SQL(1)
说明:
1、适用MySQL,其余DBMS语法会略有差异,具体操作参考对应手册。
2、由于篇幅限制,多表查询、子查询、窗口函数见后续笔记
3、在夜曲编程课程的基础上结合《SQL基础教程(第2版)》整理的笔记。
前者:一笔带过了不少细节。但总算建立了基本框架,知道都有啥。
后者:比较《SQL必知必会(第4版)》后选择了基础教程,主要在于整体排版阅读起来非常舒适;图表展示很清晰,尤其是提示了NULL值这点很受益(参见“聚合统计”一节)
但最推荐的还是宋红康老师的全套视频和讲义,边敲代码边对照讲义讲解很清晰;同一道题会展示多种查询方法,演绎式(问题式)和归纳式教学相结合,还融入了阿里开发要求;易错点等细节听视频时更有记忆点。【宋红康】MySQL数据库(mysql安装/基础/高级/优化)_哔哩哔哩_bilibili
#顺便唠一下挑选学习资料:
1、入门还是把基础学的扎实些,网上给出的重点框架更多是学完后对照看有无遗漏的。
2、选择一个老师的视频/一本教材先踏实跟下来,没有完美的资料,建立基本框架后再针对性查缺补漏。
3、资料选择标准:播放量/推荐量;视频、讲义完整,别人做的笔记;评论里多为关于课程内容本身的讨论的,确切指出课程优缺点的,往往不错;边敲代码边讲的(拒绝纯念PPT的!!!)
初步筛选后,挑某个章节,完整听下来不同老师的讲课风格,自然就做出更适合自己的选择了。
目录
基础查找
SQL子句书写顺序:
SQL子句执行顺序:
SELECT
WHERE
ORDER BY
LIMIT
聚合统计
聚合函数
COUNT计数函数
SUM(列名) 和AVG(列名)
MAX(列名)和MIN(列名)
业务——ROI
日期函数
字符串函数
转换函数
算术函数
分组与数据统计
使用GROUP BY和聚合函数需要注意的要点:
HAVING子句注意要点
ORDER BY排序注意要点
业务——RMF模型
业务——互联网流量分析
业务——互联网复购分析
MySQL运行环境
对Windows系统进行MYSQL安装
如何用VScode操作MySQL
python与MySQL的交互
数据库——表格——数据
数据库的创建(CREATE)
表格的创建、增加、修改和删除(CREATE,ALTER,DROP)
数据的插入、更新和修改(INSERT INTO……VALUES;UPDATE;DELETE;INSERT……SELECT)
数据库与SQL
数据库概要
SQL语句种类:DDL(数据库和表)、DML(数据;90%)、DCL
SQL基本书写规则
表的命名规则
数据类型
主键和外键的概念
基础查找
SQL子句书写顺序:
SELECT——FROM——JOIN——ON——WHERE——GROUP BY——HAVING——ORDER BY——LIMIT
命令结束用分号结尾。
SQL子句执行顺序:
FROM——ON——JOIN——WHERE——GROUP BY——HAVING——SELECT——DISTINCT——ORDER BY——LIMIT
# MySQL中,GROUP BY及之后的语句中可以使用SELECT语句中的别名。(不同DBMS有所差异,其他DBMS的判断标准:SELECT之后的语句可以使用SELECT语句中的别名,SELECT之前的语句如GROUP BY,HAVING不可以)
MySQL SQL语句书写顺序和执行顺序 - 楼兰胡杨 - 博客园

SELECT
1.查询的内容即为最终所要呈现的所有字段;多个字段用逗号隔开。
2.SELECT * 表示查询表格中的所有字段。
WHERE
相当于Python中的if条件,常见判断场景如下:
1.比较运算符
1)= 表等于,在SQL中可以用于对数值、时间、字符的比较;时间数据和字符数据要加引号;时间数据若只限定到"x年-x月-x日",SQL数据会默认为这一天的零点整。
# python:==表等于;=表赋值
2)<> 表不等于;!= 表不等于。
#python:!= 表不等于
2.缺失值表示无法提供有效数据
# 某行数据为空
WHERE phone_number IS NULL
# 某行数据不为空
WHERE phone_number IS NOT NULL3.BETWEEN...AND...在两个范围之间;
...IN (a,b,c,d) 可筛选多个范围,表示 或。
多个条件的连接:1)AND 且;OR 并; NOT 非。2)可用小括号指定优先级(注意列中有NULL值的情况)


