初识 Python - 简要认识、语法规范及数据类型
目录
1、简单认识
2、pip模块管理器(在线安装模块)
3、Python 开发工具
4、Python常用库
5、Python 编程模式
6、字符串与编码规范
7、标识符和保留字
8、语法格式规范
1)、行和缩进
2)、多行语句
3)、引号
4)、空行
9、注释及其他
1)、Python注释
2)、标准输入 input()
3)、标准输出 print( )输出
4)、命令行参数
10、基本数据类型
1)、变量
2)、基本数据类型介绍
3)、标准数据类型
(1)、数字类型
(2)、字符串类型及用法(★)
Python 是一种面向对象的解释型计算机程序设计语言 。具有以下特点:1)、简单易学:适合没有任何编程语言基础的人稍微看一下资料,就可以写出功能强大的程序。2)、开发效率高:很难像Java那样开发出完整的大型综合性网站或平台,但其起到画龙点睛的作用。同时也是一门典型的“胶水语言”,整合其他各种编程语言。3)、典型的工具语言:它是一门解释型编程语言,编译完毕后可直接运行,发现Bug后立即修改,剩下大量的编译时间。4)、强大丰富的模块库:高度代码重用性,编写各种工具模块引用的系统工程中,丰富的模块强大到恐怖的地步,几乎无处不在适用于各种领域。5)、优秀的跨平台:几乎所有的Python程序,都可以不加修改地运行在不同的操作系统平台。
没有安装的见微信公众号:软件安装管家。
1、简单认识
在安装好我们所需要的 Python 配置后,我们可以验证下当前的环境是否已经配置好:1)、打开 Windows下的命令行工具(win+R快捷键启动运行,然后输入 cmd 启动命令行工具),2)、使用 python 指令查看当前系统 python 的环境版本
python -V
命令参数 -V 为大写字母。若能正确显示当前 Python 版本号,则表示安装正确,否则报错 “Python” 不是内部或外部命令...
或者我们可以进入其编译环境下来验证,如图:
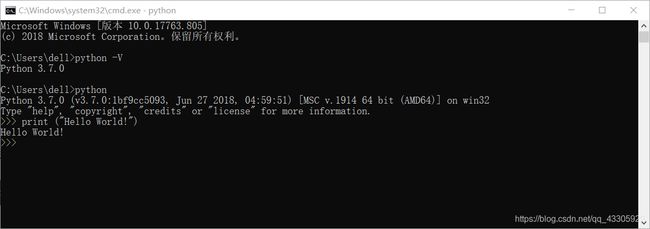
在 DOS 提示符下输入 python ,则进入到编译环境,>>> 三箭头表示 Python 提示符,可以输入指令或语句,exit() 函数可退出 python 编译环境。
Python 语言是典型的脚本语言,通过解析器直接运行*.py文件。所有Python脚本程序的后缀名都是以 *.py 结尾。pyc是一种二进制文件,是由py文件经过解释器编译后,在磁盘上生成的文件形式,是一种byte code,py文件变成pyc文件后,加载的速度有所提高,而且pyc是一种跨平台的字节码,是由python的解析器来执行的。pyc的内容是跟python的版本相关的,不同版本编译后的pyc文件是不同的。之所以需要 pyc 文件,是因为 py文件是可以直接看到源码的,如果你是开发商业软件的话,不可能把源码也泄漏出去。所以就需要编译为pyc后,再发布出去;pyo 是优化编译后的程序 ,python -O –m 源文件 即可将源程序编译为pyo文件(需要注意::从Python3开始没有pyo为后缀名的文件,取而代之是生成对应的pyc文件);· pyd 是 python 的动态链接库文件 。
py是源文件,pyc是源文件编译后的字节码文件,pyo是源文件优化编译后的字节码文件,pyd是其他语言写的Python库。Python并非完全是解释性语言,它是有编译的,先把源码 py 文件编译成pyc或者pyo,然后由python的虚拟机执行,相对于py文件来说,编译成pyc和pyo本质上和py没有太大区别,只是对于这个模块的加载速度提高了,并没有提高代码的执行速度。官方文档上说脚本代码中只要使用引用模块 import 模块库 ,那么 模块库.py 就会先编译成 pyc 然后加载运行。
2、pip模块管理器(在线安装模块)
由于Python有几乎无限的第三方模块库,那我们如何 安装 和 管理 这些第三方模块呢?这里我们必须提到 easy_install 和 pip,老版本中的Python只有 easy_install ,pip 是easy_install的高级版本,所以 pip 和 easy_install 任选一个都可以,我们目前所常使用的 Python3 这系列版本,一般在安装的时候默认选择了 pip 。
pip -V
//验证版本号
pip -h
//查看 pip 帮助pip默认与Python会同时安装到当前系统环境中,其主要的功能就是管理当前系统中的所有Python外部模块库。其常用管理指令介绍:pip list:查看当前模块库中已经安装的所有外部模块指令;pip install 模块名称:在线安装外部模块指令(同时会自动下载安装与其相关依赖的模块库);pip uninstall 模块名称:从模块库中删除指定的模块指令;pip install --upgrade 模块名称:升级指定的模块到最新的版本。
pip 安装配置:setuptools 和 wheel 两个组件都是Python安装第三方模块库的依赖工具组件,但wheel模块需手动安装,建议安装Python的外部管理模块 wheel,指令:pip install -U wheel 。
