Java之多线程优化与CPU、I/O之间的深入理解
引入
在高并发的场景之下,Java经常使用到的技术就是多线程。而多线程的使用,到底是否真的能够有效地提高服务的性能和效率,就必须拿捏得当,从计算机操作系统,到服务代码,到应用上线之后的监测。得谨小慎微的行走~
今天,就来介绍一下多线程,与系统CPU、核数,以及I/O等之间的关系。来了解一下真正改善系统的因果关系。
先来理解一些概念。
CPU(Central Processing Unit),中央处理器。是一块超大规模的集成电路,是一台计算机的运算核心(Core)和控制核心( Control Unit)。它的功能主要是解释计算机指令以及处理计算机软件中的数据。
CPU核数,CPU上面能处理数据的芯片组的数量。一个CPU可以封装1、2、4、6个运算单位同时做运算,此运算单位称之为核。比如,核心数二,就是两个内核的CPU。
I/O,IO又分为磁盘IO、网络IO。在这里对IO不作详细的阐述,有兴趣的同学可以自行查阅网上资料。简单来说,影响磁盘的关键因数是磁盘服务时间,即磁盘完成一个I/O请求所花费的时间,它由寻道时间、旋转延迟和数据传输时间三部分构成。衡量其关键指标,大致是IOPS、吞吐量等。
并行:多个cpu实例或者多台机器同时执行一段处理逻辑。
并发:通过cpu调度算法,让用户看上去同时执行,实际上从cpu操作层面不是真正的同时。并发往往在场景中有公用的资源,针对这个公用的资源往往产生瓶颈,通常会用TPS或者QPS来反应这个系统的处理能力。
什么是多线程
线程,是操作系统最小的调度单位,进程是资源(比如:内存)分配的最小单位。Java中的所有线程,在JVM的进程当中执行,CPU所调度的就是进程中的线程。
单个cpu线程在同一时刻只能执行一个Java程序,也就是一个线程。
单个线程同时只能在单个cpu线程中执行。
Java多线程并不是由于cpu线程数为多个才称为多线程,当Java线程数大于cpu线程数,操作系统使用时间片机制,采用线程调度算法,频繁的进行线程切换。在网络上有一个被认为合理的线程数值计算为
一般情况
线程数 = cpu个数 * 核数
计算密集型
线程数 = 处理器核心数
IO密集型
线程数 = n*处理器核心数
Java线程的几种状态

单核多CPU与多核单CPU
对于一个CPU,线程数总是大于或等于核心数的。一个核心最少对应一个线程,但通过超线程技术,一个核心可以对应两个线程,也就是说它可以同时运行两个线程。
一台计算机的处理器架构假设有如下两种。
单核多CPU,那么每一个CPU都需要有较为独立的电路支持,有自己的Cache,而他们之间通过板上的总线进行通信。(一致性问题)
假如在这样的架构上,我们要跑一个多线程的程序(常见典型情况),不考虑超线程,那么每一个线程就要跑在一个独立的CPU上,线程间的所有协作都要走总线,而共享的数据更是有可能要在好几个Cache里同时存在。这样的话,总线开销相比较而言是很大的,怎么办?那么多Cache,即使我们不心疼存储能力的浪费,一致性怎么保证?
