流媒体学习之路——Google的新拥塞算法SQP详解
流媒体学习之路——Google的新拥塞算法SQP详解
文章目录
- 流媒体学习之路——Google的新拥塞算法SQP详解
- 一、摘要解读
- 二、算法相关
-
- 2.1 低延迟传输算法的特点
-
- 低队列延迟
- 公平性
- 友好性
- 视频意识
- 2.2 SQP算法原理
-
- 2.2.1 算法思想
- 2.2.2 公式分析
-
- 2.2.2.1 拥塞检测
- 2.2.2.2 最小单向传输延迟(△min)
- 2.2.2.3 带宽估计规则
- 2.2.2.4 pacing与数据增长方式
- 2.2.3 动态分析
-
- 2.2.3.1 算法竞争动态
- 2.2.3.2 竞争窗口值调优
- 三、能力评估测试
-
- 3.1 简单带宽共享
- 3.2 真实wifi场景测试
- 3.3 可排队网络下竞争
- 3.4 短时间发送表现
- 3.5 公平性
- 3.6 编解码支持能力
- 3.7 真实场景能力对比
- 四、总结
2022年7月25日,Google在arXiv平台上发布了一篇名为:SQP: Congestion Control for Low-Latency Interactive Video Streaming 的文章(这篇文章上下充斥着与Copa较量的意味,可能GCC被Copa比下去了很不爽,赶紧找了个场子)。文章内容详细介绍了他们为了应对低延迟场景设计的新拥塞控制算法,并给出了一些测试对比的效果,今天我们详细地看看这篇文章。

一、摘要解读
摘要一直是一篇学术文章最凝练的部分,在这里把整段摘要做个翻译:
本文介绍了SQP的设计和相关测试,它是一种用于交互式视频流应用的拥塞控制算法(CCA)。这些应用的特点是,往往需要以非常低的端到端帧延迟来传输高比特率的压缩视频(例如,AR流、云游戏)。
SQP使用帧耦合(frame-coupled)、有节奏的数据包发送(paced packet trains)来采样网络带宽,并使用自适应单向延迟测量(adaptive one-way delay measurement)来恢复排队——这样排队延迟可以更低,而且排队的量更少(这里原文为:bounded queuing,我觉得这里表达的意思是实现有限的排队量降低了排队延迟)。
SQP能迅速适应链路带宽的变化,确保高利用率和低延迟,并且在可接受的延迟网络下(acceptable delay envelope)与其他流量竞争,也展示了较强的带宽抢占能力。SQP具有良好的公平性,在具有浅缓冲区的链路上运行良好。
在谷歌AR流媒体平台进行的SQP与Copa的A/B测试中,SQP在LTE和Wi-Fi网络下(码率统计使用的是p50数据集——前50%的数据,低延迟统计使用的是p90数据集——90%的数据,关于数据集的大家可以看看这个解释:p50, p90, p99 (pct 50, pct 90, pct 99)指什么?),实现了高码率(> 3Mbps)会话数多27%、低延迟(< 100ms)会话数多15% 。在与Cubic和BBR等算法竞争时。SQP的带宽是GoogCC (We-bRTC)、Sprout、BBR的2-3倍,性能与带模式切换的Copa相当。
