Nacos-1.3.2之服务注册
说明
本文以开源框架nacos,版本号为1.3.2针对服务的注册以及数据流转进行源码解析,核心会围绕两种数据一致性协议展开解析;Distro协议和raft协议;其中Distro协议属于自制的;raft协议基于raft算法实现;本文中也会添加本人一些理解或疑惑;
Nacos源码下载地址:https://github.com/alibaba/nacos
概念
1.服务的数据结构
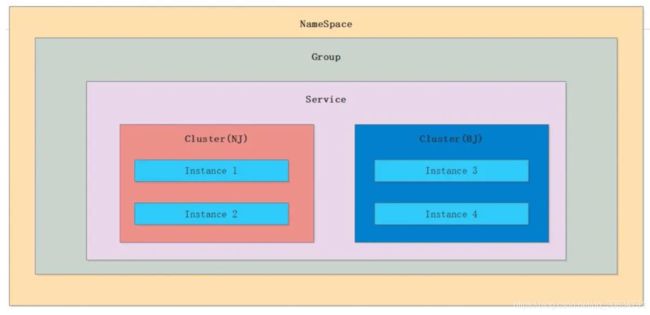
2.Distro协议
2.1.distro协议是为了注册中心而创造出的协议
2.2.客户端以服务为维度向服务端注册,注册后每隔一段时间向服务端发送一次心跳,心跳包需要带上注册服务的全部信息,在客户端看来,服务端节点对等,所以请求的节点是随机的;客户端请求失败则换一个节点重新发送请求;
2.3.服务端在接收到客户端的服务心跳后,如果该服务不存在,则将该心跳请求当做注册请求来处理;
2.4.服务端节点都存储所有数据,但每个节点只负责其中一部分服务,在接收到客户端的“写“(注册、心跳、下线等)请求后,服务端节点判断请求的服务是否为自己负责,如果是,则处理,否则交由负责的节点处理;·
2.5.每个服务端节点主动发送健康检查到其他节点,响应的节点被该节点视为健康节点;·
2.6.服务端如果长时间未收到客户端心跳,则下线该服务;
2.7.负责的节点在接收到服务注册、服务心跳等写请求后将数据写入后即返回,后台异步地将数据同步给其他节点;
2.8.节点在收到读请求后直接从本机获取后返回,无论数据是否为最新。
3.Raft协议(注册部分)
3.1 服务端收到客户端的注册请求会转发给leader;由leader 实现持久化,并发送给n/2+1为成功
3.2 在数据更改时term+100,term 为任期,每个leader 都有一个term
3.3 心跳只能由leader 发送,其它服务节点接收对比term ;if term >=local then upate datum ;并且接收的服务节点会设置leader=send node
3.4 服务节点默认采用tcp 进行注册客户端健康检查
原理参考网址:RAFT算法详解_青萍之末的博客-CSDN博客_raft算法
两者协议区别(重点)
- Distro 采用ap模式,而raft采用cp模式;(模式不同导致后面几点的差异)
- 健康检查前者采用心跳模式,采用http协议发送心跳;后者采用多协议,默认采用tcp模式;
- 存储模式:前者采用内存模式;后者采用内存+文件模式;新节点加入的时候,前者以http 请求的方式向其他节点获取数据,而后者加载本地文件,和等待leader 送信息
Server服务数据流转简述
Distro 与 raft 数据复制策略
前者在注册的时候,更新install 最后心跳时间,并发现install 发送状态更改的时候异步同步到节点;并且通过定时任务DataSyncer#startTimedSync 同步自己的数据到其它节点达到数据一致性
后者是注册的时候直接同步N/2+1个节点,然后通过心跳机制达到数据的一致性
注册流程图
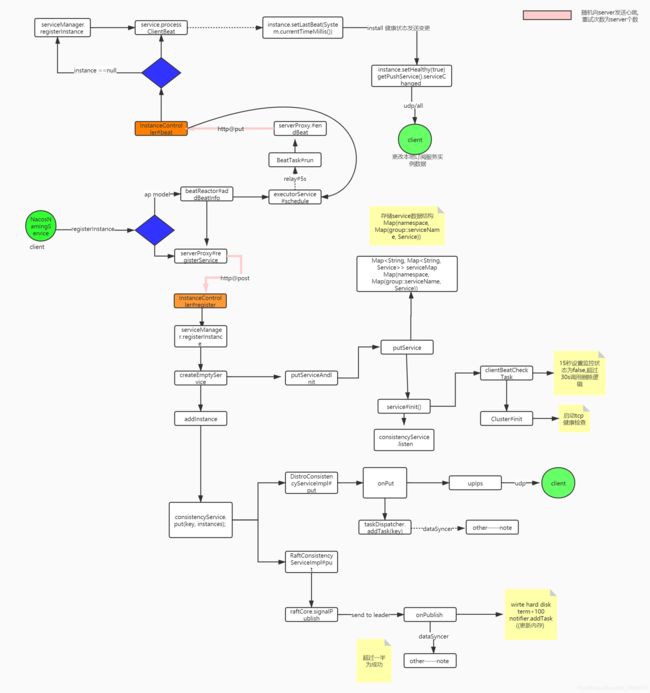
源码分析
NacosNamingService ---客户端发起服务注册
NacosNamingService#registerInstance
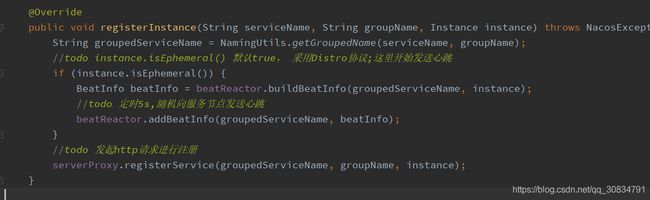
beatReactor#addBeatInfo