4.关键字LIKE和通配符的搭配使用
% 表0到任意数量个常规字符;_ 表一个常规字符(写2个__就表示2个常规字符啦)
# 找11月份的订单
WHERE order_time LIKE '%-11-%'
# 找带买家秀的评论(即含图片)
WHERE text LIKE '%ORDER BY
# ORDER BY 默认升序排列,写省略ASC;DESC为降序排列。
# 对于时间来说,数值从小到大为升序:2019年——2020年——2021年(ASC);
# 2021年——2020年——2019年(DESC)
ORDER BY total_price (ASC),order_time DESCLIMIT
# 取前3位
LIMIT 3
# 跳过前3位再取10个数据,即第4位到13位的数据;注意不同于Python函数,不需要用小括号
LIMIT 3,10DISTINCT:对某个字段去重。
聚合统计
聚合函数
聚合函数:对一组值进行计算,并返回单个值。
除COUNT(*)外,其余聚合函数会将NULL值排除在外。
所有聚合函数都可以用DISTINCT去重。
所有聚合函数都可以进行列与列之间的加减乘除运算。
COUNT计数函数
COUNT(*) 统计包含NULL的所有行数
COUNT(列名) 统计NULL以外的行数
COUNT(DISTINCT 列名) 统计去重后的行数
SUM(列名) 和AVG(列名)
都会删除NULL值再进行计算;
只适用于数值类型的列;
注意:
若8行数据中有2行NULL值,AVG()计算时分母为6;
也可将NULL值作为0计算,此时分母为8。
MAX(列名)和MIN(列名)
都会删除NULL值再进行计算;
几乎适用于所有类型的列。如时间类型date列:2020-1-1;2021-12-1;2022-1-5。此时MAX(date)=2022-1-5;如text列:C;B;A。此时MAX(text)=C.
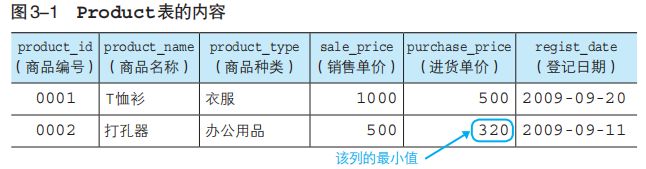

思考:订单数量要和平均数的计数口径一致吗?

业务——ROI
投资回报率ROI=产出/投入=销售收入/成本
ROI>1时,表示收益大于投入费用,可以继续投入。
ROI=1时,表示投入效果和收益持平,一般可以继续投入。
ROI<1时,除非有特殊用途,如烧钱扩大知名度,一般情况下会停止投入。
日期函数
# SQL的日期函数大部分依存于各自的DBMS,因此在不同的DBMS中语法略有差异,使用时建议查阅各个DBMS的官方手册。时间函数MySQL官方文档链接如下:
MySQL :: MySQL 5.7 Reference Manual :: 12.7 Date and Time Functions
CURRENT_DATE 当前日期2016-05-25
CURRENT_TIME 当前时间17:26:50.995+09
CURRENT_TIMESTAMP 当前日期和时间2016-04-25 18:31:03.704+09
# 以上3个函数没有参数,因此无需使用括号
EXTRACT(日期元素 from 日期) 截取日期元素,截取出“年”、“月”、“分”、“小时”、“秒”等。
DATE(日期表达式) 提取日期部分


NOW() 当前日期和时间
TIMESTAMPDIFF(YEAR, 较远日期, 较近日期) 计算日期中的整数差
DATEDIFF(日期表达式1,日期表达式2) 日期之差


