Python学习之旅三:python高级语法
使用pycharm和jupter notebook。
1 包
1.1 模块
一个模块就是一个包含python代码的文件,后缀名为.py即可,模块就是个python文件。
1.1.1 为什么要使用模块呢?
- 程序太大,编写维护非常不方便,需要拆分
- 模块可以增加代码重复利用的方式
- 当做命名空间使用,避免命名冲突
- 模块就是一个普通文件,所以任何代码都可以直接书写
1.1.2 根据模块的规范,在模块中需要包含以下内容:
- 函数(单一功能)
- 类(相似功能的组合,或者类似业务模块)
- 测试代码
1.1.3 使用模块的方法:
模块直接引入(加入模块命名以数字开头,需要借助importlib),语法如下
#1.将一整个模块导入
import module_name
module_name.function_name
module_name.class_name
#2.有选择性的导入
from module_name import function_name, class_name
function_name #不需要前缀,直接使用
class_name
#3.导入所有,正常使用也不需要前缀
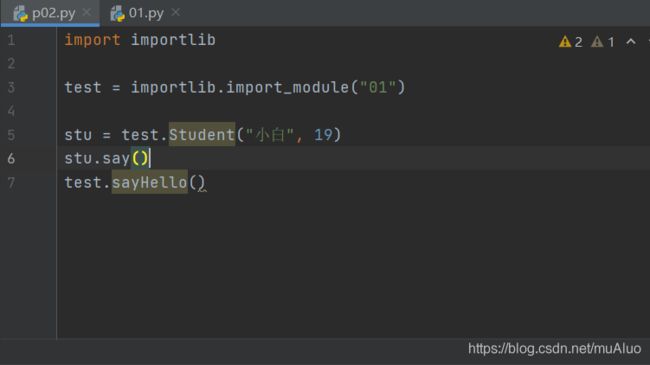
from module_name import *例如:新建模块test,新建.py文件p02,在p02中引入test模块:

运行(Ctrl+Shift+F10)结果如下:

python语法中不允许以数字开头的命名方式,但是借助importlib包可以实现导入以数字开头的模块名称。如下:
1.1.4 if __name__ == "__main__"的使用:
- 可以有效避免模块代码被导入的时候被动执行的问题
- 建议所有程序的入口都以此代码为入口
例如:
结果如下:

1.1.5 模块的搜索路径与存储
模块的搜索路径:加载模块的时候,系统会在哪些地方寻找此模块
- 系统默认的模块搜索路径
import sys
sys.path 属性可以获取路径列表
- 添加搜索路径
sys.path.append(dir)
- 模块的加载顺序:(1)搜索内存中已经加载好的模块(2)搜索python中内置模块(3)搜索sys.path路径
1.2 包
包是一种组织管理代码的方式,包里面存放的是模块。
用于将模块包含在一起的文件夹就是包。
1.2.1 自定义包的结构
/---包
/---/--- __init__.py 包的标志文件
/---/--- 模块1
/---/--- 模块2
/---/--- 子包(子文件夹)
/---/---/--- __init__.py 包的标志文件
/---/---/--- 子包模块1
/---/---/--- 子包模块21.2.2 包的导入
- 直接导入一个包
import package_name可以使用__init__.py中的内容,使用方式是:
package_name.func_name
package_name.class_name.func_name()案例
新建一个包pkg01,在项目根目录下新建一个p04.py。
__init__.py:
def inInit():
print("I am in init of package")p04.py:
import pkg01
pkg01.inInit()运行结果:

- 导入某个包里的某个具体模块
import package.module
#使用方法
package.module.func_name
package.module.class.func()
package.module.class.var- 从包中导入某个模块
from package_name import module1, module2, module3, ... #这种导入方法不执行__init__中的内容
#使用方法
module.func_name
- 导入当前包'__init__.py'文件中所有的函数和类
from package_name import *
#使用方法
func_name()
class_name.func_name()
class_name.var- 倒入包中特定模块的所有内容
from package_name.module import *
#使用方法
func_name()
class_name.func_name()- 在开发环境中经常会使用其他模块,可以在当前包直接导入其他模块中的内容
import 完整的包或者模块的路径- '__all__'的用法:在使用from package import *的时候,*可以导入的内容(即不是导入所有,而是导入指定的)。
__init__.py中如果为空,或者没有__all__,那么只可以把__init__中的内容导入;__init__如果设置了__all__的值,那么则按照__all__指定的子包或者模块进行导入,不会载入__init__中的内容。
'__all__' = ['module1', 'module2', 'package1' ......]案例
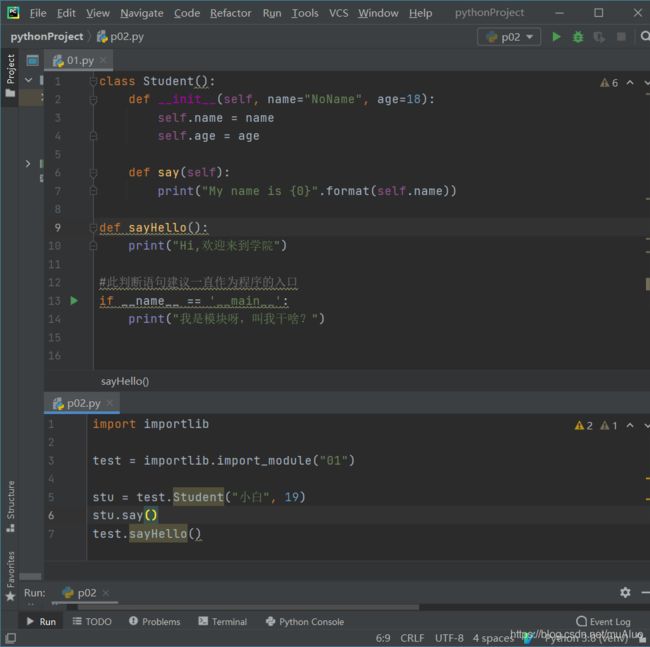
新建包pkg02,在其下新建文件p01.py,在根目录下新建p07.py。
p01.py:
class Student():
def __init__(self, name="NoName", age=18):
self.name = name
self.age = age
def say(self):
print("My name is {0}".format(self.name))
def sayHello():
print("Hi,欢迎来到学院")
#此判断语句建议一直作为程序的入口
if __name__ == '__main__':
print("我是模块呀,叫我干啥?")
p07.py:
from pkg02 import *
stu = p01.Student()
stu.say()运行结果:

