【深度学习】【分布式训练】Collective通信操作及Pytorch示例
相关博客
【深度学习】【分布式训练】Collective通信操作及Pytorch示例
【自然语言处理】【大模型】大语言模型BLOOM推理工具测试
【自然语言处理】【大模型】GLM-130B:一个开源双语预训练语言模型
【自然语言处理】【大模型】用于大型Transformer的8-bit矩阵乘法介绍
【自然语言处理】【大模型】BLOOM:一个176B参数且可开放获取的多语言模型
大模型时代,单机已经无法完成先进模型的训练和推理,分布式训练和推理将会是必然的选择。各类分布式训练和推断工具都会使用到Collective通信。网络上大多数的教程仅简单介绍这些操作的原理,没有代码示例来辅助理解。本文会介绍各类Collective通信操作,并展示pytorch中如何使用。
一、Collective通信操作
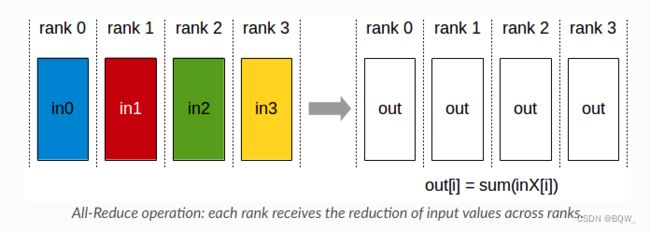
1. AllReduce
将各个显卡的张量进行聚合(sum、min、max)后,再将结果写回至各个显卡。
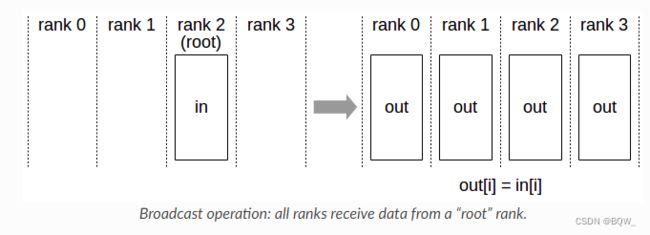
2. Broadcast
将张量从某张卡广播至所有卡。
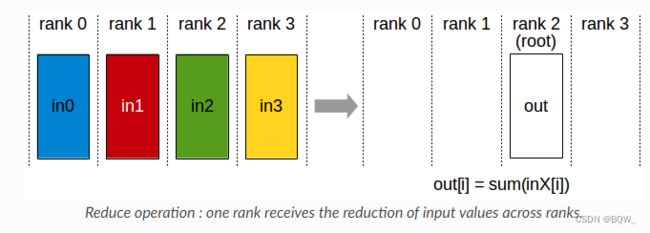
3. Reduce
执行同AllReduce相同的操作,但结果仅写入具有的某个显卡。
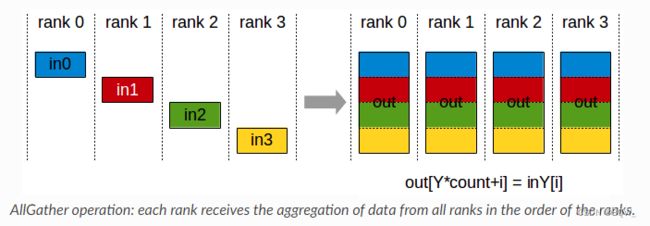
4. AllGather
每个显卡上有一个大小为N的张量,共有k个显卡。经过AllGather后将所有显卡上的张量合并为一个 N × k N\times k N×k的张量,然后将结果分配至所有显卡上。
5. ReduceScatter
执行Reduce相同的操作,但是结果会被分散至不同的显卡。
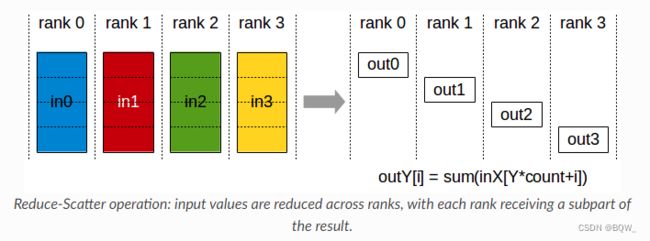
二、Pytorch示例
pytorch的分布式包torch.distributed能够方便的实现跨进程和跨机器集群的并行计算。本文代码运行在单机双卡服务器上,并基于下面的模板来执行不同的分布式操作。
import os
import torch
import torch.distributed as dist
import torch.multiprocessing as mp
def init_process(rank, size, fn, backend='nccl'):
"""
为每个进程初始化分布式环境,保证相互之间可以通信,并调用函数fn。
"""
os.environ['MASTER_ADDR'] = '127.0.0.1'
os.environ['MASTER_PORT'] = '29500'
dist.init_process_group(backend, rank=rank, world_size=size)
fn(rank, size)
def run(world_size, func):
"""
启动world_size个进程,并执行函数func。
"""
processes = []
mp.set_start_method("spawn")
for rank in range(world_size):
p = mp.Process(target=init_process, args=(rank, world_size, func))
p.start()
processes.append(p)
for p in processes:
p.join()
if __name__ == "__main__":
run(2, func) # 这里的func随后会被替换为不同的分布式示例函数
pass
先对上面的模板做一些简单的介绍。
- 函数
