Python中字符串和正则表达式
Python中字符串和正则表达式
字符串
字符串格式化
字符串格式化用来把整数、实数、列表等对象转化为特定格式的字符串。
Python中字符串格式化的格式如下:
‘%[-][+][0][m][.n]格式字符’%x
%符号之前的字符串为格式字符串,之后的部分为需要进行格式化的内容
‘%[-][+][0][m][.n]格式字符’%x
从右到左:
- x:待转化的表达式
- ‘%:格式运算符
- 格式字符:指定类型
- [.n]:指定精度或小数位数
- [m]:指定最小宽度
- [0]:指定空位填0
- [+]:对正数加正号
- [-]:指定左对齐输出
- '%:格式标志,表示格式开始
Python支持大量的格式字符,常见的格式字符如下:
- %s:字符串(采用str()的显示)
- %r:字符串(采用repr()的显示)
- %c: 单个字符
- %d: 十进制整数
- %i:十进制整数
- %o:八进制整数
- %x:十六进制整数
- %e:指数(基底写为e)
- %E指数:(基底写作E)
- %f,%F: 浮点数
- %g :指数(e)或浮点数(根据显示长度)
- %G:指数(E)或浮点数(根据显示长度)
- %%:字符“%”
str()主要用来为终端用户输出一些信息,而repr()主要用来调试;同时后者的目标是为了消除一些歧义(例如浮点数的精度问题),前者主要为了可读。
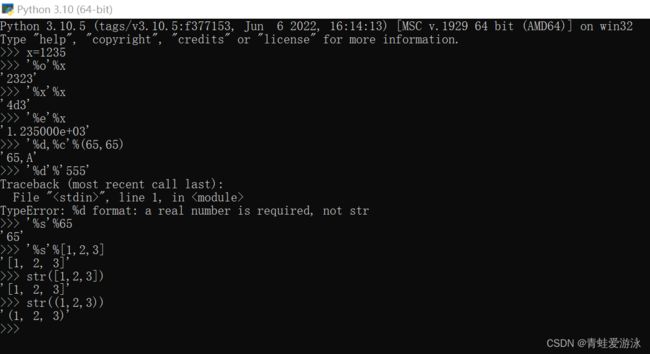
使用format()方法进行格式化:
![]()
- 0表示格式化第一个参数
- 1表示格式化第二个参数
- 1后没有“:” ,表示把本来的内容格式化到此处
- 0:,中的“,”表示在千分位用逗号做分割
- #x表示格式化为16进制数
- #o表示格式化为8进制数
- o表示格式化为8进制数但前面无0x引导
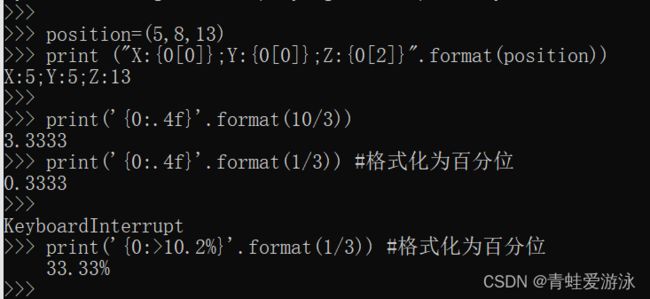
符号>表示右对齐,符号^表示居中,符号<表示右对齐
Python 3.6.x 以后的版本支持在数字常量的中间位置使用单个下划线作为分隔符来提高可读性

字符串常用方法
可以使用 dir(“”)查看字符串操作所有方法列表,使用内置函数 help()查看每个方法的帮助。字符串也是 Python 序列的一种,除了本节介绍的字符申处理方法,很多 Python
内置函数也支持对字符串的操作,例如用来计算序列长度的 len()函数,求最大值的 max()
函数,字符串编码方法 encode()和字节串解码方法 decode()。
1. find().rfind()、index().rindex().count()
find()和 rfind()方法分别用来查找一个字符串在当前字符串指定范围(默认是整个字符串)中首次和最后一次出现的位置,如果不存在则返回-1;
index()和 rindex()方法用来返回一个字符串在当前字符串指定范围中首次和最后一次出现的位置,如果不存在则抛出异常;
count()方法用来返回一个字符串在当前字符串中出现的次数,不存在返回0。
2.split(),rsplit(),partition(),rpartition()
split()和rsplit()方法分别用来以指定字符为分隔符,从字符串左端和右端开始将其分隔成多个字符串,返回包含分隔结果的列表;partition()和rpartition()用来以指定字符串为分隔符将原字符串分隔为 3 部分,分别为分隔符前的字符串,分隔符字符串、分隔符后的字符串,如果指定的分隔符不在原字符串中,则返回原字符串和两个空字符串组成的元组。
partition()方法只分隔一次
split()方法自动删除分隔结果中的字符串