pip3 install numpy
//安装 numpy 库3、Python 开发工具
IDEL 是Python软件包自带的集成开发环境,可以方便的创建、运行和调试python程序。启动IDLE后先看到的是Python shell,可以通过它在IDLE内部执行python命令IDLE还带有一个编辑器,用来编辑python程序(或脚本);有一个交互式解释器用来解释执行Python语句;有一个调试器来调试Python脚本。
VSCode是微软官方推出的强大的语言编译器,被Python开发者广泛使用。强大的插件机制,可将其变身为各种语言的编译器;灵活易用,提示友好;Python开发者首选IDE。
Sublime Text3 是一个代码编辑器,具有漂亮的用户界面和强大的功能。强大的插件机制,可将其变身为各种语言的编译器;Anaconda 插件篇快速配置Python开发环境;运行效率高,被Python开发者誉为 “Python利器”。
PyCharm是一种Python IDE,带有一整套可以帮助用户在使用Python语言开发时提高其效率的工具。比如调试、语法高亮、Project管理、代码跳转、智能提示、自动完成、单元测试、版本控制。此外,该IDE提供了一些高级功能,以用于支持Django框架下的专业Web开发。
PyDev 是Eclipse for Python的一个重要插件,可以将Eclispe完全打造成专业的Python IDE。PyDev 插件的出现方便了众多的 Python 开发人员,它提供了一些很好的功能,如:语法错误提示、源代码编辑助手、Quick Outline、Globals Browser、Hierarchy View、运行和调试等等。基于 Eclipse 平台,拥有诸多强大的功能,同时也非常易于使用,PyDev 的这些特性使得它越来越受到人们的关注。
4、Python常用库
原本这块是我在使用的时候用到的一些库,想着这应该就差不多算是常用的了,就想整理一下,在写之前突然想了想还是上网查查吧,结果一查有好多没怎么用的库,然后就索性不整理了,直接放个传送门好了(见谅)。
分类较明确的24个库 、 有点太...太全面的列举库 。
5、Python 编程模式
Python语言是一个典型的脚本语言,因此它的编程模式(方式)很灵活。常见的有两种:交互式命令编程模式、脚本编程模式。
Python脚本文件是一种典型的解释型语言,因此其执行的方式为逐行读取逐行执行;而交互式命令编程模式就是一种典型逐行读取执行模式,当程序只有一行或较少的时候,这种编程模式是比较典型的应用方式。使用Python IDLE编辑器进行编程,而该编辑器的编程模式就是典型的交互式命令编程模式,其特点是:符号>>>就是输入交互命令的提示符,每次输入完毕后回车,该命令就被Python解析器执行。
而当我们需要编写较为复杂或大段的代码的时候(特别是在使用函数编程或面向对象编程时),交互式编程这样的命令就显得很不舒服。因此,Python提供了脚本编程模式:可以创建一个后缀名为 *.py 的脚本文件,将大量的代码编写到该文件中,这样便于代码的维护和更新,之后再使用交互命令执行或IDE工具运行即可。
6、字符串与编码规范
字符串是一种数据类型,但是,字符串还有一个比较特殊的编码问题。因为计算机中只能处理数字,如果要处理文本,就必须先把文本转换为数字才能处理。最早的计算机在设计时采用8个比特作为一个字节,所以一个字节能表示的最大的整数就是255,如果想要表示更大的整数,就必须用更多的字节,在早期只有127个字符被编码到计算机里,也就是大小写英文字母;、数字和一些符号,这个编码表被称为 ASCII 编码。
Python3之所以能够很好地解决中文乱码问题,在于其将所有的字符串都是用 Unicode 进行字符编码,Unicode 把所有的语言统一到一套编码里,这样也就不会有乱码了。虽然 Unicode 在不断的发展,但最常用的是用两个字节表示一个字符(r如果遇到非常生僻的字符,就需要4个字节)现在我们见到的大多数操作系统和大多数编程语言都支持 Unicode ,ASCII 编码是一个字节,而 Unicode 编码则是两个字节。虽然 Unicode 能很好地解决乱码问题,但如果写的文本基本上全都是英文的话,用 Unicode 编码比 ASCII 编码需要多一倍的存储空间,在存储和传输上就十分不划算,所以出现了把 Unicode 编码转化为 “k可变长编码” 的 UTF-8 编码。UTF-8 编码把一个 Unicode 字符根据不同数字大小编码成 1-6个字节,常用的英文字母被编码成 1 个字节,汉字通常是 3 个字节,只有很生僻的字符才会被编码成 4-6 个字节;如果传输的文本包含大量英文字符,用 UTF-8 编码就能节省空间,UTF-8 编码有一个额外的好处,就是 ASCII 编码实际上可以被看成是 UTF-8 编码的一部分,所以大量只支持 ASCII 编码的历史遗留文件可以在 UTF-8 编码下继续工作。需要特别注意的是:在计算机内存中,都是统一使用的 Unicode 编码。
单个字符的编码, Python提供了 ord() 函数获取单个字符的十进制整数表示,chr() 函数把编码转换成对应的字符。如:

Python 源代码也是一个文本文件,所以当写的源代码中包含中文的时候,保存源码时,就需要指定 UTF-8 编码 ,当 Python 解释器读取源代码时,为了让它按 UTF-8 编码读取,我们通常在文件开头写上一行:
#-*- coding:utf-8 -*-注释是为了告诉 Python 解释器,按照 UTF-8 编码读取源代码,否则在源代码中的中文输出可能会有乱码。看这部分代码:
#-*- coding:utf-8 -*- # 声明当前的模块采用utf-8编码
name = 'zhangsan'
#判断首字符是不是大写,不是大写转换大写后再输出
if not name.istitle(): # 相当于 !name
name = name.title()
print(name)
'''
for i in range(1, 65535):
if i == 55296:
break
print(i, ":", chr(i))
pass
'''
# ord把字符对应的数字编码
print(ord('我'))
7、标识符和保留字
标识符是指用来标识某个实体的一个符号,在不同的应用环境下有不同的含义。在编程语言中,标识符是用户编程时使用的名字,对于变量、常量、函数、语句块也有名字,统称之为标识符。在编程语言中,标识符就是程序员自己规定的具有特定含义的词,比如类名称,属性名称,变量名等。在 Python 里,标识符有字母、数字、下划线组成,但不能以数字开头,另外其中的标识符是区分大小写的。以下划线开头的标识符是有特殊意义的,以单下划线开头 _foo 的代表不能直接访问的类属性,需通过类提供的接口进行访问,不能用 from xxx import * 导入;以双下划线开头的 _ _foo 代表类的私有成员。以双下划线开头和结尾的 _ _foo_ _ 代表 Python里特殊方法专用的标识,如 _ _init_ _() 代表类的构造函数。
Python可以同一行显示多条语句,方法是用分号分开,另外通常情况下,我们的 Python 语句不需要分号就是标识结束。