BeatTask 心跳线程

serverProxy#sendBeat 方法体里会遍历所有的服务节点,发送心跳请求,如果成功在return;返回的结果如果ok 又会继续延迟五秒发送心跳
InstanceController#beat -----服务端接收心跳
@CanDistro ----说明
该方法上有@CanDistro,就会先到DistroFilter就行请求转发,该类部分代码
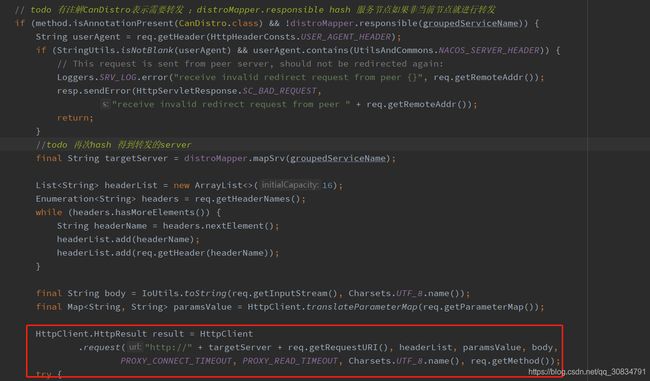
其实就是相同的组服务,会转发到固定服务节点上,进行了负载均衡;
方便后台node 动态 扩展
小朋友问号来了
- 目前的转发采用同步机制,建议采用异步模式,提高吞吐量,类似网关
方法beat 分析:
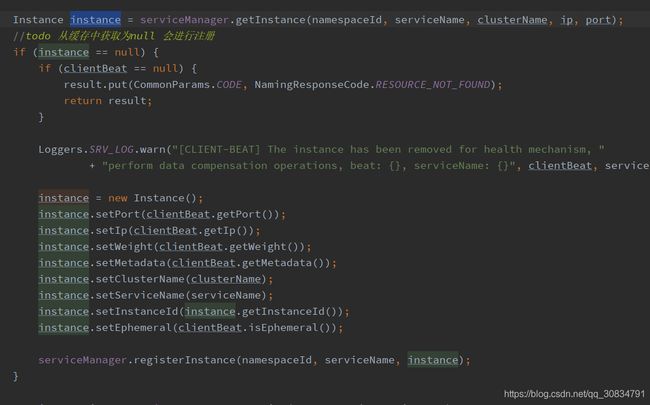
小朋友问号来了
- 先从缓存中获取对应的实例,如果木有就注册,可是在客户端在心跳是异步的,那么如果客户端调用了注册实例接口因为某种原因失败了,而且心跳成功了,结果是提示注册失败,但是有可能已经加到其它节点;会给人幻觉;
目前这个问题后期估计会得到优化
接着我们看线程类ClientBeatProcessor核心实现代码

大家看到了,心跳更新只是更改了最后心跳时间,并且如果当前install 健康状态发送变化,会发送service 更改事件;其事情做了一件事,通过udp广播给订阅者;PushService#onApplicationEvent
疑问?
细心的同学应该会发现心跳只是更改了本地数据与通知了订阅者,并没有与别它node 进行数据传播;答案在目录Server服务数据流转简述
InstanceController#register -----服务端接收注册请求
调用的 ServiceManager#registerInstance

