腾讯游戏原来是这样使用 Prometheus 的!(下)
背景
随着游戏业务不断增多,业务使用的环境也越来越复杂。此时对于监控的难度也是逐步增大,一方面是监控的数据量大;另一方面是多云之间对于监控及时性的解决方案。腾讯游戏团队与腾讯云监控团队协作,深入研究如何持续解决游戏运维监控问题。最终我们通过构建 Prometheus 监控专项能力,提供免搭建的高效运维能力,降低了全球业务监控复杂度,提升了监控及时性等棘手问题。
上期我们介绍了 Prometheus 的基础,我简单回顾一下上期重点知识,Prometheus 的四个指标类型分为 Counter(计数器) Gauge(仪表盘), Histogram(直方图), Summary (摘要)。N 台主机向一台主机上报数据指标,推荐使用 Exporter 数据采集方式;N 台主机向一台主机上报指标,推荐使用 Pushgateway 数据采集方式。欢迎点击 腾讯游戏原来是这样使用 Prometheus 的!(上) 了解更多。
在实战之前,我们再来看一下 Prometheus 的架构图:
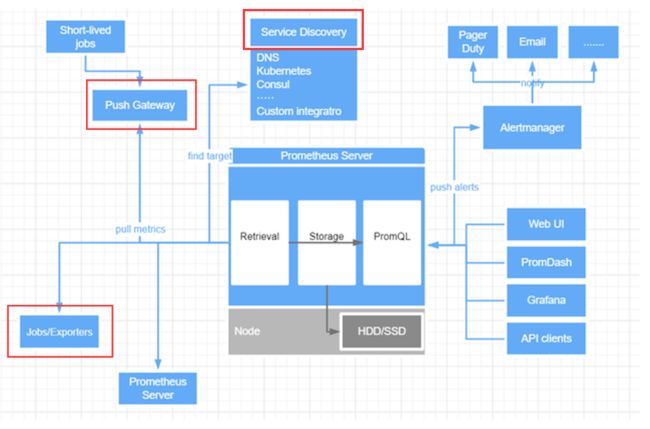
从上图中可以看出,监控数据采集有三种来源:
-
通过 Exporter 进行数据 Pull。
-
对于 short-lived jobs 通过 push 到 pushgateway,然后发送到 Prometheus server。
-
Service Discovery(自动发现)。
下文以腾讯游戏为实践案例,重点介绍 Pull 和 Push 的两种场景,ServiceDiscovery (服务发现)场景常用于 K8S 监控。
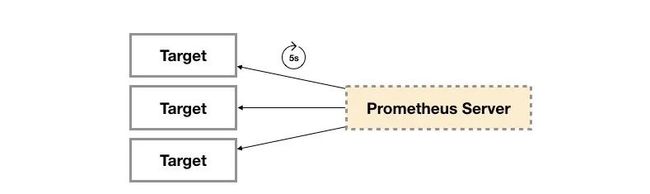
Exporter(Pull)
Exporter 方式是 Prometheus 最常用的监控方式。Prometheus 社区提供了丰富的 Exporter 实现,涵盖了从基础设施,中间件以及网络等各个方面的监控功能。这些 Exporter 可以实现大部分通用的监控需求。广义上讲所有可以向Prometheus 提供监控样本数据的程序都可以被称为一个 Exporter。而 Exporter 的一个实例称为 target,如下所示,Prometheus 通过轮询的方式定期从这些 target 中获取样本数据:
背景需求
某项目在全球统一部署时,采用大厅服和不同地区独立部署战斗服的架构,玩家通过就近接入战斗服的方式进行对战,所以大厅服和战斗服之间的稳定性非常重要,为了优化玩家体验,一般通过拉专线的方式来进行保障。而专线的网络质量,我们必须对其进行实时监控,一旦监控发现异常,可及时联系专线提供商进行处理,保障业务稳定运行。
解决方案
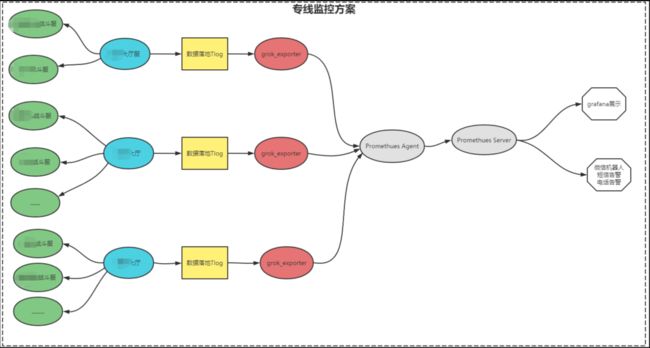
1. 大厅服实时探测各个战斗服之间网络质量,采用持续 Ping 方式
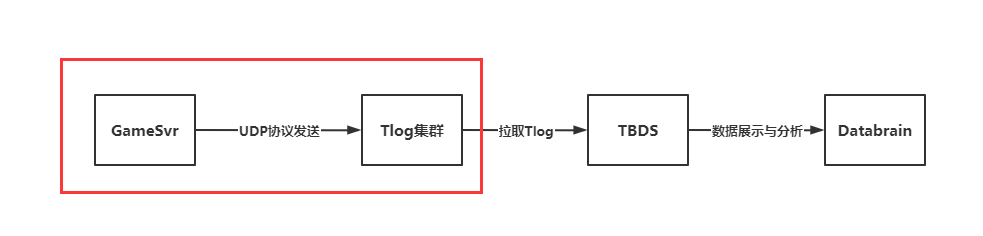
2. 大厅服将采集到的数据通过 tlog 落地
3. 使用 grok-exporter 插件解析 tlog 文件,并将结果上报到 Prometheus-agent,最终汇总到 Promethe-server 端。
架构图如下:
 [点击查看大图]
[点击查看大图]
实施过程
**1.**选取测试节点
我们需要实时监控大厅服和战斗服之间的网络质量,所以必须选择一个大厅服作为源节点,多个战斗服作为目标节点。以欧洲大厅为例:
**2.**搭建 tlog 服务
这里我们只需要前半段,也就是到数据采集这一段:
mkdir/data/home/tlog
上传 tlog.tar.gz 到 /data/home/tlog 目录并解压,修改配置文件 tlogd_bin_vec.xml ,重点修改2个地方即可:
udp://0.0.0.0:10001 #1、侦听地址和端口
/data/home/user00/tlog/logplat/log/tlogd_1/65535_%Y%m%d_%H00.log #2、文件存储路径
1024000
1024000001
3600
100
0
0
启动 tlog 服务:
cd/data/home/user00/tlog/tlogd/&&bash start_tlogd_vec.sh
3. 大厅服部署网络质量采集脚本
catidc_list.txt
1.1.1.1 2.2.2.2 sgame_eu_xxx 1
1.1.1.1 2.2.2.2 sgame_eu_xxx 1
1.1.1.1 2.2.2.2 sgame_eu_xxx 1
1.1.1.1 2.2.2.2 sgame_eu_xxx 1
1.1.1.1 2.2.2.2 sgame_eu_south_xxx 1
catspeed_test.sh
#!/bin/bash
cd/data/home/user00/scripts/
SVR_TIME=`TZ="Asia/xxx"date "+%Y-%m-%d %H:%M:%S"`
DATA_TIME=`date"+%Y-%m-%d %H:%M:00"`
SVR_IP=$(python-c"importsocket;print([(s.connect(('10.0.0.0', 53)), s.getsockname()[0],s.close()) for s in [socket.socket(socket.AF_INET,socket.SOCK_DGRAM)]][0][1])")
SRC_IDC=$(grep${SVR_IP}idc_list.txt|awk'{print$3}')
CCID="0000000"
TLOGSVR="/dev/udp/10.10.10.10/10001"
echo"$SRC_IDC"
functionget_info()
{
pingmin=1000
pingavg=1000
pingmax=1000
pingmdev=1000
IP=$1
DES_IDC=$2
NETWORK=$3
rst=$(ping-W1-c30-i2-q$IP|grep-E'packetloss|rtt min'|tr'\n'',')
FILE="/data/home/user00/log/speed_test/ping_msg_${IP}_${DATA_TIME}.log"
echo $rst|greperror>/dev/null
if[$?-ne0];then
loss_rate=$(echo$rst|awk-F',''{print$3}'|awk'{print$1}'|tr-d'%')
read pingmin pingavg pingmaxpingmdev<<<$(echo$rst|awk-F',''{print$5}'|awk'{print$4}'|awk-F'/''{print$1" "$2" "$3" "$4}')
else
loss_rate=$(echo$rst|awk-F',''{print$4}'|awk'{print$1}'|tr-d'%')
read pingmin pingavg pingmaxpingmdev<<<$(echo$rst|awk-F',''{print$6}'|awk'{print$4}'|awk-F'/''{print$1" "$2" "$3" "$4}')
fi
REPORT_STR="IDC_SPEED_TEST|$DATA_TIME|$SRC_IDC|$DES_IDC|$NETWORK|$loss_rate|$pingmin|$pingavg|$pingmax|$pingmdev|$CCID"
echo $REPORT_STR>$TLOGSVR
