Linux学习记录——십칠 基础IO(2)
文章目录
- 理解文件系统
-
- 1、了解磁盘物理结构
- 2、逻辑抽象
- 3、文件系统
-
- 如何理解文件的增删查改
- 4、软硬连接
-
- 1、软链接
- 2、硬链接
- 3、继续深入
理解文件系统
之前已经知道,文件在没被打开的时候,会存放在磁盘等外设中,这篇的重点就是这些没被打开的文件,也就是磁盘文件,如果没被打开,那么如何理解它们?以及没被打开,会有什么问题?
文件在磁盘中一定是有序存放的,磁盘文件有序,系统在搜寻它们的时候,需要定位一个文件,再进行读取和写入。这样双方都有办法高效运行。Linux的文件是以树状结构存放的,无论是绝对还是相对路径都可以访问到具体的文件。
1、了解磁盘物理结构
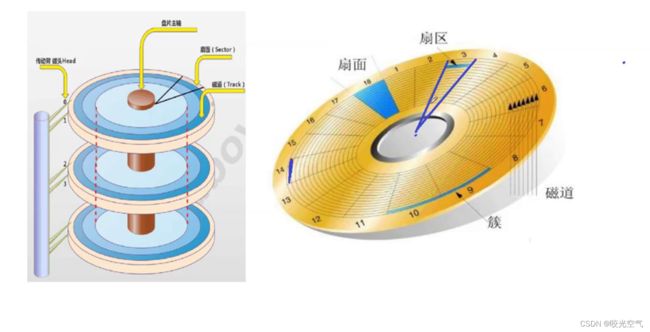
磁盘中存储的基本单元:扇区,512字节,一般磁盘所有的扇区都是512字节。同半径所有的扇区,构成磁道。
在单一个平面上,想要定位一个扇区需要先定位一个磁道,这由半径决定;再确定磁道在哪个扇区,这个根据扇区的编号来定位扇区。
不过在这之前,先要定位哪一个平面。
要定位面,可以用磁头编号来确定。柱面其实也代表了哪一个磁道。
定位的整体顺序就是磁头,柱面(磁道),扇区,也叫CHS定位法。
一个普通文件(属性+数据),也就是数据(0, 1),就是用一个或多个扇区来进行自己的数据的存储。CHS定位可以找到扇区,那就能从硬件角度找到文件,进行读取或写入。
2、逻辑抽象
经过第一阶段我们得知,系统得到任意一个CHS地址,就能访问任意一个扇区,但系统不能直接使用CHS地址,因为系统是软件,磁盘是硬件,CHS是硬件地址,如果已经硬件变了,那么系统也得发生变化。所以系统要和硬件做好解耦工作。
对于512字节的扇区,单位IO的基本数据量很小,但是系统实际进行IO时基本单位是4kb(可以调整),所以系统负担更大。基本单位的意思就是每次系统和外设进行IO都得读取4kb内容,不管IO的数据有多小。
盘面虽然为圆,但也是线性结构,就像多维数组在内存的存储方式一样。盘面有若干个磁道,一个磁道有若干个扇区,整体像一条线一样分布,所以是线性结构。对于这样的结构,每个扇区都有对应的编号,就像数组下标一样,所以定位扇区不难。
因为系统是以4kb为单位进行IO的,所以一个系统级别的文件要占8个扇区,在系统角度,系统不关心扇区。
计算机常规的访问方式是,起始地址+偏移量(由语言,数据类型决定),磁盘数据块的起始位置(第一个扇区的下标地址)+ 4kb(块的类型)。块的地址,本质就是数组的一个下标N,系统就会用这个N来定位任何一个块,这表示为OS->N->LBA->逻辑块地址。可是磁盘只认CHS,所以需要让LBA和CHS互相转化,这里系统是用数学计算来做的。
总结来看,对于磁盘的管理,最终转化成了对数组的管理,所以系统还是这个思路,先描述,再组织。
3、文件系统
块有很多,系统会给他们分区,也就是日常出现的cdef盘,不过内部其实只有一块盘,只是分区而已。
分区之后,系统对每个分区又会继续分成多个块组,然后把每个组的管理放到一样用到其他组,其他分区,就可以管理整个磁盘了。
一个分区最开始的位置有一个Boot Block,这里面会保存系统启动相关的设置,比如分区表,它存放于C盘;在系统启动时,它会加载磁盘驱动程序,加载分区表,读取操作系统的镜像文件,加载操作系统。
一个组里有很多个部分
Super Block
文件系统的所有属性信息,比如文件系统类型,整个分组情况。Linux采用的文件系统名称是Ext*。有234,这篇写Ext2.