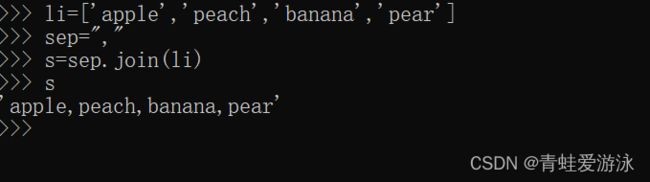
3.join()
join()方法用来将列表或其他可迭代对象中多个字符串进行连接,并在相邻字符串之间插入字符串
4.lower(),upper(),capitalize(),title(),swapcase()

replace()

6.strip(),rstrip(),lstrip()

7.eval

8. startswith(),endswith()
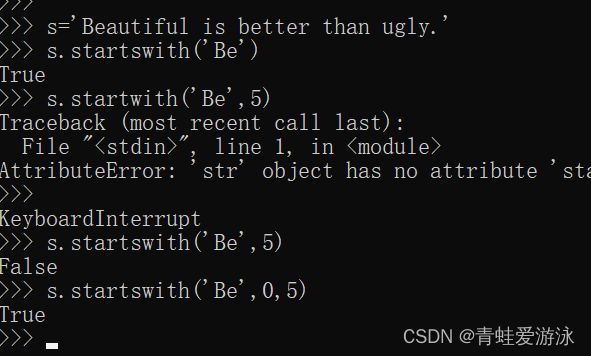
另外,这两个方法还可以接受一个包含若干字符串的元组作为参数来表示前缀或后缀,例如,下面的代码可以列出D盘根目录下所有扩展名为bmp、jpg或gif的图片
import os
[filename for filename in os.listdir(r'D:\\') if
filename.endswith(('.bmp','.jpg','.gip'))]
9.
- isalnum() → 测试是否全部为数字或英文字母
- isalpha() → 测试是否全部为英文字母
- isdigit() → 测试是否全部为数字字符
- isspace() → 测试是否全部为空白字符
- isupper() → 测试是否全部为大写英文字母
- islower → 测试是否全部为小写英文字母
下面的代码演示了8位长度随机密码生成算法的原理:

random是与随机数有关的的Python标准库,除了用于从序列中任意选择有关元素的函数 choice(),还提供了用于生成指定二进制位数的随机整数的函数 getrandbits(),生成指定范围内随机数的函数 randrange()和 randint(),列表原地乱序函数 shuffle().从序列中随机选择指定数量不重复元素的函数 sample()、返回[0,1]区间内符合 beta 分布的随机数函数 betavariate()、符合 gamma 分布的随机数函数 gammavariate()、符合 gauss 分布的随机数函数 gauss()、从指定分布中选取k个允许重复的元素的函数 choices()等,同时还提供
了 SystemRandom 类支持生成加密级别要求的不可再现伪随机数序列。
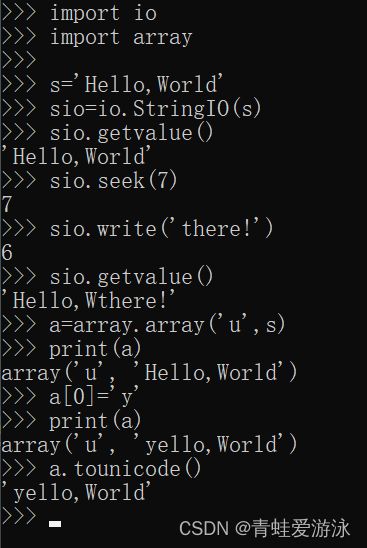
可变字符串
在Python中,字符串属于不可变对象,不支持原地修改,如果需要修改其中的值,只能重新创建一个新的字符串对象。
如果确实需要一个支持原地修改的Unicode数据对象,可以使用io.StringIO对象或array模块。
正则表达式
正则表达式由元字符及其他不同组合来构成,通过巧妙地构建正则表达式考科一匹配任意字符串。
常用的正则表达式常用元字符如下:
- “ . ” → 默认匹配除换行符以外的任意单个字符,单行模式下也可以匹配换行符
- “ * ” → 匹配位于*之前 的字符或子模式的0次或多次重复
- “+” → 匹配位于+之前的字符或子模式的1次或多次重复
- “-” → 用在[ ]内表示范围
- “|” → 匹配位于|之前或之后的字符,表示2选1
- “^” → 匹配行首,匹配以^后面的字符或子模式开头的字符串
- “$” → 匹配行尾,匹配以 $ 之前的字符或子模式结束的字符串
- “?” → 匹配位于’?'之前字符或子模式的0次货1次出现
- “\” → 表示位于“\”之后的转义字符
- “\num” → 此处的num是一个表示子模式的正整数。例如,r"(.)\1"匹配两个连续的相同字符
- “\f” → 匹配换页符
- “\n” → 匹配换行符
- “\r” → 匹配一个回车符
- “\b” → 匹配单词头或单词尾,该字符与转义字符形式相同,需要使用原始字符串
- “\B” → 与‘\b’含义相同
- “\d” → 匹配单个任何数字,相当于’[0-9]’
- “\D” → 与‘\d’含义相反,等效于‘[^0-9]’
- “\s” → 匹配单个任何空白字符,包括空格、制表符、换页符
- “\S” → 与‘\s’含义相反
- “\w” → 匹配单个任何字母、汉字、数字以及下划线,相当于[a-zA-Z0-9]
- “\W” → 与‘\w’含义相反,与 [^a-zA-Z0-9]等效
- () → 将位于()内的内容作为一个整体对待,表示子模式
- {m,n} → 将{ }中的次数进行匹配,至少m次,最多n次,逗号前后不能有空格
- [] → 匹配位于[ ]中的任意一个字符,表示范围
- [^xyz] → 反向字符集,匹配除x、y、z之外的单个任何字符
- [a-z] → 字符范围,匹配指定范围内的单个任何字符
- [^a-z] → 反向范围字符,匹配除小写英文字母之外的单个任何字符
re模块主要函数
在Python中,主要使用re模块来失陷正则表达式的操作。
re模块的常用函数如下,具体使用时,既可以直接使用re模块的函数进行字符串处理,也可以将模块变异为正则表达式对象,然后使用正则表达式对象的方法来操作字符串。
- compile(pattern[,flags]):创建正则表达式对象
- search(pattern,string[,flags]):在整个字符串中寻找模式,返回Match对象或None
- match(pattern,string[,flags]):从字符串的开始处匹配模式,返回Match对象或None
- findall(pattern,string[,flags]):返回字符串中模式的所有匹配项组成的列表
- split(pattern,string[,maxsplit=0]):根据匹配项分隔字符串
- sub(pattern,repl,string[,count=0]):将字符串中pattern的所有匹配项用repl替换
- escape(string):将字符串中所有正则表达式特殊字符进行转义
其中,函数参数flags的值可以是re,I(忽略大小写)、re.L、re.M(多行匹配模式)、re.S(使元字符‘.’匹配任意字符,包括换行符)、re.U(匹配Unicode字符)、re.X(忽略模式中的空格,并可以使用#注释)的不同组合(使用“|”进行组合)
直接使用re模块
可以使用re模块的函数来实现正则表达式操作
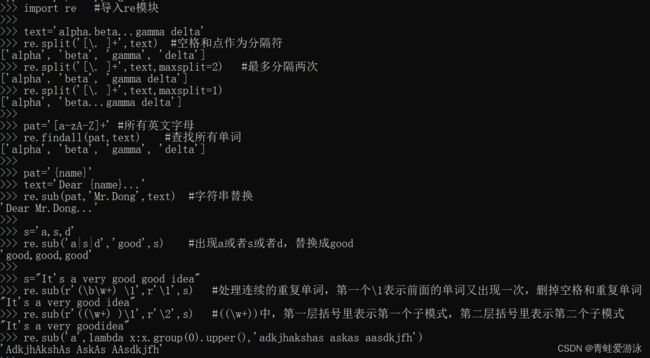
import re #导入re模块
text='alpha.beta...gamma delta'
re.split('[\. ]+',text) #空格和点作为分隔符
re.split('[\. ]+',text,maxsplit=2) #最多分隔两次
re.split('[\. ]+',text,maxsplit=1)
pat='[a-zA-Z]+' #所有英文字母
re.findall(pat,text) #查找所有单词
pat='{name}'
text='Dear {name}...'
re.sub(pat,'Mr.Dong',text) #字符串替换
s='a,s,d'
re.sub('a|s|d','good',s) #出现a或者s或者d,替换成good
s="It's a very good good idea"
re.sub(r'(\b\w+) \1',r'\1',s) #处理连续的重复单词,第一个\1表示前面的单词又出现一次,删掉空格和重复单词
re.sub(r'((\w+) )\1',r'\2',s) #((\w+))中,第一层括号里表示第一个子模式,第二层括号里表示第二个子模式
re.sub('a',lambda x:x.group(0).upper(),'adkjhakshas askas aasdkjfh')
持续更新中…