Spark SQL:Spark SQL编程
文章目录
-
- Spark SQL:Spark SQL编程
- 1、实验描述
- 2、实验环境
- 3、相关技能
- 4、知识点
- 5、实现效果
- 6、实验步骤
- 7、总结
Spark SQL:Spark SQL编程
1、实验描述
- 学习使用Spark SQL,并完成相关的实验操作。
- 实验时长:
- 45分钟
- 主要步骤:
- 启动spark-shell
- 使用spark外部数据API加载本地Json文件
- 使用DataFrame操作数据
- 使用SQL API操作数据
2、实验环境
- 虚拟机数量:1
- 系统版本:Centos 7.5
- Scala版本:2.11.0
- Spark版本: Apache spark-2.1.1
3、相关技能
- Spark 常用算子
- DataFrame的操作
4、知识点
- Spark SQL的基本概念
- DataFrame
- Spark SQL开发应用的方法
5、实现效果
查询课程名称满足指定条件的课程名操作最终效果如下图:

6、实验步骤
6.1DataFrame:是一个分布式的数据集,组织方式采用命名列的形式。类似于关系数据库中的一个表。可以由结构化的数据转换过来,也可以从Hive,外部数据库或者RDD转换。
6.1.1DataFrame:
spark的性能瓶颈在于内存和CPU,DataFrame的出现优化了算子的查询计算,同时依靠Tungsten计划逐渐摆脱对于JVM的依赖。在Spark
SQL中,可以使用SQL的方式进行操作,与RDD类似,也采用lazy的方式,只有动作发生时才会真正的执行计算
6.1.2DataFrame的数据来源很多样,支持JSON文件,Parquet文件,Hive表格,支持从本地文件系统,HDFS等分布式文件系统,以及S3云存储中读取数据。配合JDBC还可以支持外部关系型数据库。
6.2打开spark-shell 终端,进行实验。
6.2.1为消除当前实验环境中spark依赖Hadoop的警告,在Linux命令行执行如下命令:
[zkpk@master ~]$cd [zkpk@master ~]$ mv hadoop-2.7.3/ hadoop-2.7.3.bak/
6.2.2启动spark-shell,启动时指定启动模式
[zkpk@master ~]$cd [zkpk@master ~]$ cd spark-2.1.1-bin-hadoop2.7/[zkpk@master spark-2.1.1-bin-hadoop2.7]$ bin/spark-shell --master local[2]
6.2.3创建spark 的SQLContext
// 下面引入用于隐式地将RDD转换为DataFrame的包scala> import spark.implicits._
6.2.4创建DataFrames对象
6.2.4.1读取json格式的数据文件
// 使用spark外部数据源API读取JSON文件scala>val df =spark.read.json("/home/zkpk/experiment/06/courses.json")
6.2.4.2查看数据的schema信息
scala> df.printSchema()

6.2.4.3使用df.show()方法显示DataFrame内容,默认显示10条。
scala>df.show()

6.2.4.4字段介绍: name(课程名称),type(课程类型, 包括基础课(basic),
项目课(project)), length,课程包大小。
6.2.5select 操作
6.2.5.1查询所有的课程名:
scala>df.select("name").show()

6.2.5.2查询所有的课程名及课程包大小:
scala>df.select("name", "length").show()

6.2.6filter,groupyBy 和 count() 操作
6.2.6.1打印出所有的非实验课程名称,类似于使用where条件过滤
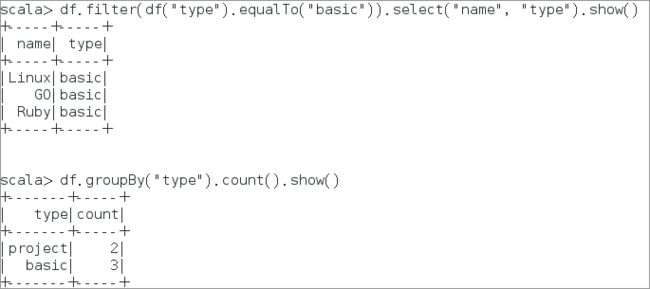
scala>df.filter(df("type").equalTo("basic")).select("name", "type").show()scala>df.groupBy("type").count().show() # 统计不同类型课程的数量
6.2.6.2将创建DataFrame 注册成临时表,此时我们将使用SQL方式进行操作
scala>df.registerTempTable("courses")
6.2.6.3将表数据cache到内存中,以减少不必要的重复计算
scala> spark.sql("cache table courses")
6.2.6.4查询课程长度在5-10之间的课程,将返回一个新的RDD
scala> spark.sql("select name from courses where length between 5 and 10").map(t => "Name: " + t(0)).collect().foreach(println)

7、总结
本次实验通过使用具体的spark SQL API完成数据的加载,处理。
可以进一步提升我们的spark技能。