#echo $REPORT_STR
if[$loss_rate-ne0];then
echo"$rst">>$FILE
bash/data/home/user00/scripts/get_mtr.sh$IP&
fi
}
whileread innerip outerip desidc has_tunnel
do
if[$innerip"x"!=$SVR_IP"x"];then
if[$has_tunnel=="1"];then
get_info $innerip$desidc0&
sleep1
fi
get_info $outerip $desidc1&
fi
done部署好脚本后,通过 crontab 进行实时数据采集:
*****cd/data/home/user00/scripts&&bash speed_test.sh
此时可以查看 tlog 数据文件夹是否能够正常采集到数据:
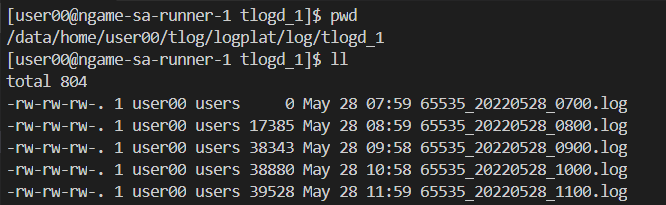
**4.**部署 grok-exporter
从非结构化日志数据中导出 Prometheus metrics!
由于 Prometheus 目前支持的数据格式基本上都是日志数据,所以需要通过第三方工具来进行 log 格式的数据进行解析。grok 是一个工具,可以用来解析非结构化的日志文件,可以使其结构化,同时方便查询,grok 被 logstash 大量依赖,同时社区也提供了一个 Prometheus 的 Exporter 可以方便的进行 log 指标,暴露为 Prometheus 的标准数据格式。
将 tlog-exporter.tar.gz 上传到 /data 目录,并解压。里面其实就是包含 grok_exporter-1.0.0.RC5.linux-amd64,添加日志解析配置文件即可。以下是解析上面 tlog 中采集到的监控数据配置文件:
dir:./patterns
metrics:
-type:gauge
name:ping_loss
help:ping_loss.
match:'IDC_SPEED_TEST\|%{YEAR}-%{MONTHNUM}-%{MONTHDAY}%{HOUR}:%{MINUTE}:%{SECOND}\|%{WORD:zone}\|%{WORD:region}\|%{WORD:network}\|%{NUMBER:ping_loss}\|%{NUMBER:ping_min}\|%{NUMBER:ping_avg}\|%{NUMBER:ping_max}\|%{NUMBER:ping_mdev}\|0000000'
value:'{{.ping_loss}}'
labels:
zone:'{{.zone}}'
region:'{{.region}}'
public_network:'{{.network}}'
-type:gauge
name:ping_min
help:ping_min.
match:'IDC_SPEED_TEST\|%{YEAR}-%{MONTHNUM}-%{MONTHDAY}%{HOUR}:%{MINUTE}:%{SECOND}\|%{WORD:zone}\|%{WORD:region}\|%{WORD:network}\|%{NUMBER:ping_loss}\|%{NUMBER:ping_min}\|%{NUMBER:ping_avg}\|%{NUMBER:ping_max}\|%{NUMBER:ping_mdev}\|0000000'
value:'{{.ping_min}}'
labels:
zone:'{{.zone}}'
region:'{{.region}}'
public_network:'{{.network}}'
-type:gauge
name:ping_avg
help:ping_avg.
