Java中高级工程师面试题目总结及答案(一)
1.git和svn的区别
- 最核心的区别Git是分布式的,而Svn不是分布的。能理解这点,上手会很容易,声明一点Git并不是目前唯一的分布式版本控制系统,还有比如Mercurial等,所以说它们差不许多。话说回来Git跟Svn一样有自己的集中式版本库和Server端,但Git更倾向于分布式开发,因为每一个开发人员的电脑上都有一个Local Repository,所以即使没有网络也一样可以Commit,查看历史版本记录,创建项 目分支等操作,等网络再次连接上Push到Server端。
从上面看GIt真的很棒,但是GIt adds Complexity,刚开始使用会有些疑惑,因为需要建两个Repositories(Local Repositories & Remote Repositories),指令很多,除此之外你需要知道哪些指令在Local Repository,哪些指令在Remote Repository。
2)Git把内容按元数据方式存储,而SVN是按文件:因为,.git目录是处于你的机器上的一个克隆版的版本库,它拥有中心版本库上所有的东西,例如标签,分支,版本记录等。.git目录的体积大小跟.svn比较,你会发现它们差距很大。 - Git没有一个全局版本号,而SVN有:目前为止这是跟SVN相比Git缺少的最大的一个特征。
- Git的内容的完整性要优于SVN: GIT的内容存储使用的是SHA-1哈希算法。这能确保代码内容的完整性,确保在遇到磁盘故障和网络问题时降低对版本库的破坏。
- Git下载下来后,在OffLine状态下可以看到所有的Log,SVN不可以。
- 刚开始用时很狗血的一点,SVN必须先Update才能Commit,忘记了合并时就会出现一些错误,git还是比较少的出现这种情况。
7)克隆一份全新的目录以同样拥有五个分支来说,SVN是同时复製5个版本的文件,也就是说重复五次同样的动作。而Git只是获取文件的每个版本的 元素,然后只载入主要的分支(master)在我的经验,克隆一个拥有将近一万个提交(commit),五个分支,每个分支有大约1500个文件的 SVN,耗了将近一个小时!而Git只用了区区的1分钟!
8)版本库(repository):SVN只能有一个指定中央版本库。当这个中央版本库有问题时,所有工作成员都一起瘫痪直到版本库维修完毕或者新的版本库设立完成。而 Git可以有无限个版本库。或者,更正确的说法,每一个Git都是一个版本库,区别是它们是否拥有活跃目录(Git Working Tree)。如果主要版本库(例如:置於GitHub的版本库)发生了什麼事,工作成员仍然可以在自己的本地版本库(local repository)提交,等待主要版本库恢复即可。工作成员也可以提交到其他的版本库!
9)分支(Branch)在SVN,分支是一个完整的目录。且这个目录拥有完整的实际文件。如果工作成员想要开啟新的分支,那将会影响“全世界”!每个人都会拥有和你一样的分支。如果你的分支是用来进行破坏工作(安检测试),那将会像传染病一样,你改一个分支,还得让其他人重新切分支重新下载,十分狗血。而 Git,每个工作成员可以任意在自己的本地版本库开啟无限个分支。举例:当我想尝试破坏自己的程序(安检测试),并且想保留这些被修改的文件供日后使用, 我可以开一个分支,做我喜欢的事。完全不需担心妨碍其他工作成员。只要我不合并及提交到主要版本库,没有一个工作成员会被影响。等到我不需要这个分支时, 我只要把它从我的本地版本库删除即可。无痛无痒。
Git的分支名是可以使用不同名字的。例如:我的本地分支名为OK,而在主要版本库的名字其实是master。
最值得一提,我可以在Git的任意一个提交点(commit point)开启分支!(其中一个方法是使用gitk –all 可观察整个提交记录,然后在任意点开啟分支。)
10)提交(Commit)在SVN,当你提交你的完成品时,它将直接记录到中央版本库。当你发现你的完成品存在严重问题时,你已经无法阻止事情的发生了。如果网路中断,你根本没办法提交!而Git的提交完全属於本地版本库的活动。而你只需“推”(git push)到主要版本库即可。Git的“推”其实是在执行“同步”(Sync)。
最后总结一下:
SVN的特点是简单,只是需要一个放代码的地方时用是OK的。
Git的特点版本控制可以不依赖网络做任何事情,对分支和合并有更好的支持(当然这是开发者最关心的地方),不过想各位能更好使用它,需要花点时间尝试下。
2.JSP与Servlet区别简述
首先说明JSP出现的背景:Servlet体系是基于B/S架构开发web应用程序,使用Servlet类将HTTP请求和响应封装在标准JAVA类中来实现各种web应用方案的。当大量的B/S架构程序开发出来以后出现了很多问题:首先servlet类有大量冗余代码,其次是开发Servlet的没法做到有精美的页面效果。所以sun提出将服务端代码添加在已经设计好的静态页面上,经过JSP容器对JSP文件进行自动解析并转换成Servlet类来交给web服务器运行。
所以JSP在本质上就是Servlet,但是两者的创建方式不一样。Servlet都是由JAVA程序代码构成,用于流程控制和事务处理,通过Servlet来生成动态网页很不直观。而JSP由HTML代码和JSP标签构成,可以方便地编写动态网页.
