leetcode题型—优先级队列(topK问题)
目录
1.Num17.14:找数组中最小k个数
a.代码实现:
b.使用快速排序解决此问题是否优于现在的写法
2.Num347:前k个高频元素
a.分析:
b.思路:
c.细节:
d.Map集合相关方法:
e.代码实现及分析:
3.Num373:查找和最小的k对数组
a.分析:
b.细节难点:
c.思路:
d.代码实现及易错分析:
4.Num692:前k个高频单词
5.Num1046:最后一块石头的重量
1.Num17.14:找数组中最小k个数
* 找出数组中最小的k个数。以任意顺序返回这k个数均可(取小数用大堆)
* 0 <= len(arr) <= 100000;0 <= k <= min(100000, len(arr))
a.代码实现:
import java.util.Comparator;
import java.util.PriorityQueue;
import java.util.Queue;
/**
* 分析:
* 找最小的k个数,topK问题,用到最大堆(注意JDK内部默认是最小堆,需要用到比较器)
* 思路:
* 1.边界:arr.length==0||k==0
* 2.构建最大堆
* 3.遍历原数组,优先级队列中只存储前个元素,不够k个一直存到k个,够了就判别,大元素出队
*/
public class SmallestK {
public int[] smallestK(int[] arr, int k) {
if(arr.length==0||k==0){
return new int[0];
}
//构造最大堆(优先级队列内部默认最小堆)
Queue queue=new PriorityQueue<>(new Comparator() {
@Override
public int compare(Integer o1, Integer o2) {
return o2-o1;
}
});
//遍历原数组元素,给队内添加元素,优先级队列只存储k个值。元素满了就判断当前添加元素与堆顶元素的大小
//比堆顶元素大无需入队,比堆顶元素小则堆顶元素出队它入队
for(int i:arr){
if(queue.size()peek){
//元素>堆顶元素,不入队,进入下一个循环
continue;
}else{
queue.poll();
queue.offer(i);
}
}
}
//循环完毕,最小的k个数已在队内(最大堆中就保存了最小的k个数),k个数依次出队即可
int[] ret=new int[k];
for (int i = 0; i < k; i++) {
ret[i]=queue.poll();
}
return ret;
}
}
b.使用快速排序解决此问题是否优于现在的写法
对于这个问题来讲,一定是可以使用排序的,排序法的思路就是先把数组排序(默认都是升序),然后依次取出前四个数即可。用最好的快排,时间复杂度nlogN,而构造最大堆这个思想,时间复杂度nlogK,k<
2.Num347:前k个高频元素
* 给你一个整数数组nums和一个整数k,请你返回其中出现频率前k高的元素,你可以按任意顺序返回。
* 1 <= nums.length <= 105 k的取值范围是 [1, 数组中不相同的元素的个数]
* 题目数据保证答案唯一,换句话说,数组中前 k 个高频元素的集合是唯一的。
a.分析:
1.题目的大小关系是按元素出现次数的大小关系排的,不是元素值的大小。
2.topK问题,找出现频次高的,应用到最小堆,让出现频率小的不断出队,留下的就是频次高的。
b.思路:
1.将数组中出现的元素以及出现的次数存储到Map中。
2.扫描Map集合(细节思考:为何是扫描Map集合而不是扫描原数组?),将前k个出现频次最高的元素放入最小堆(优先级队列)中,当整个集合扫描完毕,最小堆中就存储了前k个频次最高的元素。
3.将最小堆依次出队即可得到答案。
c.细节:
1.考虑定义类来解决问题:定义Freq类{int k;(存储不重复的那些元素) int times;(元素对应出现的次数)}
2.优先级队列存储的类型就是Freq类,如果不定义这个类,优先级队列中的元素不好处理。
3.此时优先级队列需要传入比较器,因为此时大小关系不是元素值的大小,而是出现频次的大小。【下面用到的方法我们未定义比较器,而是让Freq类实现了Comparable接口,自己来实现一个大小关系】
4.思考:为何是扫描Map集合而不是扫描原数组?->因为Map集合中存储的是不重复元素及对应次数,如果扫描原数组,不就是多个重复元素扫描又扫描了n次吗。
d.Map集合相关方法:
map.put(key,val);->将键值对中key元素对应存储上val值
map.get(key);->取出键值对key对应的val值返回
map.contains(key);->判断元素key是否存在
map.getOrDefault(key,val);->判断key存在就返回val值,不存在就给val设置默认值val并返回
map.entrySet()->取出键值对/将键值对返回

注意:
a.
