【关于Linux中----文件系统、inode、软硬链接和动静态库】
文章目录
- 一、理解文件系统和inode
- 二、硬链接与软链接
- 三、动静态库
-
- 3.1、静态库与动态库
- 3.2、生成静态库
- 3.3、生成动态库
一、理解文件系统和inode
在我前几篇博客中谈到的有关文件的话题,它们统一指的都是打开的文件,那么在这里,我要谈一下没有被打开的文件。
众所周知,文件包括文件内容和文件属性。所以,一个空文件的大小并不是0,空文件的大小指的是它的属性所占的空间。
那么空文件存在在哪里呢?
答案是磁盘。磁盘是计算机中的一个机械设备(SSD FLASH卡 USB例外)
关于磁盘的基本结构:

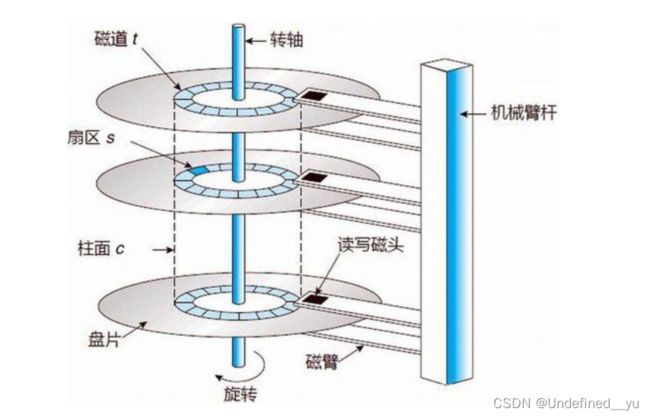
一个磁盘包括多个盘片,每一个盘片的上下两个面都是可以存储信息的,而这些信息在存储时,是按照一定的规则存在每一个扇区里的。当需要读取一些信息时,读写磁头会沿着盘片的圆心到边缘移动,同时盘片也会旋转,以便能找到想要的信息,之后再进行读写操作。
与磁盘功能相似,长相又有些接近的时下面这个东西:

大家都知道这个东西里的磁带是一条很长很长的“线”。
那么既然功能和磁盘类似,可不可以把磁盘想象成一个线性结构呢?
其实,站在OS角度,磁盘就是一个线性结构。我们把每一个盘片上的扇区想象成一个收尾闭合的长带子,再把它展开,就相当于一个长数组,而每一个扇区就像一个数组元素。
《程序员的自我修养》这本书中是这样描述的:
我们可以想象每个盘面上同心圆的周长不一样,如果按照每个磁道都拥有相同数量的扇区,那么靠近盘片外围的磁道密度肯定比内圈更加稀疏,这样是比较浪费空间的。但是如果不同的磁道扇区数又不同,计算起来就十分麻烦。
为了屏蔽这些复杂的硬件细节,现在的硬盘普遍使用一种叫做LBA(Logical Block Address)的方式,即整个硬盘中所有的扇区从0开始编号,一直到最后一个扇区,这个扇区编号叫做逻辑扇区号。逻辑扇区号抛弃了所有复杂的磁道、盘面之类的概念。当我们给出一个逻辑的扇区号时,磁盘的电子设备会将其转换成实际的盘面、磁道等这些位置。
其实,这个概念跟虚拟地址和物理内存之间的映射有点神似,都是为了OS能更方便地访问数据信息。
铺垫了这么多,只是为了更好地回答一个问题----一个没有被打开的文件,它在磁盘中是怎么被保存的?
首先,OS为了更好地管理磁盘,将磁盘内部分成了一个个小的区域,这个操作叫做分区。就像我们的电脑上有C盘、D盘、E盘等,其实这些盘都是存在在一个盘上的(一些配置特别高的电脑除外)。
其次,OS会为每一个分区写入文件系统。这样做的目的是为了每一个分区都能更独立地完成自己的任务,彼此互不影响。这个过程叫做格式化。
每一个分区中的结构如下:

所以,要管理好整个磁盘,先要管理好每一个分区,要管理好每一个分区,就要先管理好每一个Block group。
下面再看每一个Block group的内部结构:
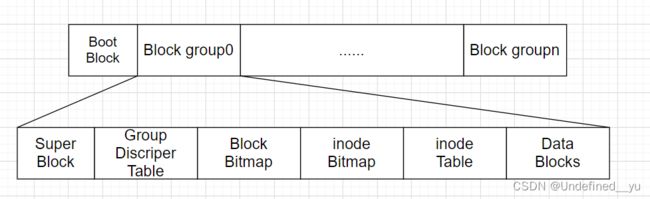
Super Block中主要包含的是每一个Block group中的空间使用情况和所有文件相关的使用信息。
Group Discriper Table中包含的是Block group的表征信息即属性,如这个group所占空间是多大,起始位置和截至位置分别在哪儿等。
这两个部分稍作了解即可,重点介绍后面四个部分。
其实,文件的属性存放在inode Table中,文件的内容存放在Data Blocks中。这两个部分内部都含有一个个的小的存储空间,每一个空间都可以存储文件相关的属性和内容。
那么,一个文件的属性和内容是怎么做到一一对应的呢?