1.3 命名空间
用于区分不同位置不同功能但相同名称的函数或者变量的一个特定前缀。
作用是防止命名冲突。
2 异常
广义上的错误分为错误和异常。
- 错误指的是可以人为避免。
- 异常是指在语法逻辑正确的前提下出现的问题。
- 在python中,异常是一个类,可以处理和使用。一般下,异常是系统给我们规定好的,一般不需要自己去定义异常。
2.1 异常的分类
BaseException 是所有异常的基类
AssertError 断言语句(assert)失败
AttributeError 尝试访问未知的对象属性
EOFError 用户输入文件末尾标志EOF(Ctrl+d)
FloatingPointError 浮点计算错误
GeneratorExit generator.close()方法被调用的时候
ImportError 导入模块失败的时候
IndexError 索引超出序列的范围
KeyError 字典中查找一个不存在的关键字
KeyboardInterrupt 用户输入中断键(Ctrl+c)
MemoryError 内存溢出(可通过删除对象释放内存)
NameError 尝试访问一个不存在的变量
NotImplementedError 尚未实现的方法
OSError 操作系统产生的异常(例如打开一个不存在的文件)
OverflowError 数值运算超出最大限制
ReferenceError 弱引用(weak reference)试图访问一个已经被垃圾回收机制回收了的对象
RuntimeError 一般的运行时错误
StopIteration 迭代器没有更多的值
SyntaxError Python的语法错误
IndentationError 缩进错误
TabError Tab和空格混合使用
SystemError Python编译器系统错误
SystemExit Python编译器进程被关闭
TypeError 不同类型间的无效操作
UnboundLocalError 访问一个未初始化的本地变量(NameError的子类)
UnicodeError Unicode相关的错误(ValueError的子类)
UnicodeEncodeError Unicode编码时的错误(UnicodeError的子类)
UnicodeDecodeError Unicode解码时的错误(UnicodeError的子类)
UnicodeTranslateError Unicode转换时的错误(UnicodeError的子类)
ValueError 传入无效的参数
ZeroDivisionError 除数为零

2.2 异常的处理
不能保证程序永远正常运行,但是必须保证程序在最坏的情况下得到的问题被妥善处理。
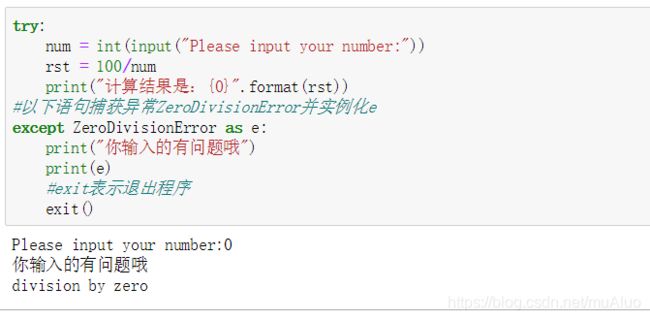
python的异常处理模块全部语法为:
try:
尝试实现某个操作,
若无异常,任务可以完成,
若有异常,将异常从当前代码块扔出去尝试解决异常(一旦出错,从出错的地方直接进入except)
#越具体的错误越往前放,当不清楚是哪一类异常时,可以直接使用BaseException
#越是父亲类的异常越往后放
except 异常类型:
解决方案1:用于尝试在此处处理异常解决问题
except 异常类型2::
...
except (异常类型1, 异常类型2...)
...
else:
如果没有出现任何异常,将会执行此代码
finally:
有无异常都要执行除了except(至少一个)以外,else和finally都是可选的。
案例

2.3 用户手动引发异常
在某些情况下,用户希望自己引发一个异常,可以使用raise关键字来引发异常。
raise error_name案例1

案例2(自己定义异常)

2.4 关于自定义异常
只要是raise异常,则推荐自定义异常。
在自定义异常的时候,一般包含以下内容:
- 自定义异常发生时的异常代码
- 自定义异常发生后的问题提示
- 异常发生的行数
最终目的是,一旦发生异常,方便程序员快速定位错误现场。
3 常用模块
- calendar
- time
- datetime
- timeit
- os
- shutil
- zip
- math
- string
- 上述所有模块使用前理论上都应该先导入,string是特例
3.1 calendar
日历相关模块。
获取一年的日历
参数:
- w = 每个日期之间的间隔字符数
- l = 每周所占的行数
- c = 每个月之间的间隔字符数

判断是否是闰年

获取指定年份之间的闰年个数

3.2 time
3.2.1 时间戳
时间戳,一个时间表示方法,根据不同语言,可以是整数或浮点数,是从1970年1月1日0时0分0秒到现在经历的秒数。
32位系统能够支持到2038年。
3.2.2 UTC时间
UTC时间又称为世界协调时间,以英国格林尼治天文所在地区时间作为参考时间,也叫作世界标准时间。
中国时间是UTC+8 东八区
3.2.3 夏令时
夏令时就是在夏天的时候将时间调快一小时,本意是督促大家早睡早起省蜡烛,每天变成25个小时。
3.2.4 时间元组
一个包含时间内容的普通元组。
3.2.5 时间模块的属性
- timezone:当前时间和UTC时间相差的秒数

