redis常见面试题
redis常见面试题
redis集群转载于:https://blog.csdn.net/sun_lm/article/details/123467103
redis的几个数据结构的应用场景借鉴于:https://blog.csdn.net/weixin_51299478/article/details/125204374
1. redis的作用
redis的作用主要就是两个:高性能和高并发
-
高性能。
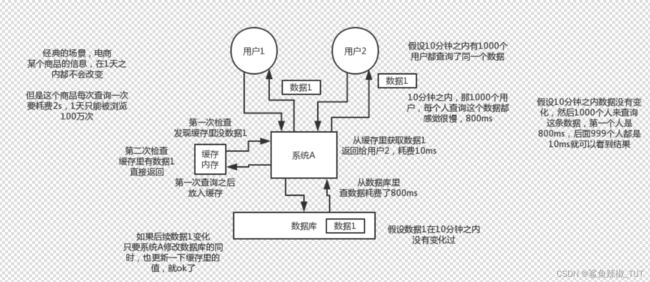
假设这么个场景,你有个操作,一个请求过来,吭哧吭哧你各种乱七八糟操作mysql,半天查出来一个结果,耗时600ms。但是这个结果可能接下来几个小时都不会变了,或者变了也可以不用立即反馈给用户。那么此时咋办?
利用redis缓存啊,把mysql折腾600ms查出来的结果,扔缓存里,一个key对应一个value,下次再有人查,别走mysql折腾600ms了。直接从缓存里,通过一个key查出来一个value,2ms搞定。性能提升300倍;这就是所谓的高性能。
-
高并发
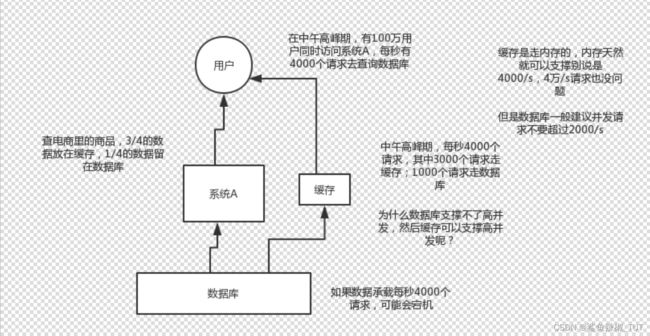
对于并发性很高的场景,mysql这么重的数据库,压根儿设计不是让你玩儿高并发的,虽然也可以玩儿,但是天然支持不好。mysql单机支撑到2000qps也开始容易报警了。 所以要是你有个系统,高峰期一秒钟过来的请求有1万,那一个mysql单机绝对会死掉。你这个时候就只能上缓存,把很多数据放缓存,别放mysql。缓存功能简单,说白了就是key-value式操作,单机支撑的并发量轻松一秒几万十几万,支撑高并发so easy。单机承载并发量是mysql单机的几十倍。
2. redis集群
系统中只有一台redis服务器是不可靠的,容易出现单点故障。为了避免单点故障,可以使用多台redis服务器组成redis集群。
redis集群就是让每台服务器只负责一部分任务,然后将这些服务器构成一个整体,对外界来说,这一组服务器就像是集群一样。
redis支持三种集群模式。
一、主从模式
至少需要两台redis服务器,一台主节点(master)、一台从节点(slave),组成主从模式的Redis集群。通常来说,master主要负责写,slave主要负责读,主从模式实现了读写分离。
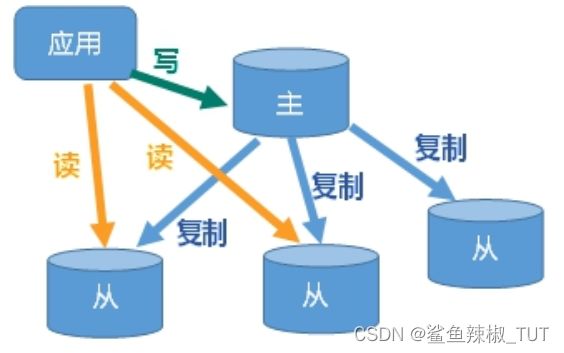
集群中有多台redis节点,就必须保证每个节点中的数据是一致的。redis中,为了保持数据一致性,数据总是从master复制到slave(从主复制到从),这就是redis的主从复制。
主从复制的作用:
- 数据冗余:实现了数据的热备份,是持久化之外的另一种数据冗余方式
- 故障恢复:master故障时,slave可以提供服务,实现故障快速恢复
- 负载均衡:master负责写,slave负责读。在写少读多的场景下可以极大提高redis吞吐量
- 高可用基石:主从复制是redis哨兵模式和集群模式的基础。
主从复制实现原理:
主从复制过程主要可以分为3个阶段:连接建立阶段、数据同步阶段、命令传播阶段。
- 连接建立阶段:在主从节点之间建立连接,为数据同步做准备。
- 数据同步阶段:执行数据的全量(或增量)复制(复制RDB文件)
- 命令传播阶段:主节点将已执行的命令发送给从节点,从节点接收命令并执行,从而实现主从节点的数据一致性
主从模式中,一个主节点可以有多个从节点。为了减少主从复制对主节点的性能影响,一个从节点可以作为另外一个从节点的主节点进行主从复制。
不足之处:主节点宕机之后,需要手动拉起从节点来提供业务,不能达到高可用。
二、哨兵模式(Sentinel)
Redis Sentinel是Redis的高可用实现方案,它可以实现对redis的监控、通知和自动故障转移,当redis master挂掉之后,可以自动拉起slave提供业务,从而实现redis的高可用。为了避免Sentinel本身出现单点故障,Sentinel自己也可采用集群模式。