创建service 服务
核心代码ServiceManager#putServiceAndInit

第一在内存中创建map,第二针对服务进行初始化,就是针对cp或者ap 就行启动健康检测机制
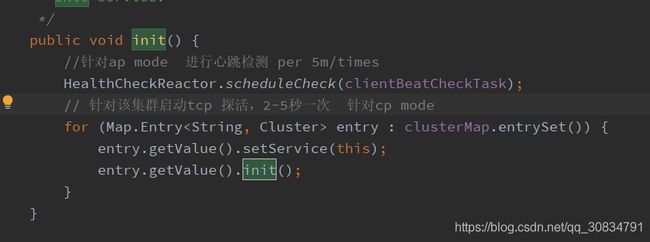
目前cp 和ap 模式采用了不同的探活方式,前者采用ttl 模式,及客户端发心跳检测模式,后者是服务端检测模式,默认采用tcp 模式
我们先看看线程clientBeatCheckTask
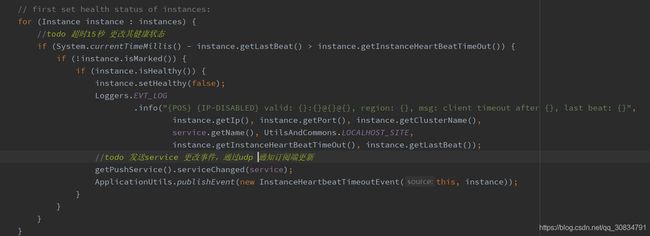

超时15秒设置为不健康,并通知订阅者,超过30秒删除
cp模式主要实现线程HealthCheckTask类
healthCheckProcessor.process(this); 最终到线程TcpSuperSenseProcessor
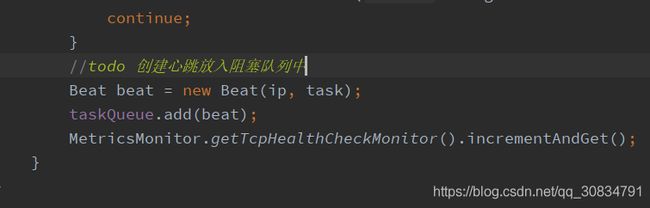
而该类本来就是一个线程在初始化时候就会启动线程执行run 方法

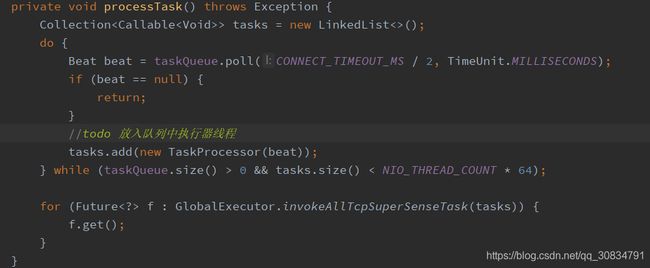
最终调用线程TaskProcessor#call

这里采用jdk nio 来就行非阻塞连接并通过延迟线程判断是否健康


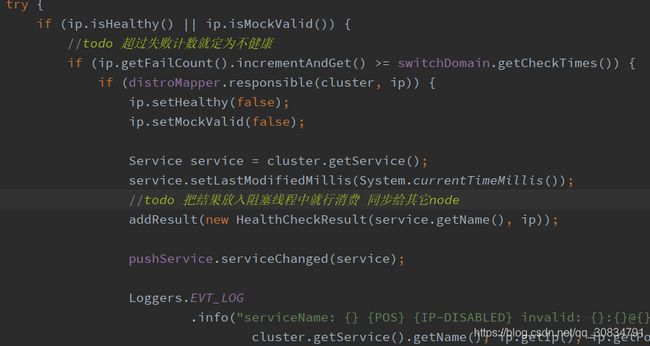
如果探活成功会执行线程PostProcessor
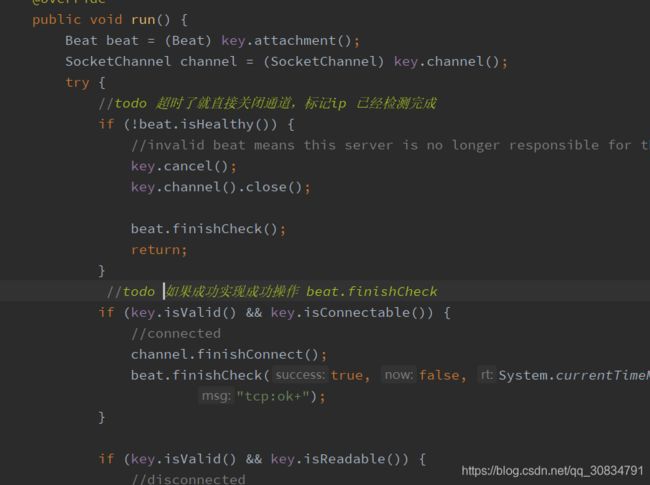

