c++ atomic
文章目录
- why atomic?
- memory consistency model
- sequentially consistent atomic
- Relaxed memory Consistency models
- 扩展阅读
why atomic?
当我们有一片内存空间S,线程A正在往S里写数据,这个时候线程B突然往S中做了++操作,导致线程A的操作结果变得不可预知(对线程A来说),这种情况换句话说叫做data race,我们一般的操作时上锁,在c++中有多种类型的锁比如std::mutex,std::shared_mutex(c++ 17),
std::mutex的性能要比std::shared_mutex低,因为std::shared_mutex上锁后其他线程可以照样可以访问被lock住的空间(只可以读原数据),而一旦线程对一块内存区域上std::mutex锁后,其他的线程无论读还是写都不会成功
mutext使用如下
#include 注意!
如果std::thread()添加的函数对象在class外部,且调用std::thread()的函数也不属于任何一个class,那么就直接调用,std::thread()第二个参数佳被调用函数的第一个参数
如果std::thread()添加的函数对象在class内部(class 内部非静态函数如我们上面的例子所示),他要除了要将函数的全部名称(包含class名字)写上去,还要指定我们这个class对象的位子,这样才能寻址到指定的函数,std::thread()第三个就是该被注册函数的第一个参数
如果std::thread()位于某个class内部,且注册的函数也位于这个class内部我们和上面一样需要指定这个class的起使位子(this在std::thread()的第二个参数中)
shared_mutext使用如下
#include 现在回归正题,为什么我们要使用atomic而不是锁?首先我们在用atomic的时候发现系统明显的慢,并且我们的锁颗粒已经小到极致,那么为了再进一步的提升性能我们只能使用atomic
首先锁的一些操作都是操作系统提供,比如win,linux,但是atomic是我们处理器提供的,锁机制其实是将被lock住的线程挂起,空出cpu资源给其他的线程,但是这有明显的inter pross的线程上下文切换(被锁住的线程在不断地尝试直到成功强到锁(也叫做busy wait))我们使用锁的时候还要考虑死锁等情况发生(当然c++中有lock_guardclass将一个锁包住当lock_guardclass对象被销毁自动的unlock)
而我们的atomic就简单的多,只需要将容易发生race的那个变量置为atomic即可
#include atomic 在C++标准中并没有说明他是lock-free的,有的平台他是lock-free,有的平台他是用mutex实现,所以C++提供了一个method去验证你的这个平台上atomic 是否是lock-free
bool std::atomic::is_lock_free()
Lock-free usually applies to data structures shared between multiple threads, where the synchronisation mechanism is not mutual exclusion; the intention is that all threads should keep making some kind of progress instead of sleeping on a mutex.
memory consistency model
什么是内存模型?简而言之我们一个代码(比如C/C++)经过翻译成汇编,汇编器汇编成ELF文件(无论是可执行文件还是可重载文件),最后再链接器链接到一起形成最终的可执行文件,这个文件是放在内存中的,如果在远古时代,没有多核,没有并行华,我们也不会有关于memory consistency的烦恼,因为就一个core,只能串行执行
我们将时间线调整到多核时代下(多核CPU架构这里不细讲),每个CPU都有自己的L1Cache(分为L1 DCache和L1 ICache),L2Cache(既存数据也存指令),然后一个L3 Cachce每个Core共享
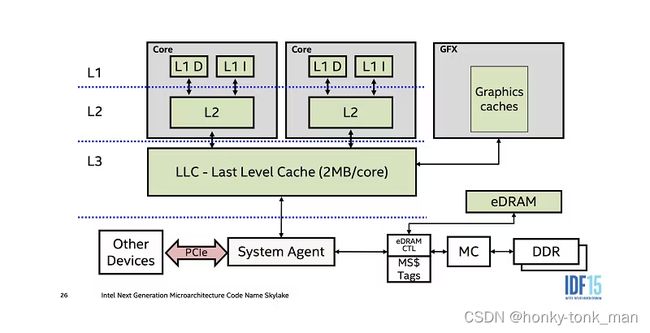
在多核时代再用串行化执行就不合时宜了把,白白浪费这么多core