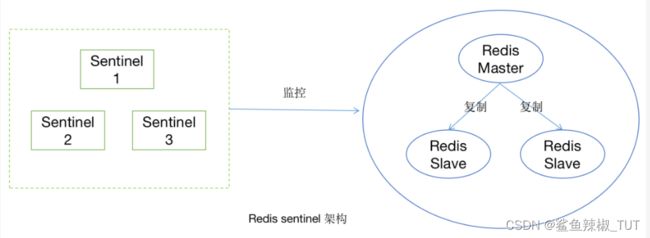
哨兵模式的原理
Sentinel是一种特殊的redis节点,每个sentinel节点会维护与其他redis节点(包括master/slave/sentinel)的心跳。
当一个sentinel节点与master节点的心跳丢失时,这个sentinel节点就会认为master节点出现了故障,处于不可用的状态,这种判定叫作主观下线(即sentinel节点自己主观认为master下线了)
之后,这个sentinel节点会与其他sentinel节点交换信息,如果发现认为主节点发生故障的sentinel节点的个数超过了某个阈值(通常为sentinel节点总数的1/2+1,即超过半数),则sentinel会认为master节点已经处于客观下线的状态,即大家都认为master故障不可用了。
之后,sentinel节点中会选举处一个sentinel leader来执行redis主节点的故障转移。
被选举出的 Sentinel 领导者进行故障转移的具体步骤如下:
- 在从节点列表中选出一个节点作为新的主节点
- 过滤不健康或者不满足要求的节点;
- 选择 slave-priority(优先级)最高的从节点, 如果存在则返回, 不存在则继续;
- 选择复制偏移量最大的从节点 , 如果存在则返回, 不存在则继续;
- 选择 runid 最小的从节点。
- Sentinel 领导者节点会对选出来的从节点执行 slaveof no one 命令让其成为主节点。
- Sentinel 领导者节点会向剩余的从节点发送命令,让他们从新的主节点上复制数据。
- Sentinel 领导者会将原来的主节点更新为从节点, 并对其进行监控, 当其恢复后命令它去复制新的主节点。
三、集群模式
主从模式实现了数据的热备份,哨兵模式实现了redis的高可用。但是有一个问题,这两种模式都没有解决,这两种模式都只能有一个master节点负责写操作,在高并发的写操作场景,master节点就会成为性能瓶颈。
redis的集群模式中可以实现多个节点同时提供写操作,redis集群模式采用无中心结构,每个节点都保存数据,节点之间互相连接从而知道整个集群状态。
如图所示集群模式其实就是多个主从复制的结构组合起来的,每一个主从复制结构可以看成一个节点,那么上面的Cluster集群中就有三个节点。
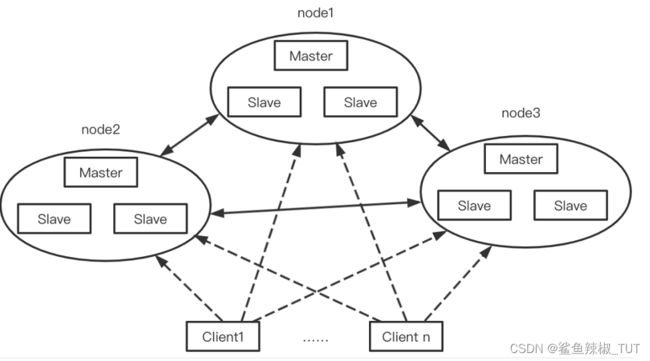
3. redis几个数据结构的应用场景
string(字符串)
在Redis中String是可以修改的,称为动态字符串(Simple Dynamic String 简称 SDS),说是字符串但它的内部结构更像是一个 ArrayList,内部维护着一个字节数组,并且在其内部预分配了一定的空间,以减少内存的频繁分配。
redis的内存分配机制是这样的:
- 当字符串的长度小于 1MB时,每次扩容都是加倍现有的空间。
- 如果字符串长度超过 1MB时,每次扩容时只会扩展 1MB 的空间。
这样既保证了内存空间够用,还不至于造成内存的浪费,字符串最大长度为 512MB。
应用场景:
-
计数器
string类型的incr和decr命令的作用是将key中储存的数字值加一/减一,这两个操作具有原子性,总能安全地进行加减操作,因此可以用string类型进行计数,如微博的评论数、点赞数、分享数,抖音作品的收藏数,京东商品的销售量、评价数等。
-
存储对象
利用JSON强大的兼容性、可读性和易用性,将对象转换为JSON字符串,再存储在string类型中,是个不错的选择,如用户信息、商品信息等。
Lisr(集合)
Redis中列表(list)类型是用来存储多个有序的字符串,列表中的每个字符串成为元素(element),一个列表最多可以存储2^32 - 1个元素。