match:'IDC_SPEED_TEST\|%{YEAR}-%{MONTHNUM}-%{MONTHDAY}%{HOUR}:%{MINUTE}:%{SECOND}\|%{WORD:zone}\|%{WORD:region}\|%{WORD:network}\|%{NUMBER:ping_loss}\|%{NUMBER:ping_min}\|%{NUMBER:ping_avg}\|%{NUMBER:ping_max}\|%{NUMBER:ping_mdev}\|0000000'
value:'{{.ping_avg}}'
labels:
zone:'{{.zone}}'
region:'{{.region}}'
public_network:'{{.network}}'
-type:gauge
name:ping_max
help:ping_max.
match:'IDC_SPEED_TEST\|%{YEAR}-%{MONTHNUM}-%{MONTHDAY}%{HOUR}:%{MINUTE}:%{SECOND}\|%{WORD:zone}\|%{WORD:region}\|%{WORD:network}\|%{NUMBER:ping_loss}\|%{NUMBER:ping_min}\|%{NUMBER:ping_avg}\|%{NUMBER:ping_max}\|%{NUMBER:ping_mdev}\|0000000'
value:'{{.ping_max}}'
labels:
zone:'{{.zone}}'
region:'{{.region}}'
public_network:'{{.network}}'
server:
protocol:http
port:9000
从配置文件最后三行可以看到,grok-exporter 启动了一个 http 服务,提供暴露 metrics 给外部。

启动 grok-exporter:
cd/data/tlog-exporter/grok_exporter-1.0.0.RC5.linux-amd64/;./grok_exporter-configtunnel_config.yml&
**5.**数据上报
grok-exporter 本质就是一个 exporter,和 node-exporter 一样,所以可以直接上报 metrics 到 Prometheus。通过在云监控上配置即可进行数据上报:
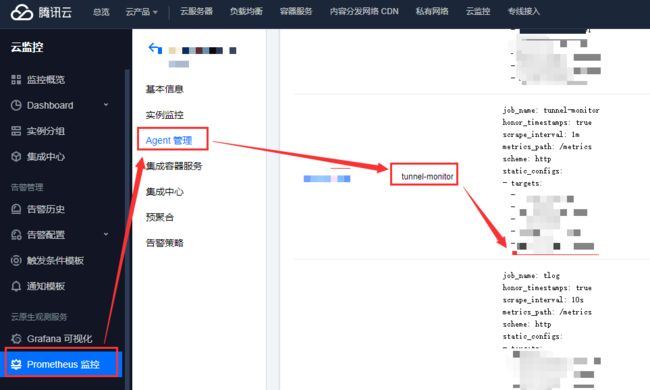
注意事项:
-
开通数据源(大厅服)到 Prometheus Agent 之间的 TCP:9000—保证数据上报正常。
-
开通数据源(大厅服)到各个战斗服之间的 ICMP 权限–保证数据采集正常。
以上三个事项操作完成后,即可到数据源这台机器行进行验证数据是否采集正常:
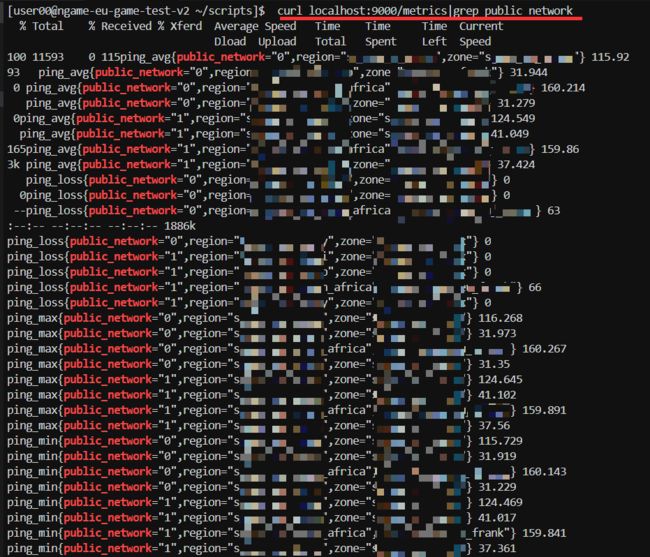
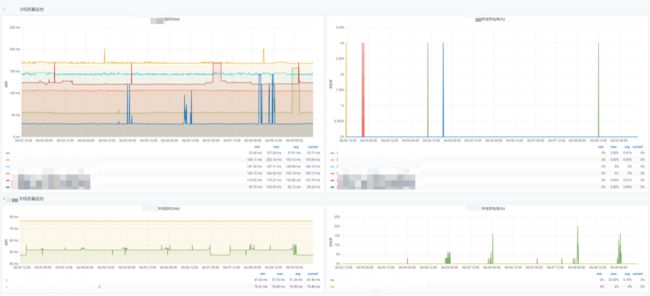
6. Grafana 图表展示
