python爬虫06 - js2py和selenium初探。
内容
js2py简介
动态HTML技术了解
selenium+chromedriver获取动态数据
用google chrome先打开这个页面http://www.porters.vip/verify/sign/(这网页有反爬 容易打不开)
需求是爬取网页的内容

检查
看这个network
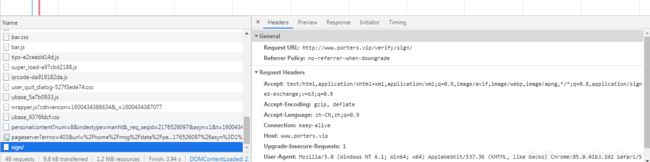
response 和 preview有数据

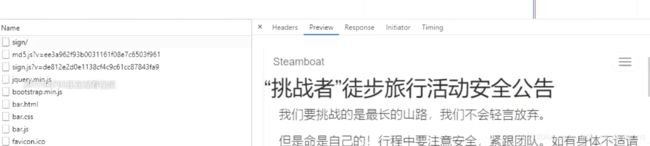
但是那里面不是我们想要的数据
我们想要的 点击查看详情的数据

所以我们可以先清空数据再在网页中点击这个黄色按钮

页面就出现了一些数据

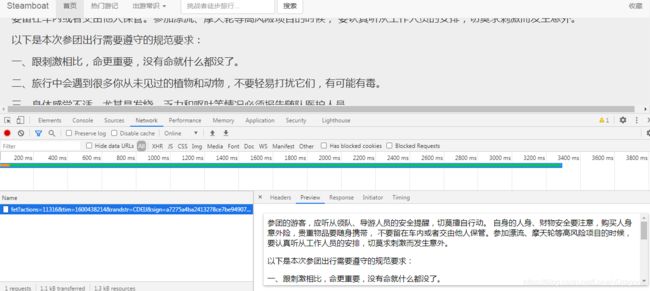
按照常规操作 请求这个url text.decode 加入个请求头 cookie 但是其实没有这么简单 这样请求 就会返回一个403对象
403错误是一种在网站访问过程中,常见的错误提示,表示资源不可用。
403就意味着你请求成功了 但是拒绝 或者是禁止访问 但是服务器已经处理了你的请求了 所以就是被反爬了
我们看看检查中的network中


sign 就是签名的意思
我们分析一下红框中的数据
sign值是一个16位进制的32位数据(32个字符)
![]()
而且呢 签名的这个数据是随机的
action 和 randstr 的数据也是随机的 只不过一个随机的是数字 一个是字母 tim是个时间戳

其实 也就是它这个反爬是它在这个参数做了反爬
我们每次请求这个url时得把参数写进去 但是
首先我们的这个网站是基于js开发的
js是开发web页面的脚本语言 经常在网页中添加一些动态功能
这个js是嵌入到html中来实现它的功能
所以我们得去html网页源码中找一些蛛丝马迹 当然网页源代码中是没有这些文本内容的 可以找找 验证确实没有
那我们来找下js (javasript)


sign 就是签名的意思 md5的js肯定是加密的 所以还是先点开sign的js
打开的代码就是js代码(不是python代码也不是java代码是javascript代码)
ajax就是前端的一个技术 先不用管 我们看到上面有个function 那么我们前面学到函数的对象类型就是一个function

那么这一块就是个函数 它的名字叫做fetch

那么它这个函数的主要作用就是: 刚才的网站有一个按钮 点击按钮过后会刷新出新的数据 那么点击这个按钮时就会触发fetch方法 fetch方法就会调用它这个Get方式 向目标url发起请求

也就是这个url http://www.porters.vip/verify/sign/fet

但是只是向url发起请求肯定不行呀 还得携带一些参数 那就找参数的关键词
在这个uri函数中

action 就是多个随机数 randints (rand随机数 int数字类型 )
tim时间戳 randstr就是随机的一个英文字母 randstrs就是多个随机英文字母
然后再看hexs 是前面的参数action tim randstr 都进行了一个md5的加密
然后将这些数据拼接后 再返回 提交这个参数