我们在创建文件的时候,都会为文件去一个名字。事实上,在Liunx操作系统层面,文件名并没有实际的意义,它只是为了用户使用而已。
操作系统用来标记每一个文件的东西叫做inode。这个inode里又包括inode编号和block编号。当操作系统要对文件进行访问时,只需要通过inode赵铎对应的属性和内容存放位置的编号,就可以提取到文件的属性和内容。
每一个inode Table和Data Blocks中都含有成百上千个可以存放属性和内容的小空间,甚至更多。那么当要为一个文件存放属性和内容时,怎么找到一个没有被使用的小空间呢?
这里就要用到Block Bitmap和inode Bitmap了。
inode Bitmap里面有很多类似于比特位的存储结构,每一个比特位就代表每一个inode Table中的小空间,而每一个比特位的数值代表这个小空间是否被占用(1代表被占用,0代表不被占用),Block Bitmap与其类似。
所以,要确定每一个存放属性和内容的小空间是否被占用,只需要遍历inode Bitmap和inode Bitmap即可。
以上就是每一个Block Group的管理方式了,管理好每一个Block Group就能管理好每一个分区,进而就可以管理好整个磁盘了。
我们知道,每一个目录也都是一个文件,都具有自己的属性和数据,目录的数据是此目录下所有的文件的文件名和对应的inode关系。
下面来创建一个文件,并向其中写入数据:
[sny@VM-8-12-centos prictice]$ touch hello.c
[sny@VM-8-12-centos prictice]$ echo "hello world" > hello.c
[sny@VM-8-12-centos prictice]$ cat hello.c
hello world
那么这个操作在操作系统层面都做了些什么呢?
首先创建文件,通过位图找到哪些inode和block可以使用,向其中填入属性和内容。
其次,写入信息和上面创建文件相同。
最后,打印信息,需要在当前目录对应的文件中找到该文件的inode编号和文件名,再通过编号找到inode和block将其内容打印出来。
但是,当我要删除某个文件时,所要进行的操作并没有上面那么复杂。不需要将所有信息删除,只需要将位图中对应的比特位置0即可,下次创建文件时,直接将其内容覆盖。
二、硬链接与软链接
二话不说,先建立一个软链接:
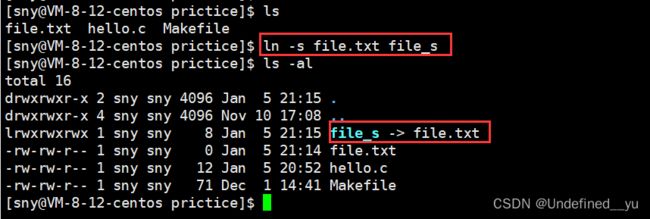
以上就是建立软链接的操作,代表的是将file_s链接到file.txt。
删除软链接操作如下:
[sny@VM-8-12-centos prictice]$ unlink file_s
[sny@VM-8-12-centos prictice]$ ls -al
total 16
drwxrwxr-x 2 sny sny 4096 Jan 5 21:17 .
drwxrwxr-x 4 sny sny 4096 Nov 10 17:08 ..
-rw-rw-r-- 1 sny sny 0 Jan 5 21:14 file.txt
-rw-rw-r-- 1 sny sny 12 Jan 5 20:52 hello.c
-rw-rw-r-- 1 sny sny 71 Dec 1 14:41 Makefile
那么,我们什么情况下会想要使用软链接呢?