另外总结一下,JSP与Servlet主要有两方面的不同:编译:JSP修改后可以立即看到结果,不需要编译;而Servelt缺需要编译。转换:JSP是动态网页开发技术,是运行在服务器端的脚本语言,而Servlet是web服务器端编程技术。所以JSP运行时就是转换为Servlet,也就是java程序来执行。
3.maven与svn怎么搭建
Maven安装配置
5.1 maven配置环境变量
下载maven,就是一个包:apache-maven-3.2.1,我用的版本是3.2.1,解压到一个路径,然后配置环境变量:
5.1 新建变量名:MAVEN_HOME 变量值:D:\server\apache-maven-3.2.1(这是我的MAVEN路径)
5.2 编辑变量名:Path 在最前面加上:%MAVEN_HOME%\bin;(注意,最后要有个";"作为分隔符)
——————————————————————————————————————————————————
完成之后,在命令行输入:mvn -version查看是否有以下内容,如果有表示配置成功。

5.2Maven数据仓库的配置
MAVEN中还有一个重要的配置就是数据仓库的路径配置,我们找到MAVEN的安装路径,进入conf–>打开settings.xml,找到localRepository标签,此时是被注释掉的,我们解除注释,然后配置一个路径,例如:d:/server/MavenRepository/maven_jar,这样以后MAVEN管理下载的jar包都会在这个路径下。当然我们需要建这样一个目录结构,然后还要讲settings.xml复制一份到d:/server/MavenRepository下,这个在与MyEclipse集成时会用到。
5.3MyEclipse中集成Maven
一样在preferences中进行配置,如下图:

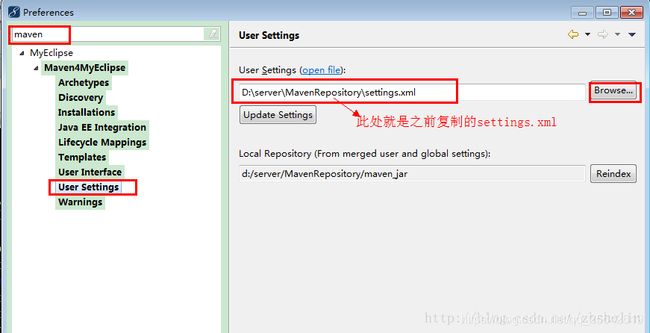
此时,点击File-->new-->other-->MyEclipse-->Maven4MyEclipse-->Maven Project,如果可以看到这些,证明配置成功,已经可以建立Maven项目了。
6.SVN安装
SVN是代码版本管理器,首先在本地安装一个SVN管理器,然后配置MyEclipse的SVN插件,将插件下载下来解压后,直接复制到MyEclipse安装目录下dropins中即可。任意建立一个项目,右键项目–>team–>share Project…,打开后如果看到了SVN代表插件安装成功。
4.maven的作用
Maven是一个构建工具,服务与构建.使用Maven配置好项目后,输入简单的命令,如:mvn clean install,Maven会帮我们处理那些繁琐的任务.