摘要中提到很重要的一点是:基于低帧延迟。我认为这里的前提假设是合理的,随着5g网络的普及以及硬件传输能力的不断迭代,低延迟网络会是未来的趋势,因此这个算法还算具备一定的前瞻性。
二、算法相关
2.1 低延迟传输算法的特点
一个可靠的低延迟传输算法需要满足一下几个特点:
低队列延迟
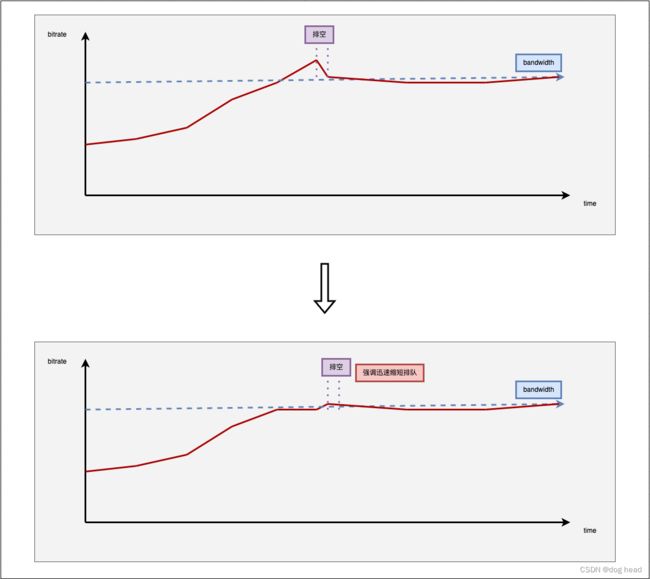
我们知道在进行带宽探测的时候无法避免的就是在带宽最大位置会过量发送数据而引发排队,类似于BBR、Cubic这类算法都会设置一个排空的阶段来进行。我们需要在带宽探测满的时候迅速地进行下调,实现降低排队延迟的特点。
公平性
公平性其实在拥塞中很重要,因为目前网络很多传输协议都会对丢失数据进行重传和补偿。当在一个拥塞网络中,我们在不顾公平性地抢占时只会导致其他算法触发补偿机制,导致网络更差进而影响自己的传输效果。当然,最重要的是保证了我们在与别的算法竞争时的稳定。文章中提到了Copa在混合流量竞争时会误测出排队的情况,导致收敛问题。
友好性
这里的友好性与上述的公平性其实类似,就是为了避免我们在整个网络竞争的过程中,减少其他流饿死的情况。其实这个特性需要根据业务来进行区分,类似需要集中流量的直播类、互动类业务,我们应该考虑尽量抢占带宽的前提下,不去将我们业务的其他流量完全抢占。
视频意识
这个就是SQP提出很重要的参考意见。因为我们在视频传输中编码器必须适应整个传输帧的大小变化,意味着视频的拥塞算法跟帧的完整性强相关,而SQP变更了以数据包为单位进行的传输统计,变为以帧进行。
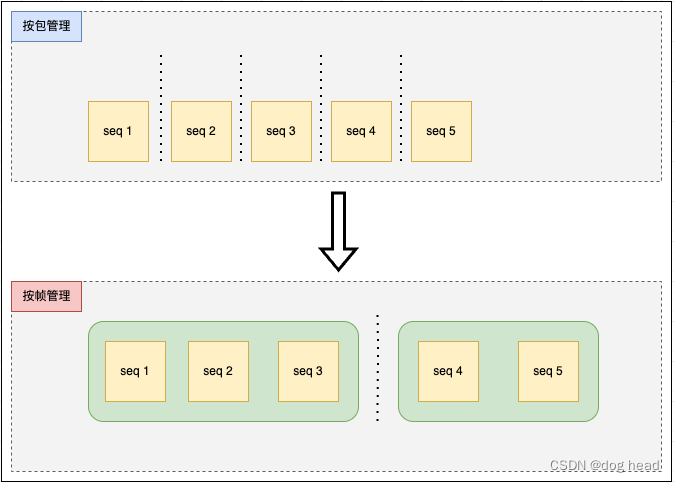
这样的思想按Google的测试结果来说似乎是可靠的。但整个网络传输过程是个非线性系统,完整帧的传输可能会引入误差,因此非常依赖低延迟的网络(一是可快速重传、帧之间传输的偏差不大)才能保证算法的可靠性。
2.2 SQP算法原理
2.2.1 算法思想
- 优先考虑延迟而不是链接利用率:由于延迟对于低延迟的交互式视频流应用的QOE更为关键,所以SQP在独立运行时牺牲了峰值带宽利用率实现了低延迟和延迟稳定性。
- 应用定制化的权衡:SQP是为低延迟的交互式流媒体应用而设计的,它在最小带宽和最大延迟方面有特殊的要求。如果这些参数由于外部因素而超出了可接受的范围(例如,不良的链路条件,由于队列建设交叉流量而造成的非常高的延迟),它能够接受结束流媒体会话。与传统算法相比,SQP限制了它的运行环境,这使得SQP能够在更广泛的相关场景中实现可接受的吞吐量和延迟性能。
- 以帧为中心的操作:一般的拥塞算法都作用于网络排队这个阶段。不经常探测的拥塞算法(如PCC、GoogCC)有较低的平均延迟,但在可变链路上受到链路利用率不足。SQP通过将每一帧作为一个短的(有节奏的)突发事件来发送,并在收到每一帧的反馈后更新其带宽估计,从而将带宽测量捎带到每一帧的传输中。对于低延迟的交互式流媒体应用,QoE是由端到端的帧延迟决定的,而不仅仅是网络内的排队延迟。SQP网络探测依赖于子帧级别的排队,而不增加端到端的帧延迟,并且能够比PCC和GoogCC等协议更快适应网络带宽的变化。
