MySQL优化:索引失效分析、in与exists使用场合
一、索引失效的情况
前文提及过可以通过explain的possible_keys、key属性判断索引是否失效,key如果为null,可能是索引没建,也可能是索引失效,下面列举一些会使索引失效的情况。
1、全值匹配:顺序、个数与索引一致
2、最佳左前缀法则:查询从索引的最左前列开始并且不跳过索引中的列,中间跳过的值,后面的索引会失效
3、索引列上做了操作(计算、函数、自动或手动类型转换),会导致索引失效而转向全表扫描
4、存储引擎不能使用索引中范围条件右边的列
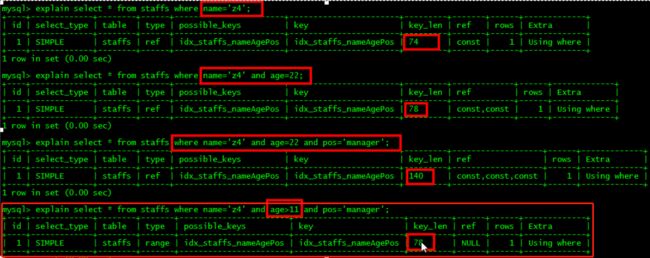
name字段用于查找,age>11也用到了,但着重用于排序,pos则没用到索引
5、尽量使用覆盖索引(索引列和查询列一致),减少select *
using where是在表里检索,using index会直接从索引里检索

这里也是范围检索,但与上面不同的是这里从索引里获取数据,没有用到age

6、mysql在使用不等于(!= 或 <>)时无法使用索引

7、is null,is not null也无法使用索引
8、like以通配符开头(‘%abc..’)也会导致索引失效
通过覆盖索引可以解决like '%字符串%'索引失效的问题
例:假设以name,age字段建索引
create index idx_user_nameAge on tb_user(name,age);
查询字段只要有一个和覆盖索引沾边就行


但如果有超过索引的部分,索引就用不上了,所以用select * 就不能使用覆盖索引

9、字符串不加单引号,该字段以后的索引失效
10、少用or,用它来连接时会索引失效
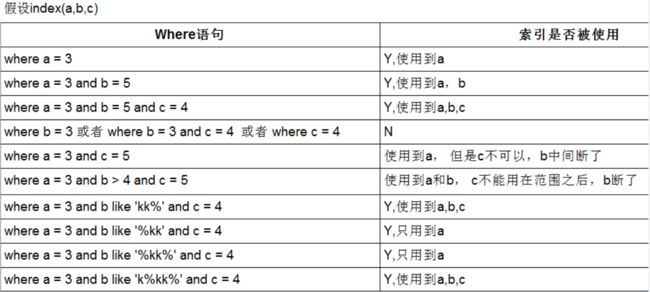
11、少数据值的列也不应该增加索引,只有两种情况,且平均分布,加了索引反而降低速度
12、range的包含范围有一定的阈值,超过会进行全文扫描
二、in与exists使用场合
坚持小表驱动大表的原则
in:当B表的数据集必须小于A表的数据集时,in优于exists
select * from A where id in (select id from B) #等价于: for select id from B for select * from A where A.id = B.id
exists:当A表的数据集小于B表的数据集时,exists优于in
将主查询A的数据,放到子查询B中做条件验证,根据验证结果(true或false)来决定主查询的数据是否保留
子查询也可以用条件表达式、其他子查询或join来替代,何种最优需具体问题具体分析
select * from A where exists (select 1 from B where B.id = A.id)
#等价于
for select * from A
for select * from B where B.id = A.id
#A表与B表的ID字段应建立索引
三、对Order By的优化
1、用order by子句的重点是是否会产生filesort。建索引时已经排好序,所以order by的顺序和索引最好一致,避免再一次排序。
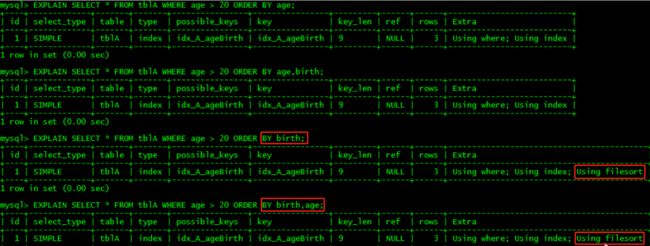
所建的索引默认升序,一升序一降序会产生内排序

2、状态最好是using index,让mysql通过扫描索引本身完成排序。
能使用index方式排序的情况:order by语句使用索引最左前列,或where子句与order子句条件组合满足索引最左前列。
(1)order by语句使用索引最左前列,order by后字段同为asc或desc都行