- altzone:获取当前时区与UTC相差的秒数,在有夏令时的情况下
- daylight:判断当前是否是夏令时时间状态,0表示是
- localtime():得到当前时间的时间结构(元组)

- asctime():返回元组的正常字符串化之后的时间格式
- ctime():获取字符串化的当前时间
- clock():获取cpu时间,3.0~3.3版本可以直接使用
- sleep():使程序进入睡眠,n秒后继续
3.3 datetime
提供日期和时间的运算和表示。
datetime常见属性:
- data,一个理想和的日期,提供year、month、day属性

- time:提供一个理想和的时间,提供hour、minute、sec、microsec属性
- datetime:提供日期和时间的组合
- timedelta:提供一个时间差,时间长度(常用)
- timeit:时间测量工具
3.4 datetime.datetime模块
from datetime import datetime
3.5 OS - 操作系统相关
跟操作系统相关,主要是文件操作。
与系统相关的操作,主要包含在三个模块里:
- os,操作系统目录相关
- os.path,系统路径相关操作
- shutil,高级文件操作,目录树的操作,文件赋值、删除、移动
绝对路径:总是从根目录上开始;
相对路径:基本以当前环境为开始的一个相对的地方。
3.5.1 os模块
- os.getcwd(),获取当前的工作目录,返回值为当前工作目录(程序在进行文件相关操作时默认查找文件的目录)的字符串

- os.chdir(路径)改变当前的工作目录,无返回值

- os.listdir(路径) 获取一个目录中所有子目录和文件的名称列表,返回值为所有子目录和文件的名称的列表
- makedirs(递归路径) 递归创建文件夹,如果不给出创建路径,则默认在当前目录下。多个文件夹层层包含的路径就是递归路径,例如/a/b/c/...

- os.system(系统命令) 运行系统shell命令,返回值为打开一个shell或者终端界面,ls是列出当前文件和文件夹的系统命令。
ls是列出当前文件和文件夹的系统命令。
- os.getenv(环境变量名) 获取指定的系统环境变量值,返回值为指定环境变量名对应的值。相应的还有putenv。

- exit() 退出当前程序,无返回值
3.5.2 值部分
- os.curdir:current dir,当前目录
- os.pardir:parent dir,父亲目录
- os.sep:当前系统的路径分隔符
- os.linesep:当前系统的换行符号
- os.name:当前系统名称

3.5.3 os.path模块,与路径相关的模块
- os.path.abspath(路径) 将路径转化为绝对路径

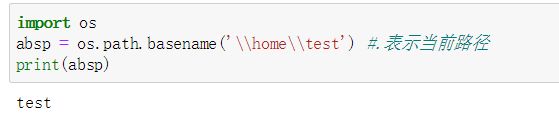
- os.path.basename(路径) 获取路径中的文件名部分,返回文件名字符串
- os.path.join(路径1,路径2,...) 将多个路径拼合到一个路径,返回拼合后的路径。
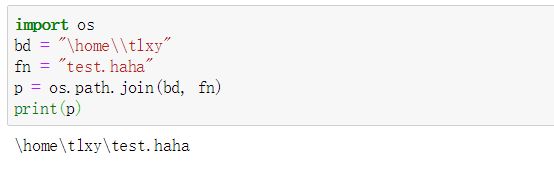
- os.path.split(路径),将路径切割为文件夹部分和当前文件部分,返回值为元组
- os.path.isdir(路径) 判断是否为文件夹,返回布尔值
- os.path.exits(路径) 判断文件或目录是否存在
3.5.4 shutil模块
- shutil.copy(来源路径, 目的路径) 复制文件,返回目标路径,可以给文件重命名。
- shutil.copy2(来源路径, 目的路径) 复制文件,保留元数据(文件信息)
- shutil.copyfile(来源路径, 目的路径) 将一个文件中的内容复制到另外一个文件当中,无返回值
- shutil.move(来源路径, 目的路径) 移动文件/文件夹,返回值为目标路径
归档和压缩
归档:把多个文件或文件夹合并到一个文件中
压缩:用算法把多个文件或文件夹无损或有损合并到一个文件中
- shutil.make_archive(归档后的目录和文件名,后缀,需要归档的文件夹) 归档操作,返回归档后的地址

- shutil.unpack_archive(归档地址,解包地址) 解包,返回解包后的地址
3.6 random
随机数,所有的随机模块都是伪随机。
- random.random()

- random.choice(序列) 随机返回序列中的某个值

- random.shuffle(列表) 随机打乱列表,打乱原列表

- random.randint((a,b))生成一个a到b之间的随机整数,包含a和b

4 Log
参考博客https://www.cnblogs.com/yyds/p/6901864.html
使用logging提供的模块级别的函数记录日志
案例:

在当前路径下会自动生成testLog.log文件:

logging日志模块四大组件记录日志
案例
需求:
1)要求将所有级别的所有日志都写入磁盘文件中
2)all.log文件中记录所有的日志信息,日志格式为:日期和时间 - 日志级别 - 日志信息
3)error.log文件中单独记录error及以上级别的日志信息,日志格式为:日期和时间 - 日志级别 - 文件名[:行号] - 日志信息
4)要求all.log在每天凌晨进行日志切割

在当前路径下生成all.log和error.log。
all.log:

error.log:

5 函数式编程(FunctionalProgramming)
Python语言的高级特性。
函数式编程是基于Lambda演算的一种编程方式
- 程序中只有函数
- 函数可以作为参数,也可以作为返回值
- 纯函数式编程语言:LISP,Haskell
Python函数式编程知识借鉴函数式编程的一些特点,可以理解为一半函数式一半Python。
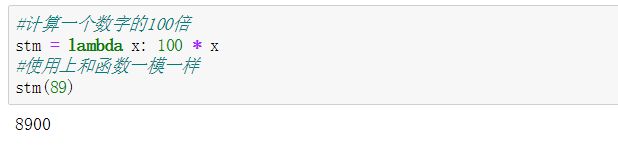
5.1 lambda表达式
函数存在的最大意义就是最大程度复用函数,但存在的一定的问题:如果函数很小、很短,则会很啰嗦,此时如果函数调用的次数少,则会造成浪费,对于阅读者来说,造成阅读流程的被迫中断。
lambda表达式(匿名函数):
- 一个表达式,函数体相对简单
- 不是一个代码块,仅仅是一个表达式
- 可以有一个多个参数,多参数用逗号隔开
lambda表达式用法:
- 以lambda开头
- 紧跟一定的参数(若有)
- 参数后用冒号和表达式主题隔开
- 只是一个表达式,所以没有return

5.2 高阶函数
高阶函数:把函数作为参数使用的函数。
函数名称就是一个变量。

以上代码得出结论:函数名称是变量;funB和funA只是名称不同;既然函数名称是变量,那么就可以被当做参数传入另一个函数。
案例

以上高阶函数非常灵活,当不是放大300倍时,只需要修改传入的参数即可,不需要改动funB函数。
5.3 系统高阶函数
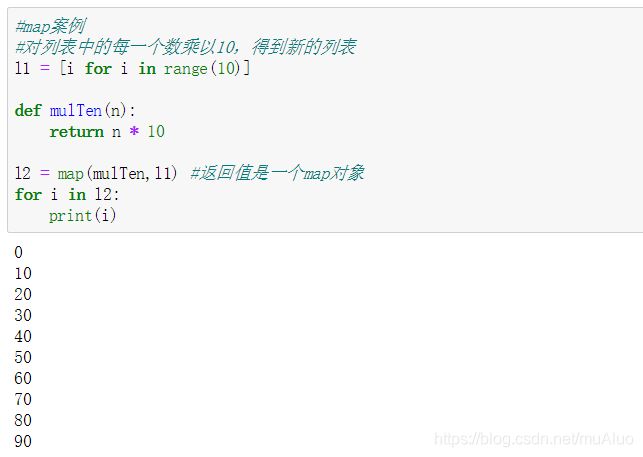
5.3.1 map
原意为映射,即将集合或列表中的每一个元素按照一定规则进行操作,生成一个新的列表或集合。
map函数是系统提供的具有映射功能的函数,返回值是一个迭代对象。
案例
5.3.2 reduce
原意是归并,缩减,把一个可迭代对象最后归并为一个结果。
reduce必须导入functools包。
对于作为其参数的函数有以下要求:
- 必须有两个参数
- 必须有返回结果
案例

5.3.3 filter
过滤函数:对一组数据进行过滤,符合条件的数据会生成一个新的列表并返回。
与map比较:
- 相同点:都对列表中的每一个元素进行操作
- 不同点:map会生成与原元素相对应的新元素,而filter不一定,只有符合条件的才会进行新的数据集合。
filter函数怎么写:
- 利用给定函数进行判断
- 返回值一定是布尔值
- 调用格式:filter(f, data),f是过滤函数(要求有输入),data是原始数据
案例

5.3.4 高阶函数-排序
把一个序列按照给定算法进行排序。
key:在排序前对每一个元素进行key函数运算,可以理解为按照key函数定义的逻辑进行排序。
python2和python3相差巨大。

5.4 返回函数
函数名可以作为具体的返回值。
案例


【拓展】
闭包(closure)
当一个函数在内部定义函数,并且内部函数应用外部函数的参数或局部变量,且当函数被作为返回值时,相关参数和变量保存在返回的函数中,这种结果叫做闭包。
以上案例中的myF是一个标准的闭包结构。
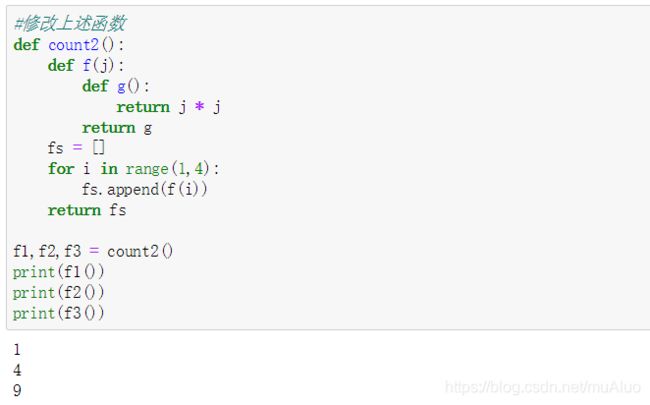
闭包常见坑案例

造成上述问题的原因:返回函数引用了变量i,i并非立即执行,而是等到三个函数都返回的时候才统一使用,此时i已经变成了3,最终调用的时候,都返回3*3。
此问题描述成:返回闭包时,返回函数不能引用任何循环变量。
解决方案:再创建一个函数,用该函数的参数绑定循环变量的当前值,无论该循环变量以后如何改变,已经绑定的函数参数值不再改变。解决如下:
5.4 装饰器(Decrator)
在不改动函数代码的基础上无限制扩展函数功能的一种机制,装饰器是一个返回函数的高阶函数。
装饰器的好处:一经定义,则可以装饰任意函数;一旦被装饰,则把装饰器的功能直接添加到定义函数的功能上。
5.4.1 使用系统定义的语法糖执行装饰器
使用@语法(此符号是python的语法糖),即在每次要扩展到函数定义前使用@+函数名。