在Redis中,可以对列表两端插入(push)和弹出(pop),还可以获取指定范围的元素列表、获取指定索引下标的元素等。列表是一种比较灵活的数据结构,可以充当栈和队列的角色,在实际开发中有很多应用场景。
列表类型有以下特点:
-
列表中的元素是有序的,即可以通过索引下标获取某个元素或者某个范围内的元素列表;
-
列表中的元素可以是重复的
-
redis中的list底层可不是一个双向链表那么简单。当数据量较少的时候它的底层存储结构为一块连续内存,称之为ziplist(压缩列表),它将所有的元素紧挨着一起存储,分配的是一块连续的内存;当数据量较多的时候将会变成quicklist(快速链表)结构。
可单纯的链表也是有缺陷的,链表的前后指针 prev 和 next 会占用较多的内存,会比较浪费空间,而且会加重内存的碎片化。在redis 3.2之后就都改用ziplist+链表的混合结构,称之为 quicklist(快速链表)。
应用场景
-
消息队列
Redis的lpush + brpop命令组合即可实现阻塞队列,生产者客户端使用lpush从列表左侧插入元素,多个消费者客户端使用brpop命令阻塞式的争抢列表尾部的元素,多个客户端保证了消费的负载均衡和高可用;
-
最新列表
list类型的lpush命令和lrange命令能实现最新列表的功能,每次通过lpush命令往列表里插入新的元素,然后通过lrange命令读取最新的元素列表,如朋友圈的点赞列表、评论列表。
Hash(字典)
Redis 中的 Hash和 Java的 HashMap 更加相似,都是数组+链表的结构,当发生 hash 碰撞时将会把元素追加到链表上,值得注意的是在 Redis 的 Hash 中 value 只能是字符串
应用场景
- 购物车:hset [key] [field] [value] 命令, 可以实现以用户Id,商品Id为field,商品数量为value,恰好构成了购物车的3个要素。
- 存储对象:hash类型的(key, field, value)的结构与对象的(对象id, 属性, 值)的结构相似,也可以用来存储对象。
set(集合)
Redis 中的 set和Java中的HashSet 有些类似,它内部的键值对是无序的、唯一 的。它的内部实现相当于一个特殊的字典,字典中所有的value都是一个值 NULL。当集合中最后一个元素被移除之后,数据结构被自动删除,内存被回收。
应用场景
-
好友、关注、粉丝、感兴趣的人集合
比如:
- 使用set的sinter命令可以获得A和B两个用户的共同好友;
- 使用set的sismember命令可以判断A是否是B的好友;
- 使用set的scard命令可以获取好友数量;
- 关注时,使用set的smove命令可以将B从A的粉丝集合转移到A的好友集合;
-
首页展示随机:美团首页有很多推荐商家,但是并不能全部展示,set类型适合存放所有需要展示的内容,而srandmember命令则可以从中随机获取几个。
-
存储某活动中中奖的用户ID ,因为有去重功能,可以保证同一个用户不会中奖两次。
zset(有序集合,zset也叫SortedSet)
zset也叫SortedSet一方面它是个 set ,保证了内部 value 的唯一性,另方面它可以给每个 value 赋予一个score,代表这个value的排序权重。它的内部实现用的是一种叫作“跳跃列表”的数据结构。
应用场景
- zset 可以用做排行榜,但是和list不同的是zset它能够实现动态的排序,例如: 可以用来存储粉丝列表,value 值是粉丝的用户 ID,score 是关注时间,我们可以对粉丝列表按关注时间进行排序。
- zset 还可以用来存储学生的成绩, value 值是学生的 ID, score 是他的考试成绩。 我们对成绩按分数进行排序就可以得到他的名次。
- zset还可以做排行榜,比如王者荣耀的巅峰赛排行榜
4. redis缓存击穿
什么是缓存击穿?