map.put(i,map.getOrDefault(i,0)+1);//i是key值
b.
if(map.containsKey(i)){ //说明i已经在map中存在了,map.get取出对应的出现次数val再+1
map.put(i,map.get(i)+1);
}else{
map.put(i,1);
}a和b在代码中等价
e.代码实现及分析:
import java.util.HashMap;
import java.util.Map;
import java.util.PriorityQueue;
import java.util.Queue;
/**
* 分析:
* 1.前k个频次最高的元素,topK问题,用到最小堆(JDK内部默认是最小堆)
* 2.出现频次最高,是元素值出现次数多的,而非元素值大的,用到键值对(Map集合)
* 思路:
* 1.将数组中的元素及出现的次数存到Map集合
* 2.扫描Map集合,前k个出现频次最高的元素放入最小堆:队中不够k个元素就添加,够了判断是否<堆顶元素,小于不入队,否则堆顶出队当前元素入队
* 3.最小堆依次出队即可
* 细节:
* 1.学会用类解决问题,定义Freq类存储值和出现次数,优先级队列存储的类型就是Freq类
* 2.此时优先级队列需要传入比较器:因为此时大小关系不是元素值的大小,而是出现频次的大小
*/
public class Num347_TopKFrequent {
//定义Freq类,内部包含每个不重复的元素及出现的次数
//这里不定义比较器,让他实现Comparable接口,自己来实现一个大小关系
private class Freq implements Comparable{
private int key;
private int times;
public Freq(int key, int times) {
this.key = key;
this.times = times;
}
@Override
public int compareTo(Freq o) {
return this.times-o.times;//出现的次数越多返回值越大
// (又因为此时最小堆,小值优先出队,所以队最后剩的都是大的次数对应的值)
}
}
public int[] topKFrequent(int[] nums, int k) {
int[] ret=new int[k];
//1.先扫描原nums数组,将每个不重复元素以及其出现的次数给存储到Map中
Map map=new HashMap<>();
for(int i:nums){
// map.put(i,map.getOrDefault(i,0)+1);//i是key值。map.getOrDefault(key,val):如果k值存在,返回相应的val值,不存在,给它设置默认值
if(map.containsKey(i)){
//说明i已经在map中存在了,map.get取出对应的出现次数val再+1
map.put(i,map.get(i)+1);
}else{
//i在map中不存在,i是第一次出现。将val存1,说明i现在出现一次了
map.put(i,1);
}
}
//2.扫描Map集合,将前k个出现频次最高的元素放入到优先级队列中【优先级队列中存储的类型是Freq类】
Queue queue=new PriorityQueue<>();
//Freq类是Compare接口的子类(按times进行的比较),它的值入队列,优先级队列是知道谁大谁小的
for(Map.Entry entry: map.entrySet()){
//依次取出键值对,存储到entry对象中
if(queue.size() 使用比较器模式:(上面的是实现了Comparable接口)
import java.util.*;
public class TopKFrequent {
private class Freq {
private int key;
private int times;
public Freq(int key, int times) {
this.key = key;
this.times = times;
}
}
public int[] topKFrequent(int[] nums, int k) {
int[] ret=new int[k];
//1.扫描nums数组,每个不重复元素及对应键值对存储到Map集合中
Map map=new HashMap<>();
for(int i:nums){
// map.put(i,map.getOrDefault(i,0)+1);
if(map.containsKey(i)){
map.put(i,map.get(i)+1);
}else{
map.put(i,1);
}
}
//2.扫描map集合,将前k个出现频次最高的元素放入到优先级队列中
Queue queue=new PriorityQueue<>(new Comparator() {//传入比较器
@Override
public int compare(Freq o1, Freq o2) {
return o1.times- o2.times;
}
});
//Map集合的for-each遍历需要将Map转化为Set
for(Map.Entry entry: map.entrySet()){
if(queue.size() 3.Num373:查找和最小的k对数组