当我们处于某一目录下,但是我们需要访问的文件在我们所处目录的n多级子目录下时,这时我们通过跳转目录进行访问会比较麻烦,但是通过软链接可以在当前目录下创建一个链接该文件的文件,就可以实现直接访问了,这样更方便。事实上,软链接的作用跟windows下的快捷方式有点相似。
需要知道的是,软链接是一个独立的文件,它有自己独立的inode,有自己的inode属性和数据块(保存的是指向文件的所在路径+文件名)。
下面再来建立一个硬链接:
[sny@VM-8-12-centos prictice]$ ln hello.c hard
[sny@VM-8-12-centos prictice]$ ls -ali
total 20
789554 drwxrwxr-x 2 sny sny 4096 Jan 5 21:29 .
789468 drwxrwxr-x 4 sny sny 4096 Nov 10 17:08 ..
789543 -rw-rw-r-- 1 sny sny 0 Jan 5 21:14 file.txt
789529 -rw-rw-r-- 2 sny sny 12 Jan 5 20:52 hard
789529 -rw-rw-r-- 2 sny sny 12 Jan 5 20:52 hello.c
793588 -rw-rw-r-- 1 sny sny 71 Dec 1 14:41 Makefile
可以看到,hello.c和hard两者的inode是相同的,所以硬链接的本质不是一个独立的文件,而是一个文件名和inode编号的映射关系!
同时可以看到,当硬链接建立时,对应的文件的链接数就会+1,链接数指的是所链接的文件个数。硬链接的本质是将链接数+1,而文件是否继续存在也取决于链接数,当链接数变为0时,该文件也就被删除了,这也就相当于引用计数。
下面再对".“和”…"做一个补充:

可以看到"."对应的inode和当前目录是相同的,也就是说它们构成硬链接。
再看一个现象:
[sny@VM-8-12-centos code]$ ll -dli prictice
789554 drwxrwxr-x 2 sny sny 4096 Jan 5 21:29 prictice
[sny@VM-8-12-centos code]$ cd prictice
[sny@VM-8-12-centos prictice]$ mkdir dir
[sny@VM-8-12-centos prictice]$ cd ..
[sny@VM-8-12-centos code]$ ll -dli prictice
789554 drwxrwxr-x 3 sny sny 4096 Jan 5 21:48 prictice
可以看到,在prictice下创建一个dir目录之后,prictice的链接数变成了3,这是因为prictice不仅链接了dir、“.”,dir中也有一个"…",所以是3。
再针对与文件有关的三个时间做一个补充:
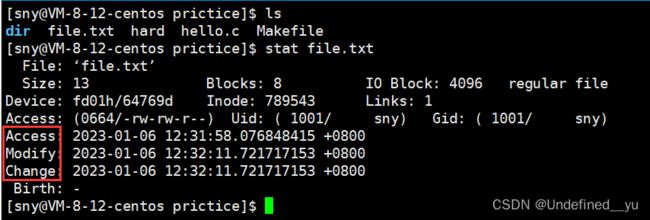
可以看到,每一个文件都有三个时间属性,下面一一解释:
①Access,它表示文件最近一次被访问的时间
接下来对该文件进行写入操作,看其Access会不会改变
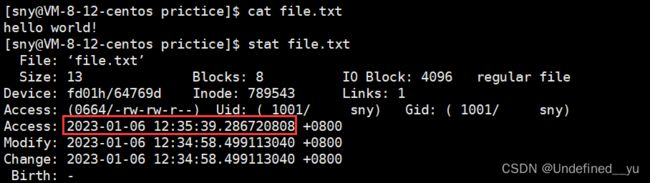
可以看到,Access确实该变了。但是需要补充一点,在一些较新的Linux中,这个时间并不会在访问文件之后立刻改变,而是会每隔一段时间进行一次更新。
②Modify,它表示最新一次文件内容被修改的时间
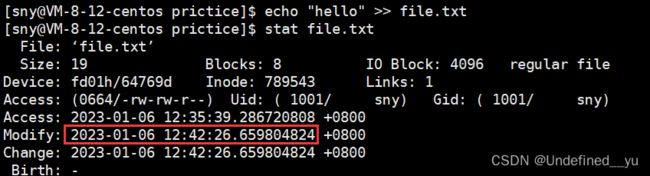
③Change,它表示最新一次文件属性被修改的时间。在上面的图中,可以看到修改文件内容时,Change也发生了变化,这是因为修改内容之后文件对应的大小属性发生了变化。同样的,当文件的其他属性(所属组,拥有者等)发生改变时,它也会改变。
下面,来编写一个C语言程序:

其对应的Makefile内容如下:
接着执行程序,如下:
[sny@VM-8-12-centos prictice]$ make
gcc -o test test.c
[sny@VM-8-12-centos prictice]$ ls -al
total 36
drwxrwxr-x 3 sny sny 4096 Jan 6 12:53 .