DATE_ADD(日期表达式,INTERVAL 数字 DAY/YEAR) 增加时间间隔
DATE_SUB(日期表达式,INTERVAL 数字 DAY/YEAR) 减去时间间隔

字符串函数
字符串函数官方文档如下:
MySQL :: MySQL 5.7 Reference Manual :: 12.8 String Functions and Operators
CONCAT(字符1,字符2,字符3……) 连接字符串函数
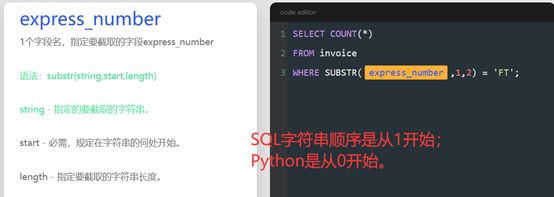
SUBSTR(对象字符串, 截取开始位置,截取的字符数) 截取字符串函数,顺序从1开始
LEFT(对象字符串,字符数) 左截取指定字符数
RIGHT(对象字符串,字符数) 右截取指定字符数
INSERT(对象字符串,开始替换位置, 替换的字符个数, 插入的字符) 在指定位置插入指定字符数的字符串
LENGTH(对象字符串) 计算字符串长度;对1个字符使用LENGTH函数有可能得到2字节以上的结果:与半角英文字母占用 1 字节不同,汉字这样的全角字符会占用 2 个以上的字节(称为多字节字符)。同样是 LENGTH 函数,不同 DBMS 的执行结果也不尽相同 。
LOWER(对象字符串) 将英文字符转换成小写
UPPER(对象字符串) 将英文字符转换成大写


转换函数
算术函数
分组与数据统计
使用GROUP BY和聚合函数需要注意的要点:
1、聚合键中包含NULL值时,在结果中会以“不确定”行(空行)的形式表现出来。


2、一般地,使用GROUP BY子句中,SELECT子句中不能出现聚合键之外的列名(MySQL除外)。 # 使用聚合函数时,SELECT子句中只能存在以下三种元素:常数;聚合函数;GROUP BY子句中指定的列名(聚合键)。


3、一般地,GROUP BY子句中不能使用SELECT子句中定义的列名(MySQL除外)。
4、GROUP BY子句的结果显示是无序的。多次执行同样的SELECT语句,得到结果可能会按完全
不同的顺序排列。
5、在WHERE子句中使用聚合函数会引发错误。只有SELECT子句、HAVING子句和ORDER BY子句能够使用聚合函数。
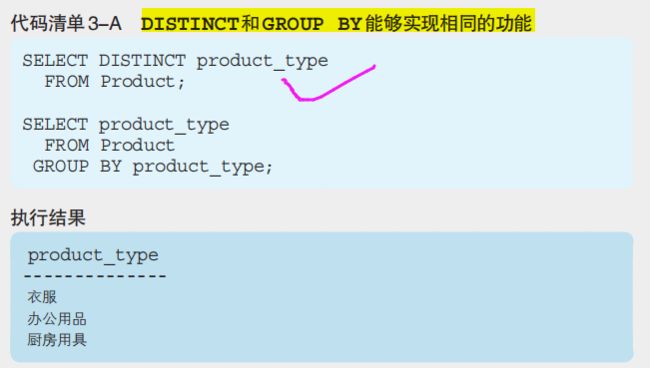
6、DISTINCT和GROUP BY能实现相同功能,执行速度也差不多。两者选择标准在于:
在“想要删除选择结果中的重复记录”时使用 DISTINCT,在“想要计算汇总结果”时使用 GROUP BY

HAVING子句注意要点
1、HAVING子句能够使用的3种要素:常数;聚合函数;GROUP BY 子句中指定的列名(聚合键)。# 在思考 HAVING 子句的使用方法时,把一次汇总后的结果(类似表 3-2 的表)作为 HAVING子句起始点的话更容易理解。


