle Solaris/i386 (32-bit): 320 KB
Oracle Solaris/x64 (64-bit): 1024 KB - -Xverify:mode,设置class文件二进制码的校验模式,mode支持以下三个选项:
remote: Verifies all bytecodes not loaded by the bootstrap class loader. This is the default behavior if you do not specify the -Xverify option.
all: Enables verification of all bytecodes.
none:Disables verification of all bytecodes. Use of -Xverify:none is unsupported.
- Advanced options
- 调整hotspot特定区域的高级参数, -XX参数
- Advanced Runtime Options
- XX:+DisableAttachMechanism, 禁止一些工具attach JVM,默认这个配置是不开启的,所以我们可以使用 jcmd, jstack, jmap, jinfo
- -XX:ErrorFile=filename,当jvm发生不可恢复的错误的错误信息存储文件的位置和名称,默认情况下错误文件会存储在当前工作目录下,文件名称为hs_err_pidpid.log 。如果指定的目录当前用户没有权限创建文件,文件会被创建在/tmp目录下。例子:
-XX:ErrorFile=./hs_err_pid%p.log - -XX:OnError=string,配置jvm遇到不可恢复的错误时执行配置的命令。例子:
-XX:OnError=“gcore %p;dbx - %p”, p%表示当前进程 - -XX:+PrintCommandLineFlags, 打印出jvm自动配置的参数,如堆空间大小,选择的垃圾回收器等。
- -XX:ThreadStackSize=size, 设置线程栈的大小,和-Xss命令作用相同
- Advanced JIT Compiler Options
- Advanced Serviceability Options
- -XX:+HeapDumpOnOutOfMemoryError,当jvm抛出java.lang.OutOfMemoryError异常时,dump堆存储文件到当前目录,可以使用-XX:HeapDumpPath命令,配置dump文件存储位置和文件名。
- -XX:HeapDumpPath=path, 例子:
-XX:HeapDumpPath=/var/log/java/java_heapdump.hprof - -XX:LogFile=path, 设置日志文件存储位置和文件名称,默认存在当前目录下,默认文件名是hotspot.log。例子:-XX:LogFile=/var/log/java/hotspot.log
- Advanced Garbage Collection Options
- -XX:+DisableExplicitGC,不允许显式调用 System.gc()
- -XX:G1HeapRegionSize=size,当使用G1垃圾回收器时,每个region的大小,可配置的值在1 MB and 32 MB之间,默认值根据堆大小确定。
- -XX:+G1PrintHeapRegions,打印哪个region被分配了,哪个region被G1 垃圾回收期回收了。
- -XX:G1ReservePercent=percent,设置保留堆空间大小的百分比,用于减少G1垃圾回收器promotion failure 的可能性,这个百分比在1-50之间,默认是10
- -XX:InitialHeapSize=size,设置初始堆大小,如果设置为0,则堆初始大小的值为年轻代和老年代之和,-Xms会同时设置堆的初始值和最小值,如果-Xms出现在该配置之后,则以-Xms配置为准。
- -XX:MaxGCPauseMillis=time,设置最大GC停顿时间,jvm垃圾回收器会努力实现这个目标,例子:-XX:MaxGCPauseMillis=500,单位ms
- -XX:MaxHeapSize=size, 设置最大堆空间,XX:InitialHeapSize and -XX:MaxHeapSize一般要保持一致,这个配置的作用和 -Xmx一样。
- -XX:MaxHeapFreeRatio=percent,在GC之后,如果堆空闲空间的百分比超过配置的比例,则会收缩堆。默认值是70
- -XX:MaxMetaspaceSize=size,设置最大的元空间大小,默认不限制大小。
- -XX:MaxNewSize=size, 设置新生代最大大小,默认不限制。
- -XX:MaxTenuringThreshold=threshold,设置晋升老年代的年龄大小,最大值是15,对于parallel(吞吐量)收集器来说,默认值是15,对CMS来说默认值是6.