drwxrwxr-x 4 sny sny 4096 Jan 5 21:52 ..
drwxrwxr-x 2 sny sny 4096 Jan 5 21:48 dir
-rw-rw-r-- 1 sny sny 19 Jan 6 12:42 file.txt
-rw-rw-r-- 1 sny sny 58 Jan 6 12:53 Makefile
-rwxrwxr-x 1 sny sny 8360 Jan 6 12:53 test
-rw-rw-r-- 1 sny sny 75 Jan 6 12:51 test.c
[sny@VM-8-12-centos prictice]$ ./test
hello world!
这里并没有什么问题,程序被成功执行
但是,再执行一次就会出现这种情况:
[sny@VM-8-12-centos prictice]$ make
make: `test' is up to date.
这是因为,当test.c中的内容没有改变时,是不会生成新的可执行程序的。而系统判断test.c内容是否被修改的方法就是通过它的Modify时间的变化,而且毫无疑问,每次生成可执行程序,这个可执行程序对应的时间一定比test.c更新,因为可执行程序生成的前提是要有对应的源文件。
而是否要生成新的可执行程序,也是通过比较它和源文件的时间决定的!
而如果我touch一个已经存在的源文件,那么它所对应的时间会被更新,这时源文件的时间一定比对应的可执行程序的时间还要新,所以再次make时,一定会生成新的可执行程序,如下:
[sny@VM-8-12-centos prictice]$ make
make: `test' is up to date.
[sny@VM-8-12-centos prictice]$ touch test.c
[sny@VM-8-12-centos prictice]$ stat test.c
File: ‘test.c’
Size: 75 Blocks: 8 IO Block: 4096 regular file
Device: fd01h/64769d Inode: 789529 Links: 1
Access: (0664/-rw-rw-r--) Uid: ( 1001/ sny) Gid: ( 1001/ sny)
Access: 2023-01-06 13:04:54.289875588 +0800
Modify: 2023-01-06 13:04:54.289875588 +0800
Change: 2023-01-06 13:04:54.289875588 +0800
Birth: -
[sny@VM-8-12-centos prictice]$ make
gcc -o test test.c
三、动静态库
3.1、静态库与动态库
在Linux中,可以用ldd命令查看可执行程序所依赖的库,如下:
[sny@VM-8-12-centos prictice]$ ldd test
linux-vdso.so.1 => (0x00007fffb27fa000)
libc.so.6 => /lib64/libc.so.6 (0x00007f29c98a5000)
/lib64/ld-linux-x86-64.so.2 (0x00007f29c9c73000)
那么这一堆是些什么东西呢?
因为test对应的源文件是一个C程序,所以它依赖的库就是C语言的标准库,如下:
[sny@VM-8-12-centos prictice]$ ls /lib64/libc.so.6 -l
lrwxrwxrwx 1 root root 12 Jul 25 16:58 /lib64/libc.so.6 -> libc-2.17.so
前面已经讲过,这是一个软链接,接下来看一下软链接的文件的具体属性:
[sny@VM-8-12-centos prictice]$ ls /lib64/libc-2.17.so -l
-rwxr-xr-x 1 root root 2156592 May 19 2022 /lib64/libc-2.17.so
其实,我们在C语言中用到的一切C语言提供的函数接口所依赖的都是这个库。
一般库分为两种:动态库和静态库
而在Linux中,动态库的库文件是以.so为后缀的,静态库的库文件是以.a为后缀的(如上面的就是一个动态库)。而一个库文件的命名规则一般是libXXXX.so 或libXXXX.a-…,一个库文件去掉lib和后缀(包含.so和.a-)之后剩下的部分就是库的名字。(如上面代码中的库就是c-2.17)
而Linux下的gcc默认动态链接编译,如下:
[sny@VM-8-12-centos prictice]$ file test
test: ELF 64-bit LSB executable, x86-64, version 1 (SYSV), dynamically linked (uses shared libs), for GNU/Linux 2.6.32, BuildID[sha1]=a4becb868bc061e68c4da1f2ac44b5b52e2d48eb, not stripped
而如果将其换为静态链接,需要将其Makefile文件内容稍作修改:
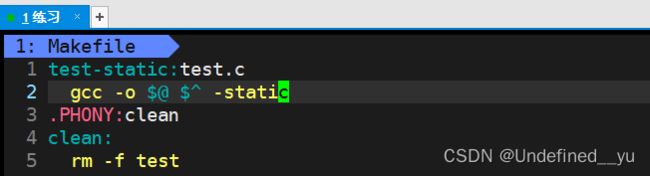
[sny@VM-8-12-centos prictice]$ make
gcc -o test-static test.c -static
[sny@VM-8-12-centos prictice]$ ls
dir file.txt Makefile test test.c test-static
[sny@VM-8-12-centos prictice]$ file test-static
test-static: ELF 64-bit LSB executable, x86-64, version 1 (GNU/Linux), statically linked, for GNU/Linux 2.6.32, BuildID[sha1]=77857e7533d6b37f39e6377c9317a26347a0985f, not stripped