Maven是跨平台的.
Maven最大化的消除了构建的重复.
Maven可以帮助我们标准化构建过程.所有的项目都是简单一致的,简化了学习成本.
总之,Maven作为一个构建工具,不仅帮我们自动化构建,还能抽象构建过程,提供构建任务实现.他跨平台,对外提供一致的操作接口,这一切足以使他成为优秀的,流行的构建工具.
但是Maven不仅是构建工具,他还是一个依赖管理工具和项目信息管理工具.他还提供了中央仓库,能帮我们自动下载构件.
使用Maven还能享受一个额外的好处,即Maven对于项目目录结构、测试用例命名方式等内容都有既定的规则,只要遵循了这些成熟的规则,用户在项目间切换的时候就免去了额外的学习成本,可以说是约定优于配置(Convention Over Configuration)。Maven几乎能够很好地支持任何软件开发方法。
例如,在传统的瀑布模型开发中,项目依次要经历需求开发、分析、设计、编码、测试和集成发布阶段。从设计和编码阶段开始,就可以使用Maven来建立项目的构建系统。在设计阶段,也完全可以针对设计开发测试用例,然后再编写代码来满足这些测试用例。然而,有了自动化构建系统,我们可以节省很多手动的测试时间。此外,尽早地使用构建系统集成团队的代码,对项目也是百利而无一害。最后,Maven还能帮助我们快速地发布项目。
5.svn远程服务器搭建
1.下载并安装 Subversion服务器程序,假设安装在 C:/Program files/subversion。
2.建立 repository,
[plain] view plain copy
c:
cd “C:\Program Files\Subversion\bin”
svnadmin create C:/SVN_SERVE_REPOSITORY
保存为.bat,双击运行。可以看到 目录下有:
3.打开\conf\svnserve.conf,
改:
anon-access = read ——
anon-access = none
auth-access = write ——
auth-access = write
password-db = passwd ——
password-db = passwd
4.打开\conf\passwd
在[users]下添加用户
username = password
- 开启SVN服务
[plain] view plain copy
cd “C:\Program Files\Subversion\bin”
svnserve -d -r C:\SVN_R
pause
双击此批处理,并且保留窗口,关闭窗口则会关闭服务。
6.导入工作空间

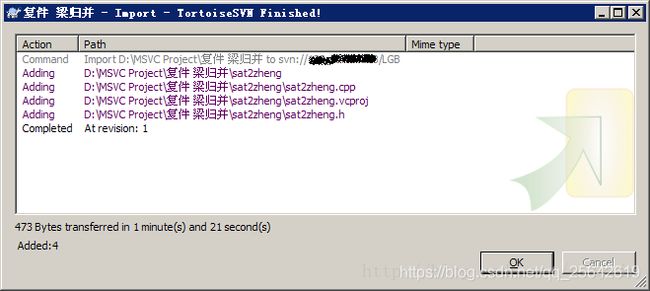
只保留源码和项目文件,右键单击 “复件 梁归并” ,SVN IMPORT


按 ok 成功:
6.单表数据备份
单表数据备份(mysql)
单表数据备份,每次只能备份一张表,而且只能备份数据,不能备份表结构。
通常的使用场景为:将表中的数据导出到文件。
备份方法:从表中选出一部分数据保存到外部的文件中,
select */字段列表 + into outfile + ‘文件存储路径’ + from 数据源;
在这里,使用单表数据备份有一个前提,那就是:导出的外部文件不存在,即文件存储路径下的文件不存在。
执行如下 SQL 语句,进行测试:
– 单表数据备份
select * into outfile ‘D:/CoderLife/testMySQL/class.txt’ from class;

如上图所示,SQL 语句已经执行成功。在这里,如果我们遇到:
ERROR 1290 (HY000): The MySQL server is running with the –secure-file-priv option so it cannot execute this statement.