- -XX:MetaspaceSize=size,元空间占用空间第一次达到配置的阈值时,会触发GC。默认值根据系统配置确定。这个阈值会随着元数据实际使用空间的大小增大或减小。
- -XX:MinHeapFreeRatio=percent,GC event之后允许的最小空闲空间比例,小于这个比例,jvm会扩展堆空间,默认值是40%。
- -XX:NewRatio=ratio,年轻代和老年代的比值,默认值是2。
- -XX:NewSize=size,年轻代的初始大小,该配置和-Xmn作用相同。
- -XX:ParallelGCThreads=threads,parallel垃圾收集的线程数量,默认值取决于jvm可用的cpu核数。
- -XX:+PrintAdaptiveSizePolicy,打印分代大小调整信息
- -XX:+PrintGC,打印每次GC的信息
- -XX:+PrintGCDetails,打印每次GC的详细信息
- -XX:+PrintGCTimeStamps,打印每次GC的时间戳
- -XX:+PrintTenuringDistribution,打印对象存活年龄信息,打印结果例子:
Desired survivor size 48286924 bytes, new threshold 10 (max 10)
age 1: 28992024 bytes, 28992024 total
age 2: 1366864 bytes, 30358888 total
age 3: 1425912 bytes, 31784800 total
…
年龄为1的对象是最年轻的幸存者:它们在最近一次的GC中存活了下来,并且从eden区转移到了survivor区。年龄为2的幸存者:经历了两次GC依然存活着,在第二次GC中,它们从一个survivor区被转移到另一个survivor区。以此类推。 - -XX:+ScavengeBeforeFullGC,每次Full GC前,执行YGC.
- -XX:SurvivorRatio=ratio, eden和survivor的比值,默认值是8
- -XX:TargetSurvivorRatio=percent,每次YGC后,期望的survivor区域占用的百分比,默认值是50.
- -XX:+UseConcMarkSweepGC,CMS作为老年代的垃圾收集器,当这个配置开启时,-XX:+UseParNewGC会被自动设置。
- -XX:+UseParNewGC,使用G1垃圾回收器,推荐内存大于6G的应用使用。
- -XX:+UseParallelGC,使用parallel scavenge垃圾回收器,这个垃圾回收器也被称为吞吐量回收器,当这个配置启用时,-XX:+UseParallelOldGC也会自动启用。
- -XX:+UseParallelOldGC
- -XX:+UseParNewGC
- -XX:+UseSerialGC,使用单线程垃圾回收器,小应用使用
-
Linux下1.8版本默认的垃圾回收器到底是什么?
- 1.8.0_181 默认(看不出来)Copy MarkCompact
- 1.8.0_222 默认 PS + PO
JVM调优
年轻代和老年代大小的选择
- jvm性能主要考虑两方面,吞吐量和延迟。吞吐量是指工作线程运行时间占jvm运行总时间的比例。垃圾回收时会有STW发生,这个停顿时间就是延迟。
- 一般来说,为不同代选择不同的大小是在满足上面两个指标的一种权衡。例如,一个非常庞大的年轻代可能会最大化吞吐量,但这样做是以占用空间、快速性和暂停时间为代价的。年轻代的停顿可以通过以牺牲吞吐量为代价使用小的年轻代来减少。一代的大小不会影响另一代的采集频率和暂停时间。
- 影响垃圾回收性能最重要的两个因素就是总堆内存大小和年轻代的大小。
- 以下关于堆的增长和收缩、堆布局和默认值的讨论以串行收集器为例。虽然其他收集器使用类似的机制,但下面描述的详细信息可能不适用于其他收集器。有关其他收集器的信息,请参阅相应的章节。
总的堆内存大小
参考文档
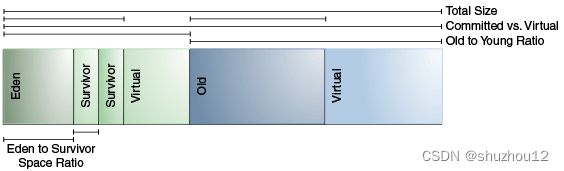