可以看到,使用动态库生成的可执行程序大小要远小于使用静态库生成的可执行程序,这也是编译器默认采用动态库的一大原因。
(一般服务器可能没有内置语言的静态库,而只有动态库,这时候使用-static命令就会报错,必须自己安装静态库才能使用)
静态库(.a):程序在编译链接的时候把库的代码链接到可执行文件中。程序运行的时候将不再需要静态库
动态库(.so):程序在运行的时候才去链接动态库的代码,多个程序共享使用库的代码。
一个与动态库链接的可执行文件仅仅包含它用到的函数入口地址的一个表,而不是外部函数所在目标文件的整个机器码
在可执行文件开始运行以前,外部函数的机器码由操作系统从磁盘上的该动态库中复制到内存中,这个过程称为动态链接(dynamic linking)
动态库可以在多个程序间共享,所以动态链接使得可执行文件更小,节省了磁盘空间。操作系统采用虚拟内存机制允许物理内存中的一份动态库被要用到该库的所有进程共用,节省了内存和磁盘空间
3.2、生成静态库
在自己制作静态库之前,先看一下库文件中都有些什么东西:
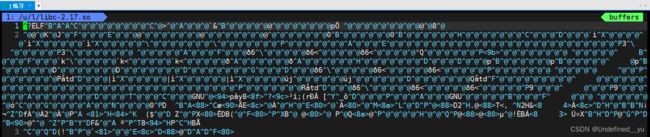
可以看到库文件中存放的是二进制的内容,那我们怎么判断一个库中是否有我们需要的函数接口呢?
一个完整的库一定包括库文件、头文件和说明文档,其中头文件是一个文本文件,它会说明一个库中暴露出的方法的基本使用,通过它就可以知道了。
头文件一般被放在/usr/include/路径下:
[sny@VM-8-12-centos prictice]$ ls /usr/include/
aio.h db_185.h fpu_control.h infiniband libnl3 net paths.h rpc strings.h unistd.h
aliases.h db.h fstab.h inttypes.h libudev.h netash pcrecpparg.h rpcsvc sys ustat.h
alloca.h dirent.h fts.h ip6tables.h limits.h netatalk pcrecpp.h sched.h syscall.h utime.h
a.out.h dlfcn.h ftw.h iptables link.h netax25 pcre.h scsi sysexits.h utmp.h
argp.h drm _G_config.h iptables.h linux netdb.h pcreposix.h search.h syslog.h utmpx.h
argz.h dwarf.h gconv.h kadm5 locale.h neteconet pcre_scanner.h selinux systemd valgrind
ar.h elf.h gelf.h kdb.h lzma netinet pcre_stringpiece.h semaphore.h tar.h values.h
arpa elfutils getopt.h keyutils.h lzma.h netipx poll.h sepol termio.h verto.h
asm endian.h gio-unix-2.0 krad.h malloc.h netiucv printf.h setjmp.h termios.h verto-module.h
asm-generic envz.h glib-2.0 krb5 math.h netpacket profile.h sgtty.h tgmath.h video
assert.h err.h glob.h krb5.h mcheck.h netrom protocols shadow.h thread_db.h wait.h
bits errno.h gnu langinfo.h mellanox netrose pthread.h signal.h time.h wchar.h
byteswap.h error.h gnu-versions.h lastlog.h memory.h nfs pty.h sound ttyent.h wctype.h
c++ et grp.h libdb mft nlist.h pwd.h spawn.h uapi wordexp.h
com_err.h execinfo.h gshadow.h libelf.h misc nl_types.h python2.7 stab.h uchar.h xen
complex.h fcntl.h gssapi libgen.h mntent.h nss.h python3.6m stdc-predef.h ucm xlocale.h
cpio.h features.h gssapi.h libintl.h monetary.h numacompat1.h rdma stdint.h ucontext.h xtables.h
cpufreq.h fenv.h gssrpc libio.h mqueue.h numa.h re_comp.h stdio_ext.h ucp xtables-version.h
crypt.h FlexLexer.h iconv.h libiptc mstflint numaif.h regex.h stdio.h ucs zconf.h
ctype.h fmtmsg.h ieee754.h libipulog mtcr_ul obstack.h regexp.h stdlib.h uct zlib.h
dat2 fnmatch.h ifaddrs.h libmnl mtd openssl resolv.h string.h ulimit.h
随便打开一个头文件,内容如下:

这只是其中的一小部分内容,多余的就不进行粘贴了。
在自己动手制作静态库之前,先插一个问题
为什么我们在写项目的时候,都习惯把声明放在.h文件里,把实现放在.cpp等的文件里呢?
