第8章 高性能服务器程序框架
8.1 服务器模型
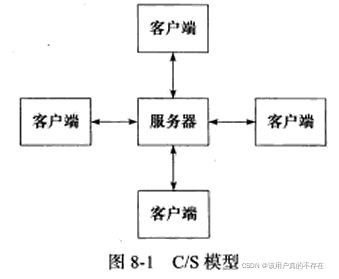
8.1.1 C/S模型
C/S(客户端/服务端)模型:所有客户端都通过访问服务器来获取所需的资源。如下图所示:
采用C/S 模型的TCP服务器和TCP客户端的工作流程图如下图所示,服务器同时监听多个客户端请求是通过select实现的:
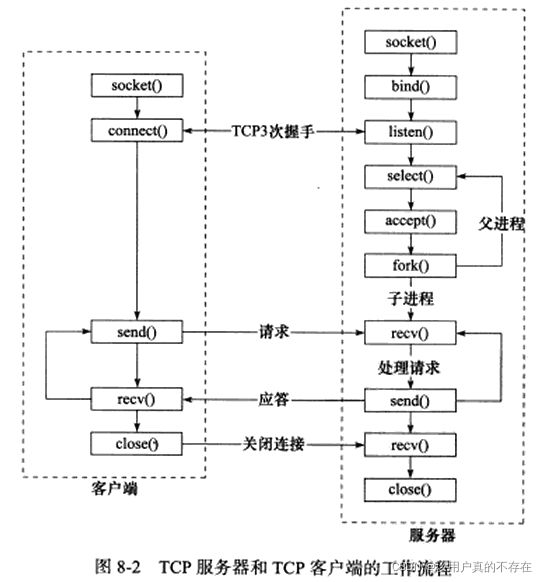
服务器启动后,首先创建一个或多个监听socket,并调用bind函数将其绑定到服务器感兴趣的端口上,然后调用listen等待客户端连接。
客服端调用connect 请求连接服务端,服务器调用accept函数接收它,并分配一个逻辑单元为新的连接服务。逻辑单元可以是新创建的子进程。逻辑单元读取客户端请求,处理该请求,然后将处理结果返回给客户端。
C/S模型优点:非常适合资源相对集中的场合,实现非常简单。
C/S模型缺点:服务器是通信的中心,当访问量过大时,可能所有客户端都将得到很慢的响应。P2P可解决这个问题。
8.1.2 P2P模型
P2P(peer to peer,点对点)模型如下图所示:
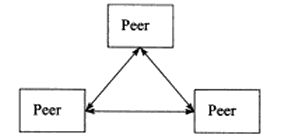
P2P模型优点:每台计算机在消耗服务的同时也给别人提供服务,使得资源能够充分共享。
P2P模型缺点:当用户之间传输的请求过多时,网络的负载将加重。
P2P模型的一个显著缺点是主机之间很难互相发现, 因此实际使用中 P2P模型通常带有一个专门的发现服务器提供查找服务,使每个客户端都唔那个尽快找到自己需要的资源。

8.2 服务器编程框架
服务器的基本框架如下图所示:
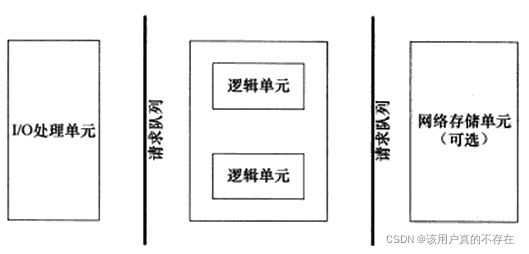
该图既能用来描述一台服务器,也能用来描述一个服务器机群。下图标是是对两种情况的各个模块的描述:

![]()
I/O处理单元:等待并接收新的客户连接,接收客户数据,将服务器响应的数据返回给客户端。
逻辑单元:通常是一个进程或线程,分析并处理客户数据,然后将结果传递给I/O处理单元或者直接发送给客户端。
网络存储单元:可以是数据库、缓存、文件,一台独立的服务器,但它不是必须的,如:ssh,telnet等登录服务就不需要这个单元。
请求队列:各个单元之间的通信方式的抽象。I/O处理单元接收到客户请求是,需要以某种方式通知一个逻辑单元来处理该请求。多个逻辑单元同时访问一个存储单元,也要使用某种机制来协调处理竞态条件。
8.3 I/O模型
阻塞和非阻塞的概念能应用于所有的文件描述符,包括socket,我们称阻塞的文件描述符为阻塞I/O,非阻塞的文件描述符为非阻塞I/O。
阻塞I/O:当用户程序执行 read ,线程会被阻塞,一直等到内核数据准备好,并把数据从内核缓冲区拷贝到应用程序的缓冲区中,当拷贝过程完成,read 才会返回。注意,阻塞等待的是「内核数据准备好」和「数据从内核态拷贝到用户态」这两个过程。socket基础API中,阻塞式的系统调用有accept、send、recv和connect(connect:需要阻塞等待三次握手的完成。accept:需要等待可用的已完成的连接,如果已完成连接队列为空,则被阻塞。)。