保留字是指在高级语言中已经定义过的字,使用者不能再将这些字作为变量、常量、函数、语句块等的命名使用。保留字包括关键字和未使用的保留字,关键字则是指在语言中有特定含义(如 for / if / pass /...),成为语法中一部分的那些字。下面的列表显示了在 Python 中的保留字,这些不能用作常数或变数,或任何其他标识符名称。
| False |
None (相当于 null ) | True | and | as (用于类型转换) |
| assert (断言,判断真假) |
async (处理异步?还不太懂) | await | break (中断循环) | class |
| continue |
def (函数定义) | del (删除变量或值) | elif ( else + if ) | else |
| except (捕获异常后的操作) |
finally (出现异常后的操作) | for | from (导入模块) | global (全局变量) |
| if |
import | in | is | lambda (匿名函数) |
| nonlocal (标识外部作用域) |
not | or | pass (占位语句,不作用) | raise (触发异常) |
| return |
try | while | with | yield (从函数依次返回值) |
8、语法格式规范
1)、行和缩进
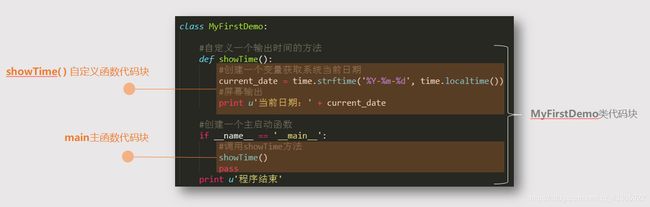
学习 Python 与其他语言最大的区别就是,Python 的代码块不使用大括号{} 来控制区分 函数、逻辑判断和代码块 等语句块的作用域范围和控制区域。Python 最具特色的就是用缩进来写模块。缩进的空白数量是可变的(y一般是1个 tab 制表位),但是所有代码块语句必须包含相同的缩进空白数量,具有行缩进一致的相邻代码被认定为是 1 个块结构,必须严格执行,如下图所示:
而有些不按照规范来写就会报错,比如:
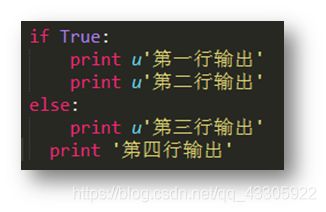
第四行的代码缩进与上一行缩进不一致导致执行报错:要么代码与 if……else保持缩进一致,要么与上一句print保持一致。
由于行缩进导致编码执行报错,经常会出现以下两种情况,我们分别说明一下:IndentationError: unexpected indent 错误是文件里格式不对,可能是tab和空格没对齐的问题,所有 python 对格式要求非常严格。IndentationError: unindent does not match any outer indentation level 错误表明使用的缩进方式不一致,有的是 tab 键缩进,有的是空格缩进,改为一致即可。
因此,在 Python 的代码块中必须使用相同数目的行首缩进空格数。建议在每个缩进层次使用 单个制表符 或 两个空格 或 四个空格 , 切记不能混用。
2)、多行语句
Python语句中一般以新行作为为语句的结束符,但有的时候一行代码太长,不便于我们书写清晰的代码结构,还可能造成代码阅读起来很不方便。因此,我们可以使用斜杠( \)将一行的语句分为多行显示,如下所示:

当语句中包含 [ ], { } 或 ( ) 括号就不需要使用多行连接符,因为它们属于序列数据类型 。
3)、引号
Python 可以使用单引号( ' )、双引号( " )、三引号( ''' 或 """ ) 来表示字符串。需要注意的是:引号的开始与结束必须的相同类型的;其中三引号可以由多行组成,编写多行文本的快捷语法,常用于文档字符串,另外在文件的特定地点,也可当做注释。如下图:

4)、空行
空行是编程过程中,函数之间或类的方法之间实现的空行分隔 ,表示一段新的代码的开始。类和函数入口之间一般也用一行空行分隔,以突出函数入口的开始,从而让代码结构更加清晰易读。
需要注意的是:空行与代码缩进不同,空行并不是Python语法的一部分;书写时不插入空行,Python解释器运行也不会出错;空行的作用在于分隔两段不同功能或含义的代码,便于日后代码的维护或重构。
9、注释及其他
1)、Python注释
在编程语言中,注释的作用是为了让自己或他人更快地了解程序作者的思路和意图,提高代码的可读性。同时在多人协同开发时,也可以提高开发效率,注释部分不参与代码的编译执行。
单行注释 #
单行注释主要应用于对某个变量,代码等的简短说明,不能换行,只能在1行内应用。
多行注释 (三个单引号) ’’’ 或 (三个双引号) ”””
多行注释主要应用于大段文字的说明,可以换行使用。一般用于对类/函数的注释(类注释也可以单行)。
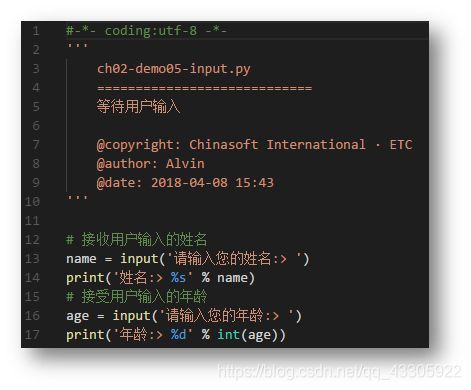
2)、标准输入 input()
等待用户输入,实际上是将当前运行的程序线程挂起,暂停程序的运行;等待用户交互操作之后,在按回车或输入特定字符之后,恢复程序挂起的线程,继续执行,同时处理输入的数据。
用法:input(‘……输入提示内容……’),该函数用接收接收的数据全部为str字符串类型;若想转换成成其他类型,需使用强制类型转换,如 类型名称( str数据 )。
3)、标准输出 print( )输出
print( ) 打印输出函数是在开发中用得很多的函数,代表输出并换行。其语法结构也有很多……
格式化输出规范 1:
如:

格式化输出规范 2:
常用格式占位符号 :%s:输出字符串类型; %d:整数类型;%f:浮点数类型(小数) 等等。n%-10s:占位10个字符,左对齐,多余的占位使用空格填充 ;n%-8.2f:占位8个字符,左对齐,.2代表小数点保留两位 。
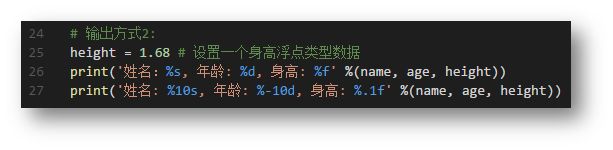
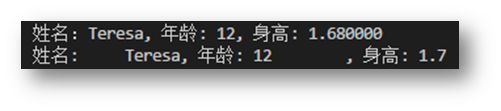
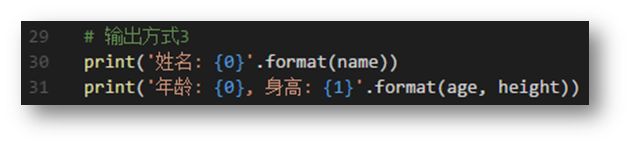
格式化输出规范 3:
print(‘{0} + {1} = {2}’.format(num1, num2, num1 + num2)) ;说明:{ } 方式为占位的另一种表现,但后续需要通过使用 format 函数绑定变量,变量或数据的个数要与占位符的个数保持一致。