2、聚合键所对应的条件不应该书写在HAVING子句当中,而应该书写在WHERE子句当中。原因:
1) WHERE 子句和 HAVING 子句的作用不同。
2)一般地,为得到相同结果,将条件写在WHERE子句比写在HAVING子句执行速度更快。原因:
a、使用 COUNT函数等对表中的数据进行聚合操作时,DBMS 内部就会进行排序处理。只有尽可能减少排序的行数,才能提高处理速度。通过 WHERE 子句指定条件时,由于排序之前就对数据进行了过滤,因此能够减少排序的数据量。但 HAVING 子句是在排序之后才对数据进行分组的,因此与在 WHERE 子句中指定条件比起来,需要排序的数据量就会多得多。
b、可以对 WHERE 子句指定条件所对应的列创建索引,这样也可以大幅提高处理速度。



ORDER BY排序注意要点
1、没有ORDER BY子句时,SELECT语句的结果是随机排序的。

3、在ORDER BY子句中可以使用SELECT子句中定义的别名。
4、在ORDER BY子句中可以使用SELECT子句中未使用的列和聚合函数。
业务——RMF模型
衡量客户价值的模型。
R即最近一次消费(Recency),通过计算最近一次消费与今天的时间间隔来得到R值。最近一次消费时间越近,则用户价值越大。
F即消费频率(Frequency),通过“对用户分组+去除空值+COUNT(*)”得到F值。消费频率越高,则用户价值越大。
M即消费金额(Monetary),通过“对用户分组+SUM()”得到M值(用户各自消费金额的求和)。消费金额越高,则用户价值越大。




(第5、6行使用别名:MySQL中GROUP BY及之后的子句都可以使用SELECT语句中的别名)
业务——互联网流量分析
1、四种behavior_type:pv——浏览访问页面;buy——购买;cart——加入购物车;fav——收藏
2、日PV(page view):每页页面访问量,用于追踪活动前/中/后的流量变化情况。一般来说,活动期间或当天访问量大幅提高,活动后后一定程度的回落,可以认为是一个成功的活动。
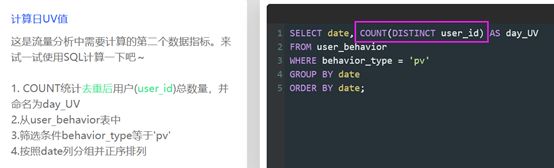
日UV(unique view):每日访问的人数。eg使用同一台电脑,IP+1,但因为登录2个不同账号,故UV+2。在同一天内,同一个账号的第一次访问记录会被记录,而之后的访问记录不计数。
人均页面访问量=日PV/日UV
3、实例:
统计日PV:按date分组并正序排列+COUNT满足behavior_type等于PV的行数。
统计日UV:按date分组并正序排列+COUNT去重后的user_id的行数。


业务——互联网复购分析
1、用户复购率=单位时间内:购买两次及以上的用户数/有购买行为的总用户数
订单复购率=单位时间内:第二次及以上购买的订单数/总订单数
复购率:说明用户的忠诚度;也说明商品或服务的用户粘性。
2、实例:用户复购率=复购用户/购买用户总数
复购用户:按用户user_id分组+初始筛选behavior_type等于buy+分组后筛选购买次数大于等于2
购买用户总数:正确操作是COUNT去重后的user_id的个数;而不是利用分组来做。

