区块链系统Docker&Kuberntes一键部署
前言
在《一图读懂BaaS》中我们介绍了BaaS平台作为一种将区块链和云计算深度结合的新型服务平台,能帮助用户快速上手区块链业务。通过BaaS平台可快捷管控联盟链,确保链上业务稳定运行。
因此,随着区块链的广泛应用,Baas服务的稳定性日趋关键,其中高可用部署就是重要环节。本文将从BaaS系统如何通过冗余+自动故障转移等机制,实现系统的高可用。
如何度量系统高可用?
在讨论系统高可用性之前,有必要先搞清楚可用性的概念,顾名思义为系统的可用程度,因此可以采用系统无故障运营的时间占总运营时间的百分比来衡量。若要以数学方式严谨定义,则需引入两个统计指标:
平均无故障时间(Mean Time Between Failures, MTBF) ,即两次故障之间正常运行的平均时间。MTBF越大,表明越不容易出故障,可用性越高,该指标反映的是网络的可靠性(reliability)。
平均修复时间 (Mean Time To Repair, MTTR), 即出现故障后修复故障的平均时间。MTTR越小,表明故障时间越短,可用性也越高,该指标反映的是网络的容错能力(fault-tolerant capability)。
有了这两个指标,可用性可以如此计算:Availability = MTBF/(MTBF+MTTR)
直观感受高可用指标等级
例如,一年365天中某系统出现5次故障,总故障时间为1小时,那么如何计算该系统高可用性呢?
首先,计算1年中的可用时间,即总时间减去故障时间为: 365*24 - 1=8759个小时,接下来计算MTBF和MTTR:
◆平均无故障时间=总的可用时间除以故障次数:
MTBF = 8759/5 = 1751.8小时
◆平均修复时间=故障时间除以故障次数:
MTTR = 1/5 = 0.2 小时
最后,Availability = MTBF/(MTBF+MTTR) = 99.9886% 即这个系统的可用性为 99.9886%,接近4个9的水平。
下表格揭示了n个9的可用性情况下,对应一年内中断服务时间:
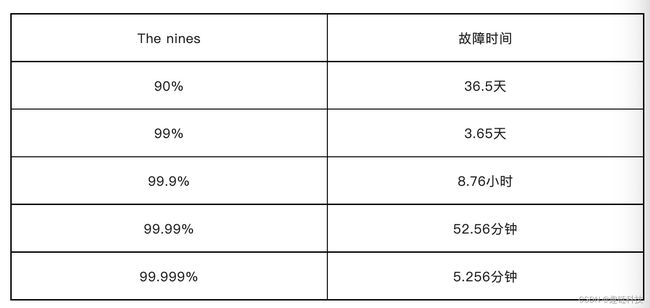
你会发现和主观想象不一样,99%的可用性其实效果并不理想,它意味着一年中系统有长达3.65天是不可用的。
如何提高系统可用性?
鉴于Availability = MTBF/(MTBF+MTTR) ,可以直观感受到:提高MTBF,降低MTTR均可以提高系统可用性。本文以如何提高MTBF为核心,即避免系统发生故障,全面提升系统可用性。
针对BaaS系统而言,导致系统故障不可用的因素很多,大致可归纳为:
1)服务器硬件故障,如服务器宕机;
2)网络线路故障,如挖断网线;
3)存储磁盘故障,如硬盘出现坏道,分区表损坏;
4)软件服务故障,如并发量/用户请求量激增导致整个服务宕掉或者部分服务不可用。
针对上述典型的硬件、网络基础设备、存储磁盘、软件服务的故障因素, BaaS系统架构设计时,如何从架构设计层面提升系统的可用性呢?