- commited vs virtual,在虚拟机初始化时,将保留堆的整个空间。可以使用-Xmx选项指定保留空间的大小。如果-Xms参数的值小于-Xmx参数的值,则不是所有保留的空间都会立即提交给虚拟机。未提交的空间在此图中标记为“virtual”。堆的不同部分,即老年代和年轻代,可以根据需要增长到virtual空间的极限。
- XX:NewRatio, 指定了年轻代和老年代的比值,默认是2。
- 增长和收缩,默认情况下,虚拟机会在每次GC时增加或缩小堆,以尽量将每次GC时存活对象的可用空间比例保持在特定范围内,因为每次GC时,存活对象的多少决定了垃圾收集的时间,存活对象不能太多。此目标范围由-XX:MinHeapFreeRatio=(默认40)和-XX:MaxHeapFree Ratio=(默认70)设置为百分比,总大小的下限为–Xms,上限为–Xmx。如果年轻代或老年代中的可用空间百分比低于40%,则该代将扩展以保持40%的可用空间,直到达到该代允许的最大大小。类似地,如果年轻代或老年代的可用空间超过70%,则该代会收缩,直到只有70%的空间是空闲的,这取决于该代的最小值。默认情况下,jvm是逐渐的将Java堆减少到目标大小,此过程需要多个垃圾收集周期。
- Parallel collector计算默认堆大小的方法适用于其它的垃圾收集器,下面描述的是Parallel collector的计算方法,除非在命令行中指定了初始堆大小和最大堆大小,否则它们将根据计算机上的物理内存量进行计算。默认的最大堆大小为物理内存的四分之一,而初始堆大小是物理内存的1/64。分配给年轻一代的最大空间量是总堆大小的三分之一。
年轻代内存大小
- 年轻代的空间越大,minor GC的次数就越少。然而,对于有限的堆大小,较大的年轻代意味着较小的老年代,这将增加Major GC的频率。最佳选择取决于应用程序分配的对象的生命周期分布。
- 默认情况下,新生代的大小是由-XX:NewRatio参数配置的,例如,设置-XX:NewRatio=3意味着年轻代和老年代之间的比率为1:3。换句话说,eden区和survivor区的空间的总大小是总堆大小的四分之一。该值的默认值是2。
- 除了使用-XX:NewRatio控制新生代大小,还可以使用-XX:NewSize 和 -XX:MaxNewSize参数控制新生代的最小值和最大值,如果两个参数配置相同的值,则新生代的大小就固定是这个数。这两个参数比-XX:NewRatio控制的更细粒度。
- survivor大小控制,您可以使用选项-XX:SurvivorRatio来调整survivor空间的大小,但这通常对性能不重要。例如,-XX:SurvivorRatio=6将eden区和survivor区空间的比例设置为1:6。换句话说,每个幸存者空间将是伊甸园大小的六分之一,因此是年轻一代的八分之一(不是七分之一,因为有两个幸存者空间)。
- 如果幸存者空间太小,则GC时从一个survivor区复制到另一个survivor区时,存活对象集合大于survivor区的大小,则这部分对象会直接溢出到老年代中。如果幸存者的空间太大,那么survivor中空闲的空间不会被使用,浪费空间。在每次垃圾收集时,虚拟机都会选择一个对象进入老年代的年龄阈值,这是一个对象在进入老年代之前可以复制的次数。此阈值是为了让幸存者保持一半空闲空间。您可以使用日志配置-Xlog:gc,age可以用于显示此阈值和年轻代中对象的年龄分布。它对于观察应用程序的对象生存周期分布也很有用。

- 年轻一代的MaxNewSize是根据总堆的最大值和-XX:NewRatio参数的值计算的。-XX:MaxNewSize参数的“not limited”默认值表示除非在命令行上指定了-XX:MaxNewSize的值,否则年轻代最大大小不受MaxNewSize限制。
确定jvm内存的步骤
- 首先确定您可以为虚拟机提供的最大堆大小。然后,根据性能指标确定年轻代的大小。请注意,最大堆大小应始终小于机器的内存,以避免出现过多的page faults and thrashing。
- 如果堆内存大小是固定的,那么随着年轻代大小的增加需要减少老年代的大小。但是需要保持老年代足够大,以容纳应用程序在任何时候使用的所有实时数据,老年代需要加上一定的额外空间(10%到20%或更多)。
- 当增加处理器数量时,也要增加年轻代的大小,因为allocation(分配内存)可以并行化。
jvm自动调整GC策略
