Hadoop HDFS分布式文件系统原理及应用介绍
HDFS有着高容错性特点,且设计用来部署在低廉的硬件上,提供高吞吐量来访问应用程序的数据,适合那些有着超大数据集的应用程序。HDFS放宽了POSIX的要求,可以实现流的形式访问文件系统中的数据。
Hadoop分布式文件系统HDFS是一种被设计成适合运行在通用硬件上的分布式文件系统。HDFS是一个高度容错性的系统,适合部署在廉价的机器上。它能提供高吞吐量的数据访问非常适合大规模数据集上的应用。
HDFS概念
HDFS(Hadoop Distributed File System)是 Apache Hadoop 项目的一个子项目. Hadoop 非常适于存储大型数据 (比如 TB 和 PB), 其就是使用 HDFS 作为存储系统. HDFS 使用多台计算机存储文件, 并且提供统一的访问接口。
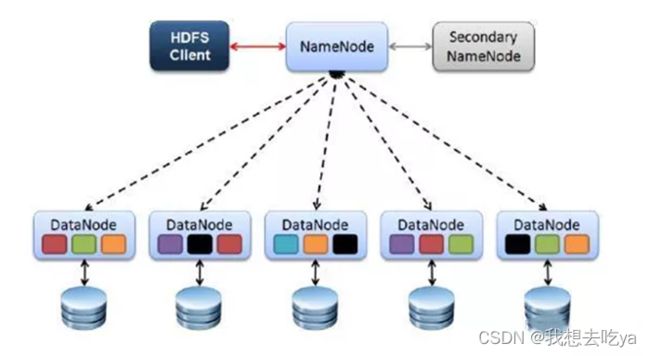
HDFS的四个基本组件:HDFS Client、NameNode、DataNode和Secondary NameNode。
HDFS采用主从结构模型,一个HDFS集群是由一个NameNode和若干个DataNode组成的。其中NameNode作为主服务器,管理文件系统的命名空间和客户端对文件的访问操作;集群中的DataNode管理存储的数据。
Client
Client是客户端。HDFS Client文件切分。文件上传 HDFS 的时候,Client 将文件切分成 一个一个的Block,然后进行存储。Client 提供一些命令来管理 和访问HDFS,比如启动或者关闭HDFS。
NameNode
NameNode就是 master,它是一个主管、管理者。管理 HDFS 元数据(文件路径,文件的大小,文件的名字,文件权限,文件的block切片信息)。
NameNode管理 Block 副本策略:默认 3 个副本,处理客户端读写请求。
DataNode
DataNode就是Slave。NameNode下达命令,DataNode 执行实际的操作。DataNode存储实际的数据块,执行数据块的读/写操作。定时向namenode汇报block信息。
Secondary NameNode
SecondaryNameNode不是NameNode的备份。当NameNode挂掉的时候,它并不能马上替换NameNode并提供服务。
辅助 NameNode,分担其工作量。在紧急情况下,可辅助恢复 NameNode。
副本机制
HDFS被设计成能够在一个大集群中跨机器可靠地存储超大文件。它将每个文件存储成一系列的数据块,这个数据块被称为block,除了最后一个,所有的数据块都是同样大小的。
为了容错,文件的所有block都会有副本。每个文件的数据块大小和副本系数都是可配置的。
在hadoop2 当中, 文件的 block 块大小默认是 「128M」(134217728字节)。