因为上面的代码都是js代码 但是我们也可以用python将js代码中的所有内容功能全部模拟下来 生成随机数 随机字母 请求url…
也就是讲到了一个点现在很多网站都开始用js加密技术了
有时候我们需要用python执行js代码 而我们用的是python 那么两种毫不相干的语言 那就要用到js2py模块
1. js2py简介
1.1 js2py模块使用
• Python中执行JS代码,通常两个库:js2py,pyexecjs
• js2py是纯python实现的库,用于在python中运行js代码,本质上是将js代码翻译成python代码
• js2py安装 pip install js2py
1.2 快速入门
里面的console.log 是js代码中一个方法 我们看一下
比如我们在此页面检查 点开console 在控制台输入代码
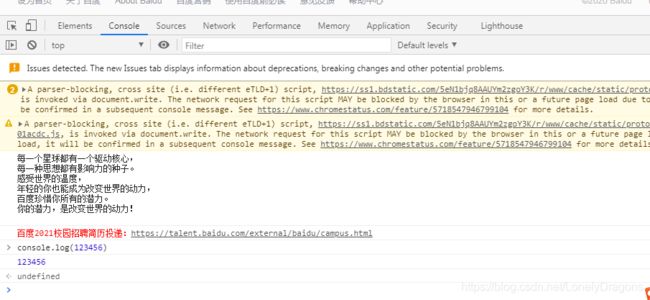
js的代码可以了解 但不是本章的主要学习对象
输入alert(‘python’) 回车 就会弹出python的弹窗

import js2py
js2py.eval_js('console.log("hello wrold")')
func_js = """
function add(a,b){
return a+b
}
"""
#给func_js赋值等于一个文档字符串 这个函数的名字是 add()有两个参数a 和b 中括号[ ]不是字典的意思 里面是函数的内容: 返回结果a+b 这就是这个js代码的一个形式
add = js2py.eval_js(func_js)
print(add(1, 2))
'hello wrold'
3
将js代码中的变量通过python来输出
先声明一个变量 var a= 后面还有;a
import js2py
print('python')
print(js2py.eval_js('var a = "python";a'))
python
python
将js代码中函数通过python来输出
add = js2py.eval_js('function add(a,b){return a + b}')
print(add(2,3))
5
讲了这么多主要就是展示了js2py模块能把js代码翻译成python代码
js代码翻译
import js2py
print(js2py.translate_js("console.log('hello world')"))
from js2py.pyjs import *
# setting scope
var = Scope( JS_BUILTINS )
set_global_object(var)
# Code follows:
var.registers([])
var.get('console').callprop('log', Js('hello world'))
将js文件翻译为Python脚本
就比如我们创建一个test.js文件
# 将js文件翻译为Python脚本
js2py.translate_file('test.js', 'test.py')
然后翻译出来的文件test.py的内容和上面print(js2py.translate_js(“console.log(‘hello world’)”))的结果内容很一样 然后原来test.js中的内容就没了

在js代码中使用函数
使用sum函数

sum中传入一个可迭代的对象 (列表 字典 元组 字符串 集合 range)
sum 将其中的元素相加
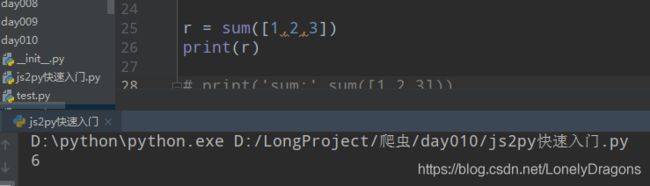
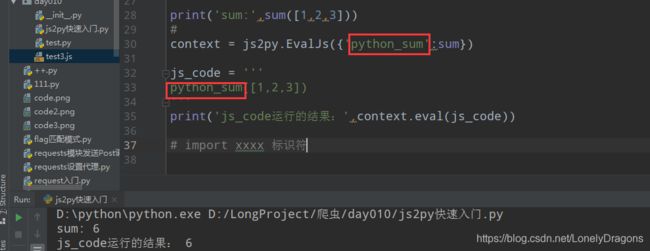
print('sum:',sum([1,2,3]))
context = js2py.EvalJs({'python_sum':sum})
js_code = '''
python_sum([1,2,3])
'''
print('js_code运行的结果:',context.eval(js_code))
但是注意点的是 两个位置python_sum必须一致
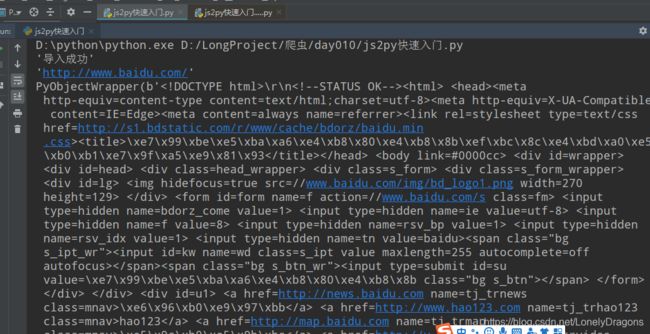
在js代码中导入Python模块并使用
import js2py
# 在js代码中导入Python模块并使用
# 使用pyimport语法
js_code = """
pyimport requests
console.log('导入成功');
var response = requests.get('http://www.baidu.com');
console.log(response.url);
console.log(response.content);
"""
js2py.eval_js(js_code)
run一下之后结果是
导入成功 url也打印了 网页源码(response.content)也打印了
也就是post get 请求不只是python中独有的 其他编程语言中也有 content 返回值 也是 编程语言还是比较相通的 有相同的 比如序列 字符串 基本数据类型 函数 方法 语句 只是表现方式不同
孰轻孰重
2. 动态HTML技术了解
2.1 爬虫和反爬虫的斗争