- 直接视频码率控制:SQP使用帧级码率的变化来应对拥堵,并通过降低视频码率来耗尽自身过多发送导致的队列。与基于窗口的协议(Copa)或为网络RTT测量而限制传输的协议(BBR)相比,SQP的基于速率的拥堵控制将端到端的帧延迟降到最低。
- 竞争性吞吐量:SQP的带宽探测和采样机制默认为竞争性的,在与别的流竞争时,可实现稳定的高吞吐量。SQP使用自适应单向延迟测量、带宽目标倍增器和帧步调平衡机制,避免了高排队延迟和饿死其他流量。SQP的设计避免了使用显式模式切换的基于延迟的拥塞算法缺陷(例如Copa)。
2.2.2 公式分析
2.2.2.1 拥塞检测
首先SQP让人觉得困惑的是——将每个帧作为一个短的突发传输,发送的速度是比网络传输率要快的,这就造成了少量的排队,如果平均视频比特率低于可用的瓶颈链路容量,那么在下一帧到达瓶颈时,这个队列会被耗尽——这样的做法类似于主动引起网络排队然后排空、再引起排队再排空,也许在目前的网络环境下表现不会那么好吧。
接着SQP的逻辑往前捋,为什么一个帧一个帧的发会有利于我们做带宽探测呢?首先当前帧以最快的速度发出去,当此时网络出现不足时我们就会立刻感知到当前整体帧的传输出现问题了,那么下一帧发送时就会进行调整,这是SQP的思路。所以我们可以总结出SQP基本是在单独一帧的级别上就能感知到网络拥塞了(< 16.66 ms @ 60FPS)。这也是相比其他拥塞算法强的地方(PCC:2RTT, BBR:1 min-RTT, and Copa:2.5 RTT)。
因此,一帧的大小为F,每帧发送间隔为I,那么可得:码率 = F / I。而每帧的间隔我们可以根据每帧第一个包的发送时间(S-start)和每帧最后一个包接到的时间(R-end)相减获得传输一帧所需的时间。然而,我们传输过程的拥塞检测值依然需要一个与rtt类似的值来进行,这里提供了一个Δmin(最小单向延迟,也就是rtt/2)这个值——每帧每个包RTP时间戳的差值,理论上同一帧的采样打在帧上的时间戳是一样的,也就是Δmin 与 R-end - S-start 的差值一般为 0,同时这个值也是判断网络出现异常的很重要的一个值;
S = F R e n d − S s t a r t − Δ m i n (1) S = \frac {F} {R_{end} - S_{start} - \Delta_{min} } \tag{1} S=Rend−Sstart−ΔminF(1)
因为当Δmin 与 R-end - S-start 的差值出现异常时,意味着网络的传输已经与正常的统计最小值不同,也就是说网络出现了拥塞状态:
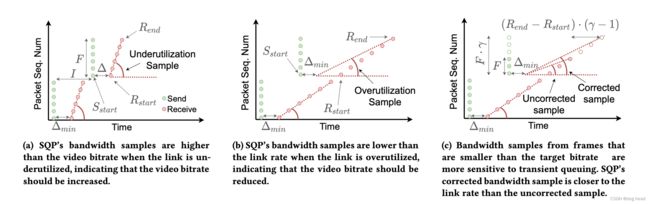
带宽充足时:Δ= - = Δmin保持不变,这是因为此时网络带宽充足,传输的数据状态如下图(a)类似;
带宽不足时:由于帧大小超标、带宽高估或网络带宽下降导致的短暂的过度利用,可能会导致在多个帧在网络中出现排队现象。这导致后续帧的Δ - Δ增加,从而降低了后续帧的带宽样本的斜率,这在下图的(b)中可以看出来;
视频编码器过热:这一条看起来好像有点摸不着头脑,但其实在对于完整帧估计有很重要的影响(原文提到的叫——Video Encoder Undershoot)。我们知道编码器在低复杂度的场景中,会提供较小的帧进行发送。这样会导致一个问题,就是可能出现小帧发送没有引起排队,但大帧发送导致了,前面的小帧发送统计的数据也会出现误伤。因此为了应对这种情况,SQP将公式做了一些调整:
S = F ⋅ γ R e n d − S s t a r t − Δ m i n + ( R e n d − R s t a r t ⋅ ( γ − 1 ) ) (2) S = \frac {{F}\cdot{\gamma}} {R_{end} - S_{start} - \Delta_{min} + (R_{end} - R_{start}\cdot{(\gamma}-1)) } \tag{2} S=Rend−Sstart−Δmin+(Rend−Rstart⋅(γ−1))F⋅γ(2)
γ = Fmax/F 是矫正系数,Fmax是没有过热情况的最大帧大小,然后我们需要通过(Rend - Rstart)· (γ - 1)来预测传输一个最大尺寸帧所需的额外时间来计算样本,由此计算得到带宽具体形式参考下图(c)。
2.2.2.2 最小单向传输延迟(△min)
我们最常听说的网络传输测量量为:RTT,指的是一个数据包的来回延迟。而这里提到的最小单向传输延迟可以理解为RTT/2,它在SQP中有很重要的意义——作为网络拥塞检测的关键指标。
这个最小单向传输延迟与拥塞窗口大小息息相关,SQP使用的是2×sRTT来作自适应窗口大小,有两个优点:
(1)不造成非常高的延迟;
(2)在2×sRTT期间可以实现既低延迟又高吞吐量。
而关于最小RTT这个参考量我们很容易就想到了BBR算法,但是在SQP与BBR比较的过程中,两个又不太相似。文章中提到了BBR算法将包显示探测的时间控制在200ms这句话,这里补充一点知识:
为了探测BBR.RTprop,BBR会周期性地进入ProbeRTT状态,排放瓶颈队列。当处于非ProbeRTT状态时,如果RTProp在ProbeRTTInterval = 10秒的时间内未被更新,BBR便会进入ProbeRTT阶段,并且减小cwnd到BBRMinPipeCwnd(4个包)。在维持BBRMinPipeCwnd或少量传输中的包至少ProbeRTTDuration(200ms)和一个往返后,BBR将退出ProbeRTT阶段,转移到Startup或ProbeBW阶段,这取决于管道是否以及被填满。
ok,也就是说在传输的过程中,BBR为了不造成过度排队,是以定期进入ProbRTT状态来排空的,并且最低限制了一个RTT或者200ms的时间。而SQP中,每一次全帧发送都可能造成排队,文章将这个行为解释为——这是一次隐式的探测。它避免了像BBR那样定期引入的延迟(200ms)。
2.2.2.3 带宽估计规则
SQP的带宽估计规则是根据:F. P. Kelly, A. K. Maulloo, and D. K. Tan, “Rate control for communication networks: shadow prices, proportional fairness and stability,” Journal of the Operational Research society, vol. 49, no. 3, pp. 237–252, 1998 这篇文章来设计的。给出了一个对数公式:
m a x l o g ( 1 + α ⋅ B ) − β ⋅ ( B − e ) 2 (3) maxlog(1+\alpha \cdot B) - \beta\cdot(B - e)^2 \tag{3} maxlog(1+α⋅B)−β⋅(B−e)2(3)
文章的内容也大致地看了一眼,里面建立了一个Lyapunov函数,冗长的数学推导。目标就是要得到一个比较合理的带宽估计值。将上面的公式转化为导数公式:
B ′ = B + δ ( r ( S B − 1 ) − ( B S − 1 ) ) (4) B' = B + \delta(r(\frac{S}{B} - 1)-(\frac{B}{S}-1)) \tag{4} B′=B+δ(r(BS−1)−(SB−1))(4)
B’是下一个带宽估计值,B是当前估值。r是带宽利用率的权重,是步长。SQP根据经验设定 = 320 kbps, = 0.25。
2.2.2.4 pacing与数据增长方式
SQP的设计包括两个关键机制,以确保与其他流量的友好性。SQP不是以线性的、不受控制的突发方式传输每一帧,而是以带宽估计的倍数对每一帧进行定位,并以略低于视频比特率为目标(乘性增决定)。
SQP以每一帧的速率为单位,得到 = · ( > 1.0) 。因此,每个帧的传输时间为 / m,其中是帧的间隔。由于突发帧的机制,SQP会始终略高于传输的速率,SQP最终会饿死其他流量。为了避免这个问题,SQP将帧间隔与带宽目标乘数机制(乘数为)结合起来。根据经验,Google设置为:=2、=0.9。
2.2.3 动态分析
2.2.3.1 算法竞争动态
上面介绍了几个公式的原理,下面我们就根据上面的公式对其整体的传输动态情况进行简单的分析。其实,网络传输与pacing息息相关,pacing控制了整体输入到网络的数据量,如何动态的、可靠的控制住输入到网络的数据是做拥塞控制的关键。
SQP是非常重视公平性的。因此我们从竞争流与其在有限链路中的竞争关系来解释它的动态。下面给出公式:
T d = B ⋅ I + R ⋅ I m C (5) T_d = \frac{B \cdot {I} + \frac{R \cdot I}{m}}{C} \tag{5} Td=CB⋅I+mR⋅I(5)
是队列排队的耗时,C是链路容量, · 是带宽乘以帧间隔时间,· 是竞争流的码率乘以帧间隔时间,m是周期转换。上面的公式可以大致算出排队耗时。而前面提到的SQP耗时公式:
T d = R e n d − R s t a r t = R e n d − S s t a r t − Δ m i n (6) T_d =R_{end}-R_{start} = R_{end}-S_{start} - \Delta_{min} \tag{6} Td=Rend−Rstart=Rend−Sstart−Δmin(6)
S采样可以理解为:SQP流消耗带宽乘以帧间隔再比上消耗时间为当前采样点的带宽 = · / 。可以结合两个公式得到:
S = C 1 + R m ⋅ B (7) S = \frac{C}{1+\frac{R}{m \cdot B}} \tag{7} S=1+m⋅BRC(7)