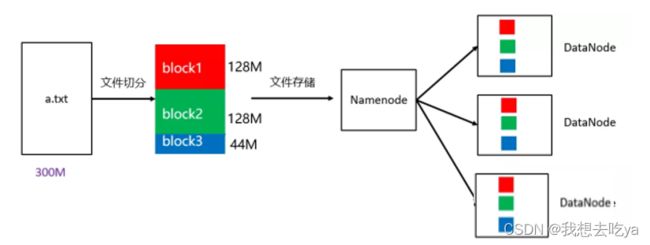
如图所示,一个大小为300M的a.txt上传到HDFS中,需要进行128M的切分,不足128M分为到另一block中。
猎聘大数据研究院发布了《2022未来人才就业趋势报告》
从排名来看,2022年1-4月各行业中高端人才平均年薪来看,人工智能行业中高端人才平均年薪最高,为31.04万元;金融行业中高端人才以27.69万元的平均年薪位居第二;通信、大数据行业中高端人才平均年薪分别为27.51万元、25.23万元,位列第三、第四;IT/互联网行业中高端人才平均年薪23.02万元,位列第七。
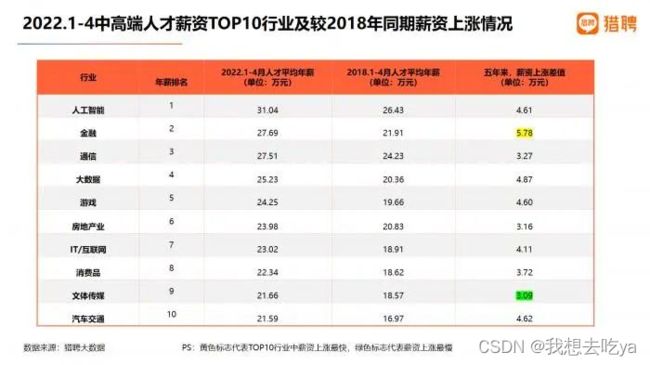
图表来源:《2022未来人才就业趋势报告》
如果你觉得很高,被平均了这样?那么打开Boss直聘,搜大数据工程师:
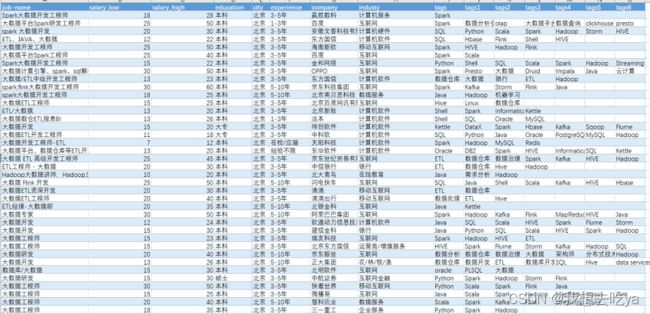
我们来做下数据分析:
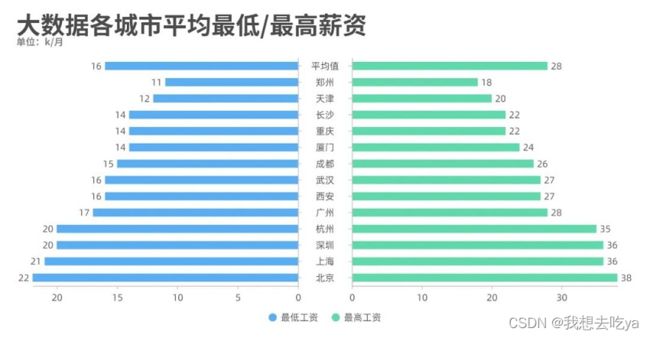
薪资那一列都有一个最低薪资和最高薪资,我们通过不同城市来对比分析一下,发现北京的工资水平最高,最低为22k,最高为38k。
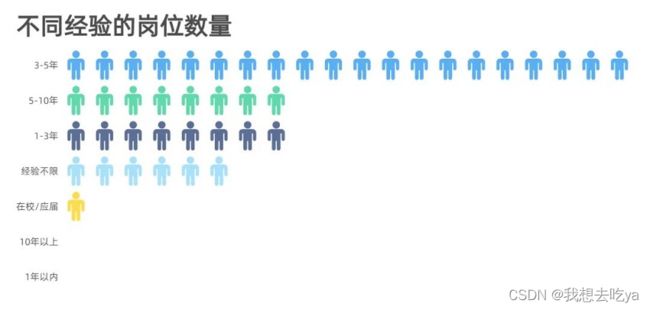
工作年限也是一个制约工资水平的很大因素,从图中可以看出,即使是刚毕业,也能达到一个11-20k的薪资范围。

而学历要求来说,大部分为本科,其次为大专和硕士,其他比较少,以至于在图中并没有显示出来。
企业对不同岗位的要求以3-5年的居多,企业当然是需要有一定工作经验的员工,但是在实际招聘中,如果你有项目经验,且理论知识没问题,企业也会放宽条件。
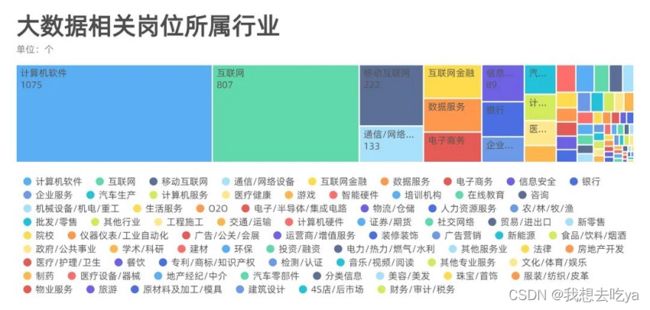
分析不同行业, 我们发现,大数据岗位需求分布在各行各业,主要还是在计算机软件和互联网最多,也有可能是这个招聘软件决定的,毕竟Boss直聘还是以互联网行业为主。
来看看哪些公司在招聘大数据相关岗位,从这个超过15的数量来看,华为,腾讯,阿里,字节,这些大厂对这个岗位的需求量还是很大的。

那么这些岗位都需要什么技能呢?Spark,Hadoop,数据仓库,Python,SQL,Mapreduce,Hbase等等

根据国内的发展形势,大数据未来的发展前景会非常好。自 2018 年企业纷纷开始数字化转型,一二线城市对大数据领域的人才需求非常强烈,未来几年,三四线城市的人才需求也会大增。
在大数据领域,国内发展的比较晚,从 2016 年开始,仅有 200 多所大学开设了大数据相关的专业,也就是说 2020 年第一批毕业生才刚刚步入社会,我国市场环境处于急需大数据人才但人才不足的阶段,所以未来大数据领域会有很多的就业机遇。
薪资高、缺口大,自然成为职场人的“薪”选择!