那么问题来了,内存中(DRAM)的可执行文件如何并行化,要知道每一个core都会缓存到自己的cache中,并且先查找自己的cache以达到加速的效果(Cache一般都是SRAM而非内存的DRAM,只有Cache miss后才会到内存查找数据,从内存找数据效率就要慢的多),所以如果我们想并行化执行内存中的指令(可执行文件由多个指令组成),首先要创建多个线程,每个线程分配某些任务,再将线程调度到不同的core上,这个时候问题来了,如果不同core(不同的线程)要操作同一块内存,如何保证一个线程在操作的时候不被另一个线程打扰?(操作该内存块的时候数据被另一个线程更改),这个时候就需要我们CPU提供原子操作,在一个线程操作一块内存的时候如果是原子操作,那么在执行原子操作的时候不会被另一个线程所插手,下面我们用C++的atomic标记一个内存区域后,线程对这个内存区域的每一个操作都是原子的
比如下面代码中多个线程对这个区域做了非常多的操作,这些操作每一个都是原子的,特别注意,不是整个线程的操作是原子的,我们下面的代码对这个区域进行了读和写2个操作,意味着有2个原子操作也就是读和写分别都是原子的,换句话说同一个线程的2个原子操作之间可能插入其他线程的原子操作,特别注意这不叫做data race,data race指的是在操作内存的时候这个内存被其他篡改,多个原子操作中并没有出现一个原子操作在操作的时候被其他的原子影响
每个CPU架构提供的memory model都是不一样的,在多个core对同一片内存空间进行操作的时候我们的底线应该是一个core操作其他的core不对这个内存区域做更改,还有就是每个core执行顺序应该按照代码的顺序执行
比如下面sequentially consistent atomic的例子,x和y都初始化为0,线程1和线程2都分别对x和y做加一操作后再相互读取对方数据(线程1读取y,线程2读取x),假设每个操作都是原子的,线程1读取y的时候可能是0可能是1,同时线程2读取x的时候只能是1,他们不可能出现都读的是0的情况,什么时候线程1和线程2读取的数据都是0?只有可能他们的指令顺序被更改,当指令顺序被更改,这代表着代码往我们预想不到的方向发展
sequentially consistent是一种强一致性的内存模型,但是现在的x86等架构并没有使用他,因为慢…当一个core下发set指令他要这个指令"广播"给其他的core,保证数据的一致性,无论接下来是本core的原子操作还是其他的core的原子操作,这个内存只能是前一个操作后的值,回顾前面讲到了多个core如何通讯?通过L3cache,并且set指令(写操作)是非常消耗时间的,我们还给他放到L3cache中(将set后的值同步到L3 cache中),可想而知速率有多慢,而sequentially consistent atomic有多慢(但还是比lock块…)
sequentially consistent atomic
首先如果使用了atomic,那么C++是可以保证sequentially consistent atomic特性的
什么是sequentially consistent atomic?他所保证的特性如下
- 所有线程的operation中load和store操作是对所有其他线程可见的
- 必须要遵从(源码)顺序执行
比如我们有2个thread,A和B,其中A执行如下2个操作
thread A
x.store(1);
reg1 = y.load();
线程B执行以下2个操作
thread B
y.store(2);
reg2 = x.load();
假设上述的2个线程的操作遵循sequentially consistent atomic,那么他们的load和store指令是相互可见的(满足条件1),并且每个线程执行atomic operate的顺序严格按照上述伪代码(满足条件2,对于线程A x.store在前y.load在后,对于线程B y.store在前,x.load在这些顺序不能变),那么他们的执行顺序有6种可能
A:x.store(1)--->B:y.store(2)--->A:reg1=y.load()--->B:reg2=x.load()
A:x.store(1)--->B:y.store(2) -->B:reg2=x.load() -->A:reg1=y.load()
A:x.store(1)--->A:reg1=y.load()-->B:y.store(2)-->B:reg2=x.load()
B:y.store(2)--->A:x.store(1)-->A:reg1=y.load()--->B:reg2=x.load()
B:y.store(2)--->A:x.store(1)-->B:reg2=x.load()-->A:reg1=y.load()
B:y.store(2)--->B:reg2=x.load()--->A:x.store(1)-->A:reg1=y.load()
再比如我们2个线程1和2执行下面的指令
线程1指令
x.store(2)
x.load()
线程2指令
x.store(3)