同时,假设链路已经完全满载,也就是 ·+ > 时,而SQP算法中,目标发送码率是采样乘上目标系数计算出来的 —— = · 。因此,获得:
B = C ⋅ T − R m (8) B = C \cdot T - \frac{R}{m} \tag{8} B=C⋅T−mR(8)
假设 = - / 作为竞争流链路的动态因子(传输链路不是一成不变的)。 = / - 作为SQP的利用率容量。那么上面的公司可以写成:
U = m ⋅ T + A − 1 m ⋅ A (9) U = \frac{m \cdot T + A - 1}{m \cdot A} \tag{9} U=m⋅Am⋅T+A−1(9)
由上述公式可以描述 下图 a 的情况:
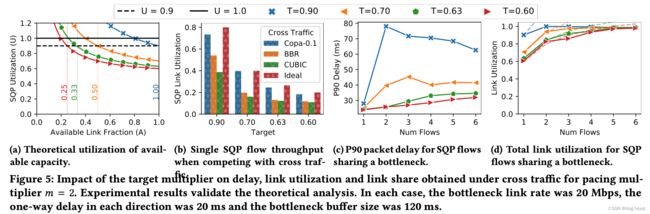
图a意义解释:纵坐标表示上述公式的U,也就是SQP流的利用率;横坐标表示上述公式的A,也就是其他流量的动态利用率。从图中可以看出来,SQP利用率的竞争关系在T设置为0.9时能达到比较好的平衡,我们在使用该算法的时候可以认真的考虑与其他流的竞争关系取舍,来调整T的取值。
图b意义解释:这张图片表示单条SQP流与其他交叉流量竞争时的表现。图片展示了与copa-0.1、BBR、CUBIC、Ideal四种交叉流量竞争的表现,可见在T=0.9时,对其他四种流量的竞争能力表现最佳,T=0.6则最差。
图c意义解释:描述了多条SQP流在瓶颈带宽中P90的包的延迟统计值。只有一条流时,延迟最低。随着流数量的增加延迟越来越大,同时T约小延迟小。
图d意义解释:描述多条SQP流在瓶颈带宽中竞争的利用率关系,随着流越多,SQP流的链路利用率越来越高,可见SQP流之间的竞争可以做到较高的公平性。
2.2.3.2 竞争窗口值调优
SQP的自适应最小单向延迟窗口是一个关键机制,它使SQP能够从网络过度使用中恢复。经过多次实验,T = 0.9, m = 2 时,可以获得比较稳定的排队水平。

事实上,在竞争中较大的窗口值可以有效提高排队恢复能力,但会明显的导致性能下降。如上图a中,延迟在2sRTT的情况下超过1条SQP流的竞争导致的延迟出现了明显的下降。这是因为互相的回复能力都得到了平衡,展现了较好的自竞争特性。上图b给出的是SQP在多条不同算法流竞争中展现的能力,在2sRTT的情况下也不至于在跟别的算法竞争中过于落后。
三、能力评估测试
3.1 简单带宽共享
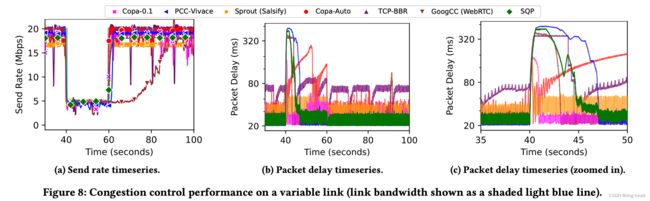
测试条件:一条20Mbps的链路,在40s时将带宽下调至5Mbps持续20s,随后恢复至20Mbps。
测试结果如下图a中,SQP可以快速地检测出带宽变化,同时维持比较精确的发送码率。下降时,SQP展现和BBR、PCC-Vivace一样灵敏的反应能力,在所有算法上涨完成时,GCC仍然没有恢复,正在缓慢上涨。图b展现出来这个过程中,SQP的延迟处于比较低,同时图c放大了带宽下调时的延迟变化图,可见SQP的延迟下降也处于比较优秀的水平,拥有几乎和BBR一样的延迟收敛能力。
3.2 真实wifi场景测试
为了更精确评测SQP在存在包抖动、可变带宽和高聚合性链路上的性能,该文章从现实的一个case中取出数据展示。