看下较全面基础知识的演示:
import sys
print(sys.argv)
print(len(sys.argv)) # 类似java里的list.size()
# python没有char类型,只有字符串类型
name = 'A' # name = "A"
print(type(name))
content = '''
白日依山尽
黄河入海流
'''
print(content)
# 单行注释
'''多行注释
说 明:求两个数字的和
参 数:参数1数字类型,参数2数字类型
返回值:返回两个数字的和
'''
def sum(x, y):
return x+y
pass
print('姓名:', "zhangsan", "年龄:", 20) # void test(String... name)
# print 默认会打印\r\n作为结束,但是可以自定义
print("姓名:", end=" ")
print("张三")
# java类似System.out.printf()
# 站位符格式化字符串
def printUserInfo(name, age, weight):
print("%s %d %f" % (name, age, weight))
pass
printUserInfo('xiaogege', 20, 69.99)
str = "{0}的年龄是 {1} 体重是 {2} 公斤".format('xiaojiejie', 18, 45.00)
print(str)
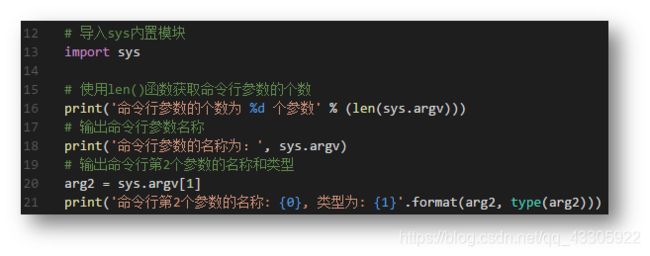
4)、命令行参数
在执行Python命令的时候需要携带的参数称之为 命令行参数。比如:
![]()
示例代码:
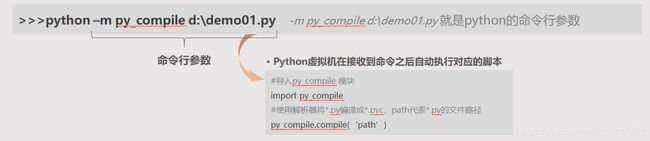
Python 中也可以所用 sys 内置模块的 sys.argv 来获取命令行参数:sys.argv 是命令行参数列表,len(sys.argv)是命令行参数个数。如:
10、基本数据类型
1)、变量
(1)、定义:
变量来源于数学,是计算机语言中能 储存计算结果 或 能表示值 的一个抽象概念(可以理解为一个代号)。其特点有:(1)、变量可以通过变量名访问;(2)、在指令式语言中,变量通常是可变的。命名规范:与之前介绍的中 标识符 的命名规范是一致的,因为变量名就是一个非常典型的标识符。
(2)、赋值:
Python 中的变量赋值不需要类型声明;每个变量在内存中创建,都包括变量的标识,名称和数据这些信息;每个变量在使用前都必须赋值,变量赋值以后该变量才会被创建。另外 变量可以删除: del 变量名[ 变量名1,变量名2...... ]
变量赋值运算符:
等号(=)用来给变量赋值 ;等号(=)运算符左边是一个变量名,等号(=)运算符右边是存储在变量中的值;赋值语法: 变量名 = 值 。
Python 还允许同时为多个变量赋值:
![]()
以上表示创建一个整型对象,值为1,三个变量被分配到相同的内存空间上。也可以为多个对象指定多个变量:
![]()
2)、基本数据类型介绍
Python 定义了一些标准类型,用于存储各种类型的数据,其有六个标准的数据类型:

3)、标准数据类型
(1)、数字类型
数字数据类型用于存储数值,它们是不可改变的数据类型,这意味着改变数字数据类型将会分配一个新的对象。Python支持四种不同的数字类型:
int:有符号整型,通常被称为是整型或长整数,是正或负整数,不带小数点(在Python3里,只有一种整数类型 int,表示为长整型,已经取消 python2 中的 Long);float:浮点型,由整数部分与小数部分组成,浮点型也可以使用科学计数法表示(2.5e2 = 2.5 x 102 = 250);bool:布尔类型,由 True 或 False,即 真1或假0(python2.7中。常用于逻辑判断使用);complex:复数,由实数部分和虚数部分构成,可以用a + bj,或者complex(a,b)表示, 复数的实部a和虚部b都是浮点型 。
(2)、字符串类型及用法(★)
字符串或串(String)是由数字、字母、下划线组成的一串字符,是不可改变的数据类型。Python的字串列表有2种取值顺序:从左到右下标索引默认0开始的,最大范围是(字符串长度-1) ;从右到左下标索引默认-1开始的,最大范围是字符串开头。
如果要实现从字符串中获取一段子字符串的话,可以使用变量 [头下标 : 尾下标:步长],就可以截取相应的字符串,其中下标是从 0 开始算起,可以是正数或负数,下标可以为空表示取到头或尾。
![]()
代码解释:s[1:5] 的结果是 love ,当使用以冒号分隔的字符串,python返回一个新的对象,结果包含了以这对偏移标识的连续的内容,左边的开始是包含了下边界。上面的结果包含了s[1] 的值 l,而取到的最大范围不包括上边界,就是s[5]的值c。
★★★
字符串转义:
由于 Python 中的字符串类型使用单引号或双引号包围,因此在字符串中若包含单引号或双引号输出则需要进行字符转义处理。
| \(在行尾时) |
续行符 |
| \\ |
反斜杠符号 |
| \' |
单引号 |
| \" |
双引号 |
| \a |
响铃 |
| \b |
退格(Backspace) |
| \n |
换行 |
| \r |
回车 |
字符串运算符 in 和 not in :
我们判断字符串中是否包含某个指定的字符或子字符串,这个时候就需要使用 in 或 not in 来进行操作。