非阻塞I/O:非阻塞的 read 请求在数据未准备好的情况下立即返回,可以继续往下执行,此时应用程序不断轮询内核,直到数据准备好,内核将数据拷贝到应用程序缓冲区,read 调用才可以获取到结果。只有在事件已经发生的情况下操作非阻塞I/O(读写等),才能提高程序的效率。因此,非阻塞I/O通常要和其他/O通知机制一起使用,如I/O复用和SIGIO信号。
I/O复用是最常用的I/O通知机制。它是指:应用程序通过I/O复用函数想内核注册一组I/O事件,内核通过I/O复用函数把就绪的事件通知给应用程序。常用的I/O复用函数是select、poll、epoll。I/O复用函数本身是阻塞的,因为它们都需要在读写事件就绪后自己负责进行读写,也就是说这个读写过程是阻塞的。
SIGIO信号也能报告I/O事件。
阻塞I/O只能阻塞一个I/O操作,而I/O复用模型能够阻塞多个I/O操作,所以才叫做I/O多路复用。
阻塞I/O、I/O复用、信号驱动I/O都是同步I/O模型。
异步I/O的读写操作总是立即返回。用户可以直接对I/O执行读写操作,这些操作告诉内核用户读写缓冲区的位置,以及I/O操作完成之后内核通知应用程序的方式。
同步I/O与异步I/O区别:同步I/O要求用户代码自行执行I/O操作,即:将数据从内核缓冲区读入用户缓冲区,或将数据从用户缓冲区写入内核缓冲区;异步I/O则有内核来执行I/O操作,即:数据在内核缓冲区和用户缓冲区之间的移动是由内核在后台完成的。

8.4 两种高效的事件处理模式
同步I/O模型通常用于实现Reactor模式,异步I/O模型则用于实现Proactor模式。后面也可以使用同步I/O方式模拟出Proactor模式。
在网络服务和分布式对象中,对于网络中的某一个请求处理,我们比较关注的内容大致为:读取请求( Read request)、 解码请求(Decode request)、处理服务(Process service)、 编码答复(Encode reply)、 发送答复(Send reply)。但是每一步对系统的开销和效率又不尽相同。
8.4.1 传统的服务模式
对于传统的服务设计,每一个到来的请求,系统都会分配一个线程去处理,这样看似合乎情理,但是,当系统请求量瞬间暴增时,会直接把系统拖垮。因为在高并发情况下,系统创建的线程数量是有限的。传统系统设计如下图所示:
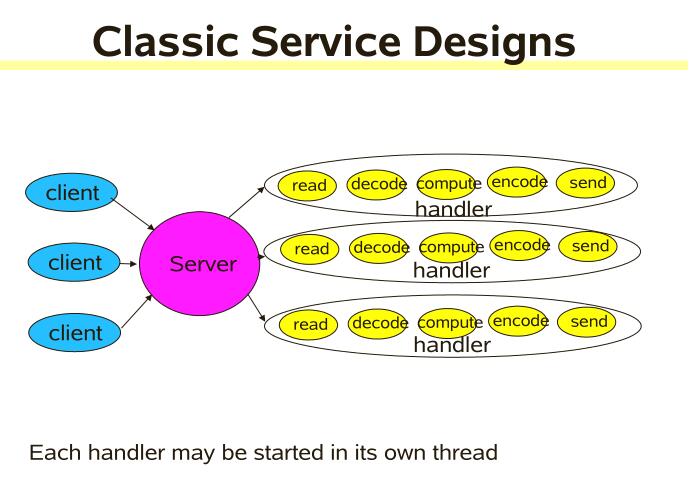
那有没有办法在只有当连接上有数据的时候,线程才去发起读请求呢?答案是有的,实现这一技术的就是 I/O 多路复用。
I/O 多路复用技术会用一个系统调用函数来监听我们所有关心的连接,也就说可以在一个监控线程里面监控很多的连接。 我们熟悉的 select/poll/epoll 就是内核提供给用户态的多路复用系统调用,线程可以通过一个系统调用函数从内核中获取多个事件。

select/poll/epoll 是如何获取网络事件的呢?