* 查找和最小的k个数对(pair:数对)
* 给定两个以升序排列的整数数组nums1和nums2 ,以及一个整数 k 。定义一对值 (u,v),其中第一个元素来自 nums1,第二个元素来自 nums2 。 请找到和最小的k个数对(u1,v1),(u2,v2)...(uk,vk)
* 1 <= nums1.length, nums2.length <= 105
* -109 <= nums1[i], nums2[i] <= 109
* nums1 和 nums2 均为升序排列 1 <= k <= 1000
a.分析:
1.求和最小的k个数对,topK问题,用大堆(JDK内部默认是最小堆)
2.k有可能大于数组长度:[1,2],[1],求和最小的三个数对,此时组合起来只有两个数对
3.学会使用类,类中两个变量u、v,u表示第一个数组的元素,v表示第二个数组的元素
b.细节难点:
1.JDK内部默认最小堆,要转化为最大堆:用到比较器改造最小堆变为最大堆实现
2.k值大于数组长度遍历到数组长度即可遍历结束,k值小于数组长度数组遍历k个元素即可,即遍历两个数组时循环条件终止条件:for(int i=0;i<Math.min(nums1.length,k);i++) (升序数组,题目找最小元素组合数对,k个后面的一定不是要用到的元素) 。
3.当最后取出队列元素时,除了前k个这个条件,另外,由于可能k>数组长导致不到k队列已经空了,此时也算结束无需再操作,即取出元素时循环的终止条件:for (int i = 0; i < k&&(!queue.isEmpty()); i++)。
c.思路:
1.定义数对的类。构建最大堆
2.扫描遍历这两个数组(u来自第一个数组,v来自第二个数组),k个键值对放入最大堆,放够后开始比较是否小于堆顶元素,小于无需入队,大于堆顶出队当前数对入队。
3.前k个pair对象依次出队
d.代码实现及易错分析:
import java.util.*;
public class Num373_KSmallestPairs {
private class Pair{
int u;
int v;
public Pair(int u, int v) {
this.u = u;
this.v = v;
}
}
public List> kSmallestPairs(int[] nums1, int[] nums2, int k) {
//1.构建出最大堆的优先级队列,实现比较器(定义出比较方法)
//最大堆存的元素是,此时元素的大小关系为pair对象中u+v的值越大,认为元素越大【最大堆大的先出就达到最后剩和最小的数对】
Queue queue=new PriorityQueue<>(new Comparator() {
@Override
public int compare(Pair o1, Pair o2) {
return (o2.u+o2.v)-(o1.u+ o1.v);
}
});
//2.遍历两个数组,注意数组循环遍历的中止条件:k>数组长度时取到数组长度即可,小于时取到k即可
//重点:k值可能比数组长度大,此时只需要遍历到数组长度就好
//k<数组长度时,数组取值只用取到k,因为元素按值升序,k后的一定是大值,用不到
//综合,所以循环的终止条件就是:Math.min(nums.length,k),取键值对个数k与数组长度的较小值【难点】
for (int i = 0; i < Math.min(nums1.length,k); i++) {
for (int j = 0; j < Math.min(nums2.length, k); j++) {
if(queue.size()(pair.u+ pair.v)){
continue;
}else{
queue.poll();
queue.offer(new Pair(nums1[i],nums2[j]));
}
}
}
}
//此时优先级队列中就存储了最大的k个数对,出队即可.
//注意出队循环中止条件:出k个数对,当数组长> ret=new ArrayList<>();
for (int i = 0; i < k && (!queue.isEmpty()); i++) {
List temp=new ArrayList<>();
Pair pair=queue.poll();
temp.add(pair.u);
temp.add(pair.v);
ret.add(temp);
}
return ret;
}
} 易错分析:
1.比较器让最小堆变为最大堆,以及内部compare实现
2.Math.min(nums1.length,k)
3.for (int i = 0; i < k && (!queue.isEmpty()); i++)
4.观察如下代码(前三个在细节分析中有详述)
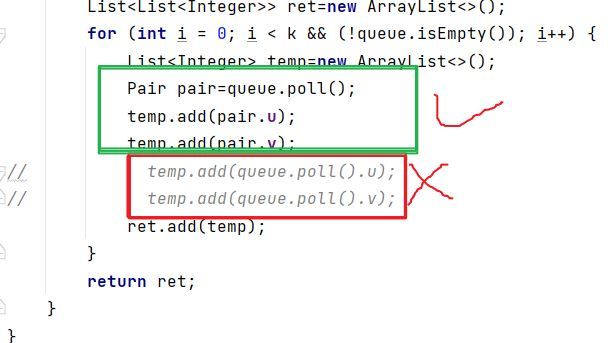
在最后这块出队是,要注意先记录出队后的数对,再把值对应的添加给temp,而不是红框中的写法,红框中意思成了每次temp.add都出了数对,第一次出的数对的u给了第一个temp.add(),第二个数对的v给了temp.add(),是错误的。
4.Num692:前k个高频单词
* 给定一个单词列表words和一个整数k,返回前k个出现次数最多的单词。
* 返回的答案应该按单词出现频率由高到低排序。如果不同的单词有相同出现频率,按字典顺序排序。
import java.util.*;
/**
* 前k个高频单词