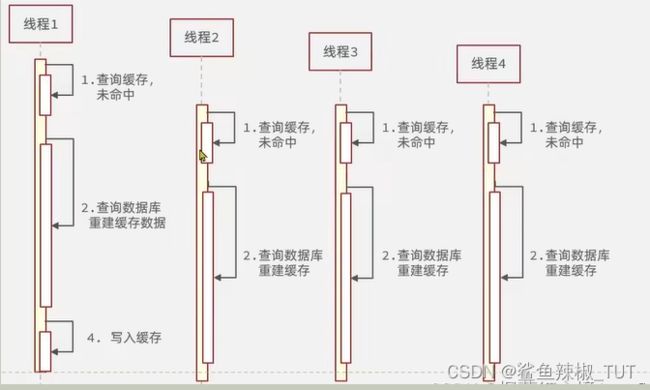
缓存击穿也叫热点key问题,就是一个被高并发访问并且缓存业务重构复杂的key突然失效了,无数的请求会在瞬间给数据库带来巨大的冲击。
当缓存的热点key过期后,一个线程来请求数据,查询缓存未命中,然后从数据库中查询然后重新构建缓存数据(需要一定的时间),在缓存数据还没构建完成此时又有大量请求进来去查询数据,缓存中未命中数据,于是后面进来的请求也同步之前请求从数据库中查询数据并构建缓存的这一过程,此时这些请求全部打到数据库中,导致数据库压力变大。
大致如下图,可以看到下面这个图中,线程1在构建缓存数据,但是还没没有构建好,又有很多线程来查询,发现缓存中没有数据,也去重建缓存了:
怎么解决?
-
利用互斥锁。在并发的多个请求中,只有第一个请求线程能拿到锁并执行数据库查询操作,其他的线程拿不到锁就阻塞等着,等到第一个线程将数据写入缓存后,直接走缓存。
执行过程如下图,线程2来的时候发现线程1占用了锁,就获取锁失败了,休眠一会,等一下再试。如果休眠时间很短,回来发现线程1还占锁,线程2就有休眠,等一下再试试。如果线程1释放锁了,所以线程2执行的时候就能拿到锁了,但是因为线程1就已经把数据写入到缓存再释放锁的,所以你线程2拿到锁去访问缓存的时候就能找到缓存中的数据了(当然如果线程2和线程1读的数据不一样,那么线程2去访问缓存,发现缓存中没有他需要的数据,即线程1写入缓存的数据不是线程2需要的数据,那么线程2还是会去访问数据库的,写数据到缓存,然后释放锁。):
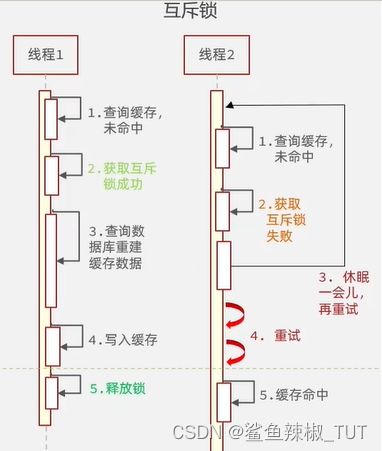
即一个线程得到锁去更新数据的时候,其他线程进来去查询数据的时候需要先去获取锁才能去查询数据库来更新缓存。此时因为已经有线程去更新缓存了,故在多次查询一样东西,后面几次查询就可命中缓存中的数据。我们看到这里,获取锁是在查询缓存没有命中才获取锁的,即,要是我们有多个线程同步获取相同的数据,要是缓存里有数据,那么他们是可以同时访问的,所以这里加锁让程序变慢的只会发生在有线程去访问数据库情况下,对能直接在缓存里查到数据的那些查询,锁并没有减慢他们的查询速度。
-
接口限流与熔断,降级。重要的接口一定要做好限流策略,防止用户恶意刷接口,同时要降级准备,当接口中的某些服务不可用时候,进行熔断,失败快速返回机制。
-
设置热点数据永远不过期(可以判断当前key快要过期时,通过后台异步线程在重新构建缓存)
5. redis缓存雪崩
什么是缓存雪崩?