爬虫建议
• 尽量减少请求次数(比如我们代码练习中就是写一行 然后就请求一下 这种方式其实很不好的 因为是程序在爬取)
• 保存获取到的HTML(把源代码保存到html文件或者js文件中),供查错和重复使用
• 关注网站的所有类型的页面
• H5页面
• APP
• 多伪装
• 代理IP
• 随机请求头
• 利用多线程分布式
• 在不被发现的情况下我们尽可能的提高速度
爬虫思路总结
页码总数明确的 就比如豆瓣top250 百度贴吧 案例 他们都有个pn值 然后把url 多余赘述的内容一点一点删除 再试试打开看看 能不能用 最后然后就能得到一个简洁url
页码总数不明确的 比如天气

2.2 ajax基本介绍
开始之前我们先看一个现象
百度网页中的新闻往下拖就会源源不断的再出来 这就是一个ajax加载数据的案例

动态了解HTML技术
• JS
• 是网络上最常用的脚本语言,它可以收集用户的跟踪数据,不需要重载页面直接提交表单,在页面嵌入多媒体文件,甚至运行网页
• jQuery
• jQuery是一个快速、简介的JavaScript框架,封装了JavaScript常用的功能代码
• ajax
• ajax是一个前端的技术 ajax可以使用网页实现异步更新,可以在不重新加载整个网页的情况下,对网页的某部分进行更新
获取ajax数据的方式
1.直接分析ajax调用的接口。然后通过代码请求这个接口。
(好处如果爬取ajax的数据就是分析这个接口 代码容易编写的 弊端就是它分析页面比较麻烦)
2.使用Selenium+chromedriver模拟浏览器行为获取数据
使用selenium第二种方式的缺点就是代码量多 性能差
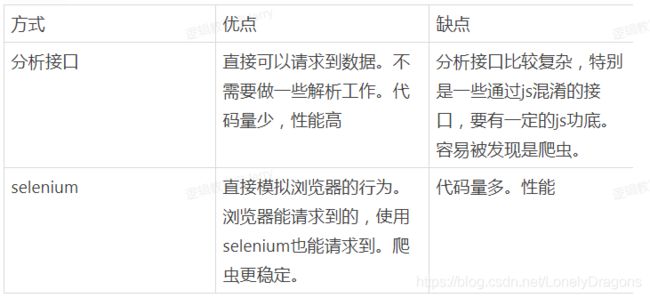
获取ajax数据的方式
黑盒测试工程师 主要是把公司的apk文件下载到你的手机 然后点击测试 再写一份测试用历 所以这个黑盒测试工程师的技术要求不算太高的 坏处就是签合同可能只会是短期的
白盒测试工程师就是得会技术 会用代码来测试bug 会用一些自动化测试工具 好处就是工作稳定 薪资比较高 那么相应的代价就是技术要求 会的东西要求就比较多了
1.直接分析ajax调用的接口。然后通过代码请求这个接口。
(好处如果爬取ajax的数据就是分析这个接口 代码容易编写的 弊端就是它分析页面比较麻烦)
比如这个12306网站 只有点击查询才会出现下面的车次信息
2.使用Selenium+chromedriver模拟浏览器行为获取数据
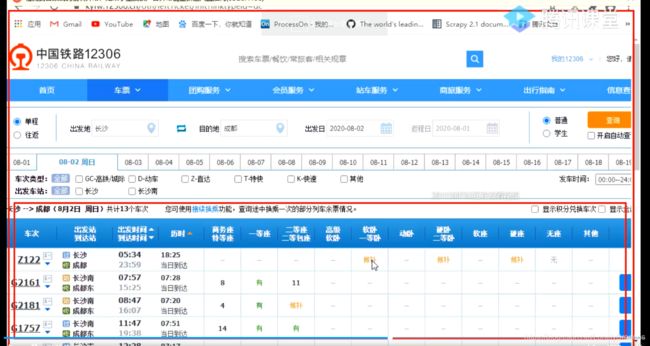
而且比如车次号G2161没法在网页源代码中找到 只能在Elements中找到 也就是网页基本没有变 局部发生了变化
如果源码中没有数据 我们想要提取数据 就可用开发者工具中的network