run会根据传入的参数world_size,生成对应数量的进程。每个进程都会调用init_process来初始化分布式环境,并调用传入的分布式示例函数。 torch.distributed.init_process_group(),该方法负责各进程之间的初始协调,保证各进程都会与master进行握手。该方法在调用完成之前会一直阻塞,并且后续的所有操作都必须在该操作之后。调用该方法时需要初始化下面的4个环境变量:- MASTER_PORT:rank 0进程所在机器上的空闲端口;
- MASTER_ADDR:rank 0进程所在机器上的IP地址;
- WORLD_SIZE:进程总数;
- RANK:每个进程的RANK,所以每个进程知道其是否是master;
1. 点对点通信
在介绍其他collective通信之前,先看一个简单的点对点通信实现。
def p2p_block_func(rank, size):
"""
将rank src上的tensor发送至rank dst(阻塞)。
"""
src = 0
dst = 1
group = dist.new_group(list(range(size)))
# 对于rank src,该tensor用于发送
# 对于rank dst,该tensor用于接收
tensor = torch.zeros(1).to(torch.device("cuda", rank))
if rank == src:
tensor += 1
# 发送tensor([1.])
# group指定了该操作所见进程的范围,默认情况下是整个world
dist.send(tensor=tensor, dst=1, group=group)
elif rank == dst:
# rank dst的tensor初始化为tensor([0.]),但接收后为tensor([1.])
dist.recv(tensor=tensor, src=0, group=group)
print('Rank ', rank, ' has data ', tensor)
if __name__ == "__main__":
run(2, p2p_block_func)
p2p_block_func实现从rank 0发送一个tensor([1.0])至rank 1,该操作在发送完成/接收完成之前都会阻塞。
下面是一个不阻塞的版本:
def p2p_unblock_func(rank, size):
"""
将rank src上的tensor发送至rank dst(非阻塞)。
"""
src = 0
dst = 1
group = dist.new_group(list(range(size)))
tensor = torch.zeros(1).to(torch.device("cuda", rank))
if rank == src:
tensor += 1
# 非阻塞发送
req = dist.isend(tensor=tensor, dst=dst, group=group)
print("Rank 0 started sending")
elif rank == dst:
# 非阻塞接收
req = dist.irecv(tensor=tensor, src=src, group=group)
print("Rank 1 started receiving")
req.wait()
print('Rank ', rank, ' has data ', tensor)
if __name__ == "__main__":
run(2, p2p_unblock_func)
p2p_unblock_func是非阻塞版本的点对点通信。使用非阻塞方法时,因为不知道数据何时送达,所以在req.wait()完成之前不要对发送/接收的tensor进行任何操作。
2. Broadcast
def broadcast_func(rank, size):
src = 0
group = dist.new_group(list(range(size)))
if rank == src:
# 对于rank src,初始化tensor([1.])
tensor = torch.zeros(1).to(torch.device("cuda", rank)) + 1
else:
# 对于非rank src,初始化tensor([0.])
tensor = torch.zeros(1).to(torch.device("cuda", rank))
# 对于rank src,broadcast是发送;否则,则是接收
dist.broadcast(tensor=tensor, src=0, group=group)
print('Rank ', rank, ' has data ', tensor)
if __name__ == "__main__":
run(2, broadcast_func)
broadcast_func会将rank 0上的tensor([1.])广播至所有的rank上。
3. Reduce与Allreduce
def reduce_func(rank, size):
dst = 1
group = dist.new_group(list(range(size)))
tensor = torch.ones(1).to(torch.device("cuda", rank))
# 对于所有rank都会发送, 但仅有dst会接收求和的结果
dist.reduce(tensor, dst=dst, op=dist.ReduceOp.SUM, group=group)
print('Rank ', rank, ' has data ', tensor)
if __name__ == "__main__":
run(2, reduce_func)
reduce_func会对group中所有rank的tensor进行聚合,并将结果发送至rank dst。
def allreduce_func(rank, size):
group = dist.new_group(list(range(size)))
tensor = torch.ones(1).to(torch.device("cuda", rank))
# tensor即用来发送,也用来接收
dist.all_reduce(tensor, op=dist.ReduceOp.SUM, group=group)
print('Rank ', rank, ' has data ', tensor)
if __name__ == "__main__":
run(2, allreduce_func)
allreduce_func将group中所有rank的tensor进行聚合,并将结果发送至group中的所有rank。
4. Gather与Allgather
def gather_func(rank, size):
dst = 1
group = dist.new_group(list(range(size)))
# 该tensor用于发送
tensor = torch.zeros(1).to(torch.device("cuda", rank)) + rank
gather_list = []
if rank == dst:
# gather_list中的tensor数量应该是size个,用于接收其他rank发送来的tensor
gather_list = [torch.zeros(1).to(torch.device("cuda", dst)) for _ in range(size)]
# 仅在rank dst上需要指定gather_list
dist.gather(tensor, gather_list=gather_list, dst=dst, group=group)
else:
# 非rank dst,相当于发送tensor
dist.gather(tensor, dst=dst, group=group)
print('Rank ', rank, ' has data ', gather_list)
if __name__ == "__main__":
run(2, gather_func)
gather_func从group中所有rank上收集tensor,并发送至rank dst。(相当于不进行聚合操作的reduce)
def allgather_func(rank, size):
group = dist.new_group(list(range(size)))
# 该tensor用于发送
tensor = torch.zeros(1).to(torch.device("cuda", rank)) + rank
# gether_list用于接收各个rank发送来的tensor
gather_list = [torch.zeros(1).to(torch.device("cuda", rank)) for _ in range(size)]
dist.all_gather(gather_list, tensor, group=group)
# 各个rank的gather_list均一致
print('Rank ', rank, ' has data ', gather_list)
if __name__ == "__main__":
run(2, allgather_func)
allgather_func从group中所有rank上收集tensor,并将收集到的tensor发送至所有group中的rank。
5. Scatter与ReduceScatter
def scatter_func(rank, size):
src = 0
group = dist.new_group(list(range(size)))
# 各个rank用于接收的tensor
tensor = torch.empty(1).to(torch.device("cuda", rank))
if rank == src:
# 在rank src上,将tensor_list中的tensor分发至不同的rank上
# tensor_list:[tensor([1.]), tensor([2.])]
tensor_list = [torch.tensor([i + 1], dtype=torch.float32).to(torch.device("cuda", rank)) for i in range(size)]
# 将tensor_list发送至各个rank
# 接收属于rank src的那部分tensor
dist.scatter(tensor, scatter_list=tensor_list, src=0, group=group)
else:
# 接收属于对应rank的tensor
dist.scatter(tensor, scatter_list=[], src=0, group=group)
# 每个rank都拥有tensor_list中的一部分tensor
print('Rank ', rank, ' has data ', tensor)
if __name__ == "__main__":
run(2, scatter_func)
scatter_func会将rank src中的一组tensor逐个分发至其他rank上,每个rank持有的tensor不同。
def reduce_scatter_func(rank, size):
group = dist.new_group(list(range(size)))
# 用于接收的tensor
tensor = torch.empty(1).to(torch.device("cuda", rank))
# 用于发送的tensor列表
# 对于每个rank,有tensor_list=[tensor([0.]), tensor([1.])]
tensor_list = [torch.Tensor([i]).to(torch.device("cuda", rank)) for i in range(size)]
# step1. 经过reduce的操作会得到tensor列表[tensor([0.]), tensor([2.])]
# step2. tensor列表[tensor([0.]), tensor([2.])]分发至各个rank
# rank 0得到tensor([0.]),rank 1得到tensor([2.])
dist.reduce_scatter(tensor, tensor_list, op=dist.ReduceOp.SUM, group=group)
print('Rank ', rank, ' has data ', tensor)
if __name__ == "__main__":
run(2, reduce_scatter_func)
参考资料
https://docs.nvidia.com/deeplearning/nccl/user-guide/docs/usage/collectives.html
https://pytorch.org/tutorials/intermediate/dist_tuto.html#collective-communication
https://pytorch.org/docs/stable/distributed.html#collective-functions