HDFS—集群扩容及缩容
- 添加白名单
- 添加新服务器
- 服务器间数据均衡
1. 添加白名单
白名单:表示在白名单的主机IP地址可以,用来存储数据。
企业中:配置白名单,可以尽量防止黑客恶意访问攻击。
配置白名单步骤:
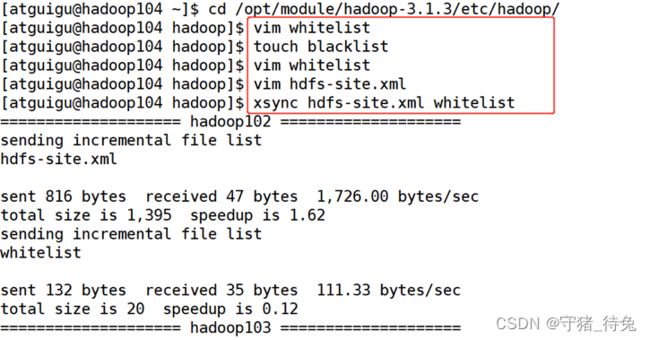
1)在NameNode节点的/opt/module/hadoop-3.1.3/etc/hadoop目录下分别创建whitelist 和blacklist文件
a.创建白名单
[atguigu@hadoop102 hadoop]$ vim whitelist
在whitelist中添加如下主机名称,假如集群正常工作的节点为102 103
hadoop102
hadoop103
b.创建黑名单
[atguigu@hadoop102 hadoop]$ touch blacklist
保持空的就可以。
2)在hdfs-site.xml配置文件中增加dfs.hosts配置参数
dfs.hosts
/opt/module/hadoop-3.1.3/etc/hadoop/whitelist
dfs.hosts.exclude
/opt/module/hadoop-3.1.3/etc/hadoop/blacklist
3)分发配置文件whitelist,hdfs-site.xml
[atguigu@hadoop104 hadoop]$ xsync hdfs-site.xml whitelist
4)第一次添加白名单必须重启集群,不是第一次,只需要刷新NameNode节点即可
[atguigu@hadoop102 hadoop-3.1.3]$ myhadoop.sh stop
[atguigu@hadoop102 hadoop-3.1.3]$ myhadoop.sh start
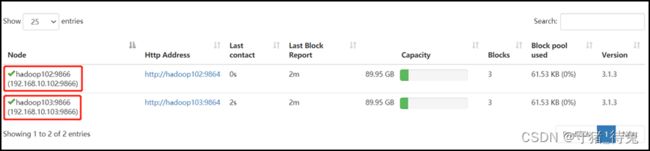
5)在web浏览器上查看DN,http://hadoop102:9870/dfshealth.html#tab-datanode
6)二次修改白名单,增加hadoop104
[atguigu@hadoop102 hadoop]$ vim whitelist
修改为如下内容
hadoop102
hadoop103
hadoop104
分发:xsync whitelist
7)刷新NameNode
[atguigu@hadoop102 hadoop-3.1.3]$ hdfs dfsadmin -refreshNodes
Refresh nodes successful
8)在web浏览器上查看DN,http://hadoop102:9870/dfshealth.html#tab-datanode

2. 添加新服务器
1)需求
随着公司业务的增长,数据量越来越大,原有的数据节点的容量已经不能满足存储数据的需求,需要在原有集群基础上动态添加新的数据节点。
2)环境准备
(1)在hadoop100主机上再克隆一台hadoop105主机
克隆前白名单加上105——关闭集群
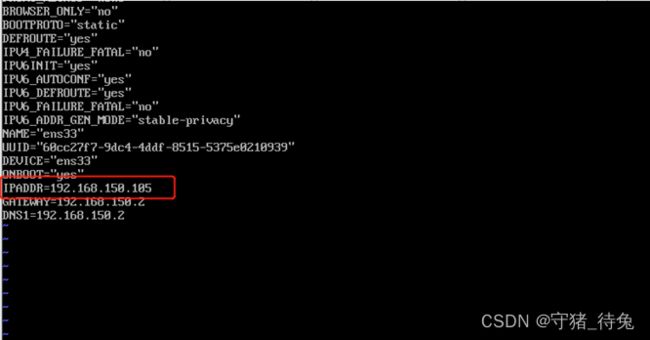
(2)修改IP地址和主机名称
[root@hadoop105 ~]# vim /etc/sysconfig/network-scripts/ifcfg-ens33
[root@hadoop105 ~]# vim /etc/hostname

reboot重启
xshell连接,账号atguigu
测试是否可以免密登录其他服务器 ssh hadoop104 可以

因为公钥和私钥在104已经配置,并且克隆到105

(3)启动
启动hdfs: start-dfs.sh
只能启动Hadoop102、3、4

Hadoop5单独启动

(4)删除105的date和log目录。因为克隆之后,会导致Hadoop104和105的data目录下的uid重复

解决:停止105的hdfshdfs --daemon stop datanode
——删除data和logs
——开启hdfs --daemon start datanode

3)服役新节点具体步骤
(1)直接启动DataNode,即可关联到集群
[atguigu@hadoop105 hadoop-3.1.3]$ hdfs --daemon start datanode
[atguigu@hadoop105 hadoop-3.1.3]$ yarn --daemon start nodemanager
4)在白名单中增加新服役的服务器
(1)在白名单whitelist中增加hadoop104、hadoop105,并重启集群
[atguigu@hadoop102 hadoop]$ vim whitelist
修改为如下内容
hadoop102
hadoop103
hadoop104
hadoop105
(2)分发
[atguigu@hadoop102 hadoop]$ xsync whitelist
(3)刷新NameNode
[atguigu@hadoop102 hadoop-3.1.3]$ hdfs dfsadmin -refreshNodes
Refresh nodes successful
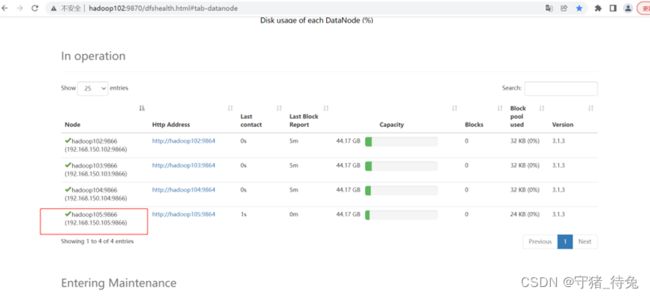
5)在hadoop105上上传文件
[atguigu@hadoop105 hadoop-3.1.3]$ hadoop fs -put /opt/module/hadoop-3.1.3/LICENSE.txt /

3. 服务器间数据均衡
1)经验:
在企业开发中,如果经常在hadoop102和hadoop104上提交任务,且副本数为2,由于数据本地性原则,就会导致hadoop102和hadoop104数据过多,hadoop103存储的数据量小。
另一种情况,就是新服役的服务器数据量比较少,需要执行集群均衡命令。

2)开启数据均衡命令
[atguigu@hadoop105 hadoop-3.1.3]$ sbin/start-balancer.sh -threshold 10
对于参数10,代表的是集群中各个节点的磁盘空间利用率相差不超过10%,可根据实际情况进行调整。
3)停止数据均衡命令
[atguigu@hadoop105 hadoop-3.1.3]$ sbin/stop-balancer.sh
注意:由于HDFS需要启动单独的Rebalance Server来执行Rebalance操作,所以尽量不要在NameNode上执行start-balancer.sh,而是找一台比较空闲的机器。