5.4.2 手动执行装饰器

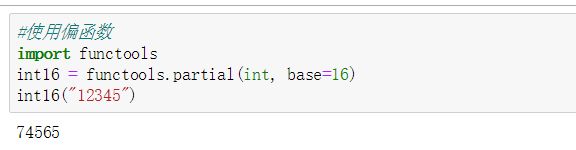
5.5 偏函数
参数固定的函数,相当于一个有特定参数的函数体。
functools.partial的作用是将一个函数的某些参数固定,返回一个新函数。

5.5 高级函数补充
5.5.1 zip
把两个可迭代内容生成一个可迭代的tuple元素类型组成的内容。
案例

5.5.2 enumerate
和zip的功能比较像。对可迭代对象中的每一个元素配上一个索引,索引和内容构成tuple元素。
案例


5.5.3 collections
常用:
- namedtuple
- dequeue
- defaultdict
- Counter
namedtuple
tuple类型,是一个可命名的tuple。

deque
比较方便地解决了频繁插入删除带来的效率问题。
案例

defaultdict
当直接读取dict不存在的属性时,直接返回默认值。
案例

Counter
统计字符串个数。
案例


6 文件
长久保存信息的一种数据信息集合。
常用操作:
- 打开关闭(文件一旦打开,需要关闭操作)
- 读写内容
- 查找
6.1 open函数
open函数负责打开文件,带有很多参数。
- 第一个参数:必须有,文件的路径和名称
- mode:表明文件用什么方式打开:
r:以只读方式打开;
w:以写方式打开,会覆盖以前的内容(文件若不存在会自动创建);
x:以创建方式打开,如文件已经存在,则报错;
a:append方式,以追加的方式对文件内容进行写入;
b:binary方式,二进制方式写入;
t:以文本方式打开;
+:可读写。
案例

6.2 with语句
with语句使用的技术是一种上下文管理协议技术(ContextManagementProtocal),其会自动判断文件的作用域,自动关闭不再使用的打开的文件句柄。
对文件的操作一般都要求使用with语句。
案例

6.3 读取文件
6.3.1 读操作
案例1:按行读取

案例2:全部读取:

案例3:read按字符读取



以上最后一个案例为什么看上去不是每行打印三个字符呢?
原因如下:
我们手动输入的回车换行符在编译时会被替换为\n,即我将如何和你招呼\n以眼泪\n以沉默,而python中的print函数默认每次打印以换行结尾,故每次读取三个字符打印出来的结果为:
我将如
何和你
招呼\n
以眼泪
\n以沉
默
将\n转义一下,就会得到以上截图中的结果了。
6.3.2 seek(offset,from)
移动文件的读取位置,也叫读取指针。
from的取值范围:
- 0,从文件头开始移动
- 1:从文件当前位置开始偏移
- 2:从文件尾部开始偏移
移动的单位是字节(byte),注意一个汉字不是一个字节(若干字节)。
返回文件只针对当前位置。
案例

6.3.3 tell函数
用来显示文件读写指针当前的位置(以字节byte为单位)。
案例

6.4 写操作
- write(str):把字符串写入文件
- writelines(str):把字符串或字符序列写入文件(可以是list)
案例


7 持久化 - pickle
序列化(持久化,落地):把程序运行中的信息保存在磁盘上。
反序列化:序列化的逆过程。
pickle:python提供的序列化模块。
pickle.dump:序列化。
pickle.load:反序列化。
案例1


案例2(结构化数据)

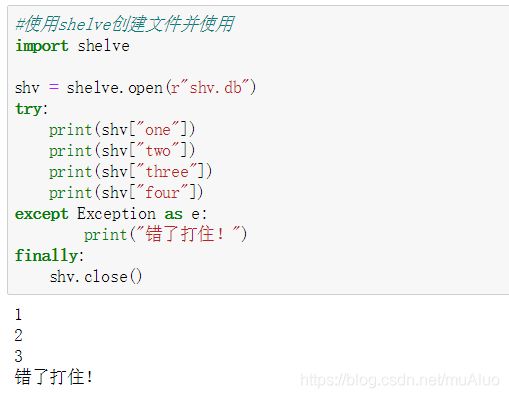
8 持久化 - shelve
持久化工具,类似字典,用k-v保存数据,存取方式与字典相似。
打开open,关闭close。
shelve特性:
- 不支持多个应用并行写入。为了解决这个问题,open的时候可以使用flag = r
- 写回问题:shelve某种情况下不会等待持久化对象进行任何修改。解决方法是强制写回,writeback=True。
9 多线程
9.1 多线程 vs 多进程
程序:一堆代码以文本形式存入一个文档
进程:程序运行的一个状态,包含地址空间、内存、数据栈等。每个进程有自己完全独立的运行环境,多进程共享数据是一个问题。
线程:一个进程的独立运行片段,一个进程可以有多个线程。可理解为轻量化的进程。一个进程的多个线程共享数据和上下文运行环境。
全局解释器锁(GIL):
Python代码的执行是由Python虚拟机进行控制的,在主循环中只能有一个控制线程执行。
Python包:
- thread:有问题,不好用,python3改为了_thread
- threading:通行的包
9.2 _thread使用
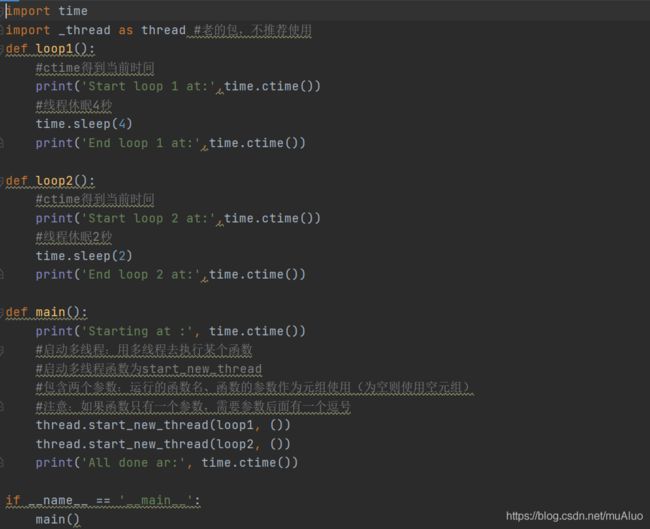
案例:多线程-减少程序执行时间
未使用多线程,按顺序执行共执行约6秒(print的时间相对于sleep的时间可以忽略不计):