在获取事件时,先把我们要关心的连接传给内核,再由内核检测:
(1)如果没有事件发生,线程只需阻塞在这个系统调用,而无需像前面的线程池方案那样轮训调用 read 操作来判断是否有数据。
(2)如果有事件发生,内核会返回产生了事件的连接,线程就会从阻塞状态返回,然后在用户态中再处理这些连接对应的业务即可。
8.4.2 Reactor模式
Reactor 翻译过来的意思是「反应堆」,反应指的是「对事件反应」,也就是来了一个事件,Reactor 就有相对应的反应/响应。Reactor 模式也叫 Dispatcher 模式,我觉得这个名字更贴合该模式的含义,即 I/O 多路复用监听事件,收到事件后,根据事件类型分配(Dispatch)给某个进程 / 线程。
Reactor 模式主要由 Reactor 和处理资源池这两个核心部分组成,它俩负责的事情如下:(1)Reactor 负责监听和分发事件,事件类型包含连接事件、读写事件。
(2)处理资源池负责处理事件,如 read -> 业务逻辑 -> send。
Reactor 模式是灵活多变的:
(1)Reactor 的数量可以只有一个,也可以有多个。
(2)处理资源池可以是单个进程 / 线程,也可以是多个进程 /线程。
常见的3个经典的模式分别问:
(1)单 Reactor 单进程 / 线程;
(2)单 Reactor 多线程 / 进程;
(3)多 Reactor 多进程 / 线程。
8.4.2.1 单 Reactor 单进程 / 线程
单Reactor单进程示意图:
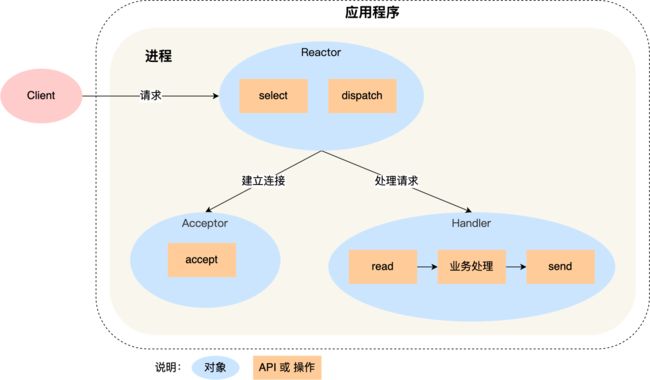
可以看到进程里有 Reactor、Acceptor、Handler 这三个对象:
- Reactor 对象的作用是监听和分发事件;
- Acceptor 对象的作用是获取连接;
- Handler 对象的作用是处理业务;
对象里的 select、accept、read、send 是系统调用函数,dispatch 和 「业务处理」是需要完成的操作,其中 dispatch 是分发事件操作。
接下来,介绍下「单 Reactor 单进程」这个方案:
- Reactor 对象通过 select (IO 多路复用接口) 监听事件,收到事件后通过 dispatch 进行分发,具体分发给 Acceptor 对象还是 Handler 对象,还要看收到的事件类型;
- 如果是连接建立的事件,则交由 Acceptor 对象进行处理,Acceptor 对象会通过 accept 方法 获取连接,并创建一个 Handler 对象来处理后续的响应事件;
- 如果不是连接建立事件, 则交由当前连接对应的 Handler 对象来进行响应;
- Handler 对象通过 read -> 业务处理 -> send 的流程来完成完整的业务流程。
单 Reactor 单进程的方案因为全部工作都在同一个进程内完成,所以实现起来比较简单,不需要考虑进程间通信,也不用担心多进程竞争。
但是,这种方案存在 2 个缺点:
- 第一个缺点,因为只有一个进程,无法充分利用 多核 CPU 的性能;
- 第二个缺点,Handler 对象在业务处理时,整个进程是无法处理其他连接的事件的,如果业务处理耗时比较长,那么就造成响应的延迟;
所以,单 Reactor 单进程的方案不适用计算机密集型的场景,只适用于业务处理非常快速的场景。
Redis 是由 C 语言实现的,它采用的正是「单 Reactor 单进程」的方案,因为 Redis 业务处理主要是在内存中完成,操作的速度是很快的,性能瓶颈不在 CPU 上,所以 Redis 对于命令的处理是单进程的方案。
代码实现:
网络上有关Reactor模型的另外一张常见的图如下所示:
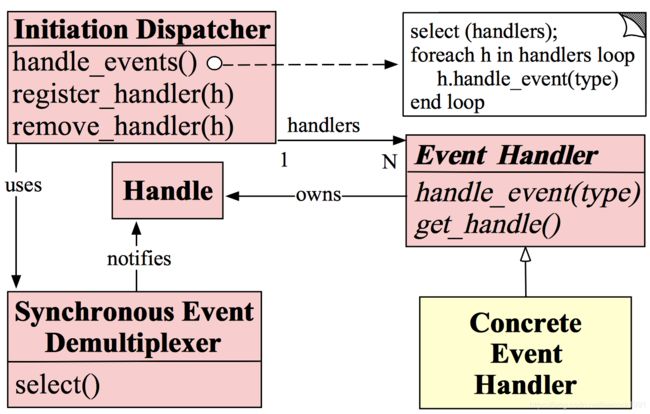
该图有五个重要的角色:
handle 即文件描述符
Synchronous Event Demultiplexer 即IO多路复用
Event Handler 即处理事件的回调函数
Concrete Event Handler 即具体的实现逻辑处理的函数
Initiation Dispatcher 即初始分发器 也是reactor角色,提供了注册、删除与转发event handler的方法。
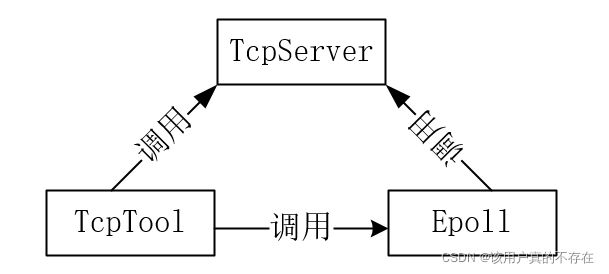
下面根据这张图,分别创建三个类:
Epoll类(包含Synchronous Event Demultiplexer,handle):实现IO多路复用。事件的增删改;监听客户端新的连接以及已有连接的读写事件;将这些事件发给相应的事件处理函数。
TcpServer类(包含Initiation Dispatcher,Event Handler):Reactor角色的类。run函数注册回调、循环监听、事件分发;其他的函数相当于是Event Handler的角色。
TcpTool类(包含Concrete Event Handler):读写事件处理的具体实现,相当于一个Concrete Event Handler角色。
这3个类的关系如下图:
首先考虑这样一个问题:服务端接收到客户端数据后,最简单的响应方式就是在接收回调函数recv_cb的最后调用send。但这么处理存在问题:
发送大量数据时,socket的发送缓冲区有可能是满的,此时send会返回-1。那我们可以增加循环去发送吗?不能,否则线程可能长时间停留在此处理该send过程,其他IO请求都没法处理了。