因为load指令是对所有其他线程可见,所以线程1可以看到自己的load指令也可以看到线程2的load指令(限制1),那么执行顺序有3种如下(假设x初始化为1)
1:x.store(2)--->2:x.store(3)--->1:x.load() 结果X=5
2:x.store(3)--->1:x.store(2)--->1:x.load() 结果X=5
1:x.store(2)--->1:x.load()--->2:x.store(3) 结果X=2
2:x.store(3)--->1:x.load()--->1:x.store(2) 结果X=3
上述的顺序永远不会出现,因为1:x.load()不能出现在1:x.store(2)之前,否则违反规则2(代码中规定了执行顺序)
此时你也许会问这有啥用,要知道c++原子操作只会在操作atomic< T > A 的时候是原子的,如下代码
#include 如果说我们想要线程1强制在线程2之后执行(结果为5),也就是下面这个顺序
2:x.store(3)--->1:x.store(2)--->1:x.load() 结果X=5
可以这样写
#include 注意c++原子操作一定是在对原子对象操作一瞬间是原子的,比如上述例子中线程1和线程2中每一个对原子对象
element操作的句子
也许你还会疑问,以为线程1对element操作的2个语句是一个原子操作,其实这是2个原子操作分别是store和load,我们c++ atomic如果不做特殊的设置默认Sequential consistency
Sequential consistency也是分布式领域大牛2013年图灵奖获得者,强分布式一致性协议paxos的发明者 Leslie Lamport发明的
Relaxed memory Consistency models
我们前面讲了sequentially consistent atomic为什么慢,因为他要将写后的数据同步到L3 Cache中去让所有的core都知道,并且写操作是非常消耗性能,如果不做同步结果可能不是我们期望的,而Relaxed memory Consistency models则是一个weak consistency models,在介绍他之前我们先了解一个东西叫做TSO(Total store ordering)
TSO其实就是一个片上缓存,不在L1/L2/L3中,而是在core中(速度更快),它用于存储我们的写操作
假设我们有2个线程1,2,分别执行下面的指令
thread1
A = 1
print(A)
thread 2
B = 1
print(B)
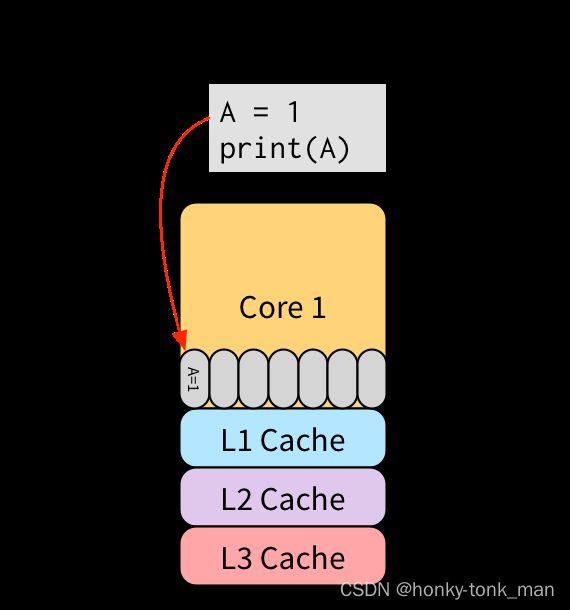
假设线程1被调度到core1上执行,他执行的第一步写操作会被缓存到TSO中,线程1的第二个指令print(B)可以直接取其第一个指令(A = 1)中的结果,无论A=1操作是否完成,因为知道第一条指令的结果,线程2同理,我们之前说过写操作非常耗时(相较于读),这里我们直接hide了写操作的延迟
为什么说Relaxed memory Consistency models是弱一致性的呢?
我们看这个情况,A和B都是初始化为0,我们期望的打印结果是10或者01,一定不会是00,因为按照片代码执行顺序,打印都在set之后(也许你会问在set的同时读取结果是不是set之前的值,答案是不会,因为我们是atomic操作,在操作的时候其他的automic操作不会干扰相同的区域)
thread1
A = 1
print(B)
thread 2
B = 1
print(B)
当加上TSO后如下所示
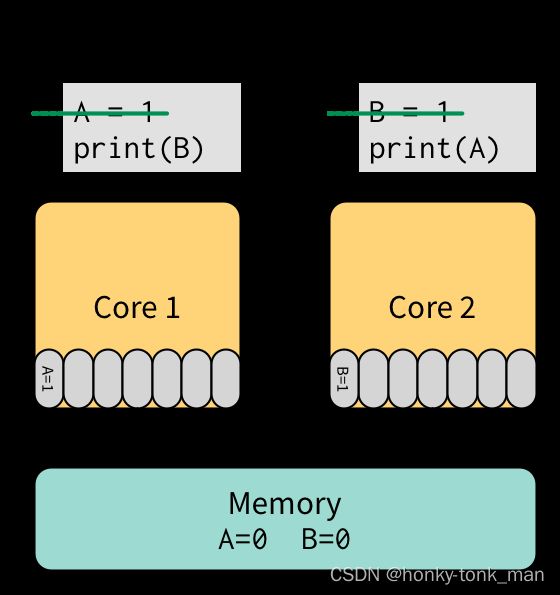
我们print的结果竟然成了我们最不想看到的,因为Core1和Core2都还在写A和B的值,而Core1和Core2的第二条指令已经开始读对方(Core1读Core2 set的1相反Core2读Core1 set的1),但是他们都是先从自己的TSO中查找,最后发现查找失败,只能从内存中找,但是内存中的值是未同步的初始化值,最后打印了00
应对这个问题X86架构的厂商通常会有一个测试叫做litmus tests,在做上述操作的时候通过测试才会让读取,而我们的C++atomic可以设置relexed mode
扩展阅读
- https://www.cs.utexas.edu/~bornholt/post/memory-models.html
- https://coffeebeforearch.github.io/2020/11/29/hardware-memory-ordering.html
- https://www.internalpointers.com/post/understanding-memory-ordering