* 给定一个单词列表words和一个整数k,返回前k个出现次数最多的单词。
* 返回的答案应该按单词出现频率由高到低排序。如果不同的单词有相同出现频率,按字典顺序排序。
*/
/**
* 分析:
* 1.前k个高频单词,topK问题,应用最小堆
* 2.出现频次最高,应用Map集合,Map:key记录单词,val记录单词出现的次数
* 3.可以使用类解决问题:Freq类存储单词和出现次数,优先级队列存储的类型就是Freq类
* 思路:
* 1.扫描将单词及对应次数存储到Map集合
* 2.遍历Map集合,取前k个频次最高的元素放入最小堆(最小堆中存储到就是Freq类)
* 先循环放k个,放够后进行判断是否当前元素<堆顶元素,<无需入队,否则堆顶出队,当前元素入队
* 3.遍历完后最小堆就存储了出现频次多的单词,依次出队即可
* 4.注意单词频率相等情况,此时要按字典序输出大的元素留下来小的元素
* 比较方法o1.compareTo(o2)是返回值越小越排在前,最小堆返回值小的先出,我们需要让字母大的先出,应该改为o2.compareTo(o1)
*/
public class Num692_TopKFrequentWord {
private class Freq{
String word;
int times;
public Freq(String word, int times) {
this.word = word;
this.times = times;
}
}
public List topKFrequent(String[] words, int k) {
Map map=new HashMap<>();
//1.将单词及对应次数存储到Map集合
for(String i:words){
map.put(i,map.getOrDefault(i,0)+1);
}
//2.扫描Map集合,前k个出现频次高的单词存入堆(优先级队列)中
Queue queue=new PriorityQueue<>(new Comparator() {
@Override
public int compare(Freq o1, Freq o2) {
if(o1.times==o2.times){
//出现频次相同,按字典顺序排队
//comapreTo是字符值越小返回值越小,返回值越小越先出队,但是此处要让小的后出(保证留下字典序中小的),应改为o2.compareTo(o1)
return o2.word.compareTo(o1.word);
}else{
//按频次高低排序
//JDK内部默认就是最小堆的实现,o1.t-o2.t值越小,返回值越小,返回值越小越优先输出
return o1.times-o2.times;
}
}
});
for(Map.Entry entry:map.entrySet()){
if(queue.size() ret=new ArrayList<>();
for (int i = 0; i < k; i++) {
ret.add(queue.poll().word);
}
Collections.reverse(ret);
return ret;
}
}
5.Num1046:最后一块石头的重量
最大堆问题
* 有一堆石头,每块石头的重量都是正整数
* 每一回合,从中选出两块最重的石头,然后将它们一起粉碎。假设石头的重量分别为x和y,且x<=y。那么粉碎的可能结果如下:
* 如果 x == y,那么两块石头都会被完全粉碎;如果 x != y,那么重量为 x 的石头将会完全粉碎,而重量为 y 的石头新重量为 y-x。
* 最后,最多只会剩下一块石头。返回此石头的重量。如果没有石头剩下,就返回 0
import java.util.Comparator;
import java.util.PriorityQueue;
import java.util.Queue;
/**
* 分析:
* 最大堆问题
* 将所有石头的重量放入最大堆中。每次依次从队列中取出最重的两块石头a和b,必有a>=b。
* 如果a>b,则将新石头a-b放回到最大堆中;如果a=b,两块石头完全被粉碎,因此不会产生新的石头。重复上述操作,直到剩下的石头少于2块。
* 最终可能剩下 1块石头,该石头的重量即为最大堆中剩下的元素,返回该元素;也可能没有石头剩下,此时最大堆为空,返回0。
* 思路:
* 1.遍历将所有石头放入最大堆
* 2.对石头进行两次出队(先出的一定>=后出的)判断a==b继续循环,a>b则a-b的值入队
*/
public class Num1046_LastStoneWeight {
public int lastStoneWeight(int[] stones) {
Queue queue=new PriorityQueue<>(new Comparator() {
@Override
public int compare(Integer o1, Integer o2) {
return o2-o1;
}
});
for(int i:stones){
queue.offer(i);
}
//最大堆入队完毕
while (queue.size()>1){
int y= queue.poll();
int x= queue.poll();
if(y>x){
queue.offer(y-x);
}
}
//此时队中没有元素(全粉碎了)或剩余一个石头
return queue.isEmpty()?0: queue.poll();
}
}