PySpark:结构化流
PySpark三: 结构化流
很多人应该已经听说过spark中的Streaming数据这个概念,这也是sprak的亮点之一。这章我们就来简单的介绍spark中Streaming的概念以及pyspark中Streaming数据的一些简单操作方法。如果是直接观看这篇文章的朋友可以先观看一下我之前的两篇文章,里面会有Pyspark基础的操作语法和hadoop环境的配置(不配置hadoop环境的话是无法运行这章的代码的)
首先我们来介绍一些基础的概念:
1、Batch 与 Stream
Batch data与Stream data是两种数据传输的方式。打个比方,数据是一湖的水,采用Batch的方法就算一桶一桶地去装,而采用Stream就是接个管道。Batch data会搜集一定的数据之后再统一地传输过去,可能一个小时,或者一天的数据统一传输。但是Stream data会实时地将产生的数据传输过去,更加具有实时性,通常来说,Batch 每次传输的数据量是多于Stream的。很类似与制造系统中流水线的概念,Batch是等一批货加工完了再统一运往下个工位,Stream是加工完一个就运输给下个工位。下图中就是Stream传输方式的示意图。
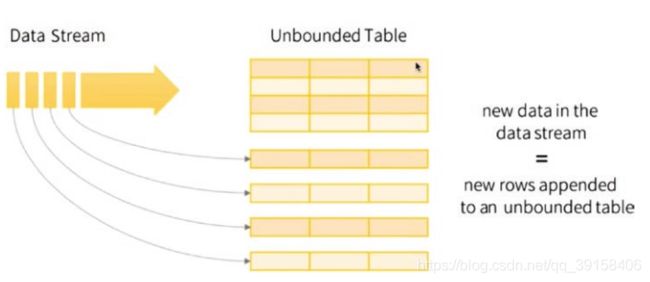
目前在很多业务中很注重实时性,比如推荐系统中的用户最新的点击序列等,推荐系统需要在用户点击之后立刻获得,因此Stream应用也越来越广泛。
2、Spark Stream
下图式Spark Stream数据流的过程。
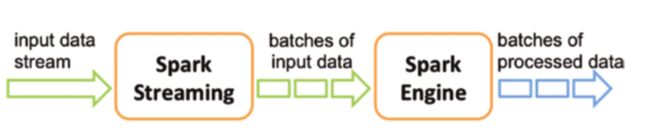
一般Spark stream会从kafka或者其它地方接收Stream数据,然后转化成小批次的数据进行处理,每个小批次数据可以视为一个RDD。
3、结构化流
为了更加直观地说明Structured Streaming,下面我们用代码和代码执行的结果来介绍。
第一步:创建Stream数据与读取
首先导入需要的类,创建一个DataFrame数据将其用增量的方式保存,并且定义一个与数据想匹配的数据格式。
from pyspark.sql import SparkSession
spark=SparkSession.builder.appName('structured_streaming').getOrCreate()
import pyspark.sql.functions as F
from pyspark.sql.types import *
df_1=spark.createDataFrame([("XN203",'FB',300,30),("XN201",'Twitter',10,19), ("XN202",'Insta',500,45)], ["user_id","app","time_in_secs","age"]).write.csv("csv_folder" ,mode='append')
schema=StructType().add("user_id","string").add("app","string").add("time_in_secs","integer").add("age","integer")
然后我们就可以从文件从取数据了,这时候像之间那样直接show就不行了。

第二步:操作
df=data.groupBy('app').count()
比如上面采用的就是聚合操作,操作后怎么查看数据呢?
查看数据之前我们必须要先定义输出模型和所需的位置,如下所示。outputMode除了complete之外还有append和update的形式(有需要的可以自行了解一下,本文以mode为complete为例),complete是输出所有的数据。
query=(app_count.writeStream.queryName('count_query').outputMode('complete').format('memory').start())
建立好输出模型和所需的位置之后,我们可以用一个简单的Spark SQL命令就可以查看数据了:
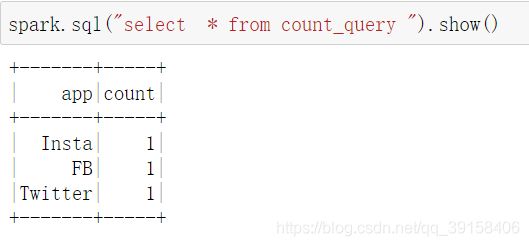
线上的话采用Stream的话,数据会源源不断地传输,由于环境所限,我们只能把数据存储到本地,那么怎么体现出Stream的特点呢?
