row_number 和 cte 使用实例:求不连续的分段结果
row_number 和 cte 使用实例:求不连续的分段结果
- 求不连续的分段结果
-
- 使用 cte 递归完成
-
- 找出连续片段的开头
- 使用 cte 递归,附加其他数据
- 完成最后的分组聚合
- 使用 row_number 完成
-
- 同时使用两个开窗函数
- 使用两个排名函数差作为分组依据
- 小结
求不连续的分段结果
问题同样出自问答区某个小伙伴的问题,原地址:https://ask.csdn.net/questions/7897228,不过这次的小伙伴问的是 mysql 的。当时老顾电脑上没有安装 mysql ,临时下载了安装,然后直接在命令行调试,所以当时的指令就显得很繁琐了。
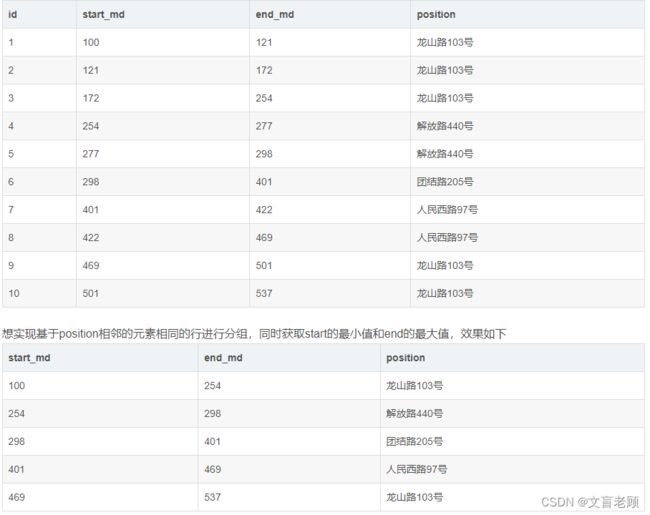
小伙伴的需求从新描述一下:
有一些连续的数据,现在要按照数据中某列的递增顺序,给另外一列的数据进行连续片段的分组查询。
问答中,小伙伴很清楚的给出了逻辑,比如龙山路这个数据,他分成两个连续片段,而不是一个。那么问题来了,简单的 group by 已经无法实现这个小伙伴的需求了,所以,我们来用 cte 完成一次吧。
使用 cte 递归完成
在当时,老顾也没想那么多,就想着 cte 可以递归,那么就用 cte 来完成就可以了。按照递归分析一下需求:
1、每一个数据与之前的数据比较,如果 position 不相同,则为当前片段的开始
2、对所有非连续片段开始的数据,追加到前一行之后,开始数据 start_md 引用片段开始的数据
3、在所有数据都追加到递归后,取所有 start_md 相同的行及最大 end_md 作为结果返回
嗯,老顾当时就是这么个思路,问答中已经有了 mysql 的写法了,这次,我们用 mssql 写一遍。
找出连续片段的开头
with t as ( -- 原始数据
select 1 id, 100 start_md, 121 end_md, '龙山路103号' position
union all select 2, 121, 172, '龙山路103号'
union all select 3, 172, 254, '龙山路103号'
union all select 4, 254, 277, '解放路440号'
union all select 5, 277, 298, '解放路440号'
union all select 6, 298, 401, '团结路205号'
union all select 7, 401, 422, '人民西路97号'
union all select 8, 422, 469, '人民西路97号'
union all select 9, 469, 501, '龙山路103号'
union all select 10, 501, 537, '龙山路103号'
),t1 as (
select * from t a
where not exists(select 1 from t where position=a.position and end_md=a.start_md)
)
select * from t1
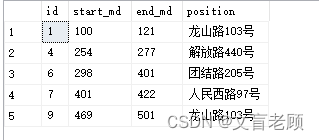
这个方式我相信小伙伴们都能做到,条件一罗列,结果就出来了。
使用 cte 递归,附加其他数据
我们都知道,cte 递归的时候,是需要最大关联,也就是笛什么卡什么尔的鸡。。。。?算了,直接写代码吧,老顾没上过学,这些名词搞不懂。。。。
with t as ( -- 原始数据
select 1 id, 100 start_md, 121 end_md, '龙山路103号' position
union all select 2, 121, 172, '龙山路103号'
union all select 3, 172, 254, '龙山路103号'
union all select 4, 254, 277, '解放路440号'
union all select 5, 277, 298, '解放路440号'
union all select 6, 298, 401, '团结路205号'
union all select 7, 401, 422, '人民西路97号'
union all select 8, 422, 469, '人民西路97号'
union all select 9, 469, 501, '龙山路103号'
union all select 10, 501, 537, '龙山路103号'
),t1 as (
select * from t a
where not exists(select 1 from t where position=a.position and end_md=a.start_md)
union all
select a.id,b.start_md,a.end_md,a.position from t a,t1 b
where a.start_md=b.end_md and a.position=b.position
)
select * from t1 order by start_md
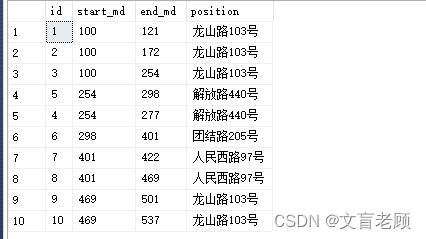
嗯,直接把连续的片段的 start_md 给弄成一样的了,这个时候,我们再按照 start_md 一分组,聚合一下 end_md 就完成了
完成最后的分组聚合
with t as ( -- 原始数据
select 1 id, 100 start_md, 121 end_md, '龙山路103号' position
union all select 2, 121, 172, '龙山路103号'
union all select 3, 172, 254, '龙山路103号'
union all select 4, 254, 277, '解放路440号'
union all select 5, 277, 298, '解放路440号'