刷新完页面 左边的60多个请求就构成了我们的这整个页面

那咱们就分析整个60多的数据请求 找到那个车次号 如果找到了是在哪个请求包里 我们就请求相应的数据接口就行了
但是我们又发现虽然60多个数据虽然不多 但是我们一个一个找还是不好找呀
清空network 我们刷新页面 查询这个车次信息 network就出现仅有几个数据 query 就是查询的意思 所以这个就是查询的意思
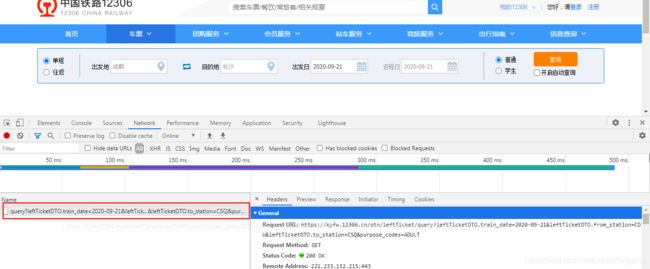
咱们看看preview的内容
打开data 再打开result
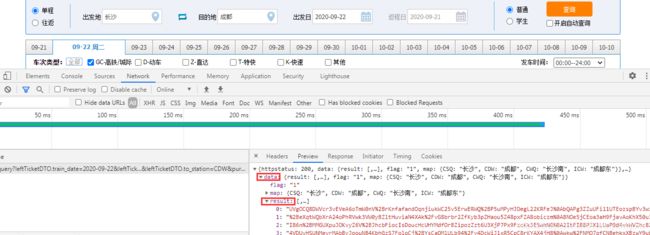
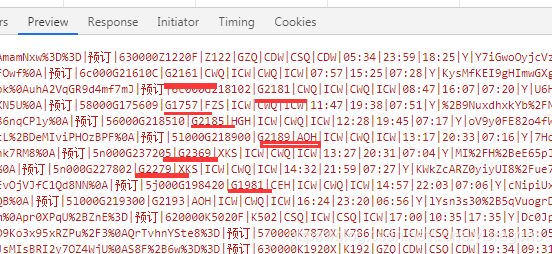
那下面这些红的就车次列表
13个