这个错误,可以通过查看「详述 MySQL 导出数据遇到 secure-file-priv 的问题」进行解决。
为了验证是否真的将class表中的数据导出到指定位置,我们可以到该路径下进行确认:

如上图所示,显然我们已经将class表中的数据导出到本地啦!不过在这里,有一点需要我们特别注意,那就是:对于从数据库导出的文件,我们最好用EditPlus等编辑工具打开,防止乱码。
此外,对于上述用于导出表中数据的 SQL 语法,其实我们可以颠倒书写顺序,也没有问题,例如:
select */字段列表 + from 数据源 + into outfile + ‘文件存储路径’;
执行如下 SQL 语句,进行测试:
– 单表数据备份
select * from class into outfile ‘D:/CoderLife/testMySQL/class2.txt’;

接下来,我们学习一些用于单表数据备份的高级操作,即自己指定字段和行的处理方式。
基本语法:select */字段列表 + into outfile + ‘文件存储路径’ + fields + 字段处理 + lines + 行处理 + from 数据源;
字段处理:
enclosed by:指定字段用什么内容包裹,默认是,空字符串;
terminated by:指定字段以什么结束,默认是\t,Tab键;
escaped by:指定特殊符号用什么方式处理,默认是\,反斜线转义。
行处理:
starting by:指定每行以什么开始,默认是,空字符串;
terminated by:指定每行以什么结束,默认是\r\n,换行符。
执行如下 SQL 语句,进行测试:
– 指定单表数据备份处理方式
select * into outfile ‘D:/CoderLife/testMySQL/class3.txt’
– 字段处理
fields
enclosed by ‘"’
terminated by ‘|’
linesstarting by ‘START:’
from class ;

如上图所示,显然导出文件class3.txt按照我们指定的格式进行输出啦!在前面,我们已经测试了各种单表数据备份的方式,现在我们删除数据,并尝试还原数据,即将保持在外部的数据重新恢复到数据表中。But,由于单表数据备份进能备份数据,因此如果表结构不存在,则不能进行还原。
基本语法:load data infile + ‘文件存储路径’ + into table + 表名 + [字段列表] + fields + 字段处理 + lines + 行处理;
执行如下 SQL 语句,进行测试:
– 删除表 class 中的数据
delete from class;
– 查看表 class 中的数据
select * from class;
– 还原表 class 中的数据
load data infile 'D:/CoderLife/testMySQL/class3.txt’into table class
– 字段处理
fieldsenclosed by '"'terminated by '|'linesstarting by ‘START:’;
– 查看表 class 中的数据
select * from class;
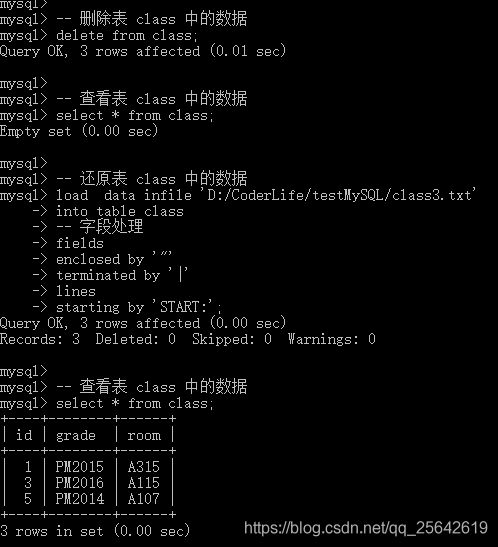
如上图所示,显然在我们删除表class中的数据之后,还原数据成功。
温馨提示:符号[]括起来的内容,表示可选项;符号+,则表示连接的意思。
oracle部分单表备份
Oracle 备份、恢复单表或多表数据步骤
Oracle 备份、恢复单表或多表数据步骤,适用于 Oracle 8、9、10。
*备份单表或多表数据:
[java] view plain copy
print?
exp user/password@server file=filefullpathname log=logfullpathname tables=(tablespacename.table1,tablespacename.table2,…)
例如,作者要导出用户名为 sybj,密码为 sybj,sid 为 lyzz,表空间 sybj 下表 table1、table2 中的数据,win 下 CMD 命令如下:
[java] view plain copy
print?