正确的处理方式:recv完之后,将socket在epoll中的可触发事件更改为可写,更改之后,文件描述符发生变化,触发写事件,就会调用写处理函数,发送数据;在写数据的回调中send完数据后,再将其更改为可读,更改之后,文件描述符发生变化,触发读事件,就会调用写读函数,接收数据。如此便可循环运行下去。
下面的代码实现的功能是:客户端手动输入要发送的数据,服务端收到后打印接收到的数据,并发送”This is reactor server!"数据;客户端收到后,打印收到的数据。
服务端代码:
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
using namespace std;
#define MAXEVENTS 1024 //最多监控的事件的数量
#define BUFFERSIZE 1024
/**************************** TcpTool ****************************/
class TcpTool
{
public:
TcpTool(int fd) : m_fd(fd)
{
assert(m_fd >= 0);
}
~TcpTool()
{
close(m_fd);
}
int getFd() { return m_fd; }
int read();
int write();
private:
int m_fd;
};
int TcpTool::read()
{
char buffer[BUFFERSIZE];
memset(buffer, 0, sizeof(buffer));
int ret = recv(m_fd, buffer, sizeof(buffer), 0);
if(ret == 0)
{ //断开连接
std::cout<<"link error!"< 0)
{
cout<<"recv from clit:"< 0)
{
cout<<"send success!"<; //为函数模板指定别名
using HandleReadCallBack = std::function;
using HandleWriteCallBack = std::function;
using CloseConnCallBack = std::function;
int add(int fd, TcpTool* tool, int events); //将fd文件描述符及对应的事件类型events添加到epoll监视中
int mod(int fd, TcpTool* tool, int events); //修改fd文件描述符对应的事件
int del(int fd, TcpTool* tool, int events); //删除fd文件描述符对应的事件
int wait(int timeouts); //等待是否有文件描述符发生变化
void handleEvents(int listenFd, int ecentsNum); //当epoll中有事件需要处理时,将待处理的事件分发给相应的事件处理函数
//设置事件回调函数,后面会将handleRead()作为实参传入该函数
void setAccpetConnCB(const AccpetConnCallBack& cb)
{
accptConnCB = cb;
}
void setCloseConnCB(const CloseConnCallBack& cb)
{
closeCB = cb;
}
void setWriteCB(const HandleWriteCallBack& cb)
{
writeCB = cb;
}
void setReadCB(const HandleReadCallBack& cb)
{
readCB = cb;
}
private:
int epollFd; //调用epoll_create()返回的文件描述符
vector vecEvents; //保存发生事件的文件描述符对应的事件
//定义函数指针
AccpetConnCallBack accptConnCB;
HandleReadCallBack readCB;
HandleWriteCallBack writeCB;
CloseConnCallBack closeCB;
};
Epoll::Epoll():epollFd(::epoll_create(MAXEVENTS)), vecEvents(MAXEVENTS)
{
assert(epollFd > 0); //是否有事件发生
}
Epoll::~Epoll()
{
::close(epollFd);
}
int Epoll::add(int fd, TcpTool* tool, int events)
{
struct epoll_event event;
event.data.ptr = (void*)tool;
event.events = events;
int ret = ::epoll_ctl(epollFd, EPOLL_CTL_ADD, fd, &event);
return ret;
}
int Epoll::mod(int fd, TcpTool* tool, int events)
{
struct epoll_event event;
event.data.ptr = (void*)tool;
event.events = events;
int ret = ::epoll_ctl(epollFd, EPOLL_CTL_MOD, fd, &event);
return ret;
