区块链浏览器构建实战
前言
随着区块链技术的不断发展和应用落地,大众逐步加深了对区块链技术的认识。我们都知道,区块链具有可追溯、不可篡改等技术特点,那么链上的数据如何查询、溯源呢?这就是我们今天要分享的主角—区块链浏览器。
区块链浏览器:是链上数据可视化的主要窗口,是提供用户浏览与查询区块链所有信息的工具。借助这一窗口,如区块信息、交易信息、账户信息等重要的加密数据得以直观呈现。因此,区块链浏览器对于区块链使用者而言至关重要。以目前国外开源区块链项目以太坊为例,其社区开源浏览器Etherscan承载大量用户流量,是分析链上行为最便捷的工具。
本文将从区块链浏览器研发实操经验切入,与大家交流如何快速构建一个区块链浏览器。
浏览器可以呈现什么?
通过分析一些开源浏览器,我们总结出区块链浏览器展示的典型区块链信息如下几类:
- 区块高度
- 交易数
- 交易趋势
- 区块列表
- 最近交易列表等
浏览器数据可以直接获取吗?
通常,区块链提供必要的链SDK信息,用以帮助开发者获取链上区块和交易数据,但是其提供的接口往往是基础性的,例如如何获取区块高度、获取某个区块详情、获取某个交易详情等,这些数据直接对应了页面上的区块列表、区块详情、交易详情等基础数据,无法直接通过链SDK获取浏览器所需的的全量信息。
为此,一个好的区块浏览器是需要支持在本地进行链上数据的加工与处理。
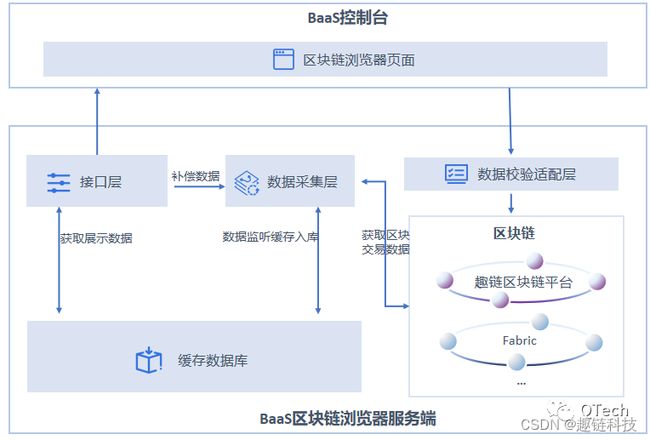
首先,通过对不同区块链底层的区块和交易数据等进行监听,当链上产生新区块时,监听系统可通过链SDK第一时间获取该区块的信息;随后,系统将相关数据进行缓存入库,按需设计多种统计逻辑以完成数据的加工统计。因此,区块链浏览器页面上的数据并非直接通过链上SDK直接请求获取,而是源于本地的列表数据和统计数据。
较于通用的直接通过链SDK获取的模式,我们更需要的是一个通过本地缓存区块数据并且加工链上数据的方式来显著提升前端对区块链浏览器数据获取速度,但对于这一方案读者可能会产生两个质疑:
**组件是定时获取链上SDK数据的,那就意味着本地数据与链上数据存在时差,这会影响使用体验么?
由于不是链上直接获取,那如何保障本地缓存内的数据真实有效性呢?
针对质疑一,显然这个时差主要源于本地定时获取链上数据的频率,因此通过控制频率范围在合理范围内,就可以实现极短的延时,基本不会影响用户使用浏览器的性能体验。而针对质疑二是本方案中研发设计人员需要重点关注并解决的。
如何保障数据真实有效?
实际上,为了确保数据浏览器数据的真实性,区块浏览器需要增加数据校验模块,即用户可以通过简单的接口调用与区块链进行交互,快速验证数据的真实性。例如,上述校验模块中接口主要包括如下功能:
区块证明:用于证明特定区块是否在区块链的账本数据中存在;
交易证明:用于证明特定交易或者交易执行结果是否在区块链账本数据中存在;
账户证明:用于证明特定账户数据是否在区块链账本数据中存在;
因此通过上述分解,我们可以将整个浏览器的数据获取、加工、校验的流程理解如下:
区块链浏览器设计实操
前面已初步介绍了区块链浏览器的设计思路以及整体运作流程。下面我们以趣链BaaS区块链浏览器为例,详细介绍该区块浏览器的具体设计,如何实现不同区块链的区块及交易数据采集和存储。如下所示,整个自研浏览器组件整体架构如下:
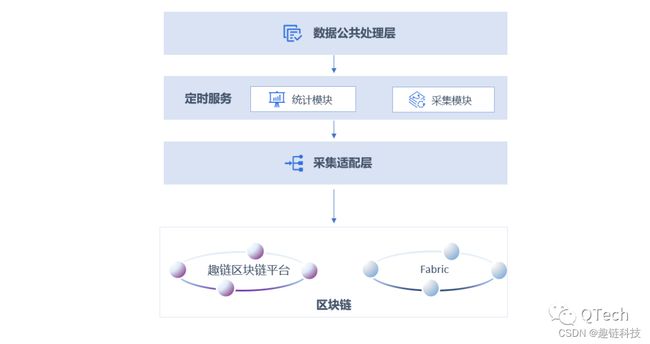
自研浏览器组件架构图
为便于大家理解,我们首先对架构图中的各模块功能进行简单描述:
Ø数据公共处理层:负责数据存储优化等功能,将在下一篇推文中着重介绍相关的功能设计;
Ø采集适配层:负责不同区块链数据的采集适配;
Ø定时服务:负责定时触发采集和统计逻辑,采集器主要通过趣链BaaS的自研链驱动功能实现与不同的区块链底层进行交互并且获取最新的区块和交易数据。其中:
■采集模块:负责定时主动触发采集逻辑,包括数据处理等功能;
■统计模块:
1)统计模块也是定时服务,定时判断是否有新数据入库;
2)若产生新数据则会触发统计逻辑,如区块数、交易数、合约数、合约调用数等指标统计;
3)统计数据将直接入库或者更新已有数据;
现在有了这些介绍,我们就可以将目光聚焦在趣链自研浏览器组件是如何在一个服务里面获取不同区块链的数据。首先,我们对其设计了一个抽象采集层,在具体调用时只需传入趣链BaaS自研的链驱动即可。
例如,以下示例展示了如何获取最新区块接口:
// Collector collector definition
type Collector interface {
// GetLatestBlock 获取最新的区块
GetLatestBlock() (*Block, error)
}
随后,通过如何实现趣链区块链平台的区块数据采集代码来实际演示如何运作,
- 自建项目
hpc,创建目录 - 进入 hpc目录
cd hpc
go mod init hpc
touch main.go
- 成功目录结构如下
.