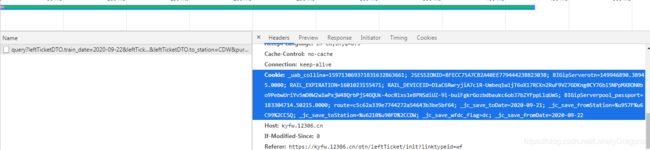
然后我们请求这这个url那这个数据就行了

但是这里做有反爬 我们加上个cookie
1.直接分析ajax调用的接口。然后通过代码请求这个接口。
这个就是第一种方式 你会发现这个分析比较麻烦 但是写代码写起来比较简单
俺么还有一种方式就是第二种使用Selenium+chromedriver模拟浏览器行为获取数据
3. Selenium+chromedriver获取动态数据
3.1 Selenium 介绍
• selenium是一个web的自动化测试工具,最初是为网站自动化测试而开发的,selenium可以直接运行在浏览器上,它支持所有主流的浏览器,可以接收指令,让浏览器自动加载页面,获取需要的数据,甚至页面截屏(所以selenium不是专门做爬虫的 )
• chromedriver是一个驱动Chrome浏览器的驱动程序,使用他才可以驱动浏览器。当然针对不同的浏览器有不同的driver。以下列出了不同浏览器及其对应的driver:
• Chrome:https://sites.google.com/a/chromium.org/chromedriver/downloads
Firefox:https://github.com/mozilla/geckodriver/releases
Edge:https://developer.microsoft.com/en-us/microsoft-edge/tools/webdriver/
Safari:https://webkit.org/blog/6900/webdriver-support-in-safari-10/
• 下载chromedriver
• 百度搜索:淘宝镜像(https://npm.taobao.org/)
• 安装总结:https://www.jianshu.com/p/a383e8970135
• 安装Selenium:pip install selenium
但是上述的资源因为是外网的东西,我们使用局域网是访问不到的 阿里的淘宝镜像就是已经提前将这些外网资源下载到他们的服务器了 所以换源安装就行 使用国内网就好了

我们需要学习的就是Phantomjs 和Chromedriver 这两个
那么安装Phantomjs怎么安装的呢 我们以Windows系统来举例
先点击链接
![]()
直接下载这个版本就行了
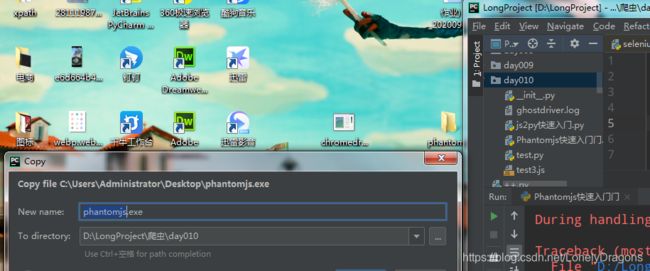
解压后是文件夹 打开文件夹 点开bin目录 有个exe后缀的文件 然后再把这个文件拷贝到桌面
然后是chromedriver 先查看你的GoogleChrome的版本


要下载对应版本的
第二点就下载解压后的 文件必须在英文路径下
windows用这个就行 不论是32 64位的都能用

3.2 Phantomjs快速入门
无头浏览器:一个完整的浏览器内核,包括js解析引擎,渲染引擎,请求处理等,但是不包括显示和用户交互页面的浏览器
Phantomjs案例
没有selenium库的可以换源安装

走一个我们发现报错了
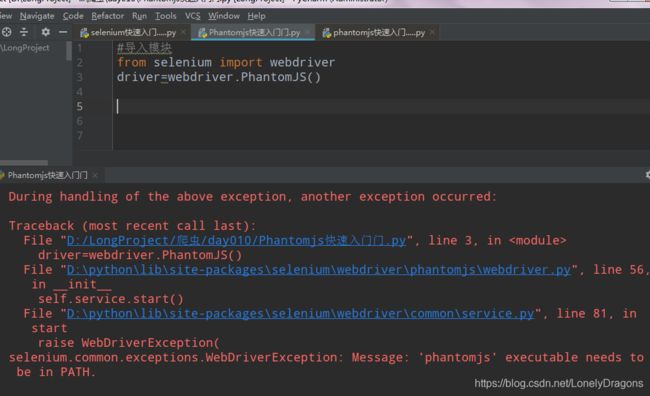
Message: ‘phantomjs’ executable needs to be in PATH.
消息:“phantomjs”可执行文件必须位于路径中。
可以把文件放在此程序同一目录下 解决问题



执行后

虽然也是红的字 但是这个跟以前的不一样 这个的意思是你的PhantomJS过时了但是还能用的 我们不用管在这个
当然放在文件路径下 如同上面的 下次用还得放 所以放到path中就可以一劳永逸

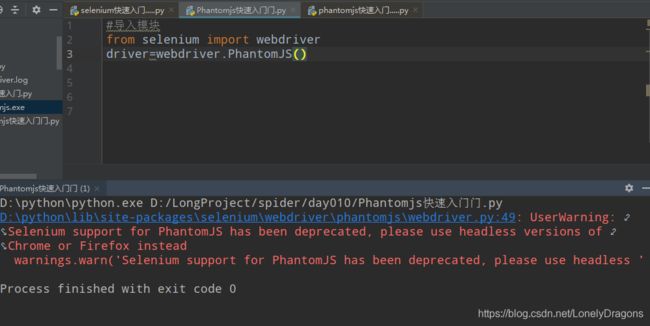
这样就行额 没有报错只要警告
selenium是做自动化的工具 比如让它帮助我们打开浏览器