(2)加上where子句的条件与order by子句条件列组合满足索引最左前列

(3)不能使用索引的情况

假如以category_id、comments、views的顺序建索引

3、filesort的两种算法
(1)双路排序:两次扫描磁盘(读取行指针和order by列,对他们进行排序,然后扫描已排好序的列表,重新列表读取数据输出)。
(2)单路排序:mysql4.1版本后,从磁盘读取查询需要的所有列,按order by列在buffer对它们排序,然后扫描排序后的列表输出,只读取一次数据,且把随机IO变为顺序IO,但会使用更多空间,因为它把每一行都保存在内存中。
单路排序存在的问题:
因为要把所有字段取出,可能要取出的大小超出sort_buffer容量,导致每次只能取sort_buffer容量大小的数据进行排序(创建tmp文件,多路合并),排完再取sort_buffer容量大小的数据,反而会导致更多I/O操作。
4、order by优化策略:
(1)单路多路算法的数据都有可能超过sort_buffer_size,超出后会建tmp文件进行合并排序,导致多次I/O,可以根据系统能力增大sort_buffer_size参数设置
(2)增大max_length_for_sort_data参数,会增加用单路排序的概率,但如果设太大,也会更容易使数据超过sort_buffer_size,当query的字段大小总和小于max_length_for_sort_data且排序字段不是text/blob类型时,才会用单路排序,否则还是用多路排序。
(3)order by时不要用select *,只select需要的字段,多余的字段会占用sort_buffer的内存。
5、group by:
适用order by原则,实质先排序后分组,遵守索引建的最佳左前缀,使用不当会产生临时表。
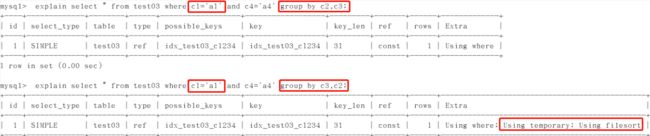
当无法使用索引列,增大max_length_for_sort_data和sort_buffer_size参数设置。能在where的条件就不放在having里。
四、案例,其他注意点
假如以c1,c2,c3,c4的顺序建立索引
1、对于常量类型,查询优化器会自动调优SQL,顺序不影响
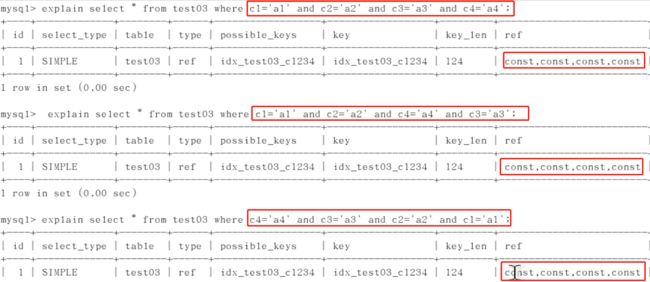
2、范围之后全失效,但查询优化器会先常量类型自动调优,c3被调前,c4后的失效,但c4是最后一个了,所以仍用到4个。以上的例子中间并没有断
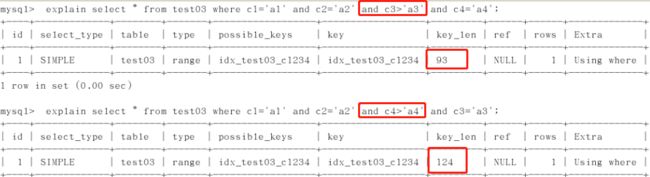
3、都只用到了c1,c2,第三条语句无法使用到索引排序,所以mysql内部自己进行了一次排序(前两个c3没用到查找,但用到了排序,所以无using filesort,只是没有记录到key_len里)

4、order by不按索引顺序会出现using filesort,本来照理第一个按order by c3,c2排序会出现filesort,但是前面已经有c2=‘a2’的条件,c2已经是常量值,所以c2其实不用排序

五、多表连接在从表加索引可以提高速度
案例1:两表连接的情况,多表连接时在主表还是从表建索引的问题
如未使用索引的情况

左连接把索引建在从表的关联字段比较好,主表一定会有,从表才是检索的关键

案例2:三表关联要建在哪些字段上
没建索引的时候

在第二、三个从表的关联字段加索引
ALTER TABLE `phone` ADD INDEX z(`card`); ALTER TABLE `book` ADD INDEX Y(`card`);

结论:
(1)join语句中被驱动表上join条件字段加索引可以提高效率;
(2)当无法保证被驱动表的join条件字段被索引且内存资源充足的前提下,不要太吝啬JoinBuffer的设置。