├── go.mod
└── main.go
- go.mod 引入依赖
module hpc
go 1.17
require (
git.hyperchain.cn/blocface/chainsdk v0.0.1
)
- main.go 编辑, 可关注代码注释的补充描述:首先,将自定义实现接口Collector的对象注册进执行器,引入采集器执行器,执行即可;
*注意:若链上没有区块,此方法返回 &bs.Block{}, nil,各种不同的区块链可通过自定义实现方式来达到采集效果;
package main
import (
bs "git.hyperchain.cn/blocface/chainsdk/pkg/collect/base"
"git.hyperchain.cn/blocface/chainsdk/pkg/collect/collectinter"
)
func main() {
err := collectinter.Register(mockImp{})
if err != nil {
panic(err)
}
collectinter.Execute()
}
type mockImp struct {
}
func (m mockImp) GetLatestBlock() (*bs.Block, error) {
panic("自定义实现获取最新区块")
}
- 工具包中提供信息对象,如提供节点或者链的相关信息
type Base struct {
node string
Node struct {
Name string
Type string
Host string
Ports string
UniqueName string
}
Channel string
}
- 编译打包(平台 GOOS=linux 架构GOARCH=amd64)
GOOS=linux GOARCH=amd64 go build -ldflags="-w -s" -gcflags="all=-N -l" -o hpc .
通过上述步骤,我们实现了趣链区块链平台的区块数据采集,随后,我们只需在趣链自研浏览器组件中调用引入相关的客户端包,根据驱动二进制的路径新建客户端即可。
// NewChainClient new chain client
func NewChainClient(tool, channel, cfgRootPath string, node base.Node, opts ...ClientOpt) (*ChainClient, error) {
abs, err := filepath.Abs(tool)
if err != nil {
return nil, errors.Wrap(err, "get absolute path")
}
marshal, err := json.Marshal(node)
if err != nil {
return nil, errors.Wrap(err, "marshal node")
}
c := &ChainClient{
tool: abs,
node: string(marshal),
channel: channel,
configRootPath: cfgRootPath,
timeout: 10 * time.Second,
}
for _, opt := range opts {
opt(c)
}
return c, nil
}
调用逻辑获取最新区块示例
func (c ChainClient) GetLatestBlock() (*base.Block, error) {
command := fmt.Sprintf("%s -p '%s' -m GetLatestBlock ", c.tool, c.configRootPath)
out, err := util.NewDefaultCMD(command, []string{}, util.WithTimeout(int(c.timeout.Seconds())), util.WithForceKill(true), util.WithErrPrint(false)).Run()
if err != nil {
return nil, errors.Wrap(err, "call GetLatestBlock")
}
out = strings.TrimSuffix(out, "\n")
var b = base.Block{}
err = deocde([]byte(out), &b)
if err != nil {
return nil, errors.Wrapf(err, "decode resp [%s]", out)
}
return &b, nil
}
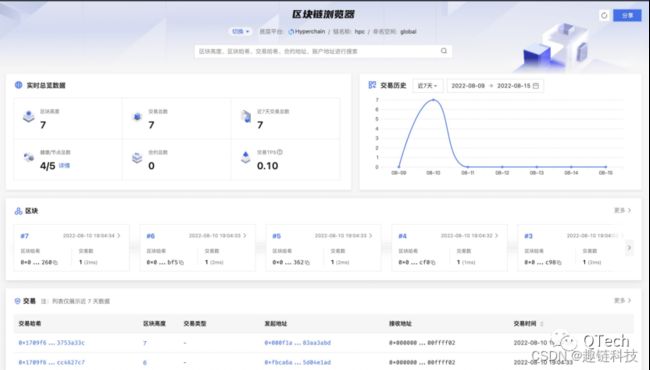
以下是趣链BaaS的区块链浏览器前端页面,只需调取内部接口就可以直接从数据库中获取所需的信息,我们从区块、交易、合约、账户等多个维度为用户提供直观的链上数据呈现,便于用户更好的洞悉链上业务运行全貌。
总结
趣链自研浏览器组件通过上述模式实现无差异化的调用逻辑,达到对不同区块链底层数据的统一支持,并充分预留了新区块链底层的灵活扩展性。通过上述核心功能模块设计,基本实现了区块链浏览器的最小化产品MVP。
当然,实际在搭建区块链浏览器时,还有很多挑战,最典型的挑战之一就是如何应对大数据量,相信细心的读者已经看到前面的架构介绍中提到了数据公共处理层,这一模块主要就是进行数据存储相关的优化,保证数据存储不会随时间的增加而不断增加,充分减轻服务器存储部分的压力,我们将在后续推文中着重介绍~