数据采集正常后,我们可以在云监控上购买一个 Grafana 进行数据展示。
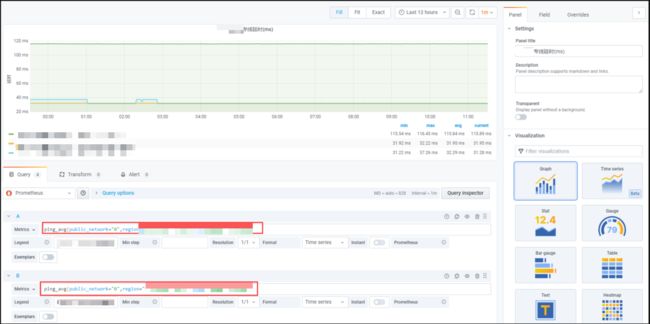
Grafana 图表添加:
延时
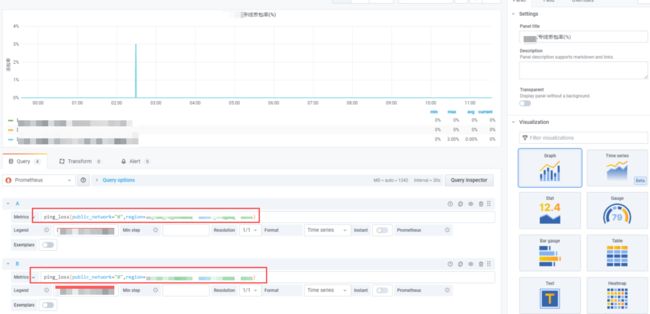
丢包
最终效果图:
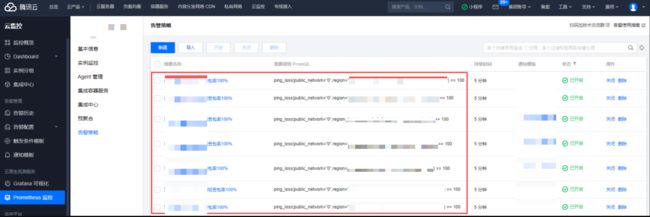
7. 告警通知
云监控上进行告警配置
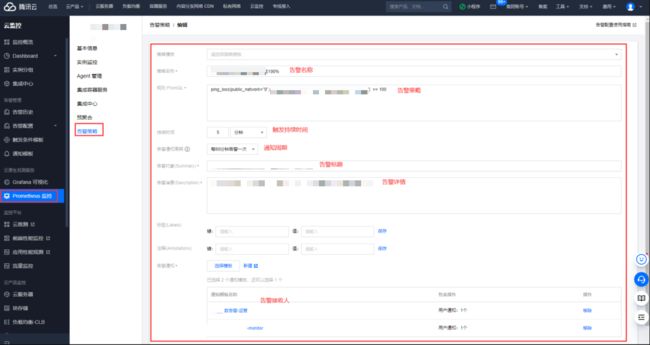
告警通知配置
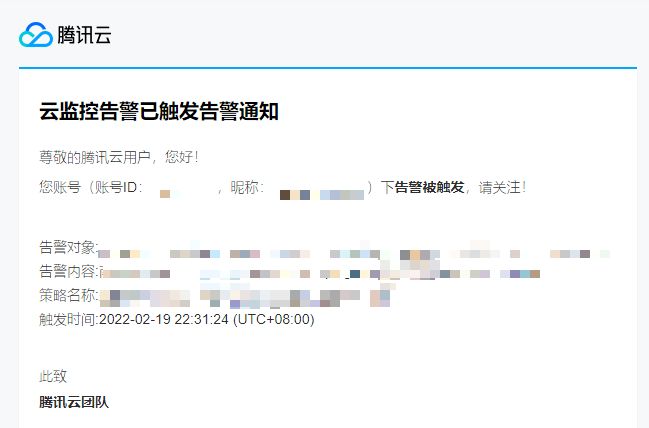
收到的告警通知
8. 最终收益
a. 及时发现网络问题,上报给运营商进行修复
b. SLA 索赔重要依据
专线运营商一般与公司签订了 SLA 协议,影响重大可以索赔,挽回损失。如果我们没有真实数据作为证据,即使专线质量很差,也无法索赔。
PushGateway(Push)
背景需求
某项目在进行一个大版本更新时,有非常多的步骤需要验证每一步参数配置是否正确。由于项目有 N 个大区 M 个服需要同时进行配置检查(主要是 log 文件检查),虽然通过一些脚本可以实时查询,但是需要导出结果进行查看,而且每一步都需要执行查看,很不直观,所以决定采用 Prometheus 进行数据采集,通过图表 Grafana 进行可视化展示。
解决方案
前面提到过的 grok-exporgter 虽然可以对 log 文件进行解析,但是需要在线上业务服务器上启动一个 grok-exporter,有几个风险点需要考虑:
-
如果 log 文件太大,exporter 是否会抢占服务器资源,导致正常业务受损?
-
exporter 是否有安全漏洞,让黑客有机可乘?虽然有安全组,但是不能保证 exporter 不主动连接外网。
-
是否需要对 exporter 的存活进行监控。
-
维护成本。
所以这里我们考虑使用 Prometheus 的另外一种方式:pushgateway。它是一种 short-lived-job,非常适合主动上报一些指标。
我们的数据大部分都是由节点上的 agent 端收集本地数据后暴露到 /metrics,再由 Prometheus pull 到本地进行存储展示的,但是终归这种指标收集的方法是有局限性的,并且有可能被其他如防火墙等安全机制拦截,又或者我们的 client 端并不能采集到我们想要的指标,那么在这种情况下,我们可以通过一个工具 Pushgateway 来进行代理,将其他区域或自定义的指标收集并提交到 Prometheus 上。官网也直接说明了:对于不能直接和 Prometheus Server 通讯的话,推荐使用 pushgateway 。
具体架构如下:
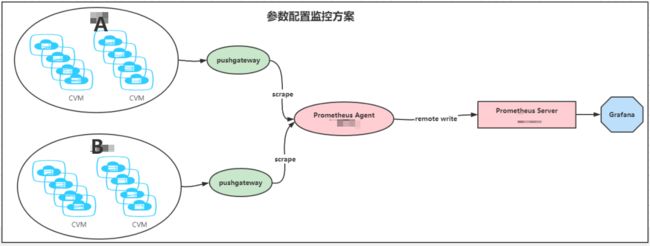
同一个大区或者多个大区(有专线的情况)部署一个 Pushgateway,然后大区下面的服务器向 Gateway 上报数据,Prometheus agent 从 Pushgateway 抓取数据上报到 Prometheus server 。