实际上后面好几个组里SB的内容可能都一样,且统一更新,但它不放在外面而放在组内的原因是为了防止SB区域坏掉,如果坏掉,那么整个分区不可用。
Group Descriptor Table
组描述符,该组内的详细的统计等属性信息。
Inode Table
无论是文件的内容还是属性,都要以块的形式保存在磁盘某个位置。一般而言,一个文件内部所有属性的集合被称为inode节点(128字节),一个文件有一个inode。一个分区有大量的inode,一个组会有一个专门的区域来保存该组内所有的inode节点,叫做inode table。这个表存在的意义是为了区分开组内所有的inode,它会给每个inode一个inode编号,这个编号也属于对应文件的属性id。
Data blocks
文件的内容是可变的。系统用数据块来进行内容的保存。所以一个有效文件,要保存内容,就需要1 ~ n个数据块,多个文件就有多个数据块,也就是data blocks。
Linux查找文件是要根据inode编号来查找的,inode这个结构体中除了属性也有一个数组,对应该数据块的编号,那么就可以读取对应的内容了。一个inode对应一个文件,而该文件inode属性和该文件对应的数据块是有映射关系的。
inode Bitmap
inode的整体使用情况,也就是位图。 位图中第二个位置就是表示第二个inode,为0就是不正常工作,为1就是正常工作。
Block Bitmap
也是位图结构,每一个比特位表示data bolck是否空闲可用。
---------------------------------------------------------------------------------------------------------------
用ls -il就可以看到inode编号。Linux只认inode,文件的inode属性中,并不存在文件名,所谓的文件名是给用户区分的。目录同样也是文件,任何一个文件其实都在一个目录内部,那么目录的内容是什么呢?目录有数据块,里面保存了该目录下文件名和文件inode编号对应的映射关系,而且在目录内,文件名和inode互为key值。当用户访问一个文件时,用户是在特定目录下访问的,比如cat log.txt,这时候系统会先在当前目录下找到log.txt的inode编号,然后在目录所属的分区中,通过inode找到分组,在inode table中找到文件的inode,通过inode和对应的data block的映射关系,找到该文件的数据块,并加载到系统,显示出来。
如何理解文件的增删查改
根据文件名,系统找到inode 编号,根据inode将inode bitmap对应的比特位设置为0,这时候文件的属性就没了,然后根据inode找到data blocks对应的数据块,并且将block bitmap中对应的比特位设置为0,这样内容也就没了。所以删除文件只需要改位图即可。
创建一个文件时,在该目录所处的分组中查inode bitmap,找到比特位为0的位置,把它设置为1,根据第几个比特位也就得到了inode 编号,把文件创建后的默认属性填充进inode节点中,inode申请好数据,然后在目录的数据块中追加inode的映射关系和新的文件名。
误删文件怎么办?