但是如上运行后并无反应
因为Phantomjs无头浏览器:一个完整的浏览器内核,包括js解析引擎,渲染引擎,请求处理等,但是不包括显示和用户交互页面的浏览器
也就是Phantomjs是无界面浏览器 但是它会把网站加载到内存 执行JavaScript 也就是它能执行你的逻辑 代码 但是你是看不到界面的
其实呢 它这里提供了一个截屏的功能 咱们通过截屏来看这个功能
#导入模块
from selenium import webdriver
#驱动
driver=webdriver.PhantomJS()
#打开百度
driver.get('https://www.baidu.com')
#截屏
driver.save_screenshot('baidu.png')#指定一个文件名

虽然又是红色警告 这个并不是报错 不用管它

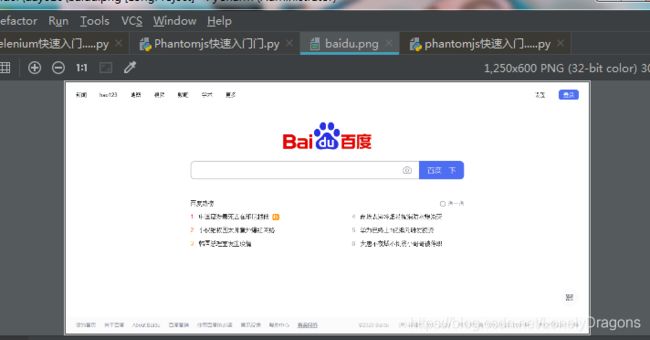
也就是我们没有手动打开这个百度 是这个Phantomjs帮我们打开了
使用左上角 小鼠标键 点击搜索框
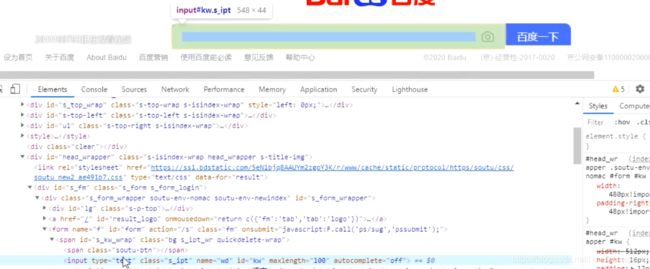
你会发现input便签这行 有type class name id等等的属性 我们找到id就找到了(定位)这个搜索框 图中的id值为’kw’

#导入模块
from selenium import webdriver
#驱动
driver=webdriver.PhantomJS()
#打开百度
driver.get('https://www.baidu.com')
#定位操作输入内容
driver.find_element_by_id('kw').send_keys('python')
#截屏
driver.save_screenshot('baidu.png')#指定一个文件名
然后看看baidu.png
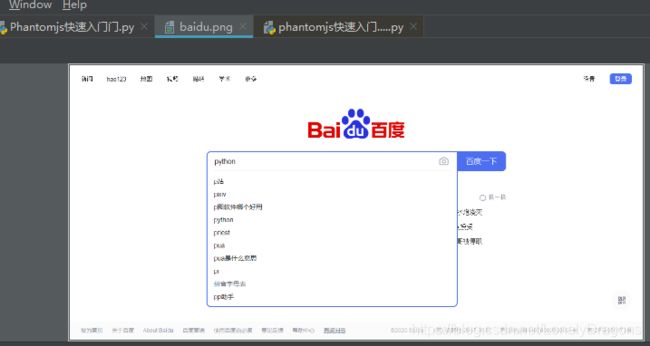
那么仅仅实现了这些操作还是不够的 如果想让它回车 或是百度一下 使网页出现这些内容
其实也很简单 只需要找到百度一下这个按钮 的id

id是 ‘su’

我们发现好像没有刷新出来内容
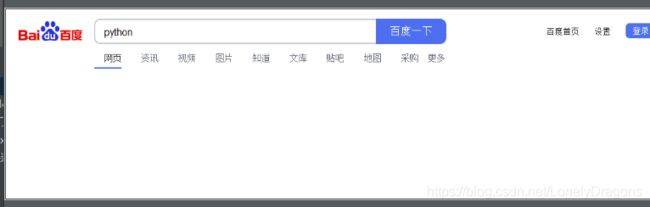
我们导入 一个time模块 让这个程序在点击之后停顿几秒