- 在jdk19中,在class-server服务器上默认使用G1,否则使用serial垃圾回收。当jvm检测到超过两核的cpu时或者堆内存大于1792M时,就认为是class-server。
- GC线程的最大数量受堆大小和可用CPU资源限制
- 初始堆大小为物理内存的1/64,最大堆大小为物理内存的1/4
- Java HotSpot VM垃圾收集器可以配置为优先满足两个目标之一:最大暂停时间和应用程序吞吐量。如果满足了设定的目标,收集器将尝试满足另外一个目标。当然,这些目标并不总是能够实现的:应用程序需要一个最小的堆来保存至少所有的存活对象,而其他配置可能会妨碍实现最大暂停时间或吞吐量目标,因为这些目标的实现和堆大小直接相关。
- 如果已达到吞吐量和最大暂停时间目标,那么垃圾收集器将减小堆的大小,直到其中一个目标(总是吞吐量目标)无法实现。垃圾收集器可以使用的最小和最大堆大小可以分别使用-Xms=和-Xmx=设置。
最大停顿时间目标
- 垃圾收集器会维护STW的平均时间和该平均值的方差。平均时间是从第一个GC开始算起的,但它是加权的,最近的STW权重更大。如果暂停时间的平均值加上方差大于最大暂停时间目标,则垃圾收集器认为没有达到目标。
- 最大暂停时间目标由-XX:MaxGCPauseMillis=指定。垃圾收集器会调整Java堆大小和其他与垃圾收集相关的参数,以使垃圾收集暂停时间小于毫秒。最大暂停时间目标的默认值因收集器而异。这些调整可能会导致垃圾收集发生得更频繁,并且降低应用程序的总吞吐量。然而,在某些情况下,仍然无法达到期望的暂停时间目标。
吞吐量目标
- 吞吐量是指收集垃圾所花费的时间和应用程序运行的时间的比值。
- 吞吐量目标由命令行选项-XX:GCTimeRatio=nnn指定。垃圾收集时间与应用程序时间之比为1/(1+nnn)。例如,-XX:GCTimeRatio=19设置了垃圾收集时间占总时间的1/20或5%的目标。
- 如果没有达到吞吐量目标,那么垃圾收集器的一个可能操作是增加堆的大小,这样应用程序垃圾收集的频率就会降低,应用程序运行的时间就会变长,但是会导致停顿时间增加。
调整策略
- 堆会增长或收缩以支持所选的吞吐量目标。了解堆优化策略,如选择最大堆大小,选择最大暂停时间目标。
- 不要明确为堆设置最大值,除非您确定需要需要的堆大小大于默认最大堆大小。选择一个足以满足您的应用程序的吞吐量目标。
- 应用程序行为的改变可能导致堆增长或收缩。例如,如果应用程序开始以更高的速率分配内存,那么堆会增长以保持吞吐量。
- 如果堆已经增长最大大小,但是仍然没有达到吞吐量目标,那么说明设置的最大堆大小对于吞吐量目标来说太小了。将最大堆大小设置为接近总物理内存的值,但不会导致应用程序的交换。再次去顶应用程序。如果吞吐量目标仍然没有达到,那么说明应用程序设定的吞吐量目标对于平台上的可用内存来说太高了。
- 如果可以达到吞吐量目标,但暂停时间过长,则设置一个能接受的最大暂停时间目标。但是这可能意味着无法达到吞吐量目标,因此请选择对应用程序可接受的折衷值。
- 当垃圾收集器试图满足竞争目标时,堆的大小通常会发生调整。即使应用程序已达到稳定状态,也是如此。实现吞吐量目标(可能需要更大的堆)的压力与最大暂停时间和最小占用空间的目标(两者都可能需要较小的堆)相竞争。
第一步,了解JVM常用命令行参数
-
JVM的命令行参数参考:https://docs.oracle.com/javase/8/docs/technotes/tools/unix/java.html
-
HotSpot参数分类
标准: - 开头,所有的HotSpot都支持
非标准:-X 开头,特定版本HotSpot支持特定命令
不稳定:-XX 开头,下个版本可能取消
java -version
java -X
试验用程序:
import java.util.List; import java.util.LinkedList; public class HelloGC { public static void main(String[] args) { System.out.println("HelloGC!"); List list = new LinkedList(); for(;;) { byte[] b = new byte[1024*1024]; list.add(b); } } }- 区分概念:内存泄漏memory leak,内存溢出out of memory