多核单CPU,那么我们只需要一套芯片组,一套存储,多核之间通过芯片内部总线进行通信,共享使用内存。在这样的架构上,如果我们跑一个多线程的程序,那么线程间通信将比上一种情形更快。
多个CPU常见于分布式系统,用于普通消费级市场的不多,多用于cluster,云计算平台等。多CPU架构最大的瓶颈就是I/O,尤其是各个CPU之间的通讯,低成本的都用100M以太网做,稍微好一点的用1000M以太网,再好的就用光纤等等,但无论如何速度和通量都比不上主板的主线。所以多CPU适用于大计算量,对速度(时间)不(太)敏感的任务,比如一些工程建模,或者像SATI找外星人这种极端的,跑上几千年都不着急的。而且多CPU架构更简单清晰,可以用消费级产品简单做数量堆叠,成本上有优势。而多核单CPU则适合对通讯I/O速度要求较快的应用,(相同核数量下)成本上也高一些,好像只有在超级计算机里会用到以万为单位的核心数,普通消费级产品也就是到16核封顶了,因为成本控制的原因。
磁盘I/O与CPU
IO所需要的CPU资源非常少。大部分工作是分派给DMA完成的。
DMA(Direct Memory Access,直接存储器访问) 是所有现代电脑的重要特色,它允许不同速度的硬件装置来沟通,而不需要依赖于 CPU 的大量中断负载。否则,CPU 需要从来源把每一片段的资料复制到暂存器,然后把它们再次写回到新的地方。在这个时间中,CPU 对于其他的工作来说就无法使用
IO进行时,数据会不停地搬入搬出缓冲区而已(使用了缓冲区)。比如,用户程序发起读操作,导致“ syscall read ”系统调用,就会把数据搬入到一个buffer中;用户发起写操作,导致 “syscall write ”系统调用,将会把一个 buffer中的数据搬出去(发送到网络中 or 写入到磁盘文件)。

过程大致为:
1、内核给磁盘控制器发出指令;
2、在DMA的控制下,把磁盘上的数据读入到内核缓冲区;
3、内核把数据从内核缓冲区复制到用户缓冲区。
对于操作系统而言,JVM只是一个用户进程,处于用户态空间中。而处于用户态空间的进程是不能直接操作底层的硬件的。而IO操作就需要操作底层的硬件,比如磁盘。因此,IO操作必须得借助内核的帮助才能完成(中断,trap),即:会有用户态到内核态的切换。
多线程的底层机制是由操作系统实现的,当一个线程遇到IO阻塞时,例如读写文件,操作系统可能会暂时挂起该线程,从而让其他线程优先执行,也就是将多出来的时间片切分给其他的线程,直到等待该线程的IO操作返回,再重新调度该线程运行。
CPU密集
CPU密集的意思是该任务需要大量的运算,而没有阻塞,CPU一直全速运行。
CPU密集任务只有在真正的多核CPU上才可能得到加速(通过多线程),而在单核CPU上,无论你开几个模拟的多线程,该任务都不可能得到加速,因为CPU总的运算能力就那些。
IO密集
IO密集型,即该任务需要大量的IO,即大量的阻塞。在单线程上运行IO密集型的任务会导致浪费大量的CPU运算能力浪费在等待。所以在IO密集型任务中使用多线程可以大大的加速程序运行,即时在单核CPU上,这种加速主要就是利用了被浪费掉的阻塞时间。
除了同步IO之外,系统可能还支持异步IO,即IO不阻塞,对IO设备发出读写命令之后立即返回执行下一条命令,而IO设备的返回结果则在将来未知的某个时间点通过信号来回调。这也是nodeJS底层的实现机制。
线程管理
因此,Java实现多线程来提高系统性能,通常的一种解决办法就是,使用线程池进行管理和控制。从而协调配合CPU、IO等指标,达到尽可能能地使用计算机的所有有效资源。
ThreadPoolExecutor大致逻辑
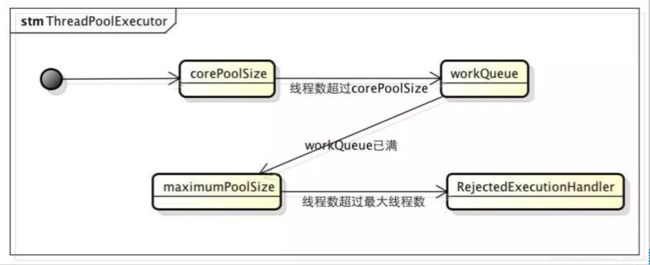
核心的构造方法参数
| 参数名 |
作用 |
|---|---|
| corePoolSize |
核心线程池大小 |
| maximumPoolSize |
最大线程池大小 |
| keepAliveTime |
线程池中超过corePoolSize数目的空闲线程最大存活时间;可以allowCoreThreadTimeOut(true)使得核心线程有效时间 |
| TimeUnit |
keepAliveTime时间单位 |
| workQueue |
阻塞任务队列 |
| threadFactory |
新建线程工厂 |
| RejectedExecutionHandler |
当提交任务数超过maxmumPoolSize+workQueue之和时,任务会交给RejectedExecutionHandler来处理 |
小结
进程之间是相互独立的,不共享内存和数据,线程之间的内存和数据是公用的,每个线程只有自己的一组CPU指令、寄存器和堆栈,对于线程来说只有CPU里的东西是自己独享的,程序中的其他东西都是跟同一个进程里的其他线程共享的。
操作系统创建进程时要分配好多外部资源。相对于读文件、查数据库、访问网络来说,CPU计算的时间使用较少。多线程可以说是计算机多种资源的并行运用。