#导入模块
from selenium import webdriver
import time
#驱动
driver=webdriver.PhantomJS()
#打开百度
driver.get('https://www.baidu.com')
#定位操作输入内容
driver.find_element_by_id('kw').send_keys('python')
#点击按钮
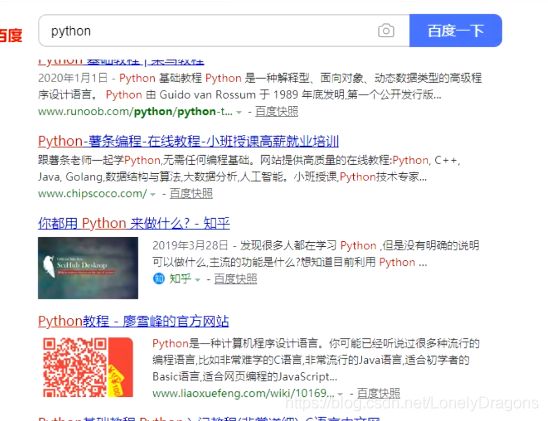
driver.find_element_by_id('su').click()
time.sleep(5) #停顿5秒 当然停顿一秒也行
#截屏
driver.save_screenshot('baidu.png')#指定一个文件名
这回就行了
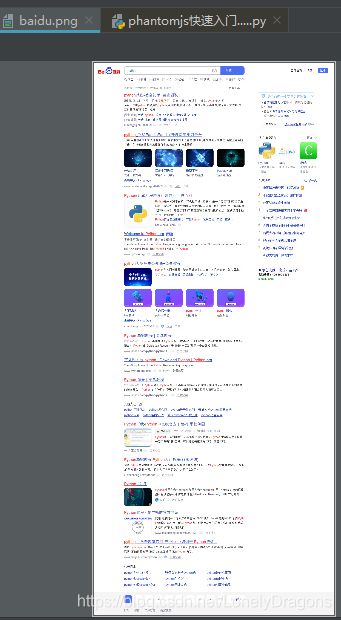
查看当前请求的url地址
print(driver.current_url)

我们再把click打开 看看获得的地址有何变化

果然发生了变化

查看网页源代码
print(driver.page_source)
我们可以清楚看到 这个是加上那行点击代码的
打印出来的网页源代码还是https://www.baidu.com的
去掉那行点击代码 源代码的结果还是一样的
但是这个东西已经过时了 我们就是防止面试官问到不会
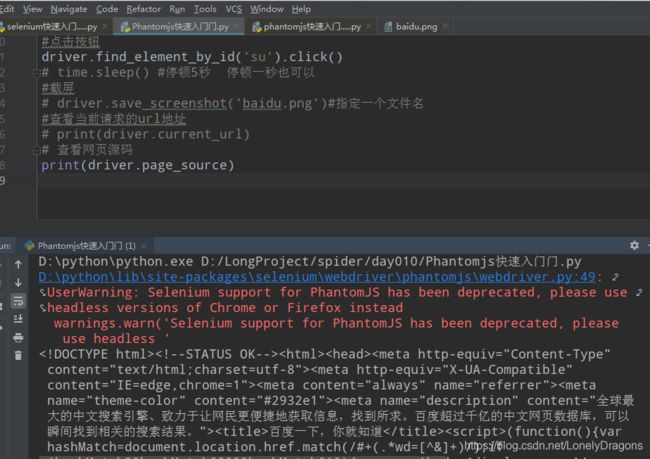
3.3 selenium快速入门
# 1.加载网页
from selenium import webdriver
driver = webdriver.PhantomJS("安装目录")
driver.get("https://www.baidu.com")
driver.save_screenshot("baidu.png")
# 2.定位和操作
driver.find_element_by_id("kw").send_keys("长城")
driver.find_element_by_id("su").click()
# 3.查看请求信息
driver.page_source
driver.get_cookies()
driver.current_url
# 4.退出
driver.quit()
这个是我们学习的重要 以后的内容都是学这个 这个和上面的操作其实差不多 但是更加人性化
照样把这个放到环境变量当中
运行之后这个selenium就非常人性化了(起码不用截屏了)