实施过程
1.部署 Pushgateway
拉取软件包
wgethttps://github.com/prometheus/pushgateway/releases/download/v1.4.0/pushgateway-1.4.0.linux-amd64.tar.gz
解压
tar-zxvfpushgateway-1.4.0.linux-amd64.tar.gz
拷贝二进制文件
cppushgateway-1.4.0.linux-amd64/pushgateway/usr/bin/
添加服务文件
cat>/usr/lib/systemd/system/pushgateway.service<**2.**数据上报
数据上报格式
echo"relaysvr_version${RelaySvrVersion}"|curl--data-binary@-http://${svr_ip}/metrics/job/${job}/instance/${private_ip}/area/${area}/idc/${idc}/host/${hostname}
relaysvr_version:metric
${RelaySvrVersion}:metric 值
job、private_ip、area、idc、hostname 分别表示:job 名称、上报实例、大区、服、主机名
这几个指标对于后面进行图表化展示非常关键,可以通过这些维度对数据进行分类、展示、统计、告警等等。
数据上报脚本(部分,其他 role 类似,添加 else 不同情况即可)
#!/bin/bash
area="xxx"
idc="xxx"
job="config-check"
svr_ip="10.10.10.10:9091"
hostname=`hostname`
private_ip=`/sbin/ifconfig-a|grep inet|grep -v 127.0.0.0|grep -E "(10\.|10.10|10\.)"|grep-v inet6|awk '{print $2}'|tr -d "addr:"`
role=""
role_relay=`echo$hostname|grep "relaysvr"|wc -l`
role_game=`echo$hostname|grep "gamesvr"|wc -l`
role_room=`echo$hostname|grep "roommatch"|wc -l`
role_dirsvr=`echo$hostname|grep "dirsvr"|wc -l`
functiontrans_to_mon(){
case$1 in
JAN|Jan|jan)
mon="01"
;;
FEB|Feb|feb)
mon="02"
;;
MAR|Mar|may)
mon="03"
;;
APR|Apr|apr)
mon="04"
;;
MAY|May|may)
mon="05"
;;
JUN|Jun|jun)