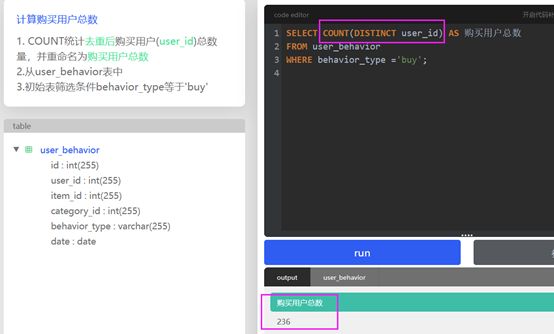


MySQL运行环境
对Windows系统进行MYSQL安装
1、安装MySQL(牢记密码)
2、安装VScode——在VScode中安装MySQL插件 # 也可选择Navicat,MySQL workbench等可视
化工具。
3、在VSCODE中创建与MYSQL的连接
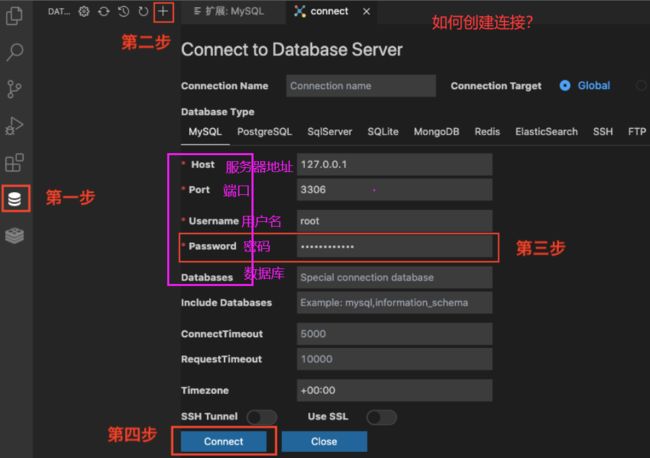
如何用VScode操作MySQL
1、如何在VScode中新建数据库
法1:点击数据库栏内右上角的➕ 号,输入新的数据库名并创建。
法2:CREATE DATABASE 数据库名 CHARSET=utf8mb4; #支持中文显示的编码规则utf8mb4

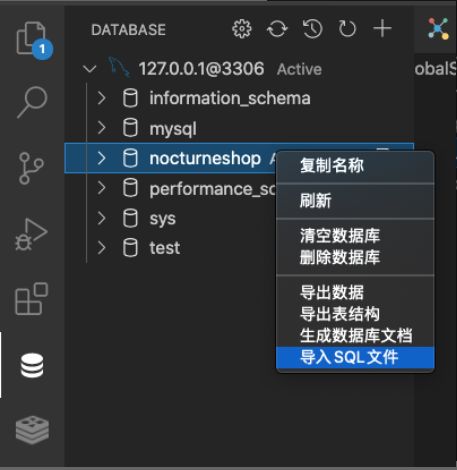
2、如何在VScode中导入SQL文件
创建数据库——导入SQL文件
3、常用查询语句:
SHOW DATABASES; 展示当前所有数据库;
USE 数据库名; 选择要操作的数据库;
SHOW TABLES; 查看该库的所有表;
SELECT 子句; 对特定的表进行查询;
4、SQL文件是数据库执行语句的脚本文件,可用记事本、VScode等打开。
python与MySQL的交互
交互要求安装:python;MySQL;pymysql。
交互语法:(在python中写代码?)
1、安装导入:import pymysql
在Python中,我们通过pymysql这个模块来驱动MySQL工作。
2、创建连接/关闭连接:连接变量=pymysql.connect(5个要素); 连接变量.close()
通过pymysql中的connect()类创建Python与MySQL之间的连接。
3、创建游标/关闭游标:游标变量=连接变量.cursor(); 游标变量.close()
未设定游标规则时:在结果集生成的同时,SQL会创建一个游标,并处于结果集的第一行数据之前。在默认情况下,游标会直接读取该位置之后的所有行数据并输出。
游标:操作结果集的工具,可以帮我们记录读取数据时要开始的位置和要结束的位置。eg第一次显示1~3行;第二次显示4~5行;第三次显示6行。这样交互式的输出。
4、存储SQL指令:SQL="' "'
执行SQL指令:执行变量=游标变量.execute(SQL)
输出执行结果总行数:print(执行变量)
5、获取数据:在pymysql中,cursor 提供系列的 fetch 方法,用来控制游标从结果集中读取内容。
游标变量.fetchone()
游标变量.fetchmany(要读取的行数)
游标变量.fetchall()
6、提交结果并生效:连接变量.commit()
# 使用execute执行INSERT、UPDATE、DELETE这类DML语言时,数据库本身并未被修改,只返
回该操作影响的行数。当手动提交commit()后,数据库被修改。