- java -XX:+PrintCommandLineFlags HelloGC
- java -Xmn10M -Xms40M -Xmx60M -XX:+PrintCommandLineFlags -XX:+PrintGC HelloGC
PrintGCDetails PrintGCTimeStamps PrintGCCauses - java -XX:+UseConcMarkSweepGC -XX:+PrintCommandLineFlags HelloGC
- java -XX:+PrintFlagsInitial 默认参数值
- java -XX:+PrintFlagsFinal 最终参数值
- java -XX:+PrintFlagsFinal | grep xxx 找到对应的参数
- java -XX:+PrintFlagsFinal -version |grep GC
调优前的基础概念:
- 吞吐量:用户代码时间 /(用户代码执行时间 + 垃圾回收时间)
- 响应时间:STW越短,响应时间越好
所谓调优,首先确定,追求啥?吞吐量优先,还是响应时间优先?还是在满足一定的响应时间的情况下,要求达到多大的吞吐量…
问题:
科学计算,吞吐量。数据挖掘,thrput。吞吐量优先的一般:(PS + PO)
响应时间:网站 GUI API (1.8 G1)
调优,从规划开始
-
调优,从业务场景开始,没有业务场景的调优都是耍流氓
-
无监控(压力测试,能看到结果),不调优
-
步骤:
- 熟悉业务场景(没有最好的垃圾回收器,只有最合适的垃圾回收器)
- 响应时间、停顿时间 [CMS G1 ZGC] (需要给用户作响应)
- 吞吐量 = 用户时间 /( 用户时间 + GC时间) [PS]
- 选择回收器组合
- 计算内存需求(经验值 1.5G 16G)
- 选定CPU(越高越好)
- 设定年代大小、升级年龄
- 设定日志参数
- -Xloggc:/opt/xxx/logs/xxx-xxx-gc-%t.log -XX:+UseGCLogFileRotation -XX:NumberOfGCLogFiles=5 -XX:GCLogFileSize=20M -XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:+PrintGCCause
- 或者每天产生一个日志文件
- 观察日志情况
- 熟悉业务场景(没有最好的垃圾回收器,只有最合适的垃圾回收器)
一个案例理解常用工具
-
测试代码:
package com.mashibing.jvm.gc; import java.math.BigDecimal; import java.util.ArrayList; import java.util.Date; import java.util.List; import java.util.concurrent.ScheduledThreadPoolExecutor; import java.util.concurrent.ThreadPoolExecutor; import java.util.concurrent.TimeUnit; /** * 从数据库中读取信用数据,套用模型,并把结果进行记录和传输 */ public class T15_FullGC_Problem01 { private static class CardInfo { BigDecimal price = new BigDecimal(0.0); String name = "张三"; int age = 5; Date birthdate = new Date(); public void m() {} } private static ScheduledThreadPoolExecutor executor = new ScheduledThreadPoolExecutor(50, new ThreadPoolExecutor.DiscardOldestPolicy()); public static void main(String[] args) throws Exception { executor.setMaximumPoolSize(50); for (;;){ modelFit(); Thread.sleep(100); } } private static void modelFit(){ List<CardInfo> taskList = getAllCardInfo(); taskList.forEach(info -> { // do something executor.scheduleWithFixedDelay(() -> { //do sth with info info.m(); }, 2, 3, TimeUnit.SECONDS); }); } private static List<CardInfo> getAllCardInfo(){ List<CardInfo> taskList = new ArrayList<>(); for (int i = 0; i < 100; i++) { CardInfo ci = new CardInfo(); taskList.add(ci); } return taskList; } } -
java -Xms200M -Xmx200M -XX:+PrintGC com.mashibing.jvm.gc.T15_FullGC_Problem01
-
一般是运维团队首先受到报警信息(CPU Memory)
-
top命令观察到问题:内存不断增长 CPU占用率居高不下
-
top -Hp 观察进程中的线程,哪个线程CPU和内存占比高
-
jps定位具体java进程
jstack 定位线程状况,重点关注:WAITING BLOCKED
eg.
waiting on <0x0000000088ca3310> (a java.lang.Object)
假如有一个进程中100个线程,很多线程都在waiting on ,一定要找到是哪个线程持有这把锁
怎么找?搜索jstack dump的信息,找 ,看哪个线程持有这把锁RUNNABLE
作业:1:写一个死锁程序,用jstack观察 2 :写一个程序,一个线程持有锁不释放,其他线程等待 -
为什么阿里规范里规定,线程的名称(尤其是线程池)都要写有意义的名称
怎么样自定义线程池里的线程名称?(自定义ThreadFactory) -
jinfo pid
-
jstat -gc 动态观察gc情况 / 阅读GC日志发现频繁GC / arthas观察 / jconsole/jvisualVM/ Jprofiler(最好用)
jstat -gc 4655 500 : 每个500个毫秒打印GC的情况
如果面试官问你是怎么定位OOM问题的?如果你回答用图形界面(错误)
1:已经上线的系统不用图形界面用什么?(cmdline arthas)
2:图形界面到底用在什么地方?测试!测试的时候进行监控!(压测观察) -
jmap - histo 4655 | head -20,查找有多少对象产生
-
jmap -dump:format=b,file=xxx pid :
线上系统,内存特别大,jmap执行期间会对进程产生很大影响,甚至卡顿(电商不适合)
1:设定了参数HeapDump,OOM的时候会自动产生堆转储文件
2:很多服务器备份(高可用),停掉这台服务器对其他服务器不影响
3:在线定位(一般小点儿公司用不到) -
java -Xms20M -Xmx20M -XX:+UseParallelGC -XX:+HeapDumpOnOutOfMemoryError com.mashibing.jvm.gc.T15_FullGC_Problem01
-
使用MAT / jhat /jvisualvm 进行dump文件分析
https://www.cnblogs.com/baihuitestsoftware/articles/6406271.html
jhat -J-mx512M xxx.dump
http://192.168.17.11:7000
拉到最后:找到对应链接
可以使用OQL查找特定问题对象 -
找到代码的问题
调优实战
G1垃圾如何标记(三色标记)
基础概念
- region
- Cset
- Rset
- Humongous
- card Table
G1垃圾收集器
参考链接
启用G1
-XX:+UseG1GC
jvm hotspot内存管理
参考链接