 使用多线程(使用包_thread):
使用多线程(使用包_thread):
主线程分配完任务,不等待loop1、loop2子线程执行完就直接报告完成任务:
 主线程等待loop1和loop2执行完:
主线程等待loop1和loop2执行完: 

多线程,传参数:


9.3 threading使用
直接利用threading.Thread生成Thread实例。
- t = threading.Thread(target=函数名, args=(参数1, ))
- t.start():启动多线程
- t.join():等待子线程执行完成
案例

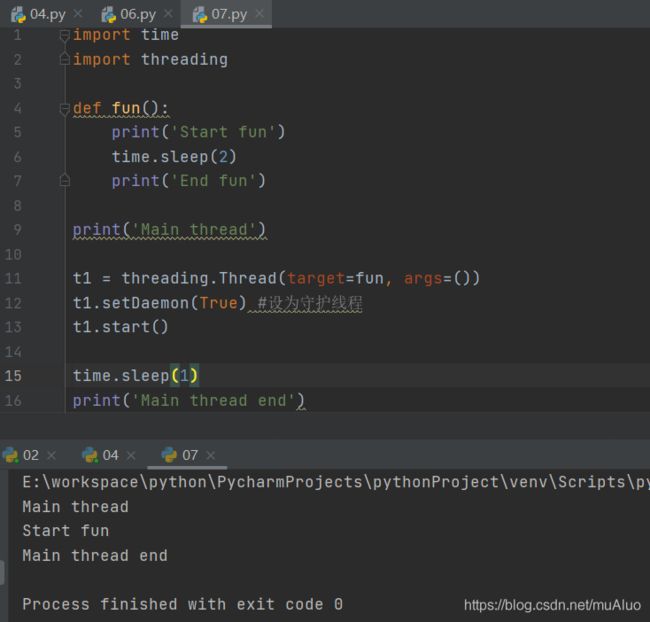
- 守护线程daemon:如果在程序中将线程设置为守护线程,则子线程会在主线程结束时自动退出。一般认为,守护线程不重要或不允许离开主线程独立运行。守护线程能否有效和环境有关。
守护线程案例
非守护线程(主线程结束,子线程依然执行):