任何学习过程都需要一个科学合理的学习路线,才能够有条不紊的完成我们的学习目标。Python+大数据所需学习的内容纷繁复杂,难度较大,为大家整理了一个全面的Python+大数据学习路线图,帮大家理清思路,攻破难关!
Python+大数据学习路线图详细介绍
第一阶段 大数据开发入门
学前导读:从传统关系型数据库入手,掌握数据迁移工具、BI数据可视化工具、SQL,对后续学习打下坚实基础。
1.大数据数据开发基础MySQL8.0从入门到精通
MySQL是整个IT基础课程,SQL贯穿整个IT人生,俗话说,SQL写的好,工作随便找。本课程从零到高阶全面讲解MySQL8.0,学习本课程之后可以具备基本开发所需的SQL水平。
2022最新MySQL知识精讲+mysql实战案例_零基础mysql数据库入门到高级全套教程
第二阶段 大数据核心基础
学前导读:学习Linux、Hadoop、Hive,掌握大数据基础技术。
2022版大数据Hadoop入门教程
Hadoop离线是大数据生态圈的核心与基石,是整个大数据开发的入门,是为后期的Spark、Flink打下坚实基础的课程。掌握课程三部分内容:Linux、Hadoop、Hive,就可以独立的基于数据仓库实现离线数据分析的可视化报表开发。
2022最新大数据Hadoop入门视频教程,最适合零基础自学的大数据Hadoop教程
第三阶段 千亿级数仓技术
学前导读:本阶段课程以真实项目为驱动,学习离线数仓技术。
数据离线数据仓库,企业级在线教育项目实战(Hive数仓项目完整流程)
本课程会、建立集团数据仓库,统一集团数据中心,把分散的业务数据集中存储和处理 ;目从需求调研、设计、版本控制、研发、测试到落地上线,涵盖了项目的完整工序 ;掘分析海量用户行为数据,定制多维数据集合,形成数据集市,供各个场景主题使用。
大数据项目实战教程_大数据企业级离线数据仓库,在线教育项目实战(Hive数仓项目完整流程)
第四阶段 PB内存计算
学前导读:Spark官方已经在自己首页中将Python作为第一语言,在3.2版本的更新中,高亮提示内置捆绑Pandas;课程完全顺应技术社区和招聘岗位需求的趋势,全网首家加入Python on Spark的内容。
1.python入门到精通(19天全)
python基础学习课程,从搭建环境。判断语句,再到基础的数据类型,之后对函数进行学习掌握,熟悉文件操作,初步构建面向对象的编程思想,最后以一个案例带领同学进入python的编程殿堂。
全套Python教程_Python基础入门视频教程,零基础小白自学Python必备教程
2.python编程进阶从零到搭建网站
学完本课程会掌握Python高级语法、多任务编程以及网络编程。
Python高级语法进阶教程_python多任务及网络编程,从零搭建网站全套教程
3.spark3.2从基础到精通
Spark是大数据体系的明星产品,是一款高性能的分布式内存迭代计算框架,可以处理海量规模的数据。本课程基于Python语言学习Spark3.2开发,课程的讲解注重理论联系实际,高效快捷,深入浅出,让初学者也能快速掌握。让有经验的工程师也能有所收获。
Spark全套视频教程,大数据spark3.2从基础到精通,全网首套基于Python语言的spark教程
4.大数据Hive+Spark离线数仓工业项目实战
通过大数据技术架构,解决工业物联网制造行业的数据存储和分析、可视化、个性化推荐问题。一站制造项目主要基于Hive数仓分层来存储各个业务指标数据,基于sparkSQL做数据分析。核心业务涉及运营商、呼叫中心、工单、油站、仓储物料。
全网首次披露大数据Spark离线数仓工业项目实战,Hive+Spark构建企业级大数据平台