union all select 6, 298, 401, '团结路205号'
union all select 7, 401, 422, '人民西路97号'
union all select 8, 422, 469, '人民西路97号'
union all select 9, 469, 501, '龙山路103号'
union all select 10, 501, 537, '龙山路103号'
),t1 as (
select * from t a
where not exists(select 1 from t where position=a.position and end_md=a.start_md)
union all
select a.id,b.start_md,a.end_md,a.position from t a,t1 b
where a.start_md=b.end_md and a.position=b.position
)
select start_md,max(end_md) end_md,position
from (
select * from t1
) a
group by position,start_md
order by start_md
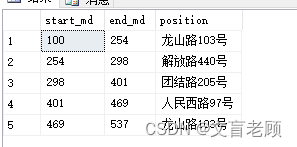
很好,和问答题主的要求一样了,这次因为时间充足,所以指令没有那么累赘了,很方便的就完成了。
使用 row_number 完成
还是这个问题,除了 cte 递归之外,我们还可以使用 row_number 来完成哦。这里也许会惊讶一些小伙伴,但是,老顾要说,从来没有人规定,开窗函数在查询中只能使用一次!
1、 使用开窗函数,分别对递增数据进行完整的序号分配,和分组后的序号分配
2、求两个序号的差,最为新的分组依据,为了避免分组差有相同值,同时以原本预定的列作为分组依据的另一个列
同时使用两个开窗函数
with t as ( -- 原始数据
select 1 id, 100 start_md, 121 end_md, '龙山路103号' position
union all select 2, 121, 172, '龙山路103号'
union all select 3, 172, 254, '龙山路103号'
union all select 4, 254, 277, '解放路440号'
union all select 5, 277, 298, '解放路440号'
union all select 6, 298, 401, '团结路205号'
union all select 7, 401, 422, '人民西路97号'
union all select 8, 422, 469, '人民西路97号'
union all select 9, 469, 501, '龙山路103号'
union all select 10, 501, 537, '龙山路103号'
)
select *
,row_number() over(order by start_md) mid
,row_number() over(partition by position order by start_md) nid from t
order by id

老顾这次使用了两个 row_number ,但是分配序号的依据并不一样哦,一个是按顺序分配,一个是分组分配,这个时候,大家看看 mid 和 nid ,有没有感觉逻辑变得简单了?当 mid-nid 相同,且 position 一致。。。。是不是直接就可以得到问答小伙伴的结果了?
使用两个排名函数差作为分组依据
看到标题和前边的说明,相信小伙伴们已经明白了,这个题目原来如此简单。。。
with t as ( -- 原始数据
select 1 id, 100 start_md, 121 end_md, '龙山路103号' position
union all select 2, 121, 172, '龙山路103号'
union all select 3, 172, 254, '龙山路103号'
union all select 4, 254, 277, '解放路440号'
union all select 5, 277, 298, '解放路440号'
union all select 6, 298, 401, '团结路205号'
union all select 7, 401, 422, '人民西路97号'
union all select 8, 422, 469, '人民西路97号'
union all select 9, 469, 501, '龙山路103号'
union all select 10, 501, 537, '龙山路103号'
)
select min(start_md) start_md,max(end_md) end_md,position
from (
select *
,row_number() over(order by start_md) mid
,row_number() over(partition by position order by start_md) nid
from t
) a
group by mid-nid,position

逻辑清晰,条理分明,实现简单。。。哎。。。答问答的时候怎么就没想起来呢。
小结
对于同一个需求,其实有很多种方式去完成,我们可以在我们的知识范围内选择我们可以实现的方式来实施。对于知识体系搭建,唯一的要求就是见多识广,当你看到的足够多了,学习和使用过的东西足够多了,自然就能找到比较好的解决方案了。记得小说《重生传说》里,有这么一段话:**我们长大之后,总觉得自己所学的知识没有用,其实不是没用,是因为你所学太少,根本想不到在哪里该用什么。**摘自《重生传说》第三章。
所以,祝愿所有的小伙伴多学多看,读万卷书行万里路,能够活学活用自己的一身本领。不忘初心,砥砺前行。永远18岁,敏而好学。