下图a的粗灰线表示的是链路带宽变化线,可见SQP实现了很高的带宽利用率。结合图b发现,虽然Copa-Auto、Sprout和BBR也实现了很高的带宽利用率,但是延迟出现了很明显的增大。而WebRTC、PCC和Vivace无法适应带宽的快速变化,导致带宽利用率严重不足。
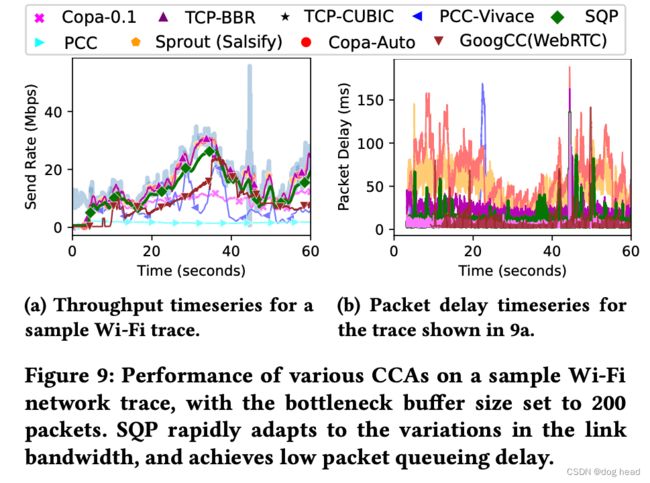
下图展示了所有的wifi利用率的结果平均值。SQP实现了78%的高利用率,而PCC、Vivace和Copa-0.1的平均链路利用率分别为46%、35%和59%,同时只发生了4-8毫秒的延迟。虽然Cubic、BBR、Sprout和Copa-Auto实现了较高的链路利用率,但这是以明显较高的延迟为代价的(高出130-342%)。
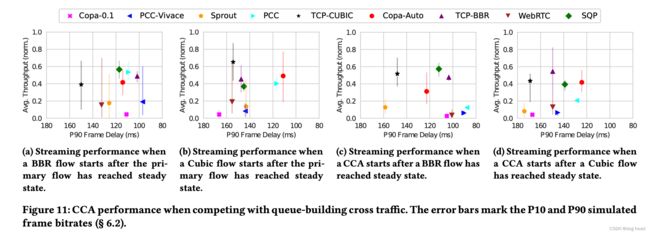
3.3 可排队网络下竞争
测试条件:20Mbps带宽链路进行60s测试,同时给予120ms的延迟排队能力。每种算法运行10s后加入竞争流。
下图a显示引入BBR竞争流的p90数据帧延迟图,图b则是结果:显示BBR加入后SQP没有出现过于明显的帧延迟变化;
下图c显示引入Cubic竞争流的p90数据帧延迟图,图d为结果:同样显示SQP没有明显变化。
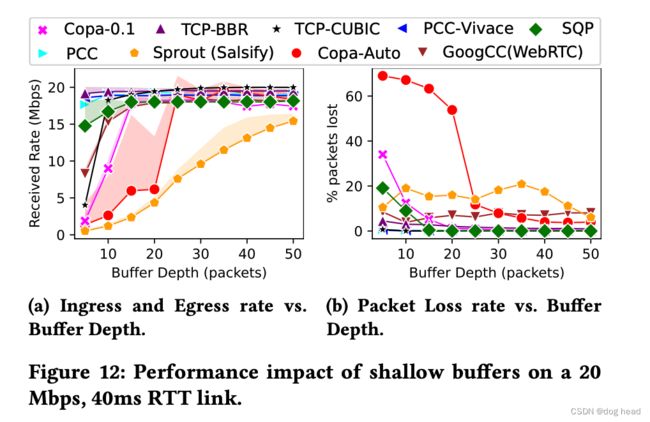
在实际应用中,CCA链路的帧率为60帧的话需要每帧16.66ms的间隔,也就是说SQP发送倍数(m=2)时每次只有8ms的数据缓冲时间来进行数据准备。下图a展示了CCA链路使用各个算法时缓冲区值,阴影部分则为损失率。SQP在缓冲区有15个或更多的数据包时达到最大吞吐量,这相当于在20Mbps的链路上有8毫秒的排队时间(典型的最后公里的网络链路,如DOCSIS、手机和Wi-Fi链路,有更大的数据包缓冲区)。如果缓冲区大小小于15个数据包,SQP以18Mbps的速度传输(=0.9分之一的链路容量),但对应每个帧的尾端的数据包都会丢失。Copa-Auto、Sprout和GoogCC需要更大的缓冲区,而BBR和PCC这类擅长处理浅层缓冲区的算法分别表现为:~4%的损失,5个数据包的缓冲区;<1%的损失,5个数据包的缓冲区。
3.4 短时间发送表现
在下图a中展示了SQP和多种算法流的短时间内大量发送(帧率为60帧)的表现。SQP表现稳定,发送码率在多个帧内几乎无变化。图b展示了各个流延迟的变化,SQP没有发生剧烈的波动,同时SQP没有造成队列排队,虽然Sprout看起来延迟和SQP类似,但是它的排队更严重。


3.5 公平性
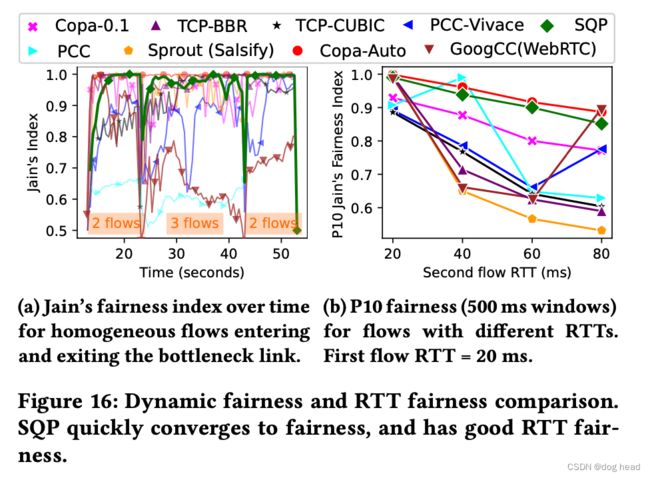
实验1条件:在60Mbps带宽的链路中共享10个传输流,链路的RTT限制为40ms。理想的行为是每个流平分60Mbps每个流为6Mbps。事实上,PCC-Vivace和Sprout无法实现稳定的竞争平衡,SQP表现次于Cublic、BBR、Copa。但是相比与以上公平性较高的几个算法,SQP具备更低的延迟。例如下图就展示了各个竞争流的延迟表现。