BaaS系统的分层架构

上图概括性地剖析了BaaS系统分布式架构的通用设计,考虑到BaaS系统涉及到对联盟链部署、合约部署、监控、日志等众多领域服务模块,趣链BaaS在设计中采用前后端分离,而后端服务选用微服务架构的设计方案。
按照用户流量流入方向,自上而下划分为:客户端层->高可用反向代理层->Web前端服务->系统网管层->后端微服务层->存储层。具体而言:
1、客户端层: 典型的调用方是浏览器browser或者SDK lite Https;
2、高可用反向代理(LoadBalance): 例如选用keepalive + haproxy组合的高可用反向代理,作为系统入口;
3、Web应用:实现核心的页面渲染逻辑;
4、微服务层:根据功能领域的不同进行服务化拆分部署,提供开发效率;
5、数据存储层/缓存层:提供服务稳定可用的文件存储以及缓存层加速服务性能;
6、数据库层:提供高可用的关系型数据库存储方案。
综上,从基础的硬件层到操作系统层、数据库层、服务应用层、网络层,都有可能产生单点故障,若要实现系统的高可用,就要有效消除系统每一层的单点故障,可以总结为通过每一层的冗余+自动故障转移来实现整个系统的高可用。
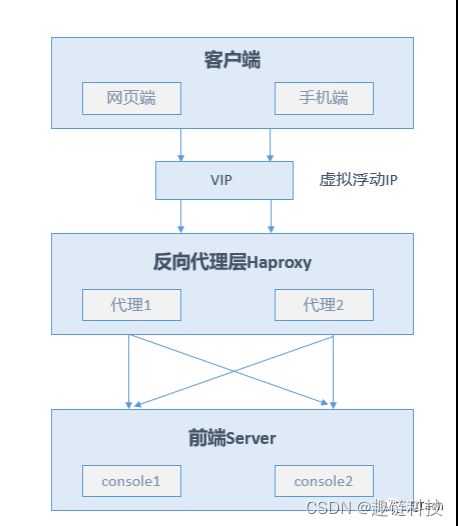
客户端层->反向代理层
反向代理是位于 Web 服务器前面的服务器,负责将客户端(例如 Web 浏览器)请求转发至 Web 服务器。通常用于帮助提高安全性、性能和可靠性,具体而言反向代理具有如下优势:
负载均衡: 提供负载均衡解决方案,在不同服务器之间平均分配传入流量,防止单个服务器过载,若某台服务器无法运行,则其他服务器可以代为处理。
防范攻击: 配置反向代理后,服务无需透漏其源服务器的IP地址,使得攻击者更难对源服务器发起针对性攻击。
全局服务器负载平衡(GSLB):此模式下,一个网站可以分布在全球各地的多个服务器上,反向代理会将客户端发送到地理位置上最接近它们的服务器,可减少请求和响应传播的距离,最大程度减少加载时间。
一方面,在BaaS系统中引入反向代理层可带来诸多好处,但另一方面在高可用场景下,反向代理层自身也会成为系统中的单点故障,为此需要为反向代理层设置高可用方案。实践中,可考虑通过反向代理层的冗余和故障自动转移来实现,以haproxy为例:有两台haproxy,一台提供反向代理服务,另一台通过冗余方式保证高可用,常见的实践是keepalived通过探测haproxy(Load balancer)服务的状态以及配置同一个虚拟浮动IP(Floating IP),当其中Active haproxy(Load balancer)挂掉时,会被Keepalived探测到这一异常情况,随后自动启用故障转移机制,将客户端流量自动迁移至其他Passive haproxy(Load Balancer)。由于上述两个haproxy选用的相同的对外Floating Vitual IP,因此这一过程用户是无感知的。
Web服务->后端微服务
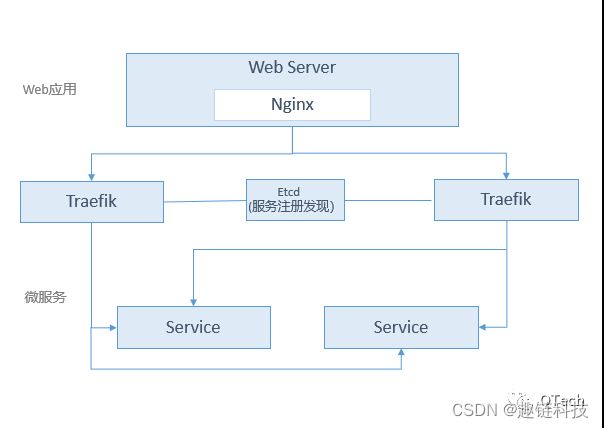