}
int Epoll::del(int fd, TcpTool* tool, int events)
{
struct epoll_event event;
event.data.ptr = (void*)tool;
event.events = events;
int ret = ::epoll_ctl(epollFd, EPOLL_CTL_DEL, fd, &event);
return ret;
}
int Epoll::wait(int timeouts)
{
//&*vecEvents.begin():取vecEvents的首地址
//等待事件的发生
int eventsNum = ::epoll_wait(epollFd, &*vecEvents.begin(), static_cast(vecEvents.size()), timeouts);
if (eventsNum == 0 || eventsNum < 0)
{
//暂不处理
return 0;
}
return eventsNum;
}
void Epoll::handleEvents(int listenFd, int eventsNum)
{
assert(eventsNum > 0);
for (int i = 0; i < eventsNum; i++)
{
TcpTool* tool = (TcpTool*)(vecEvents[i].data.ptr);
int fd = tool->getFd(); //获取tool中的fd(acceptFd或listenFd)
if (fd == listenFd)
{
accptConnCB(); //回调
}
else if (vecEvents[i].events & EPOLLIN) //读事件
{
readCB(tool);
}
else if (vecEvents[i].events & EPOLLOUT) //写事件
{
writeCB(tool);
}
}
}
/********************* TcpServer **************************/
class TcpServer
{
public:
TcpServer(int port, int listenFd):
m_port(port),
m_listenFd(listenFd),
m_toolptr(new TcpTool(m_listenFd)),
m_epollptr(new Epoll())
{
assert(m_listenFd >= 0);
}
void run();
private:
//这些函数用来给回调函数指针赋值
void acceptConn();
void closeConn(TcpTool* tool);
void handleRead(TcpTool* tool);
void handleWrite(TcpTool* tool);
using EpollPtr = std::unique_ptr;
using TcpToolPtr = std::unique_ptr;
int m_port;
int m_listenFd;
//只能有一个epoll实例,所以使用unique_ptr 自动释放
EpollPtr m_epollptr;
TcpToolPtr m_toolptr;
};
void TcpServer::acceptConn()
{
while(1)
{
struct sockaddr_in clntAddr;
socklen_t len ;
int acceptFd = ::accept(m_listenFd,(struct sockaddr*)&clntAddr,&len);
if (acceptFd == -1)
{
if (errno == EAGAIN)
break;
cout << "accept errno!"<add(acceptFd, tool, (EPOLLIN|EPOLLET));
}
}
void TcpServer::closeConn(TcpTool* tool)
{
int fd = tool->getFd();
m_epollptr->del(fd, tool, 0);
close(fd); //关闭文件描述符
delete tool;
tool = nullptr;
}
void TcpServer::handleRead(TcpTool* tool)
{
int fd = tool->getFd();
int nRead = tool->read();
//对方关闭连接或发生错误
if(nRead == 0 || (nRead <0 && (errno != EAGAIN)))
{
cout << "close connection and delete tool" <mod(fd, tool, EPOLLIN);
return;
}
m_epollptr->mod(fd, tool, EPOLLOUT);
}
void TcpServer::handleWrite(TcpTool* tool)
{
int fd = tool->getFd();
int nWrite = tool->write();
//对方关闭连接或发生错误
if(nWrite == 0 || (nWrite <0 && (errno != EAGAIN)))
{
cout << "close connection and delete tool" <mod(fd, tool, EPOLLIN); //