守护线程(子线程和主线程一起死亡):
9.4 线程常用属性(threading)
- threading.currentThread:返回当前线程变量
- threading.enumerate:返回一个包含正在运行的线程的list,正在运行的线程指的是线程启动后、结束前
- threading.activeCount:返回正在运行的线程数量,效果跟len(threading.enumerate)相同
- thr.setName:给线程设置名字
- thr.getName:获得线程的名字
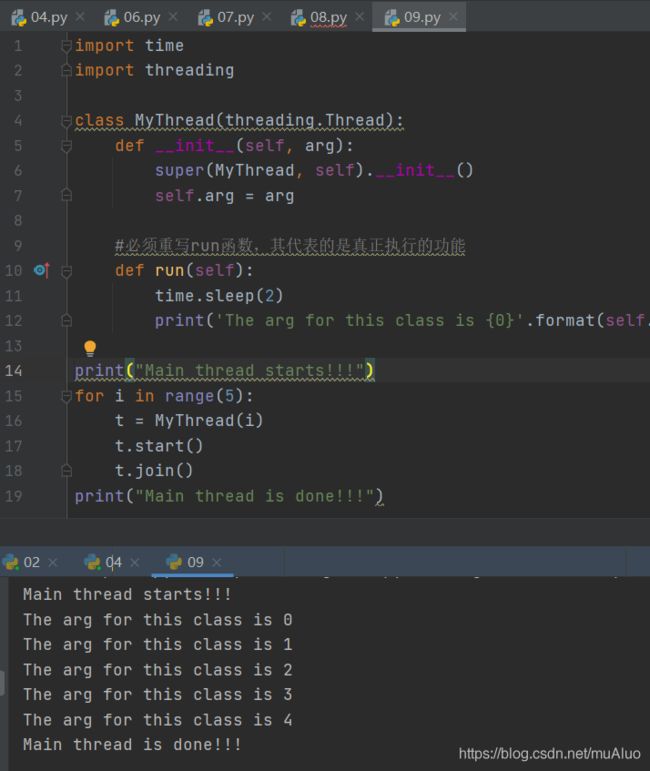
9.5 继承threading.Thread
- 直接继承threading.Thread
- 重写run函数
- 类实例可以直接运行
案例
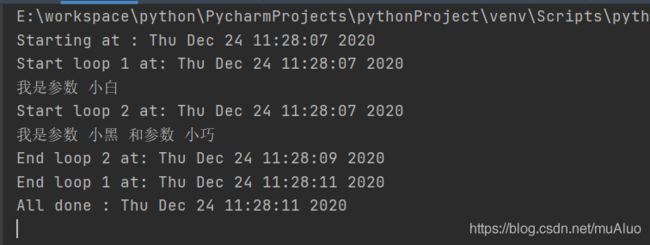
企业中常用的写法(实用):
import threading
import time
loop = [4,2]
class ThreadFunc:
def __init__(self, name):
self.name = name
def loop(self, nloop, nsec):
'''
:param nloop: loop函数的名称
:param nsec: 系统休眠时间
:return:
'''
print("Start loop ", nloop, 'at ', time.ctime())
time.sleep(nsec)
print("Done loop ", nloop, 'at ', time.ctime())
def main():
print("Starting at ", time.ctime())
t = ThreadFunc("loop")
t1 = threading.Thread(target=t.loop, args=("LOOP1", 4))
t2 = threading.Thread(target=ThreadFunc('loop').loop, args=("LOOP2", 2))
t1.start()
t2.start()
t1.join()
t2.join()
print("All done at", time.ctime())
if __name__ == '__main__':
main()
while True:
time.sleep(10)
9.6 共享变量
共享变量:当多个线程同时访问一个变量时,会产生共享变量问题。
解决变量:锁、信号灯。
锁(Lock):
是一个标志,标志一个线程在占用一些资源。
使用方法:
- 上锁
- 放心使用共享资源
- 取消锁/释放锁
注意事项:
- 锁谁:哪个资源需要多个线程共享,就锁哪个
- 理解锁:锁其实不是锁住谁,而是一个令牌
import threading
sum = 0
loopsum = 1000000
lock = threading.Lock()
def myAdd():
global sum, loopsum
for i in range(1,loopsum):
#上锁、申请锁
lock.acquire()
sum += 1
#释放锁
lock.release()
def myMinu():
global sum, loopsum
for i in range(1,loopsum):
#上锁、申请锁
lock.acquire()
sum -= 1
#释放锁
lock.release()
if __name__ == '__main__':
print("Starting....{}".format(sum))
t1 = threading.Thread(target=myAdd, args=())
t2 = threading.Thread(target=myMinu(), args=())
t1.start()
t2.start()
t1.join()
t2.join()
print("Done....{}".format(sum))
线程安全问题:
如果一个资源/变量,它对于多线程来讲,不用加锁也不会引起任何问题,则成为线程安全。
线程不安全变量类型:
- list,set,dict
线程安全变量类型:
- queue
生产者消费者问题(多线程同步问题经典案例):
一个模型。可以用来搭建消息队列。解耦生产者和消费者。
queue是一个用来存放变量的数据结构,特点是先进先出,内部元素排队,可以理解为一个特殊的List。
import queue
import time
import threading
#模拟生产者
class Producer(threading.Thread):
def run(self):
global queue
count = 0
while True:
if queue.qsize() < 1000:
for i in range(100):
count += 1
msg = '生成产品' + str(count)
queue.put(msg)
print(msg)
time.sleep(0.5)
#模拟消费者
class Customer(threading.Thread):
def run(self):
global queue
while True:
if queue.qsize() > 100:
for i in range(3):
msg = self.name + "消费了" + queue.get()
print(msg)
time.sleep(1)
if __name__ == '__main__':
queue = queue.Queue()
for i in range(500):
queue.put('初始产品'+str(i))
for i in range(2):
p = Producer()
p.start()
for i in range(5):
c = Customer()
c.start()
死锁问题:
申请和释放的顺序应该是相反的。
产生死锁:
import threading
import time
lock_1 = threading.Lock()
lock_2 = threading.Lock()
def func_1():
print("func_1 Starting......")
lock_1.acquire()
print("func_1 申请了lock_1......")
time.sleep(2)
print("func_1 等待lock_2......")
lock_2.acquire()
print("func_1申请了lock_2......")
lock_2.release()
print("func_1释放了lock_2......")
lock_1.relase()
print("func_1释放了lock_1......")
print("func_1 Done......")
def func_2():
print("func_2 Starting......")
lock_2.acquire()
print("func_2 申请了lock_2......")
time.sleep(4)
print("func_2 等待lock_1......")
lock_1.acquire()
print("func_2申请了lock_1......")
lock_1.release()
print("func_2释放了lock_1......")
lock_2.relase()
print("func_2释放了lock_2......")
print("func_2 Done......")
if __name__ == '__main__':
print("主程序启动......")
t1 = threading.Thread(target=func_1, args=())
t2 = threading.Thread(target=func_2, args=())
t1.start()
t2.start()
t1.join()
t2.join()
print("主程序结束......")
锁的等待时间问题:
func_1申请不到资源后会释放本身持有的资源(解决死锁的一种方法)。
import threading
import time
lock_1 = threading.Lock()
lock_2 = threading.Lock()
def func_1():
print("func_1 Starting......")
lock_1.acquire(timeout=4)#超过4秒就不等了
print("func_1 申请了lock_1......")
time.sleep(2)
print("func_1 等待lock_2......")
rst = lock_2.acquire(timeout=2)
if rst:
print("func_1得到了lock_2......")
lock_2.release()
print("func_1释放了lock_2......")
else:
print("func_1注定申请不到lock_2......")
lock_1.release()
print("func_1释放了lock_1......")
print("func_1 Done......")
def func_2():
print("func_2 Starting......")
lock_2.acquire()
print("func_2 申请了lock_2......")
time.sleep(4)
print("func_2 等待lock_1......")
lock_1.acquire()
print("func_2申请了lock_1......")
lock_1.release()
print("func_2释放了lock_1......")
lock_2.release()
print("func_2释放了lock_2......")
print("func_2 Done......")
if __name__ == '__main__':
print("主程序启动......")
t1 = threading.Thread(target=func_1, args=())
t2 = threading.Thread(target=func_2, args=())
t1.start()
t2.start()
t1.join()
t2.join()
print("主程序结束......")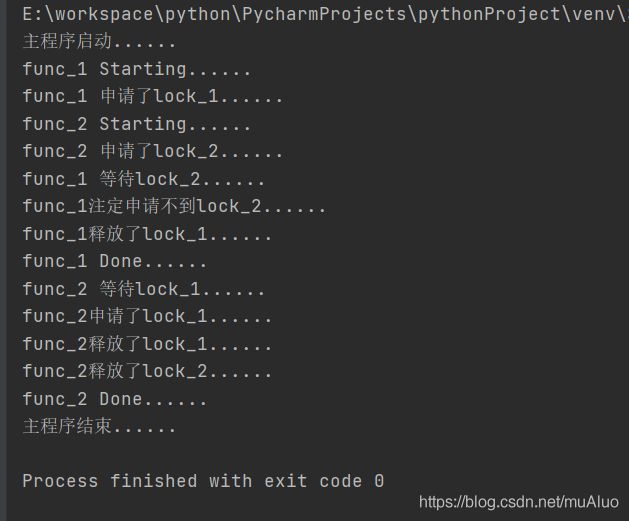
semaphore:
允许一个资源做多由几个线程同时使用。
import threading
import time
#允许最多三个线程同时使用
semaphore = threading.Semaphore(3)
def func():
if semaphore.acquire():
for i in range(5):
print(threading.currentThread().getName() + ' get semaphore')
time.sleep(15)
semaphore.release()
print(threading.currentThread().getName() + ' release semaphore')
for i in range(8):
t = threading.Thread(target=func)
t.start()
threading.Timer:
在指定的秒数后执行指定的函数。Timer利用多线程,在指定时间后启动一个功能。
可重入锁:
一个锁可以被一个线程多次申请。主要解决递归调用的时候需要申请锁的情况(以下案例中如果不使用可重入锁,将会产生死锁)。
import threading
import time
class MyThread(threading.Thread):
def run(self):
global number
time.sleep(1)
if mutex.acquire(1):
number += 1
msg = self.name + 'set number to ' + str(number)
print(msg)
mutex.acquire()
mutex.release()
mutex.release()
number = 0
mutex = threading.RLock() #可重入锁
def testRL():
for i in range(4):
t = MyThread()
t.start()
if __name__ == "__main__":
testRL()
9.7 线程替代方案
subprocess
- 完全跳过线程,使用进程
- 是派生进程的主要替代方案
- python2.4后引入
multiprocessing
- 使用threading借口派生,使用子进程
- 允许多核或多cpu派生进程,接口和threading非常相似
- python2.6后引入
concurrent.futures
- 新的异步执行模块
- 任务级别的操作
- python3.2后引入
9.7.1 多进程
进程间的通讯(InterprocessCommunication,IPC)
进程之间无任何共享状态。
进程的创建:
- 直接生成Process对象

