挂着高级工程师的头衔,连延时消息都搞不定,你这样迟早会被别人卷死!
背景
项目涉及到了一个自动过单的问题:24小时后无人操作,自动通过什么的,所以,为了实现这个功能,决定采用延时队列。
那么,如何实现一个延时队列呢?我去各博客进行了技术调研,整理了一下几种方法,供大家参考,如果有什么更加好的方法,也欢迎评论区讨论。
注意:本文只是常见的技术方案的讨论,大家选中方案以后,可以根据方案名去找开源的实现代码,这里就不提供代码了。
技术方案
一、基于redis的zset延时队列
原理:
Redis中的ZSet是一个有序的Set,内部使用HashMap和跳表(SkipList)来保证数据的存储和有序。
zset有一个score值,可以在添加数据的时候,使用zadd把score写成未来某个时刻的unix时间戳,然后按照时间大小进行排序,定时去查询redis的zset队列首部,即可查询到最早过期的数据,进行处理,以此完成延时逻辑。
底层:
HashMap里放的是成员到score的映射,而跳跃表里存放的是所有的成员,排序依据是HashMap里存的score,使用跳跃表的结构可以获得比较高的查找效率,并且在实现上比较简单。
具体使用:
消费者使用zrangeWithScores获取优先级最高的(最早开始的的)任务。
注意,zrangeWithScores并不是取出来,只是看一下并不删除,类似于Queue的peek方法。
程序对最早的这个消息进行验证,是否到达要运行的时间,如果是则执行,然后删除zset中的数据,如果不是,则继续等待。
命令详情:
其中,min可以设置为0,max为当前时间戳,这样每次获取到的结果为到目前为止过期的所有任务。min,max代表的是score范围。在范围内的数据才会读取出来。
优点:
实现简单:
redis已经设计好了数据结构,保证了顺序
解耦:
把任务、任务发起者、任务执行者的三者分开,逻辑更加清晰,程序强壮性提升,有利于任务发起者和执行者各自迭代,适合多人协作
异常恢复:
由于使用Redis作为消息通道,消息都存储在Redis中。
如果发送程序或者任务处理程序挂了,重启之后,还有重新处理数据的可能性。
分布式:
如果数据量较大,程序执行时间比较长,我们可以针对任务发起者和任务执行者进行分布式部署。
特别注意任务的执行者,也就是Redis的接收方需要考虑分布式锁的问题。
缺点:
由于zrangeWithScores 和 zrem是先后使用,所以有可能有并发问题,即两个线程或者两个进程都会拿到一样的一样的数据,然后重复执行,最后又都会删除。
如果是单机多线程执行,或者分布式环境下,需要使用Redis事务,也可以使用由Redis实现的分布式锁
消费延迟由轮训速度决定,当消息过多会影响其他功能对redis的使用
二、基于redis的过期回调实现延时队列
原理:
Redis的key过期回调事件,也能达到延迟队列的效果,简单来说我们开启监听key是否过期的事件,一旦key过期会触发一个callback事件。
实现:
修改redis.conf文件开启notify-keyspace-events Ex,然后消费延时任务的消费者,需要开启一个线程监听redis。
java是可以通过spring注入Bean RedisMessageListenerContainer即可实现。
优点:
开发简单:
redis自己已经实现了主要的功能
主动通知:
不需要消费者自己去轮询
缺点:
返回的数据主要是key,没有value,需要设计好key来
多服务的情况下,一个key过期,通知所有开启监听者,通信性能浪费
三、定时器轮询遍历数据库记录
原理:
所有的订单或者所有的命令一般都会存储在数据库中,我们会起一个线程定时去扫数据库或者一个数据库定时Job,找到那些超时的数据,直接更新状态,或者拿出来执行一些操作。
优点:
开发周期短
缺点:
查找和更新对会占用很多时间,轮询频率高的话甚至会影响数据入库
另一方面,对于订单这类数据,我们也许会遇到分库分表,那上述方案就会变得过于复杂,得不偿失
四、基于时间轮TimeWheel实现
原理:
底层为一个环形链表或者一个数组,每个节点表示一个时间,任务会以链表的形势挂在时间轮上面。
每x秒转动一次,并且会遍历链表,执行挂在上面的到期任务。
原始时间轮:
如下图一个轮子,有8个“槽”,可以代表未来的一个时间。
如果以秒为单位,中间的指针每隔一秒钟转动到新的“槽”上面,就好像手表一样。
如果当前指针指在1上面,我有一个任务需要4秒以后执行,那么这个执行的线程回调或者消息将会被放在5上。
那如果需要在20秒之后执行怎么办,由于这个环形结构槽数只到8,如果要20秒,指针需要多转2圈。
位置是在2圈之后的5上面(20 % 8 + 1)。
这个圈数需要记录在槽中的数据结构里面。
这个数据结构最重要的是两个指针,一个是触发任务的函数指针,另外一个是触发的总第几圈数。
时间轮可以用简单的数组或者是环形链表来实现。
优点:

相比DelayQueue的数据结构,时间轮在算法复杂度上有一定优势。
DelayQueue由于涉及到排序,需要调堆,插入和移除的复杂度是O(lgn),而时间轮在插入和移除的复杂度都是O(1)。
优点是我们可以使用一个线程监控很多的定时任务
缺点:
实现较为复杂,时间轮只是一种算法,其他的问题,比如三高(高可用、高性能、高并发)中的高可用和高性能需要自己实现
缺点是时间粒度由节点间隔确定,所有的任务的时间间隔需要以同样的粒度定义,比如时间间隔是1小时,则我们定义定时任务的单位就为小时,无法精确到分钟和秒。
五、基于RabbitMQ 消息队列的延时队列
原理:
利用RabbitMQ 的TTL(消息存活时间)和DLX(死信转发)模拟出延时队列的效果。
RabbitMQ可以针对Queue和Message设置 x-message-tt,来控制消息的生存时间,如果超时,则消息变为dead letter。
然后,RabbitMQ的Queue可以配置x-dead-letter-exchange 和x-dead-letter-routing-key(可选)两个参数,如果队列内出现了dead letter,则按照这两个参数重新路由。
这时候,利用DLX,当消息在一个队列中变成死信后,它能被重新publish到另一个Exchange,这时候消息就可以重新被消费。
总而言之,利用DLX,当消息在一个队列中变成死信后,它能被重新publish到另一个Exchange,这时候消息就可以重新被消费。
优点:
使用消息队列保证了消息的安全,可以比较容易的实现精确一次消费、至少一次消费、最多一次消费的需求,使用简单。
缺点:
可能有内存问题,而且比较重
RabbitMQ的需要进行额外配置,添加死信消息队列和DLX
六、基于RocketMQ的延时消息队列
原理:
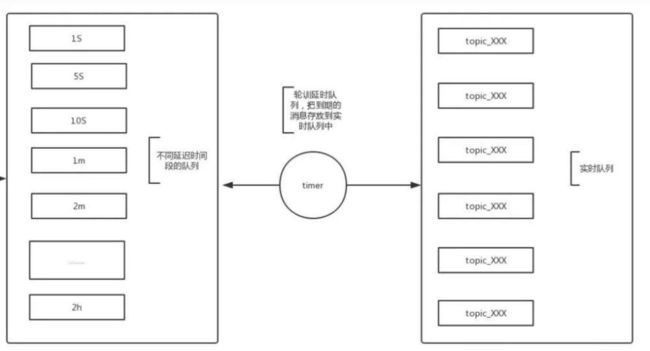
rocketmq发送延时消息时,先把消息按照延迟时间段发送到指定的队列中(每种延迟时间段的消息都存放到同一个队列中),然后通过一个Timer定时器进行轮训这些队列,查看消息是否到期,如果到期就把这个消息发送到指定topic的队列中。
这样的好处是同一队列中的消息延时时间是一致的,还有一个好处是这个队列中的消息时按照消息到期时间进行递增排序的,说的简单直白就是队列中消息越靠前的到期时间越早。
七、基于Quartz的延时队列
原理:
quartz是一个企业级的开源的任务调度框架,quartz内部使用TreeSet来保存Trigger。
Java中的TreeSet是使用TreeMap实现,TreeMap是一个红黑树实现。
红黑树的插入和删除复杂度都是logN,和最小堆相比各有千秋,最小堆插入比红黑树快,删除顶层节点比红黑树慢。
优点:
有专门的任务调度线程,和任务执行线程池。
缺点:
quartz功能强大,主要是用来执行周期性的任务,当然也可以用来实现延迟任务。
如果只是实现一个简单的基于内存的延时任务的话,quartz就稍显庞大。
八、基于DelayQueue的延时队列
原理:
实现原理主要是利用了PriorityQueue这个类,内部是一个最小堆,满足一定条件的时候,会返回过期数据,让阻塞等待数据的线程继续执行,以此实现的延时功能。
之所以要用到PriorityQueue,主要是需要排序,也许后插入的消息需要比队列中的其他消息提前触发,那么这个后插入的消息就需要最先被消费者获取,这就需要排序功能。
PriorityQueue内部使用最小堆来实现排序队列,队首的,最先被消费者拿到的就是最小的那个,使用最小堆让队列在数据量较大的时候比较有优势。
使用最小堆来实现优先级队列主要是因为最小堆在插入和获取时,时间复杂度相对都比较好,都是O(logN)。
优点:
开发较为简单,有现成的类使用,虽然是单机,但是也可以多线程生产和消费,提高效率。
缺点:
java实现,单机任务
可靠性低,需要自己实现持久化逻辑,内存占用问题
九、基于ScheduledExecutorService的延时队列
原理:
ScheduledExecutorService是JDK自带的一种线程池,它能调度一些命令在一段时间之后执行(延时队列),或者周期性的执行。
ScheduledExecutorService的实现类ScheduledThreadPoolExecutor提供了一种并行处理的模型,简化了线程的调度。
DelayedWorkQueue是类似DelayQueue的实现,也是基于最小堆的、线程安全的数据结构,所以会有上例排序后输出的结果。
和直接使用delayQueue相比,使用DelayQueue获取消息后触发事件都会实用多线程的方式执行,以保证其他事件能准时进行。
而ScheduledThreadPoolExecutor就是对这个过程进行了封装,让大家更加方便的使用,同时在加强了部分功能,比如定时触发命令。
优点:
单机情况下,其支持多线程,并且对于任务的多线程支持更加方便。
缺点:
java实现,适用单机任务