数据库——表格——数据
数据库的创建(CREATE)
见:如何在VScode中新建数据库
表格的创建、增加、修改和删除(CREATE,ALTER,DROP)
1、表格的创建:CREATE TABLE
1)若MySQL储存多个数据库,法1:USE 数据库名;
法2:使用数据库名对表进行限定:数据库名.表名;
2)为避免表名与关键词重复时产生冲突,用反引号``把表名、字段名括起来;
3)表结构:字段、数据类型、约束;创建出来的是表头及单元格输入约束。

2、表格的新增:ALTER TABLE 数据库名.表名 ADD 字段名 数据类型 约束
3、表格的修改:
改字段名称和结构;ALTER TABLE 数据库名.表名 CHANGE 被修改的字段名 修改后的字段名 修改后的数据类型 约束
只改字段结构;ALTER TABLE 数据库名.表名 MODIFY 被修改的字段名 修改后的数据类型 约束

4、表格的删除(谨慎使用):
删除整个表:DROP TABLE 数据库名.表名;
删除表中的某个字段:ALTER TABLE 数据库名.表名 DROP被删除的字段
数据的插入、更新和修改(INSERT INTO……VALUES;UPDATE;DELETE;INSERT……SELECT)
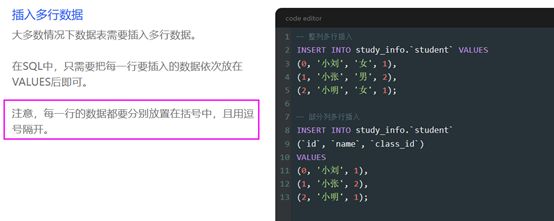
1、数据的插入:INSERT语句
全列插入与部分列插入;插入多行数据

某列插入NULL:可以直接在 VALUES子句的值清单中写入 NULL。但是,想要插入 NULL 的列一定不能设置 NOT NULL 约束。
插入默认值DEFAULT 约束:建议大家使用显式的方法。因为这样可以一目了然地知道 sale_price 列使用了默认值,SQL语句的含义也更加容易理解。隐式方法:省略INSERT语句中的列名,就会自动设定为该列的默认值(没有默认值时会设定为NULL)。


2、数据的更新:UPDATE语句
UPDATE 表名 SET 字段名=修改后的值 WHERE 筛选条件(大多通过主键判断)
可筛选1行或多行(多列更新)


3、数据的删除:DELETE语句
DELETE FROM 表名 WHERE 筛选条件
4、从其他表中复制数据:INSERT……SELECT语句


数据库与SQL
数据库概要

SQL语句种类:DDL(数据库和表)、DML(数据;90%)、DCL

SQL基本书写规则
- 以分号结尾。表示查询结束
- 不区分大小写。但为了代码的可读性,推荐在编写SQL代码时关键字统一使用大写字母,要查询的数据(表名、字段名等)使用小写。(插入到表中的数据是区分大小写的)
- 逗号分隔。要查询的数据(表名、字段名等)使用英文逗号分隔。
- 不限制代码缩进格式。推荐在编写SQL代码时,通过换行与缩进来提高代码的可读性。
- 关键字的顺序要求严格。比如在一次查询语句中,SELECT一定要写在FROM之前。
- 单词之间需要使用半角空格或者换行符进行分隔。
- 常数:在 SQL 语句中直接书写的字符串、日期或者数字等称为常数。字符串和日期常数需要使用单引号(')括起来。 数字常数无需加注单引号(直接书写数字即可)
表的命名规则
1、数据库名称、表名和列名等只能使用以下三种字符。
数据类型
主键和外键的概念

#一些没有停留在原地的记录#
被动完成一个个任务,没有总结出可复制的行为模式,导致总是处在thoughtless的状态,每次任务出现时好像都是新的、不确定的。
解决方式:1.经典教材学习,搭建基本框架和分析思路。2.广泛阅读,积累commercial sense,对人和世界运行的认知。3.应用层面:实习;对某个问题的主题性研究;对日常现象的思考。
20220126:面对新知识,我很依赖优秀的视频教程,因为没什么通过阅读掌握好知识的经历,所以对阅读还是不那么自信的。