- 派生子类创建进程


在os中查看pid、ppid以及它们的关系:

生产者消费者模型:
- 使用JoinableQueue
import multiprocessing
from time import ctime
def customer(input_q):
print("Into customer:", ctime())
while True:
item = input_q.get()
print("pull", item, "out of q")
input_q.task_done() #发出信号通知任务完成
print("Out of consumer:", ctime())
def producer(sequence, output_q):
print("Into producer:", ctime())
for item in sequence:
output_q.put(item)
print("put", item, "into q")
print("Out of producer:", ctime())
if __name__ == "__main__":
q = multiprocessing.JoinableQueue()
cons_p = multiprocessing.Process(target=customer, args=(q, ))
cons_p.daemon = True
cons_p.start()
sequence = [1, 2, 3, 4]
producer(sequence, q)
q.join()
- 队列中哨兵的使用(生产者不生产了,消费者不会一直等待,通过哨兵通知)
import multiprocessing
from time import ctime
def customer(input_q):
print("Into customer:", ctime())
while True:
item = input_q.get()
if item is None:
break
print("pull", item, "out of q")
print("Out of consumer:", ctime())
def producer(sequence, output_q):
print("Into producer:", ctime())
for item in sequence:
output_q.put(item)
print("put", item, "into q")
print("Out of producer:", ctime())
if __name__ == "__main__":
q = multiprocessing.Queue()
cons_p = multiprocessing.Process(target=customer, args=(q, ))
cons_p.start()
sequence = [1, 2, 3, 4]
producer(sequence, q)
q.put(None)
cons_p.join()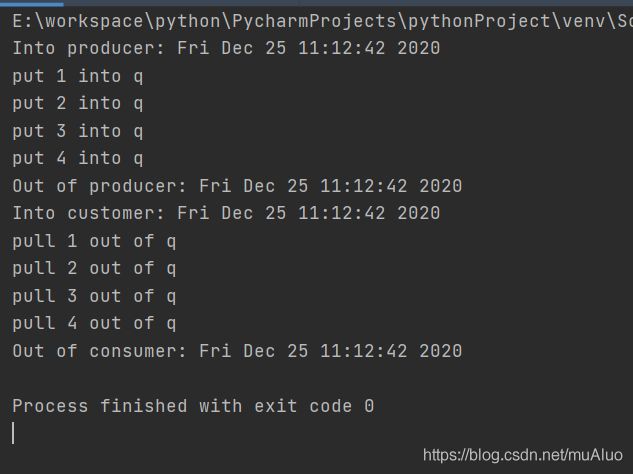
- 哨兵的改进(有几个消费者就需要几个哨兵)
import multiprocessing
from time import ctime
def customer(input_q):
print("Into customer:", ctime())
while True:
item = input_q.get()
if item is None:
break
print("pull", item, "out of q")
print("Out of consumer:", ctime())
def producer(sequence, output_q):
print("Into producer:", ctime())
for item in sequence:
output_q.put(item)
print("put", item, "into q")
print("Out of producer:", ctime())
if __name__ == "__main__":
q = multiprocessing.Queue()
cons_p1 = multiprocessing.Process(target=customer, args=(q, ))
cons_p1.start()
cons_p2 = multiprocessing.Process(target=customer, args=(q,))
cons_p2.start()
sequence = [1, 2, 3, 4]
producer(sequence, q)
q.put(None)
q.put(None)
cons_p1.join()
cons_p2.join()