【目标检测】—— mAP概念
1. 什么是IOU
1.1 IOU含义
衡量检测框与标签框的重合程度
计算方式:

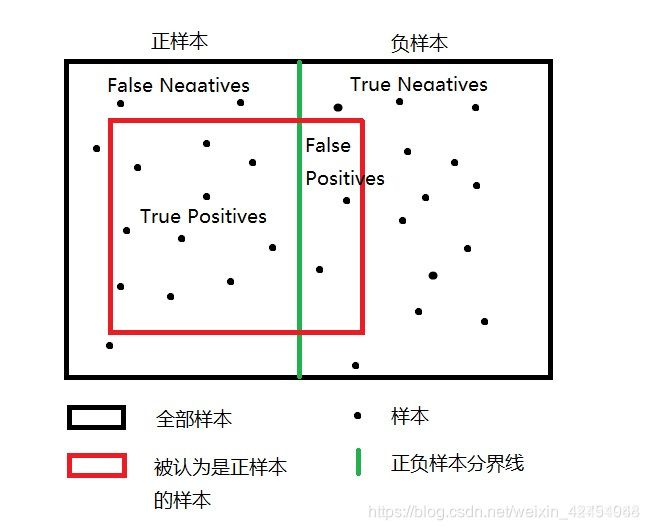
2. 什么是TP、TN、FP、FN
TP :True Positives,其指的是被分配为正样本,且分配对了的样本。(实际为正样本)
TN :True Negatives,其指的是被分配为负样本,且分配对了的样本。(实际为负样本)
FP :False Positives,其指的是被分配为正样本,且分配错误的样本。(实际为负样本)
FN :False Negatives,其指的是被分配为负样本,且分配错了的样本。(实际为正样本)
3. 什么是Precision和Recall
Precision:精度,衡量分类器找出的正类的确是正类的概率
公式:
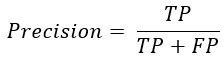
含义:分类器认为是正类,且确实是正类的部分占分类器认为是正类的比例。
Recall:召回率,衡量分类器找出全部正类的能力
公式:
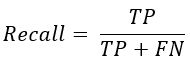
含义:分类器认为是正类,且确实是正类的部分占实际全部正类的比例。
4. 单一指标的缺陷
在目标检测算法里面有一个非常重要的概念是置信度,如果置信度设置的高的话,预测的结果和实际情况就很符合,如果置信度低的话,就会有很多误检测。
假设一幅图里面总共有3个标签为正的样本,而目标检测对这幅图的预测结果有10个,其中3个实际上是正样本,7个实际上是负样本。对应置信度如下:

case1:若将置信度设为0.95,则置信度>0.95的被认为是正样本,其余被认为是负样本,此时TP=1,FP=0,FN=2,可计算出:
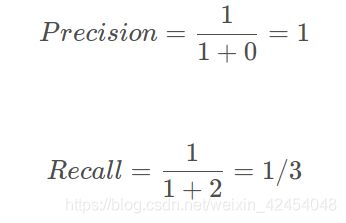
此时Precision非常高,但是事实上我们只检测出一个正样本,还有两个没有检测出来,因此只用Precision就不合适。(漏检测)
case2:若将置信度设为0.35,则置信度>0.35的被认为是正样本,其余被认为是负样本,此时TP=3,FP=3,FN=0,可计算出
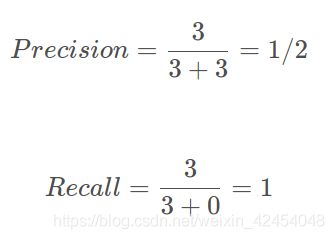
此时Recall非常高,但是事实上目标检测算法认为是正样本的样本里面,有3个样本确实是正样本,但有三个是负样本,存在非常严重的误检测,因此只用Recall就不合适。(误检测)
5. 什么是AP、mAP
5.1 P-R曲线
取不同的置信度,可以获得不同的Precision和Recall的点的组合,这些点可以画出P—R曲线:

5.2 AP
当我们取得置信度够密集的时候,就可以获得非常多的Precision和Recall。
此时Precision和Recall可以在图片上画出一条线,这条线下部分的面积就是某个类的AP值。
5.3 mAP:mean Average Precision, 即各类AP的平均值
作用:目标检测中衡量检测精度的指标
计算方式:
mAP =所有的类的AP值求平均。
5.4 目标检测中mAP计算方式
对于目标检测而言,每一个类别都可计算出其Precision和Recall,每个类别都可以得到一条P-R曲线,曲线下的面积就是AP的值。
假设存在M张图片,对于其中一张图片而言,其具有N个检测目标,其具有K个检测类别,使用检测器得到了S个Bounding Box(BB),每个BB里包含BB所在的位置以及K个类的得分C。利用BB所在的位置可以得到与其对应的GroundTruth的IOU值。
计算步骤:
- 对所有的BB,计算BB所在位置与其最对应的GroundTruth的IOU值,记为MaxIOU,设置一个阈值threshold,一般设置为0.5。
- 若MaxIOU < threshold,则认为该BB(预测框)无真实框与其对应,此时可以记录其属于False Positive,使其FPi = 1,并记录其属于类I的分数C。
- 若MaxIOU>threshold,则认为该预测框与该真实框最对应;
此时再分两种情况:
(1)当该框的类别属于类I时,此时可以记录其属于True Positive,使其TPi = 1,并记录其属于类I的分数C。
(2)当该框的类别不属于类I时,此时可以记录其属于False Positive,使其FPi = 1,并记录其属于类I的分数C。 - 通过2和3,可以得到K*S个分数C以及TP和FP的元组,(C,TP,FP),对这K*S个元组按照得分C进行排序。
- 将得分从大到小排序后进行截取,截取得分最大的S个,通过该步骤可以获得每个框是否成功对应了自己所属的类,计算每次截取所获得的recall和precision,画出PR曲线。
5.5 mAP计算举例
假设我们有一个用于检测猫类的模型,同时有20个测试样本,首先利用该模型得到所有测试样本的置信度分数(属于猫这一类别的概率),同时通过预测框(bbox)和标签框(ground truth)的IOU值判断样本为正样本还是负样本,得到gt_label。

接下来对confidence score排序,得到:

P-R曲线:
选取score排名在前top-5的结果,其为TP和FP(分类器认为其是正类)。其中图像id=4,2为TP,id=13,9,6为FP
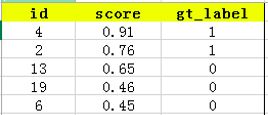
而confidence score排在top-5之外的为FN和TN(分类器认为其是负类),其中id=9,16,7,20为FN,id=1,18,5,15,10,17,12,14,8,11,3为TN

则Precision = TP/(TP+FP)= 2/5
Recall=TP/(TP+FN)= 2/6
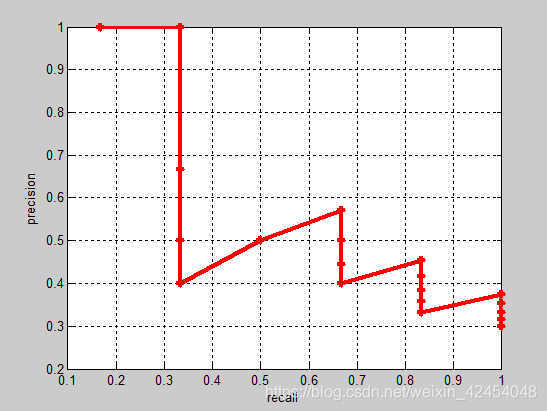
根据不同的top-n,执行上述操作,可以得到precision-recall曲线:
AP计算
假设这N个样本中有M个正例,那么我们会得到M个recall值(1/M, 2/M, …, M/M),对于每个recall值r,我们可以计算出对应(r’ >= r)的最大precision,然后对这M个precision值取平均即得到最后的AP值。计算方法如下:

相应的Precision-Recall曲线(这条曲线是单调递减的)如下:

AP衡量的是学出来的模型在每个类别上的好坏,mAP衡量的是学出的模型在所有类别上的好坏,得到AP后mAP的计算就变得很简单了,就是取所有AP的平均值。