mon="06"
;;
JUL|Jul|jul)
mon="07"
;;
AUG|Aug|aug)
mon="08"
;;
SEP|Sep|sep)
mon="09"
;;
OCT|Oct|oct)
mon="10"
;;
NOV|Nov|nov)
mon="11"
;;
DEC|Dec|dec)
mon="12"
;;
esac
echo$mon
}
functiontrans_to_digts(){
mon_en_build=`echo"$1"|awk '{print $1}'`
mon_digts_build=`trans_to_mon$1`
RelaySvrBuildTime=`echo"$1"|sed "s/$mon_en_build/$mon_digts_build/g"|tr-cd "[0-9]"`
echo $RelaySvrBuildTime
}
if[$role_relay -eq1];then
role="relaysvr"
fileupdate=`ls-al /data/home/user00/sgame/world/cfg/relaysvr.cfg|awk '{print$6,$7,$8}'`
RelaysvrFileUpdate=`trans_to_digts"$fileupdate"`
HeartBeatToRoomSec=`grepHeartBeatToRoomSec /data/home/user00/sgame/world/cfg/relaysvr.cfg|awk-F"=" '{print $2}'`
RelaysvrIsInTesting=`grep"IsCurInTesting"/data/home/user00/sgame/world/cfg/relaysvr.cfg|awk -F[=] '{print$2}'`
buildtime=`cd/data/home/user00/sgame/world/relay/relaysvr/ &&./relaysvr -v|grep "Compile Time"|tail -n 1|awk -F"Time:"'{print $2}'`
RelaySvrBuildTime=`trans_to_digts"$buildtime"`
RelaySvrVersion=`cd/data/home/user00/sgame/world/relay/relaysvr/ &&./relaysvr -v|grep "branches"|head -n 1|awk -F[/] '{print$8}'|tr -cd "[0-9]"`
echo "relaysvr_file_update${RelaysvrFileUpdate}"|curl--data-binary@-http://${svr_ip}/metrics/job/${job}/instance/${private_ip}/area/${area}/idc/${idc}/host/${hostname}