前端Web服务到后端微服务之间有一层反向代理层,负责将前端请求根据不同的路由规则路由到有效的后端服务地址。目前市面上通用的作为反向代理的组件有Nginx、Haproxy、Traefik等等。以Traefik为例,具有Http 动态更新路由、支持请求的粘性Session (sticky session)、接口的Healthcheck等众多优良特性。实践中,反向代理层可采用Traefik针对后端服务地址提供的Health Check机制,当任一Servers服务中的后端地址挂了后,会自动进行故障转移,将流量请求迁移到其他的Servers 地址,整个过程由Traefik自动完成,对调用方是透明的。
微服务层->缓存层
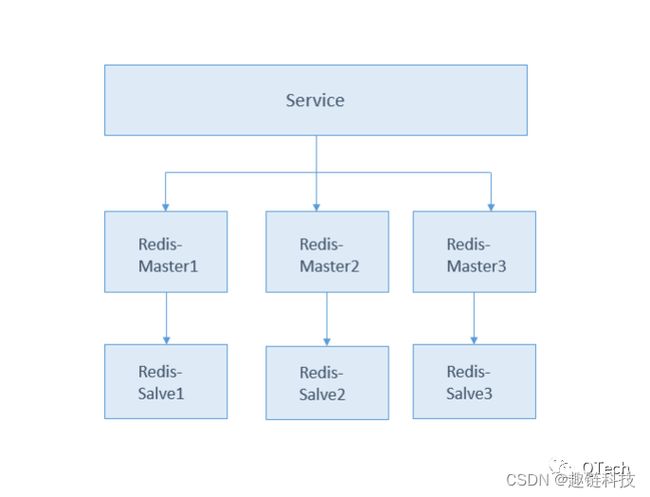
微服务到缓存层的高可用,通过缓存数据的冗余实现。经典的缓存层数据冗余有以下两种做法:
方案一:利用客户端的封装,Service对cache进行双读或者双写;
方案二:使用支持主从同步的缓存集群来解决缓存层高可用,以redis集群主从模式为例,当redis中的任意主master挂了之后,若该master节点有相应的slave节点存活,则自动将slave节点升级为master节点,保证redis缓存服务的高可用。
微服务层->存储层
实践中,BaaS平台存储层的高可用方案可考虑选用NFS + Keepalive + Rsync的同步架构, 不同主机部署多个NFS-Server后端以及Keepalived,通过Keepalived的VIP地址对外提供统一的NFS服务Server地址,每个热备组内同一时刻只有一台主服务器提供服务,其他服务器处于冗余状态,若主NFS服务宕机,其虚拟VIP地址会被其他备用NFS服务器接替(接替顺序可按优先级排序),实现高可用的NFS服务。
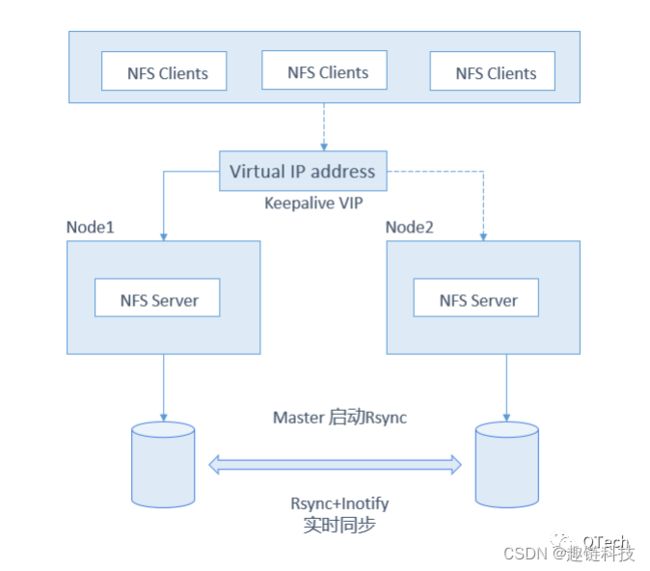
微服务层->数据库层
由于大部分系统的数据库层都采用了“主从同步,读写分离”架构,所以数据库层的高可用,又分为“读库高可用”和“写库高可用”两大类。
▲读库高可用

顾名思义,读库高可用可通过读库的冗余实现。至少配置1个主库,2个从库,“数据库连接池”会建立与这些读库的连接,每次请求最终会路由至这些读数据库中。当任意一个读数据库挂了之后,数据库连接池会通过健康检查探测到这一异常并自动进行故障转移,流量便会自动迁移至其他读库,整个过程由数据库连接池自动完成。
▲写库高可用
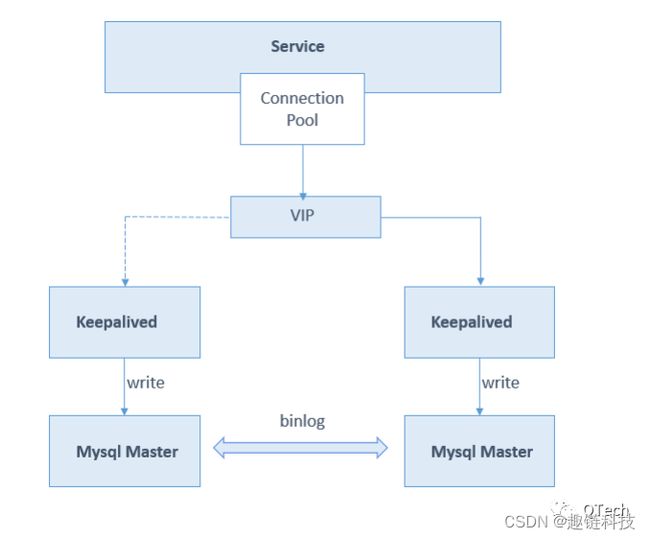
同理,写库高可用通过写库的冗余来实现,以MySQL双主同步模式为例,其中一台对外提供服务,另一台冗余以保证高可用,一旦keepalived探测到主库异常情况后会自动故障转移,将流量迁移至另一台的db-master。
总结
本文以如何提高平均无故障时间(Mean Time Between Failures, MTBF)为核心,针对导致BaaS系统故障的硬件、网络基础设备和存储磁盘等常见故障因素,分析了在BaaS架构设计中,如何针对性的对各层设计对应的“冗余+自动故障转移机制”,最大化避免系统发生故障,全面提升系统可用性。
实践中,提升系统高可用任重而道远,我们也会在未来的推文中持续介绍趣链BaaS如何在缩短平均修复时间 (Mean Time To Repair, MTTR)等维度,进一步提升系统高可用。