df_2=spark.createDataFrame([("XN203",'FB',100,30),("XN201",'FB',10,19),("XN202",'FB',2000,45)],["user_id","app","time_in_secs","age"]).write.csv("csv_folder",mode='append')
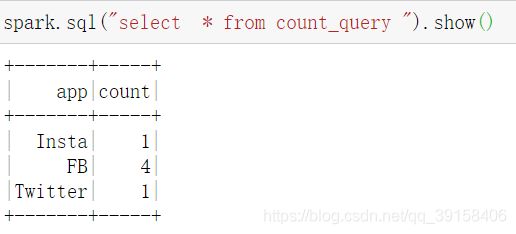
执行上面的代码,代表着将数据新加到之间的数据之上。
此时,重新执行查询操作,可以发现,查询到的数据已经发生了改变。
除了查看每个app的count之外,我们们还可以查询其它的聚合信息,步骤也和上面一样,先定义操作方法(和上一章的操作方法完全一样,比如我下面需要查看每个app花费的时间并之和并且进行倒序),然后定义输出模型和所需位置:
app_df=data.groupBy('app').agg(F.sum('time_in_secs').alias('total_time')).orderBy('total_time',ascending=False)
app_query=(app_df.writeStream.queryName('app_wise_query').outputMode('complete').format('memory').start())
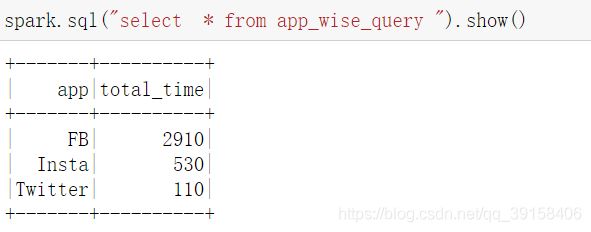
然后使用SQL命令查询

此时,如果我们继续往文件中添加数据:
df_3=spark.createDataFrame([("XN203",'FB',500,30),
("XN201",'Insta',30,19),("XN202",'Twitter',100,45)],
["user_id","app","time_in_secs","age"]).write.csv("csv_folder",
mode='append')
然后再进行刚才命令的查询,发现新进来的数据已经被使用了。
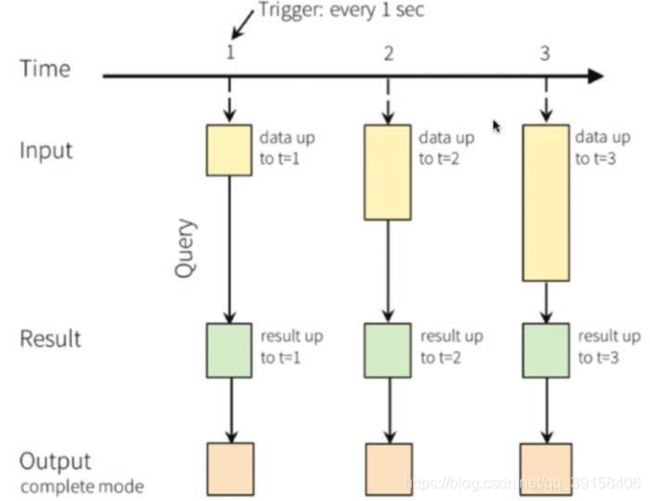
经过上文中的例子,相信这种结构化流的思想已经有了一定的了解。下图是一个输出模型是complete 的结构化流处理数据的流程图。当数据在1时候到达第一个的时候,建立一个查询方法,我们可以查询到第一个数据信息,当2时候又有一个数据新进来的时候,执行查询操作,可以直接看到12时刻所有进来数据的信息。
四:尾言
本节中介绍了Stream数据与batch数据的区别,还有Stream数据的处理流程和简单的语法介绍。更多Pyspark的介绍请期待下节。想了解更多算法,数据分析,数据挖掘等方面的知识,欢迎关注ChallengeHub公众号,添加微信进入微信交流群,或者进入QQ交流群。