}
void TcpServer::run(){
//先将m_listenFd对应的事件加入epoll监听
m_epollptr->add(m_listenFd, m_toolptr.get(), (EPOLLIN | EPOLLET));
//注册回调函数
m_epollptr->setAccpetConnCB(std::bind(&TcpServer::acceptConn,this));
m_epollptr->setWriteCB(std::bind(&TcpServer::handleWrite,this,std::placeholders::_1));
m_epollptr->setReadCB(std::bind(&TcpServer::handleRead,this,std::placeholders::_1));
//开始事件循环
while(1){
int eventsNum = m_epollptr->wait(-1);
if(eventsNum > 0){
//事件分发
m_epollptr->handleEvents(m_listenFd,eventsNum);
}
}
}
int main()
{
int port = 6666;
int listenFd = socket(AF_INET, SOCK_STREAM | SOCK_NONBLOCK, 0);
//端口重用
int reuse = 1;
setsockopt(listenFd, SOL_SOCKET, SO_REUSEADDR, &reuse, sizeof(reuse));
struct sockaddr_in servAddr;
::memset(&servAddr,0,sizeof(servAddr));
port = ((port <= 1024) || (port >=65536)) ? 6666 : port;
servAddr.sin_family = AF_INET;
servAddr.sin_port = ::htons((unsigned short)port);
servAddr.sin_addr.s_addr = ::htonl(INADDR_ANY);
if((::bind(listenFd, (struct sockaddr*)&servAddr, sizeof(servAddr))) == -1){
std::cout<<"bind error!"< 客户端代码:
#include
#include
#include
#include
#include
#include
#include
#include
#include
using namespace std;
#define BUFFERSIZE 1024
int main()
{
int sock = socket(AF_INET, SOCK_STREAM, 0);
struct sockaddr_in servAddr;
memset(&servAddr, 0, sizeof(servAddr));
servAddr.sin_family = AF_INET;
servAddr.sin_port = htons(6666);
servAddr.sin_addr.s_addr = htonl(INADDR_ANY);
int ret = connect(sock, (struct sockaddr*)&servAddr, sizeof(servAddr));
if (ret == -1)
{
cout <<"connect error"<> sendbuff;
send(sock, sendbuff, sizeof(sendbuff), 0);
char recvbuff[BUFFERSIZE] = {0};
int ret = recv(sock, recvbuff, sizeof(recvbuff), 0);
if (ret)
{
cout<<"recv serv:"< 8.4.2.2 单 Reactor 多进程 / 多线程
「单 Reactor 多线程」方案的示意图如下:
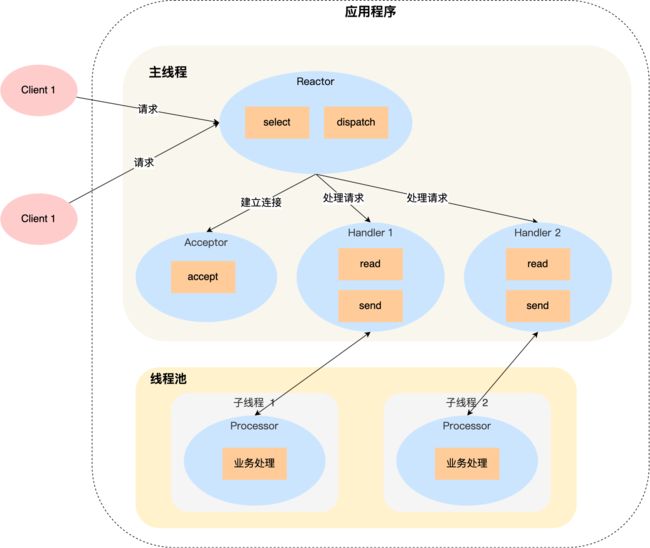
- Reactor 对象通过 select (IO 多路复用接口) 监听事件,收到事件后通过 dispatch 进行分发,具体分发给 Acceptor 对象还是 Handler 对象,还要看收到的事件类型;
- 如果是连接建立的事件,则交由 Acceptor 对象进行处理,Acceptor 对象会通过 accept 方法 获取连接,并创建一个 Handler 对象来处理后续的响应事件;
- 如果不是连接建立事件, 则交由当前连接对应的 Handler 对象来进行响应;
上面的三个步骤和单 Reactor 单线程方案是一样的,接下来的步骤就开始不一样了:
- Handler 对象不再负责业务处理,只负责数据的接收和发送,Handler 对象通过 read 读取到数据后,会将数据发给子线程里的 Processor 对象进行业务处理;
- 子线程里的 Processor 对象就进行业务处理,处理完后,将结果发给主线程中的 Handler 对象,接着由 Handler 通过 send 方法将响应结果发送给 client;
单 Reator 多线程的方案优势在于能够充分利用多核 CPU 的能,那既然引入多线程,那么自然就带来了多线程竞争资源的问题。例如,子线程完成业务处理后,要把结果传递给主线程的 Reactor 进行发送,这里涉及共享数据的竞争。