说明:
tcp和心跳检查区别:前者是服务端发起的检查在一定次数之后更改其intance 状态,并且这个状态是每个服务器自己在内存中维护;后者是采用ttl 模式由客户端发起心跳,如果超过一定时间就会删除instance;网络恢复后也会通过心跳再次注册;
ServiceManager#addInstance----注册实例进入service

注册流程图

ap 模式
DistroConsistencyServiceImpl#put
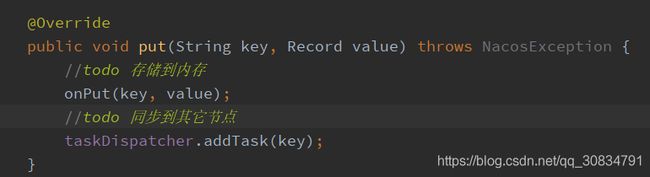
Onput 存储到内存,并异步通知订阅者

数据同步发生在TaskDispatcher内部线程类TaskScheduler

这里采用poll 次数,和数据来批量同步,减少请求次数
疑问?
如果期间服务宕机呢?数据会发生丢失吗
目前看可能性小,因为还有心跳机制,没有会自动添加实例
最终调用DataSyncer#submit
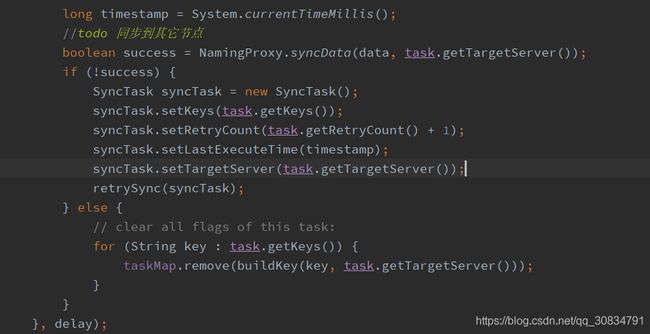
通过服务代理批量同步到其它节点,如果失败一直同步直到成功为止
cp模式
RaftConsistencyServiceImpl#put
最终调用的是raftCore#signalPublish
判断当前节点是不是leader ,非leader 进行转发

先就行本地存储,并想n/2+1 个node 发送注册,均成功才返回成功
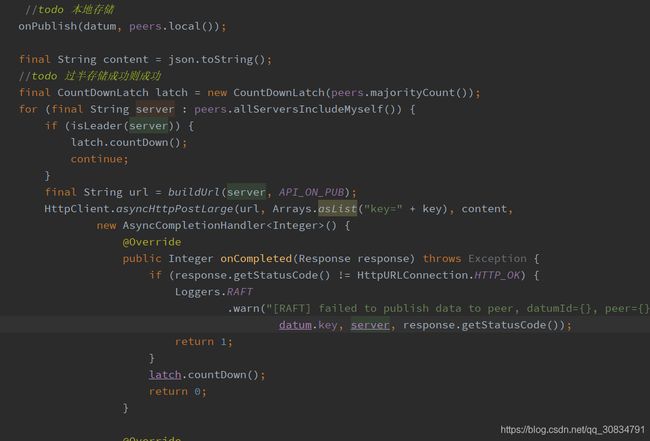
本节点存储采用阻塞文件时存储,并term +100,这个在leader 分区容错很重要,在我的leader 选举博客中有介绍;最后才通知,通知客户端


疑问?
Raft 设计目前版本还是有些网络分区问题的
比如:
三个活跃节点 A,B,C;其中A 为leader
- 在注册服务的时候,先在A 节点存储成功,但是这个时候B,C 因为某种原因网络波动了,导致最终注册失败,提示给客户端注册失败;但是随后网络恢复,leader 会通过心跳把刚才注册的服务同步到其它节点
总结
由于版本低,内部还有一些待优化,不过内一些代码设计,或者设计模式,比如事件机制,就业务解耦,部分代码重复利用率高 (个人浅谈)