答:一方面是为了方便维护。另一方面是为了要制作库,当我们要把自己写好的并且已经生成的可执行程序交给别人时,我们时不希望直接把自己的具体技术实现暴露给别人的。这时候就会选择提供.h问价和生成的库,因为库文件中的内容是二进制的,这样就可以防止技术盗窃。
那接下来,就先创建两个.h和.c文件:
[sny@VM-8-12-centos prictice]$ mkdir mylib
[sny@VM-8-12-centos prictice]$ cd mylib
[sny@VM-8-12-centos mylib]$ touch add.h
[sny@VM-8-12-centos mylib]$ touch add.c
[sny@VM-8-12-centos mylib]$ touch sub.h
[sny@VM-8-12-centos mylib]$ touch sub.c
[sny@VM-8-12-centos mylib]$ ls
add.c add.h sub.c sub.h
内容如下:
[sny@VM-8-12-centos mylib]$ cat add.h
#pragma once
#include 可以看到上面的代码是用来实现加法和减法的。
接下来,我们回到上级目录,并且创建程序,在其中使用两个头文件:
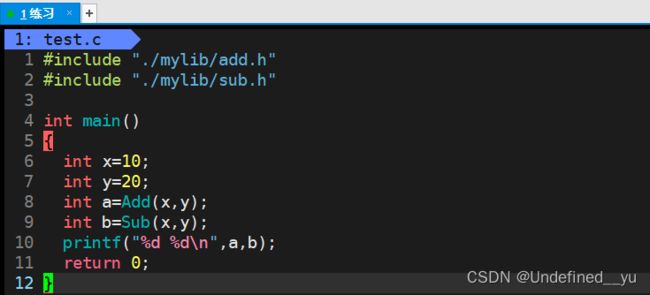
执行结果如下:
[sny@VM-8-12-centos prictice]$ gcc test.c
/tmp/ccJ42vz5.o: In function `main':
test.c:(.text+0x21): undefined reference to `Add'
test.c:(.text+0x33): undefined reference to `Sub'
collect2: error: ld returned 1 exit status
出现这样的结果是因为,程序在编译的时候只找到了函数的声明,而没有找到函数的实现。正确的方法是这样的:
[sny@VM-8-12-centos prictice]$ gcc test.c mylib/add.c mylib/sub.c
[sny@VM-8-12-centos prictice]$ ll
total 20
-rwxrwxr-x 1 sny sny 8472 Jan 6 15:54 a.out
drwxrwxr-x 2 sny sny 4096 Jan 6 15:34 mylib
-rw-rw-r-- 1 sny sny 163 Jan 6 15:48 test.c
[sny@VM-8-12-centos prictice]$ ./a.out
30 -10
可见,成功生成了可执行程序。
那么在没有库的情况下,怎么进行编译呢?