下图a展示的是吞吐量和延迟的散点图,SQP实现公平6Mbps的带宽同时,延迟只有75ms。图b表现了帧延迟前10的数据,SQP也是处于较低的位置。

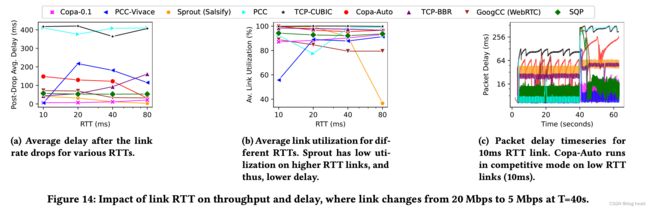
实验2条件:基于以上的基础进行流量加入实验,分别在10s、20s的时候加入两个新流量,随后在40s和50s时分别停止这两条流量。
下图a表示的是jain‘s公平指数与时间的关系。SQP在较快的速度下实现了公平,而PCC和GCC都无法实现加入流时的公平性。图b显示的是在不同RTT下公平性的特点,可见SQP在不同的RTT变化下,整体的公平性仍然很高。
补充——计算系统公平性的指数计算公式如下:
F I = ( ∑ i = 1 n T i O i ) 2 / ( n ∑ i = 1 n ( T i O i 2 ) ) FI = \bigg(\sum_{i=1}^{n} \frac{T_i}{O_i} \bigg)^2 / \bigg(n\sum_{i=1}^{n} \bigg(\frac{T_i}{O_i}^2 \bigg) \bigg) FI=(i=1∑nOiTi)2/(ni=1∑n(OiTi2))
其中,FI为公平指数,Ti 为网络中第 i 条链路的传输容量;Oi 为所有 n 条链路全都工作时,第 i 条链路的实际吞吐量。
FI 的取值范围为[1/n, 1]。当 FI=1 时,整个系统达到绝对公平,各条链路的实际吞吐量与其传输容量对应成比例,各链路按照其传输容量所占比例使用无线资源(信道);当 FI =1/n 时,系统将完全不公平,此情况为某一链路完全垄断无线资源(信道),其他链路的流量为 0。
3.6 编解码支持能力
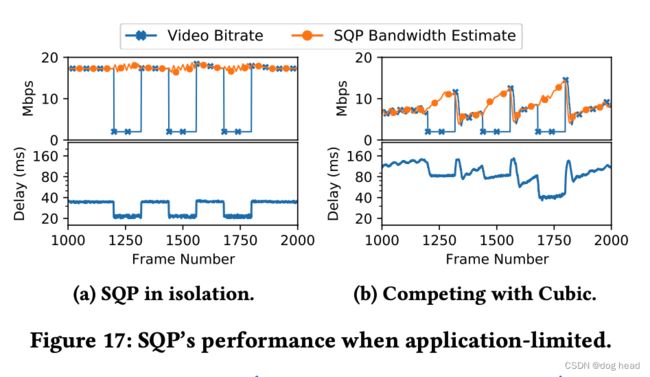
实验条件:带宽限制20Mbps、RTT为40ms、120ms缓冲区。我们知道大部分的代码都需要使用数据进行探测,但是SQP能够支持在编码器码率不足时仍保持较好的带宽估计能力。例如图a,SQP的带宽探测在视频编码码率动态波动剧烈的时候也没有出现明显的估计波动。
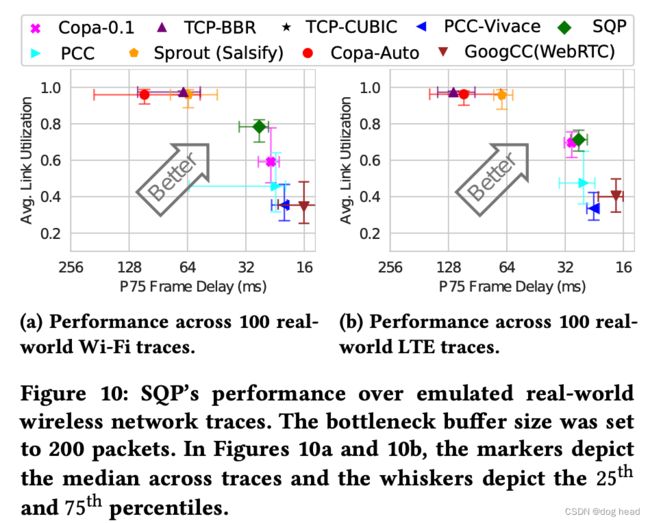
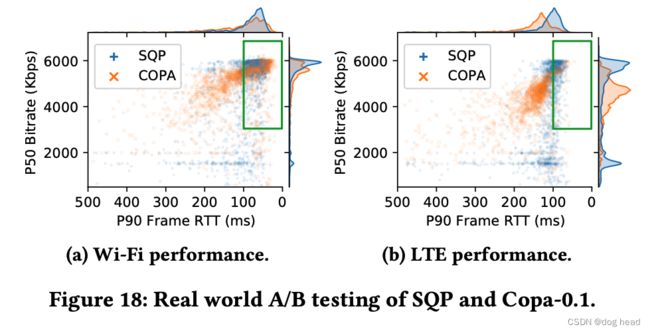
3.7 真实场景能力对比
Google为了测试SQP在真实场景的表现,分别在他们的AR流媒体平台上部署了SQP和Copa1.0进行测试。在下图中显示——无论是Wifi还是LTE网络——相比与Copa1.0,SQP表现出更高的带宽利用率和低延迟能力。
四、总结
本文主要针对Google近期的SQP文章进行解读,结合SQP的底层逻辑和文章中的测试效果进行了解析和介绍。事实上,SQP的表现在AR流的传输上可能有较好的提升,但在传统低码率的音视频流上的效果有待验证。下面给出他们结论的翻译:
在本文中,我们介绍了SQP的设计、评估和实际应用的结果,SQP是一种为低延迟互动流媒体应用设计的拥堵控制算法。SQP是专门为低延迟交互式视频流设计的,并且针对该类视频进行了适当的调整。SQP的拥堵控制方法使其能够在动态链路上保持低排队延迟和高利用率,并在Cubic和BBR等队列建设交叉流量的情况下实现高吞吐量,而且无需切换模式(相比BBR)来适应链路。