echo "relaysvr_heartbeat_to_roomsec${HeartBeatToRoomSec}"|curl--data-binary@-http://${svr_ip}/metrics/job/${job}/instance/${private_ip}/area/${area}/idc/${idc}/host/${hostname}
echo "relaysvr_is_intesting${RelaysvrIsInTesting}"|curl--data-binary@-http://${svr_ip}/metrics/job/${job}/instance/${private_ip}/area/${area}/idc/${idc}/host/${hostname}
echo "relaysvr_build_time${RelaySvrBuildTime}"|curl--data-binary@-http://${svr_ip}/metrics/job/${job}/instance/${private_ip}/area/${area}/idc/${idc}/host/${hostname}
echo "relaysvr_version${RelaySvrVersion}"|curl--data-binary@-http://${svr_ip}/metrics/job/${job}/instance/${private_ip}/area/${area}/idc/${idc}/host/${hostname}
fi
在服务器上部署好脚本后,做成计划任务
*/1****/bin/bash/data/home/user00/bin/game_state_monitor/configcheck.sh>/dev/null2>&1
Pushgateway 上检查指标: 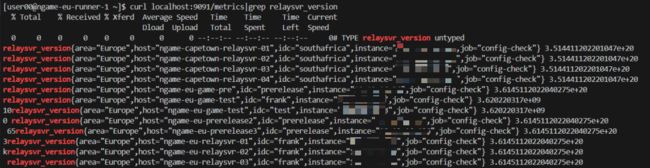
3. Grafana 图标展示
因为我们这里都是一些配置文件,所以更适合用 table 进行展示。
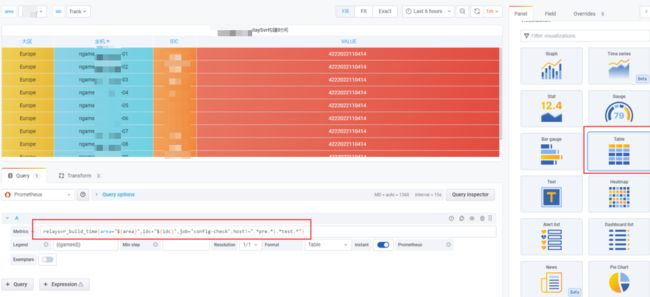
当然,这里还有其他几个地方需要配置,才能出现彩色的图表:

配色方案
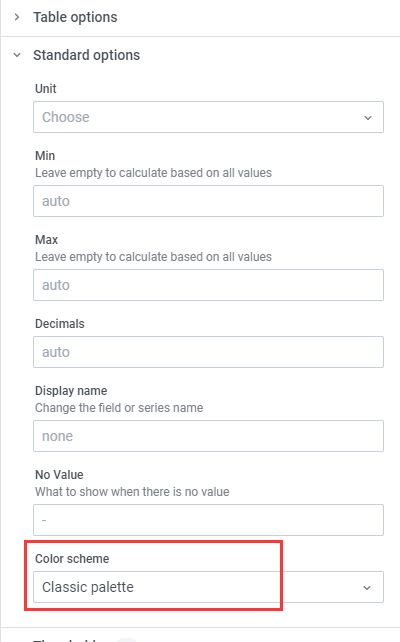
最终效果图

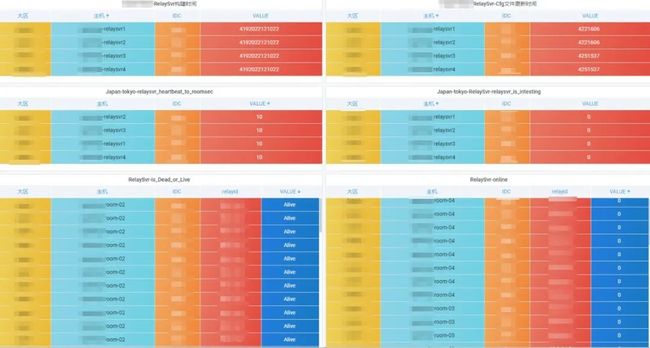

4. 最终收益
a. 节省时间。所有区服在规定时间内,进行了一次不停服更新,对玩家来说是无感知的。

b. 信息直观。更新过程无需登录服务器查看配置,只需要在界面上查看图标信息。
c. 节省人力。一个区技同学跑流水线,一个正职人员查看配置参数就可以搞定所有大区的更新操作。
总结
通过 Prometheus 基础介绍和实战介绍,我们感受到了 Prometheus 的强大,以及 腾讯云 Prometheus 监控服务 给我们带来的便利,替我们省去了运维的后顾之忧。房子是建起来了,但还是毛坯。对于开发运维人员来说,我们需要继续装修,想出更好的方案,让房子住起来更加舒服。