先编写一个Makefile文件:
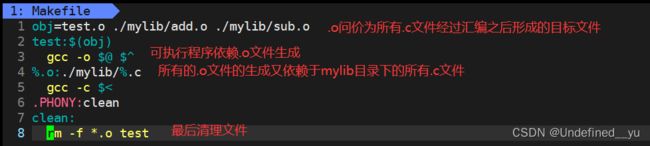
结果如下:
[sny@VM-8-12-centos prictice]$ make
cc -c -o test.o test.c
gcc -o test test.o mylib/add.o mylib/sub.o
[sny@VM-8-12-centos prictice]$ ll
total 40
-rwxrwxr-x 1 sny sny 8472 Jan 6 15:54 a.out
-rw-rw-r-- 1 sny sny 129 Jan 6 16:12 Makefile
drwxrwxr-x 2 sny sny 4096 Jan 6 16:12 mylib
-rwxrwxr-x 1 sny sny 8472 Jan 6 16:13 test
-rw-rw-r-- 1 sny sny 163 Jan 6 15:48 test.c
-rw-rw-r-- 1 sny sny 1664 Jan 6 16:13 test.o
[sny@VM-8-12-centos prictice]$ ./test
30 -10
经过上面的例子,不难看出,如果要形成库,就要打包所有的.o文件。
所以,我们就明确了生成静态库的方法(打包.o文件):

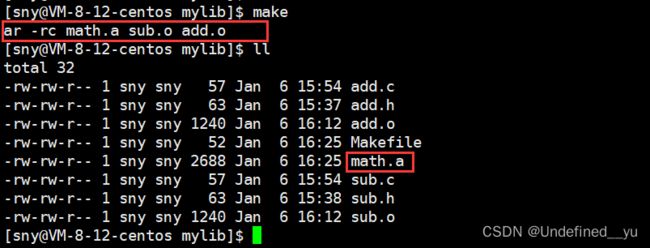
这样就成功生成了一个静态库。
可以用ar -tv命令查看静态库中的内容:
[sny@VM-8-12-centos mylib]$ ar -tv math.a
rw-rw-r-- 1001/1001 1240 Jan 6 16:12 2023 sub.o
rw-rw-r-- 1001/1001 1240 Jan 6 16:12 2023 add.o
那么如果我们要把自己的.h文件和静态库一起给别人,就可以把他们打包在一起,如下:
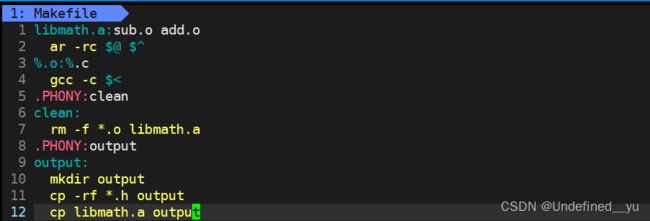
[sny@VM-8-12-centos mylib]$ make clean;make
rm -f *.o libmath.a
gcc -c sub.c
gcc -c add.c
ar -rc libmath.a sub.o add.o
[sny@VM-8-12-centos mylib]$ make output
mkdir output
cp -rf *.h output
cp libmath.a output
[sny@VM-8-12-centos mylib]$ ll
total 40
-rw-rw-r-- 1 sny sny 57 Jan 6 15:54 add.c
-rw-rw-r-- 1 sny sny 63 Jan 6 15:37 add.h
-rw-rw-r-- 1 sny sny 1240 Jan 6 16:58 add.o
-rw-rw-r-- 1 sny sny 2688 Jan 6 16:58 libmath.a
-rw-rw-r-- 1 sny sny 175 Jan 6 16:57 Makefile
drwxrwxr-x 2 sny sny 4096 Jan 6 16:58 output
-rw-rw-r-- 1 sny sny 57 Jan 6 15:54 sub.c
-rw-rw-r-- 1 sny sny 63 Jan 6 15:38 sub.h
-rw-rw-r-- 1 sny sny 1240 Jan 6 16:58 sub.o
那么制作出来的静态库该怎么使用呢?