要避免多线程由于竞争共享资源而导致数据错乱的问题,就需要在操作共享资源前加上互斥锁,以保证任意时间里只有一个线程在操作共享资源,待该线程操作完释放互斥锁后,其他线程才有机会操作共享数据。
接着来看看单 Reactor 多进程的方案。
单 Reactor 多进程相比单 Reactor 多线程实现起来很麻烦,主要因为要考虑子进程 <-> 父进程的双向通信,并且父进程还得知道子进程要将数据发送给哪个客户端。
而多线程间可以共享数据,虽然要额外考虑并发问题,但是这远比进程间通信的复杂度低得多,因此实际应用中也看不到单 Reactor 多进程的模式。
「单 Reactor」的模式还有个问题,因为一个 Reactor 对象承担所有事件的监听和响应,而且只在主线程中运行,在面对瞬间高并发的场景时,容易成为性能的瓶颈的地方。
8.4.2.3 多 Reactor 多进程 / 线程
要解决「单 Reactor」的问题,就是将「单 Reactor」实现成「多 Reactor」,这样就产生了第 多 Reactor 多进程 / 线程的方案。
多 Reactor 多进程 / 线程方案的示意图如下(以线程为例):
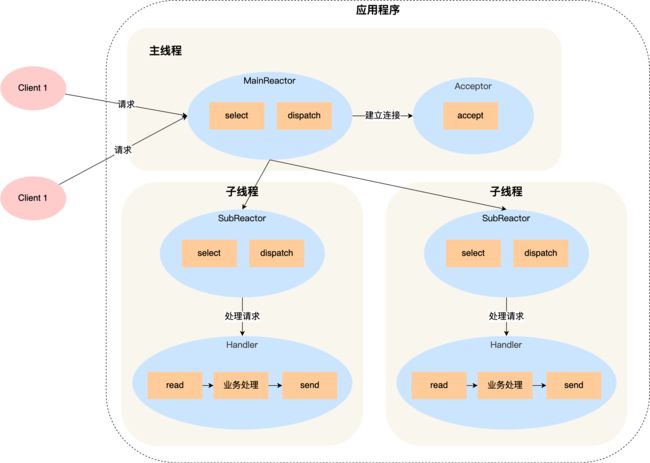
- 主线程中的 MainReactor 对象通过 select 监控连接建立事件,收到事件后通过 Acceptor 对象中的 accept 获取连接,将新的连接分配给某个子线程;
- 子线程中的 SubReactor 对象将 MainReactor 对象分配的连接加入 select 继续进行监听,并创建一个 Handler 用于处理连接的响应事件。
- 如果有新的事件发生时,SubReactor 对象会调用当前连接对应的 Handler 对象来进行响应。
- Handler 对象通过 read -> 业务处理 -> send 的流程来完成完整的业务流程。
多 Reactor 多线程的方案虽然看起来复杂的,但是实际实现时比单 Reactor 多线程的方案要简单的多,原因如下:
- 主线程和子线程分工明确,主线程只负责接收新连接,子线程负责完成后续的业务处理。
- 主线程和子线程的交互很简单,主线程只需要把新连接传给子线程,子线程无须返回数据,直接就可以在子线程将处理结果发送给客户端。
8.4.3 Proactor模式
Proactor 正是采用了异步 I/O 技术,所以被称为异步网络模型。
现在我们再来理解 Reactor 和 Proactor 的区别,就比较清晰了:
- Reactor 是非阻塞同步网络模式,感知的是就绪可读写事件。在每次感知到有事件发生(比如可读就绪事件)后,就需要应用进程主动调用 read 方法来完成数据的读取,也就是要应用进程主动将 socket 接收缓存中的数据读到应用进程内存中,这个过程是同步的,读取完数据后应用进程才能处理数据。
- Proactor 是异步网络模式, 感知的是已完成的读写事件。在发起异步读写请求时,需要传入数据缓冲区的地址(用来存放结果数据)等信息,这样系统内核才可以自动帮我们把数据的读写工作完成,这里的读写工作全程由操作系统来做,并不需要像 Reactor 那样还需要应用进程主动发起 read/write 来读写数据,操作系统完成读写工作后,就会通知应用进程直接处理数据。
因此,Reactor 可以理解为「来了事件操作系统通知应用进程,让应用进程来处理」,而 Proactor 可以理解为「来了事件操作系统来处理,处理完再通知应用进程」。这里的「事件」就是有新连接、有数据可读、有数据可写的这些 I/O 事件,这里的「处理」包含从驱动读取到内核以及从内核读取到用户空间。
无论是 Reactor,还是 Proactor,都是一种基于「事件分发」的网络编程模式,区别在于 Reactor 模式是基于「待完成」的 I/O 事件,而 Proactor 模式则是基于「已完成」的 I/O 事件。
下面是Proactor 模式的示意图:
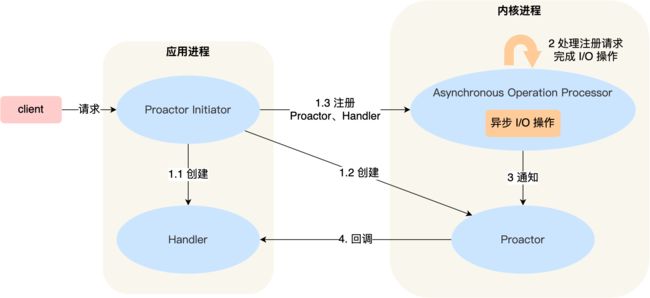
- Proactor Initiator 负责创建 Proactor 和 Handler 对象,并将 Proactor 和 Handler 都通过 Asynchronous Operation Processor 注册到内核;
- Asynchronous Operation Processor 负责处理注册请求,并处理 I/O 操作;
- Asynchronous Operation Processor 完成 I/O 操作后通知 Proactor;
- Proactor 根据不同的事件类型回调不同的 Handler 进行业务处理;
- Handler 完成业务处理;
可惜的是,在 Linux 下的异步 I/O 是不完善的, aio 系列函数是由 POSIX 定义的异步操作接口,不是真正的操作系统级别支持的,而是在用户空间模拟出来的异步,并且仅仅支持基于本地文件的 aio 异步操作,网络编程中的 socket 是不支持的,这也使得基于 Linux 的高性能网络程序都是使用 Reactor 方案。
而 Windows 里实现了一套完整的支持 socket 的异步编程接口,这套接口就是 IOCP,是由操作系统级别实现的异步 I/O,真正意义上异步 I/O,因此在 Windows 里实现高性能网络程序可以使用效率更高的 Proactor 方案。
8.5 两种高效的并发模式
