学习系统编程No.13【文件系统】
引言:
北京时间:2023/3/31/7:48,该篇博客在两天前本就应该产出,但是摆烂谁拦得住,所以呜呜呜!本以为欠的钱也要快还完了,没想到啊,越欠越多,烦人!但是,欠的都是小钱,不像以前,欠的是大钱,所以也不怎么打紧,慢慢还啦!这周的榜估计是保不住了,具体还要看看周末摆烂不摆烂,谁让腾讯有钱,可以看《阿凡达之水之道》,真的很想看,所以我已经料想都了自己的周末是怎么过的了,难过!但是不怕,伤心和开心就和机遇和挑战一样,是并存的。比如,我昨天非常的开心,幸福来得太突然,因为有人愿意帮我买溜溜球,开心激动坏了,可惜我不怎么好意思收,哈哈哈!但是我依然很开心,发现生活真的不只是学习,更重要的还有摆烂!!!哈哈哈!可能在我看来摆烂就是这么的朴实无华吧!今天就让我们来回顾一下缓冲区的知识和贯穿体系的过程,当然最重要的是文件系统知识!
自主封装系统调用接口
了解了上篇博客的知识,我们对写代码具体是在干什么有了一个更加深入的理解,对平时使用的无论是C语言代码还是C++代码都有了进一步理解,知道了,语言只不过是对系统调用接口的一个封装,目的只是为了可以提高编程效率而已,所以接下来,我们就自己也封装一个调用文件操作的系统调用,用来加深我们对FILE结构体和系统调用接口的理解,如下代码:
我们自主实现的就是一个对系统文件操作接口的封装,我们分成4个接口实现,打开(fopen)、关闭(fclose)、写入(fwrite)、刷新(fflush),具体每个接口的实现过程如下:
FILE对象结构体如下:

打开文件
1.识别标志位 2.尝试打开文 3.构建FILE结构体 4.初始化FILE对象

关闭文件
5.冲刷缓冲区中的数据 6.关闭文件 7.释放堆空间(FILE结构体) 8.指针置空

刷新缓冲区
9.判断缓冲区类型 10.按照缓冲区类型,根据原理刷新数据

写入数据
11.判断缓冲区是否满了,是否可以写入 12.根据缓冲区剩余情况,进行数据拷贝 13.更新计数器(更新数据大小) 14.刷新缓冲区中的数据

上述就是我们对系统文件操作接口的一个类似于C语言中文件操作接口的封装,当然我们只是简易封装,目的只是为了深入了解文件操作的原理而已,具体代码在该文最后。
回顾缓冲区
上篇博客,我们讲缓冲区的知识,使用文字描述的形式进行了一个深刻的了解,知道了什么是缓冲区的基本刷新策略等知识,但是要注意,我们使用的缓冲区都是属于用户级缓冲区,并不是真正意义上系统中的缓冲区,所以在本质上看来,用户级的缓冲区就只是一个buffer数组而已,并且知道,在用户层设置这个缓冲区的意义,目的就是为了可以减少调用系统调用的次数,因为系统调用是需要时间的(存在效率问题),所以为了提高效率,在用户层,就需要去封装一个缓冲区,用于存储需要调用系统接口去写入到外设中的数据,例:寄送快递,快递站肯定是一批一批的寄,不可能一件一件的寄 ,同理缓冲区的作用也就是如此,还要注意,数据之间的传递使用的是 拷贝 的形式,具体如下图:
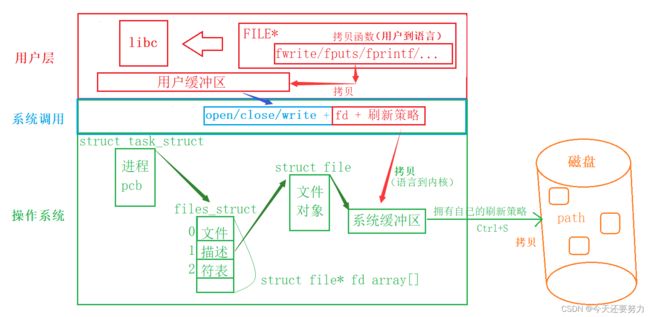
通过上图,我们可以发现,上述知识在基础IO中是属于用户层级别缓冲区的理解和使用,所以根据上图操作系统中的知识,此时我们来看一看系统中的缓冲区吧!并且对于操作系统中的文件对象、文件描述符表和被打开文件与进程之间关系的知识,在之前的博客中都进行了详细的讲解,这里就不多做了解了,重点搞定系统缓冲区,如上图,我们使用C库中的接口fprintf写入一个数据,此时经过两次拷贝之后来到了系统缓冲区中,所以此时身为缓冲区,无论是用户层面还是系统层面,在我们看来本质只是一个用来临时存储数据和拥有自己的刷新策略的数组而已(当然系统缓冲区可能是一块物理内存),并且目的还是一样的,就只是想要提高效率,因为从系统缓冲区将数据拷贝到外设,本质上是需要使用文件对象中的函数指针去调用外设驱动程序对应的读写函数的,同理,调用驱动程序的读写接口,需要时间,应该避免频繁调用,所以系统缓冲区的作用同理用户缓冲区。并且知道,系统缓冲区的刷新策略和用户缓冲区的刷新策略是不同的,系统缓冲区的刷新策略更加的复杂,需要根据内存的使用情况和CPU来提供相应的刷新策略,例如:平时我们害怕电脑在没把数据保存之前断电,此时这种情况,就是属于数据全部都存储在了系统缓冲区中,还没有被拷贝到外设中,解决方法就是使用Ctrl+S的方式,所以此时的Ctrl+S的方法就等于是一种将数据刷新到外设的手段,当然手段还有很多,例如,使用系统接口,强制刷新系统缓冲区中的数据,如下:fsync(fp->fd)
深入理解printf和scanf
明白了上述的知识之后,此时我们就以我们在C语言中经常使用的printf和scanf来举例,看一下这两个用户接口到底是如何工作的呢?理解如果工作之前,我们首先要明白一点,就是无论是printf还是scanf,它的结尾都是 f ,所以要注意的是,它们本质上都是格式化接口,都会对输入和输出的数据进行格式化 ,明白了这点之后,接下来,我们就来看看输出接口的工作原理吧!
printf
假设此时有一个变量int a = 123456;此时在我们看来,这个123456代表的就是一个整形十二万三千四百五十六,而在编译器看来,此时它就是一个字符串,所以当我们使用 printf("%d\n",a);它的第一步工作是获取对应的变量,第二步是定义缓冲区,然后将变量对应的数据进行格式化(格式化成字符串形式),第三步是将字符串拷贝到stdout->buffe中(调用系统接口write完成),第四步就是结合刷新策略刷新缓冲区,所以综上考虑到printf接口的使用模式,此时我们就知道了,平常我们使用printf打印一条语句,例:printf("hello world\n");这个本来才是printf的真正使用,像上述的打印一个整形,不过只是因为printf具有格式化的能力,所以也可以打印而已,具体原理:进行字符串的遍历,如果遇到了 % 就进行格式化,格式化的具体类型,就看%后面的数据,如果是d此时就将该字符串格式化成整形,同理……
总:printf的本质就是用来打印字符串的,只是因为其具有将字符串格式化的能力,所以可以进行整形等类型数据的打印而已
scanf
第一步,直接进行读取,调用系统接口read,将数据读取到stdin->buffer(标准输入缓冲区中),第二步对缓冲区中的数据(buffer数组)进行格式化,第三步,将标准输入文件中的数据,写入到对应的变量中
,例:int a,b; scanf("%d %d",&a,&b); 调用系统接口read,read(0,stdin->buffer,num);将对应的数据写到标准输入文件的缓冲区中,此时由于标准输入文件就是我们的键盘,所以此时我们就可以从键盘中输入数据,并且将我们输入的数据存储到标准输入文件对应的缓冲区中,所以可以明白,我们从键盘中输入的数据本质上也是以字符串的形式进行的输入,所以此时标准输入缓冲区中,就是以字符串的形式存放,所以此时同理去遍历标准输入缓冲区中的字符串,遇到空格就切割成两个子串,然后使用atoi接口,将字符串类型转换成整形
文件系统
搞定了上述知识和之前几篇博客的知识,此时我们就明白了进程和被打开文件之间的关系,以及一些列的有关知识,所以此时我们就将操作系统中的文件给搞明白了,所以接下来我们就去看看不在操作系统中的文件(在外设中的文件),如何存储和供给调用 ,如下:
什么是磁盘文件
首先,我们要明白,一个文件如果不在内存之中,此时应该在哪里呢?了解到,一个文件如果不在内存之中,那么此时它只能是在磁盘等外设中静静存储着,只有当它被打开时,它才会被加载到内存(冯若依曼规定),并且因为之前我们学习的是被打开文件和进程之间的关系,也就是操作系统中的文件知识,所以此时我们就来了解一下操作系统以外的文件,也就是没有被打开的文件,目的:理解文件的动态特征和静态特征,从静态文件和动态文件两个方面看文件的本质,如下,以一个场景开始话题:
场景:一个快递没有被拿回家,还在菜鸟驿站中存储着,为什么要存储在菜鸟驿站呢?主要就是为了解决:快速定位,便于整理(快速读取和写入)
所以类似于上述的场景,我们在管理磁盘文件时,也应该模拟该模式,先定位文件,其次才是读取或者写入文件
了解磁盘的物理结构
磁盘详解
在以前,我们的电脑存储数据用的都是机械磁盘,但是随着科技的进步,机械磁盘逐渐被固态硬盘(SSD)替代,如下:就是我们现在电脑中的固态硬盘图片和以前电脑中的磁盘