但是打开的谷歌浏览器会有一个提示
![]()
这个提示是让我们看的 当然百度的那些开发者也会看到
所以其实这个selenium也会受到反爬的 它还是弊端的 因为毕竟他不是专门来做爬虫的 因为别人也能看到上面的正在受到自动测试软件的控制。这句话
然后咱们导入time模块让它停留几秒关闭
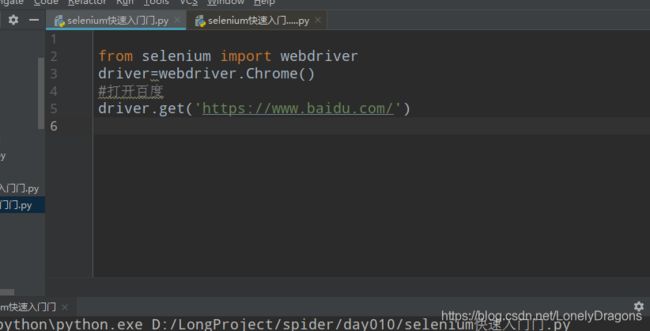
from selenium import webdriver
import time
driver=webdriver.Chrome()
#打开百度
driver.get('https://www.baidu.com/')
time.sleep(3)
#退出浏览器
driver.quit()
运行后 浏览器停留3秒后关闭

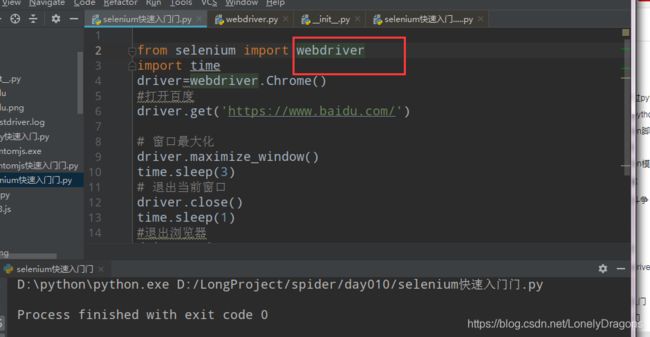
如上图运行后
将会打开浏览器 然后最大化窗口 然后退出浏览器
比如窗口最大化的这种类似方法我们看源码就行了
driver.close() #driver.close()和driver.quit()区别在这里看不出来 下节讲到多窗口时会讲到
time.sleep(1)
停一秒关闭窗口
from selenium import webdriver
import time
driver=webdriver.Chrome()
#打开百度
driver.get('https://www.baidu.com/')
# 窗口最大化
driver.maximize_window()
time.sleep(3)
# 退出当前窗口
driver.close()
time.sleep(1)
#退出浏览器
driver.quit()
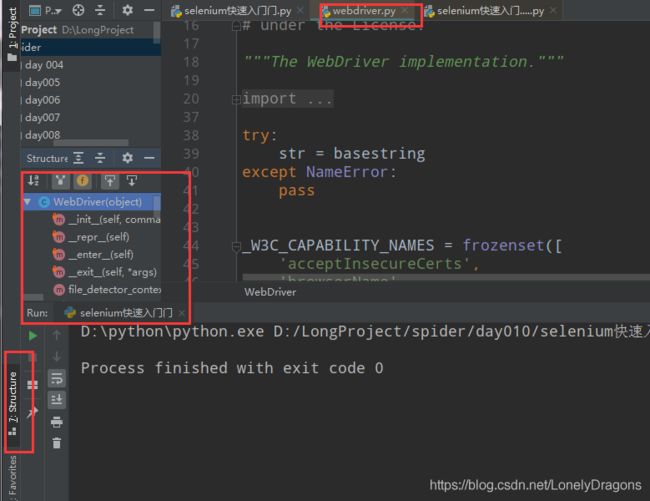
_init_ 特殊方法 初始化属性
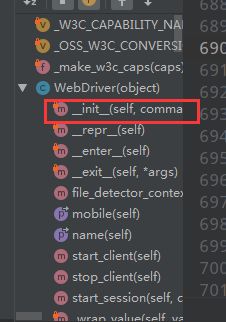

关闭窗口 和退出程序
比如下图的源代码中的这个方法

我们就可以看源代码 练习使用

复习