简单演示一下:
a = b = c = 1 # 类似的常量池概念
print(id(a))
print(id(b))
print(id(c))
print(a is b)
stra = "hello"
strb = "hello1"
print(stra is strb)
x, y , z = 11, '1111', '你好呀'
strx = 'I LOVE Python\n' # 切片
substr = strx[0]
print(substr)
print(strx[2:6])
print(strx[-1])
print(strx[-7:]) # 从-7开始取之后的所有的字符
print(strx[0:12:2] #表示从0 到 12 (注意不包括12)中每隔 2 字符取一位
print('LOVE' not in strx)
print(strx.count('O', 2, 7))
print(strx.find("LOVE"))
print(strx.split(" ")) # 语义分析
stry = " zhangsan "
print(stry.strip()) # java : trim()
title = "title"
title = title.title()
print(title)
字符串常用内建函数 :
函数 count :
语法结构:str.count(sub, star=0, end=len(string)) ,该方法用于统计字符串里某个字符出现的次数,可选参数为在字符串搜索的开始与结束位置。sub :搜索的子字符串 ;start :字符串开始搜索的位置。默认为第一个字符,第一个字符索引值为0 ;end :字符串中结束搜索的位置 。字符中第一个字符的索引为 0 ,默认为字符串的最后一个位置 。
该函数返回值是返回子字符串在字符串中出现的次数。

函数 endswith :
语法结构:str. endswith(suffix[, start[, end]]) ,该方法用于判断字符串里是否出现目标字符为后缀,可选参数为在字符串搜索的开始与结束位置 。suffix :该参数可以是一个字符串或者是一个元素。
如果字符串含有指定的后缀返回True,否则返回False。

函数 find :
语法结构:str. find(str, beg=0, end=len(string)) ,该方法检测字符串中是否包含子字符串 str ,如果指定 beg(开始) 和 end(结束) 范围,则检查是否包含在指定范围内,如果包含子字符串返回开始的索引值,否则返回-1。str :指定检索的字符串 ;beg :开始索引,默认为0 ;end :结束索引,默认为字符串的长度。
如果包含子字符串返回开始的索引值,否则返回-1。

函数 index :
语法结构:str. index(str, beg=0, end=len(string)) ,该方法也是检测字符串中是否包含子字符串 str ,与 python find()方法一样,只不过如果 str 不在 string中会报一个异常。

函数 replace :
语法结构:str. replace(old, new, [ , max]) ,该方法把字符串中的 old(旧字符串)替换成 new(新字符串),如果指定第三个参数max,则替换不超过 max 次。
该函数返回字符串中的 old(旧字符串) 替换成 new(新字符串)后生成的新字符串。

函数 split :
语法结构:str. split ( split [, num=string.count(str)] ) ,该方法通过指定分隔符对字符串进行切片,如果参数num 有指定值,则仅分隔 num 个子字符串 。str :分隔符,默认为所有的空字符,包括空格、换行(\n)、制表符(\t)等 ;num :分割次数。
函数返回的是分割后的字符串列表。

函数 strip :
语法结构:str. strip ( [ chars ] ) ,该方法用于移除字符串头尾指定的字符(默认为空格)。chars :移除字符串头尾指定的字符。
函数返回的是移除字符串头尾指定的字符生成的新字符串。

字符串处理函数的汇总 :
字符串大小写转换 :lower() / upper() /swapcase() / title() ;字符串搜索、替换 :find() /count() / replace / strip() / lstrip() /rstrip() ;字符串分割、组合 :split() / join() ;字符串编码、解码 :decode()/encode() ;字符串测试 :isalpha() / isdigit() / isspace() / islower() / isupper() / istitle() 。