F:/oralce/ora92/bin>exp sybj/sybj@lyzz file=G:/tmps/test009.tmp log=G:/tmps/test009.log tables=(sybj.table1,sybj.table2)
备份文件 test009.tmp 将会在目录 G:/tmps/ 下生成。
*单表或多表数据恢复:
如果被恢复的表已经存在,应该先将其删除,不然报“IMP-0015”错误,导入失败。单表或多表数据恢复命令如下:
imp user/password@server file=filefullpathname log=logfullpathname full=y
仍以上面的例子,将 table1、table2 数据恢复,win 下 CMD 命令如下:
F:/oralce/ora92/bin>imp sybj/sybj@lyzz file=G:/tmps/test009.tmp log=G:/tmps/test009imp.log full=y
7.shiro 认证流程
1、首先调用Subject.login(token)进行登录,其会自动委托给Security Manager,调用之前必须通过SecurityUtils. setSecurityManager()设置;
2、SecurityManager负责真正的身份验证逻辑;它会委托给Authenticator进行身份验证;
3、Authenticator才是真正的身份验证者,Shiro API中核心的身份认证入口点,此处可以自定义插入自己的实现;
4、Authenticator可能会委托给相应的AuthenticationStrategy进行多Realm身份验证,默认ModularRealmAuthenticator会调用AuthenticationStrategy进行多Realm身份验证;
5、Authenticator 会把相应的token 传入Realm,从Realm 获取身份验证信息,如果没有返回/抛出异常表示身份验证失败了。此处可以配置多个Realm,将按照相应的顺序及策略进行访问。
8.HashMap和Hashtable的区别
HashMap和Hashtable都实现了Map接口,但决定用哪一个之前先要弄清楚它们之间的分别。主要的区别有:线程安全性,同步(synchronization),以及速度。
HashMap几乎可以等价于Hashtable,除了HashMap是非synchronized的,并可以接受null(HashMap可以接受为null的键值(key)和值(value),而Hashtable则不行)。
HashMap是非synchronized,而Hashtable是synchronized,这意味着Hashtable是线程安全的,多个线程可以共享一个Hashtable;而如果没有正确的同步的话,多个线程是不能共享HashMap的。Java 5提供了ConcurrentHashMap,它是HashTable的替代,比HashTable的扩展性更好。
另一个区别是HashMap的迭代器(Iterator)是fail-fast迭代器,而Hashtable的enumerator迭代器不是fail-fast的。所以当有其它线程改变了HashMap的结构(增加或者移除元素),将会抛出ConcurrentModificationException,但迭代器本身的remove()方法移除元素则不会抛出ConcurrentModificationException异常。但这并不是一个一定发生的行为,要看JVM。这条同样也是Enumeration和Iterator的区别。
由于Hashtable是线程安全的也是synchronized,所以在单线程环境下它比HashMap要慢。如果你不需要同步,只需要单一线程,那么使用HashMap性能要好过Hashtable。
HashMap不能保证随着时间的推移Map中的元素次序是不变的。
要注意的一些重要术语:
- sychronized意味着在一次仅有一个线程能够更改Hashtable。就是说任何线程要更新Hashtable时要首先获得同步锁,其它线程要等到同步锁被释放之后才能再次获得同步锁更新Hashtable。
- Fail-safe和iterator迭代器相关。如果某个集合对象创建了Iterator或者ListIterator,然后其它的线程试图“结构上”更改集合对象,将会抛出ConcurrentModificationException异常。但其它线程可以通过set()方法更改集合对象是允许的,因为这并没有从“结构上”更改集合。但是假如已经从结构上进行了更改,再调用set()方法,将会抛出IllegalArgumentException异常。
- 结构上的更改指的是删除或者插入一个元素,这样会影响到map的结构。
我们能否让HashMap同步?
HashMap可以通过下面的语句进行同步:
Map m = Collections.synchronizeMap(hashMap);
结论
Hashtable和HashMap有几个主要的不同:线程安全以及速度。仅在你需要完全的线程安全的时候使用Hashtable,而如果你使用Java 5或以上的话,请使用ConcurrentHashMap吧。