并发编程的目的是让程序”同时“执行多个任务,主要有多进程和多线程两种方式。并发模式是指I/O处理单元和多个逻辑单元之间协调完成任务的方法。服务器主要有两种并发编程模式:半同步/半异步(half-sync/half-async)模式和领导者/追随者(Leader/Followers)模式。
8.5.1 半同步/半异步模式
“半同步/半异步”中的同步和异步与”同步I/O和异步I/O“中的同步和异步含义不同。在这里:
同步:程序完全按照代码序列的顺序执行
异步:程序的执行需要由系统事件(中断、信号等)来驱动。
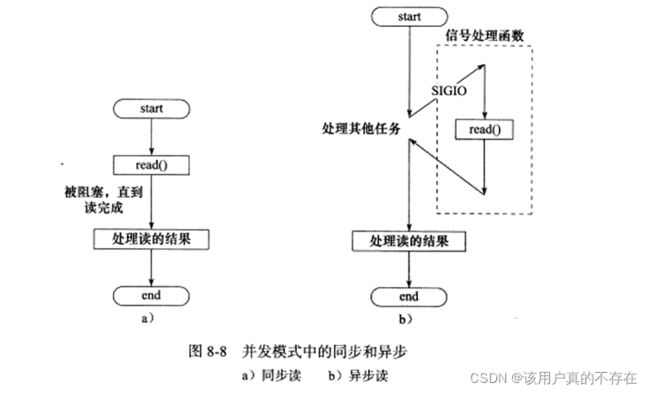
同步线程:按照同步方式运行的线程
异步线程:按照异步方式运行的线程
半同步/半异步模式:同时使用同步线程和异步线程。
8.5.1.1 半同步/半反应堆模式

该模式中,异步线程只有一个就是主线程,它负责监听所有socket上的事件。如果监听socket上有连接请求到来,主线程就接受并得到一个新的连接socket(accept系统调用返回的socket描述符),然后将该连接socket注册到epoll事件列表中,如果连接socket上有读写事件发生,主线程就将该连接socket加入请求队列中。所有工作线程都睡眠在请求队列上,当有任务到来时,他们将通过竞争(如互斥锁)来处理任务。
该模式的代码实现在15.5节,此处暂时不实现。
8.5.1.2 高效的半同步/半异步模式
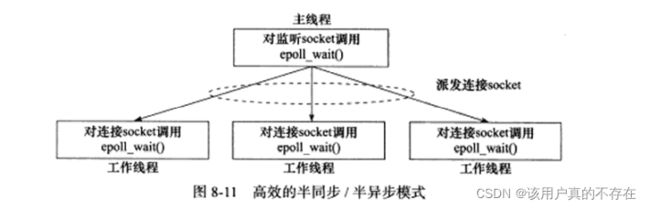
该模式中,主线程只管监听socket,连接socket由工作线程管理。如果监听socket上有连接请求到来,主线程就接受并得到一个新的连接socket,并将该连接socket派发给没有工作线程,此后该连接socket上的任何I/O操作都由被选中的工作线程来处理,直到客户端关闭连接。
主线程向工作线程派发socket的最简单的方式,就是往它和工作线程之间的管道里写数据。工作线程检测到管道上有数据可读时,就分析是否是一个新的连接socket,如果是,就把该socket上的读写事件注册到自己的epoll内核事件列表中。
该模式的代码实现在15.3节,此处暂时不实现。
8.5.2 领导者/追随者模式(暂时不写)
8.6 有限状态机(暂时不写)
8.7 提高服务器性能的其他建议
前面我们介绍了几种高效的事件处理模式和并发模式,以及高效的逻辑处理方式一有限状态机,它们都有助于提高服务器的整体性能。下面我们进一步分析高性能服务器需要注意的其他几个方面:池、数据复制、上下文切换和锁。
8.7.1 池
“浪费”服务器的硬件资源,以换取其运行效率。这就是池(pool) 的概念。池是一组资源的集合,这组资源在服务器启动之初就被完全创建好并初始化,这称为静态资源分配。当服务器进入正式运行阶段,如果它需要相关的资源,就可以直接从池中获取,无须动态分配。当服务器处理完后,可以把相关的资源放回池中,无须执行系统调用来释放资源。因此,池相当于服务器管理系统资源的应用层设施,它避免了服务器对内核的频繁访问。
内存池通常用于socket的接收缓存和发送缓存。对于某些长度有限的客户请求,比如HTTP请求,预先分配-一个大小足够(比如5000字节)的接收缓存区是很合理的。当客户请求的长度超过接收缓冲区的大小时,我们可以选择丢弃请求或者动态扩大接收缓冲区。
进程池和线程池都是并发编程常用的“伎俩”。当我们需要一个工作进程或工作线程来处理新到来的客户请求时,我们可以直接从进程池或线程池中取得一个执行实体,而无须动态地调用fork或pthread_ create 等函数来创建进程和线程。
连接池通常用于服务器或服务器机群的内部永久连接。当某个逻辑单元需要访问数据库时,它可以直接从连接池中获取一个连接实体并使用。完成访问之后,逻辑单元再将该连接返还给连接池。
8.7.2 数据复制
高性能服务器应该避免不必要的数据复制,尤其是当数据复制发生在用户代码和內核之间的时候。如果内核可以直接处理从socket或者文件读入的数据,则应用程序就没必要将这些数据从内核缓冲区复制到应用程序缓冲区中。这里说的“直接处理”指的是应用程序不关心这些数据的内容,不需要对它们做任何分析。比如ftp服务器,当客户请求一个文件时,服务器只需要检测目标文件是否存在,以及客户是否有读取它的权限,而绝对不会关心文件的具体内容。这样的话,ftp 服务器就无须把目标文件的内容完整地读人到应用程序缓冲区中并调用send函数来发送,而是可以使用“零拷贝”函数sendfile来直接将其发送给客户端。
此外,用户代码内部(不访问内核)的数据复制也是应该避免的。举例来说,当两个工作进程之间要传递大量的数据时,我们就应该考虑使用共享内存来在它们之间直接共享这些数据,而不是使用管道或者消息队列来传递。
8.7.3 上下文切换和锁
并发程序必须考虑上下文切换(context switch)的问题,即进程切换或线程切换导致的的系统开销。进程/线程间的切换将占用大量的CPU时间。此外,多线程服务器的一个优点是不同的线程可以同时运行在不同的CPU上。当线程的数量不大于CPU的数目时,上下文的切换就不是问题了。
并发程序需要考虑的另外一个问题是共享资源的加锁保护。锁通常被认为是导致服务器效率低下的一个因素,因为由它引入的代码不仅不处理任何业务逻辑,而且需要访问内核资源。因此,服务器如果有更好的解决方案,就应该避免使用锁。如果服务器必须使用“锁”,则可以考虑减小锁的粒度,比如使用读写锁。当所有工作线程都只读取一块共享内存的内容时,读写锁并不会增加系统的额外开销,因为只有当其中某一个工作线程需要写这块内存时,系统才必须去锁住这块区域。