[sny@VM-8-12-centos testlib]$ gcc test.c -I./lib -L./lib -lmath
[sny@VM-8-12-centos testlib]$ ll
total 24
-rwxrwxr-x 1 sny sny 8472 Jan 6 18:38 a.out
drwxrwxr-x 2 sny sny 4096 Jan 6 18:28 lib
-rw-rw-r-- 1 sny sny 129 Jan 6 18:08 Makefile
-rw-rw-r-- 1 sny sny 159 Jan 6 18:38 test.c
[sny@VM-8-12-centos testlib]$ ./a.out
30 -10
[root@localhost linux]# gcc main.c -L. -lmymath
-L 指定库路径
-l 指定库名
测试目标文件生成后,静态库删掉,程序照样可以运行
这里的lib和上面的output内容相同,test.c内容如下:
[sny@VM-8-12-centos testlib]$ cat test.c
#include "./lib/add.h"
#include "./lib/sub.h"
int main()
{
int x=10;
int y=20;
int a=Add(x,y);
int b=Sub(x,y);
printf("%d %d\n",a,b);
return 0;
}
当然,也可以直接在Makefile里指定路径,就可以生成对应的可执行程序:
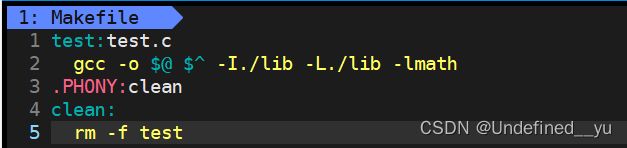
[sny@VM-8-12-centos testlib]$ make
gcc -o test test.c -I./lib -L./lib -lmath
[sny@VM-8-12-centos testlib]$ ls
a.out lib Makefile test test.c
[sny@VM-8-12-centos testlib]$ ./test
30 -10
那我们之前写代码的时候为什么不用指定库所在的路径呢?
因为这些库是在默认路径下的,编译器是可以识别到的。
换句话说,如果你不想每次都指定路径,可以把自己的库移到默认路径下,但是不建议这么做,这样会导致默认路径下结构混乱,万一这个库有点bug就更不好了。
实际上,上面的过程就是所谓的“软件安装”的过程,本质就是把所需要的库下载下来。
3.3、生成动态库
动态库的制作和静态库大同小异,只需将Makefile文件稍作改动即可:
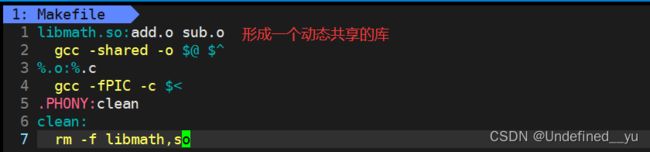
shared: 表示生成共享库格式
fPIC:产生位置无关码(position independent code)
结果如下:
[sny@VM-8-12-centos mylib]$ make
gcc -shared -o libmath.so add.o sub.o
[sny@VM-8-12-centos mylib]$ ls
add.c add.h add.o libmath.a libmath.so Makefile output sub.c sub.h sub.o
同样的,也可以将动态库和.h文件打包在一起:

[sny@VM-8-12-centos mylib]$ make lib
mkdir lib
cp *.h lib
cp libmath.so lib
[sny@VM-8-12-centos mylib]$ ls
add.c add.h add.o lib libmath.a libmath.so Makefile output sub.c sub.h sub.o
下面用静态库的使用方法来使用动态库:
[sny@VM-8-12-centos testlib]$ make
gcc -o test test.c -I./lib -L./lib -lmath
[sny@VM-8-12-centos testlib]$ ls
lib Makefile test test.c
[sny@VM-8-12-centos testlib]$ ./test
./test: error while loading shared libraries: libmath.so: cannot open shared object file: No such file or directory
很遗憾地发现运行结果出错了。这里的问题在于,静态库在使用时是直接将库中的内容复制了一份,但是动态库不会复制这些内容。指明路径只是告诉了编译器库在哪里,但是这时程序已经编译好了,也就没有用到库里面的东西。
这里介绍一个解决方法:
使用环境变量,将库所在路径设置为环境变量 LD_LIBRARY_PATH,这样编译的时候就能自动找到需要的库了,如下:
[sny@VM-8-12-centos testlib]$ cd lib
[sny@VM-8-12-centos lib]$ pwd
/home/sny/code/prictice/testlib/lib
[sny@VM-8-12-centos lib]$ export LD_LIBRARY_PATH=/home/sny/code/prictice/testlib/lib
[sny@VM-8-12-centos lib]$ cd ..
[sny@VM-8-12-centos testlib]$ make clean;make
rm -f test
gcc -o test test.c -I./lib -L./lib -lmath
[sny@VM-8-12-centos testlib]$ ls
lib Makefile test test.c
[sny@VM-8-12-centos testlib]$ ./test
30 -10
但是这种方法,在每次退出程序之后就失效了,下次再使用使,还要进行同样的操作。
当然还有其他的方法,就是ldconfig 配置/etc/ld.so.conf.d/,ldconfig更新,这种方法在退出程序之后是不会失效的,但是在一个库不经常被使用或访问次数没有那么多时,不建议使用。
所以,综合来看,还是建议使用第一种方法,虽然每次都需要设置环境变量,但是代价较小。
好好学习,好好写博客,加油!