磁盘逐渐被固态硬盘取代的原因就是因为,固态硬盘的读写速度和数据存储安全性方面相比于磁盘是更加优异的,但今天我们的重点不是学习固态硬盘,而是学习磁盘,所以让我们以磁盘为出发点,深入了解一下磁盘吧!
磁盘内部图片如下:

如上如所示,就是磁盘的物理结构,磁盘盘面类似于很久以前见过的光盘(CD),但是这两者是有区别的,磁盘不仅支持读数据,它也支持写数据,而CD则不支持写数据,只支持读数据,并且要知道磁盘在读写数据的过程,具体原理是因为磁生电和电生磁的概念,这里我们就不多做了解,感兴趣的同学可以参看上述的磁盘详解链接,本质:正负、0 1原理,万物都可以用0 1区分,所以数据也是同理,而我们的正负电,就是一个0 1最好的表征方式
磁盘具体物理存储结构
本来有关硬件层面的知识和我们都没有太大的关系的,例如什么切割磁感线等知识,但是为什么我们还要研究磁盘的存储结构呢?其实目的就是:尝试在硬件上,理解数据的一次读和写,也就是尝试着理解数据在硬件上存储的本质就行了,具体的存储原理我们不关心,但是涉及到我们需要调用外设的驱动程序存储数据的时候,我们就应该了解,驱动程序具体是如何将数据写入或者读取,所以我们就可以以磁盘为例,来看看外设都是如何进行读写操作的,所以凭借上述的知识,我们大致可以知道驱动程序想要将数据写入外设,或者想要从外设中读取数据,都是通过0 1的形式来工作的,因为以磁盘为例,磁盘只能通过正负,0 1来区分数据,所以可以猜想,驱动程序想要交互,也必须以0 1进行,如下图:
一片磁盘上的物理存储结构:

从该图我们可以看出 ,一个扇面可以被分成多个扇区,并且注意:一个扇区是512个字节(4kb),并且可以知道,每个扇区都有不同的磁道,所以可以看出,同半径的所有扇区,它们是处于扇面的同一磁道,所以此时磁盘以这个结构涉及,磁头就可以很好的通过磁道的不同和扇区的不同,进行不同扇区,不同磁道上的数据的读写,所以如下图: 可以发现,磁头是有固定类型和移动类型的,并且磁盘是通过许多的扇面构成,不仅仅只有一个扇面,
整个磁盘具体物理存储结构:

注意:不同的磁盘的设计策略是不同的,例如上述磁盘,是通过磁头的移动来进行不同扇区中数据的读写的,但是有的磁盘磁头是被固定的,只能通过不同扇区上的不同磁头来读写数据,如下图:
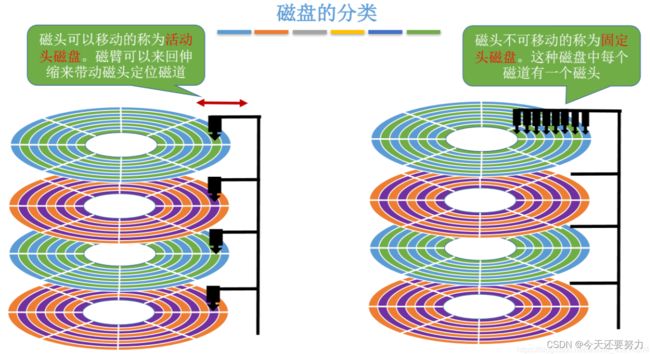
所以定位磁盘上的数数据,使用的就是CHS定位法:第一步确定哪一个扇面(通过磁头解决),第二步确定磁道,第三步确定磁道属于的扇区
明白了上述磁头是如何定位一个磁盘上的数据时,此时我们可以推测,如果操作系统可以通过磁头获取的这个数据的地址从而来获取磁盘上的数据,那么操作系统就可以间接访问磁盘上的任意一个位置的数据了,那么我们的这个推测是正确的吗?
显然,我们这个推测是不正确的,首先,我们电脑中的磁盘是可以别替换的,所以如果磁盘被替换,那么操作系统接收的磁盘中的数据位置就会发生很大的改变,操作系统是不允许发生很大的改变的,所以想要获取磁盘上数据的位置,操作系统就需要和磁盘进行一个解耦工作,避免因为磁盘发生改变,而导致操作系统发生改变,而是让解耦工作去适应不同的磁盘,操作系统通过获取解耦之后的数据位置来访问磁盘数据,这样更加安全和可靠,所以总的来说,操作系统想要访问磁盘上的数据就需要通过解耦的形式构建一个自己的新地址
磁盘的抽象理解
如下图,我们可以通过磁带来抽象理解磁盘:

所以根据上图,我们可以将物理磁盘抽象成线性,将磁道抽象成一段相同的磁带,所以我们就可以将磁盘上的磁道给抽象成一个一个的数组(数组之间是以扇区分割),最终我们就将磁盘以磁道的形式抽象成了一个一个的数组,所以此时我们就可以通过数组下标的形式去访问每个磁道上对应扇区的数据了,具体原理,通过扇区的不同来区分出不同的数组,例,1号扇区表示的就是对应磁道上的第一个数组,2号扇区表示的就是对应磁道上的第二个数组,如下图所示:
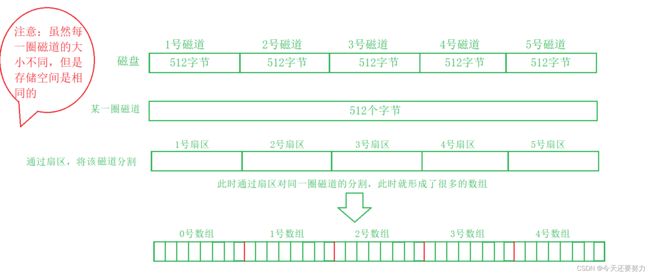
所以如果按照上述的理论,我们将磁盘给抽象成了这个样子,那么此时操作系统就可以通过以4kb(512字节)为单位对磁盘中的数据块进行读写操作,所以在操作系统的角度下,它并不关心扇区!操作系统想要找到一个数据块(也就是一个扇区),只要知道起始扇区,然后通过偏移量的相加,就可以很好的进行下一个或者几个数据块位置的获取(LBA.逻辑块地址),获取到了该数据块的地址之后,本质又因为该数据块是一个数组,所以此时我们就可以通过数组下标的形式对这个数据块进行读写;
所以计算机的常规访问形式,起始地址+偏移量(数据类型),从而进行地址访问,获取第一个地址,所以我们只要知道第一个扇区的起始位置,然后+4kb(块数据类型),此时我们就可以获取到一整个块类型的数据(类比获得一个int类型的数据),并且块的地址,本质就是一个数组下标,此时就可以用数组下标的方式,定位任何一个下标,然后访问该下标上的数据
明白了上述知识之后,我们就知道了,磁盘是通过CHS的方法定位数据,而操作系统是通过LBA的方式定位数据,所以磁盘和操作系统是存在一定的耦合关系的,所以如果想要让操作系统获取到磁盘上的数据,此时就需要进行一个解耦操作,而这个解耦工作,本质上就是通过加减乘除,一定的运算来实现的,这里不多做讲解,感兴趣的同学可以参考该链接:LBA和CHS之间的转换
总:通过抽象的方式,此时操作系统对磁盘的管理,通过先描述,再组织的方式(struct block),就变成了对一个数组的管理!
正式学习文件系统
有了上述的知识,此时我们就可以进入文件系统的学习了,文件系统的本质就是操作系统对磁盘上的数据进行管理的方式,通过日常生活的理解,解决一个大问题,我们都是将问题划分成一个一个的小问题,管理一个大数据,我们都是通过划分成一个一个的小数据,所以此时操作系统想要管理磁盘上的文件不仅仅是对数组进行管理那么简单,因为磁盘上的数据过于庞大了,所以此时我们以日常生活中为例,通过分治的方式让操作系统完成对磁盘上数据的管理。
所以此时通过分治的概念,我们就可以把一整个磁盘先分成若干份,如下图所示,分成C盘和D盘:

然后在C盘和D盘内部进行进一步的分区,将磁盘划分成一个一个的小区间,这样,我们只要把一个小区间管理好之后,其它的小区间就依葫芦画瓢进行管理,这样,我们就可以将一个庞大的磁盘数据,给有序的管理好,这样操作系统在读写磁盘的时候,就可以凭借很高的效率完成
如何管理好一个小区间
所以明白了上述知识,此时就可以知道,我们还是通过先描述再组织的方式对一个一个分区进行管理,谈到先描述再组织,此时就又涉及到了结构体,所以本质上,我们还是通过结构体的方式对磁盘进行管理,例如:分成几个区,我们可以如下这样表示,然后再将每个区进行分组
struct disk
{
struct part[4];
.....
}
每个组如何管理,我们可以这样表示:
struct part
{
struct part group[100];
int lba_start;
int lba_end;
.....
}
如上,我们就可以通过控制每个区间的每个组的开始位置和结束位置来进行对每一个区间的管理,如下图,就是一个组中的详细管理模式:
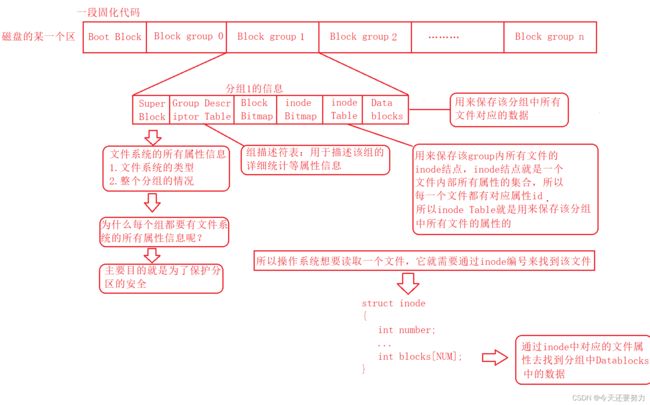
注意:文件系统每次访问外设都是4kb,所以无论你写入多少数据,操作系统每次都是开辟4kb空间使用
总结:摆烂归摆烂,只要不放弃就行,哈哈哈!!!
#include