只要知道被删文件的inode编号就可以恢复。先把inode bitmap的对应的比特位设置为1,读取inode表,提取这个文件对应的数据块,将block bitmap对应的位置设为1
但是前提是我们得知道inode,这个是在Linux的日志中记载的。
------------------------------------------------------------------------------------------------------------
一个分区一个文件系统,inode不能跨分区。 一个分区中会有很多个inode,假设已经设定好了前1万inode分配给一组,然后每个组的起始值就确定好了,分组中inode bitmap的位图结构的位置加上起始值就是inode在整个分区的位置。比如1万7是在第二组。
上面所提到的各种东西,比如文件的增删,磁盘分区,分区分组等等是谁做的?操作系统。分区完成后,为了能够让分区正常使用,需要对分区进行格式化。格式化的过程就是系统向分区写入文件系统的管理属性信息。如果这个分区已经被操作过了,那么格式化只是把位图结构全设置为0即可,inode table 和 data blocks不动。
如果inode只是单单用数组建立和data block的映射关系,假设有15个,那么这也就是意味着一个文件内容最多放入60kb
在inode结构体中,data block是一个数组,用下标访问数据块。但是数据块可能很大,前几个会是直接索引,二级索引中下标指向的数据块里的内容不是直接的数据而是其它数据块的编号,比如20, 32, 45, 56等等,一个编号,int类型,也就是4字节,4kb / 4byte = 1000,所以这里可以存放1000个编号。可以这样理解,inode结构体里的这个数组,相当于把数据块分成了好几份,前面是几份一个数据块,后面是一份多个数据块,数组整体的下标减少,每个下标访问的编号也不多,增加了效率。
有没有可能inode用完了,data block没用完?或者打他 block用完了,inode没用完。这是会出现的,且也没办法解决。不过基本也用不完。
4、软硬连接
1、软链接

ln -s myfile.txt my-soft
![]()
cat my-soft也可以查看到内容
软链接是一个独立的连接文件,有自己的inode number,有自己的inode属性和内容。
软链接存放是指向的文件的路径。
如果一个文件藏得太深,那么定义一个软连接可以很便捷地直接访问文件。
2、硬链接
ln myfile.txt my-hard
![]()
这时候myfile.txt权限后的数字从1变成了2,my-hard也是2,并且它们用得同一个inode,编号也一样,硬链接没有独立的inode。
硬链接建立了新的文件名,去映射老的inode,它没有独立的inode, 只是修改了一下目录。如果删除myfile文件,my-hard前面的数字从2变为1,但是cat一下还是能看到之前的内容。
创建一个文件后,再创建硬链接,这个硬链接会用同样的inode结构体,结构体里有个ref_count变量,这时候它就++变成2了,这个变量就是硬链接数,本质是一种引用计数,表示有多少个文件名指向我。
硬链接的删除可用unlink,也可以用rm。但删除并非一定是删除,如果有多个硬链接,就会把删除重载成减硬链接数的函数,直到还剩一个硬链接的时候就删除这个硬链接。
如果把内容重写到硬链接,也重写到了文件,所以两个写法都可以,本质上都是对文件进行写入。
3、继续深入
路径很深的时候,可以通过软链接来节省时间,那如果一个硬链接路径很深呢?
创建一个普通文件的时候,硬链接数是1,但创建一个目录则是2。所以系统里面,一定有一个文件名在目录创建的时候,指向了这个目录的inode,所有硬链接数是2,这个文件名是谁?在空目录里,我们知道它并不是绝对的空,还有别的隐藏文件,这其中就有. … 两个文件,代表当前目录和上级目录,这个. 和目录文件的inode一样,并且硬链接数都是2,所有就是点文件和目录文件指向了同一个inode。这也就是为什么写路径的时候可以写绝对路径也可以写相对路径,因为访问的文件都是一样的。
…文件硬链接数是3,它为什么是3?2个点和上上个目录文件都是一个inode,同样,上上个目录文件的点文件也是这个inode,所以就是3.
根据以上这个,可以大概推断出一个目录里的文件数就是目录的硬链接数-2.不过不够准,做个估计也就行了。
不能给目录建立硬链接
ln 目录名 hear-link。不行。这个行为只能操作系统做,用户不准做。这是因为目录建立硬链接容易造成环路路径问题。比如建立一个上上级目录的硬链接,那么访问到这个硬链接的时候程序又回到了上上级目录,最终就是死循环,环路问题。只是操作系统对此有特殊处理,所以不会有事。
结束。