当Redis宕机或者大量缓存集中在某一时间段失效,这时候大量的请求都会直接请求到数据库,此时可能就会把数据库压垮。
怎么解决?
- 使用 Redis 高可用架构:即使用 Redis 集群来保证 Redis 服务不会挂掉
- 给业务添加多级缓存
- 给缓存业务添加限流降级的策略
- 不同的key,设置不同的过期时间,让缓存失效的时间尽量均匀;
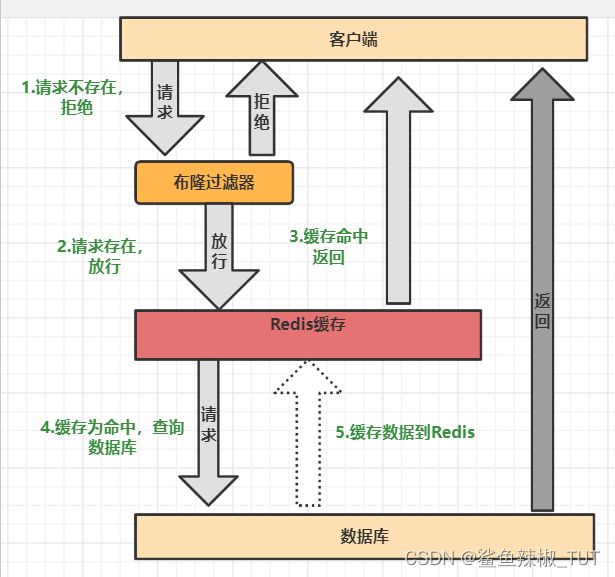
6. redis缓存穿透
什么是缓存穿透?
一般的缓存系统,都是按照key去缓存查询,如果不存在对用的value,就应该去后端系统查找(比如DB数据库)。一些恶意的请求会故意查询缓存中和数据库中都不存在的key,这时缓存就永远不会生效,而且要是这个用户请求量很大,这些请求都打到数据库从而导致数据库压力过大。这就叫做缓存穿透。
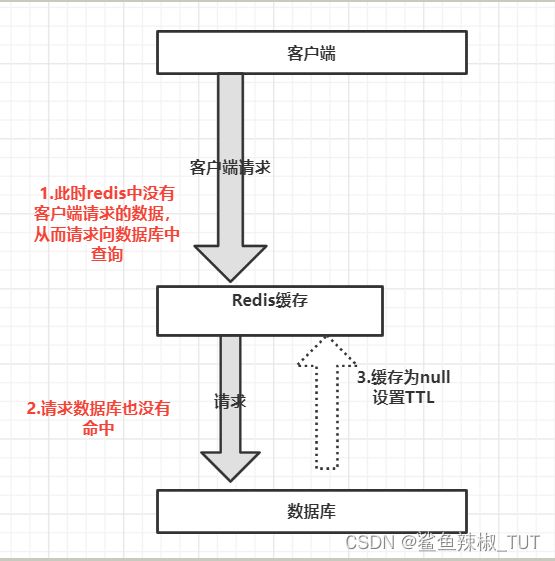
怎么解决?
-
对查询结果为空的情况也进行缓存,缓存时间设置短一点,或者该key对应的数据insert之后清理缓存。为什么要进行清除呢?因为大量无效的空值将占用空间,非常浪费,所以你要经常把这些空值清理。
-
布隆过滤器(Bloom Filter)拦截: 将所有可能的查询key 先映射到布隆过滤器中,查询时先判断key是否存在布隆过滤器中,存在才继续向下执行,如果不存在,则直接返回。布隆过滤器有一定的误判,所以需要你的业务允许一定的容错性。布隆过滤器(Bloom Filter),它实际上是一个很长的二进制向量(位图)和一系列的随机映射函数(哈希函数),它可以用于检索一个元素是否存在一个集合中,他的优点是空间的查询效率和查询时间都远远超过一般算法,缺点是有一定的误识别率并且删除比较困难。
总之,使用布隆过滤器的优缺点,如下:
- 优点:内存占用少,没有多余的key
- 缺点:实现的过程比较复杂,并且存在误判的可能