32张图带你解决RocketMQ所有场景问题
一、RocketMQ的基本原理
「RocketMQ基本架构图如下」

image.png
从这个架构图上我们可以知道,RocketMQ有4块核心部分:
-
NameServer:管理Broker的信息,让使用MQ的系统感知到集群里面的broker -
Broker:主从架构实现数据多副本存储和高可用 -
producer:生产者 -
consumer:消费者
二、NameServer
2.1 Broker信息注册到哪个NameServer?
每台broker机器需要向所有的NameServer机器上注册自己的信息,防止单台NameServer挂掉导致Broker信息不全,保证NameServer的集群高可用。
2.2 Broker信息怎么注册?
基于Netty的网络通信。
2.3 Broker挂了如何感知?
-
「NameServer感知:30s心跳机制和120s故障感知机制」

image.png
broker会每隔30秒向NameServer发送一个的心跳 ,NameServer收到一个心跳会更新对应broker的最近一次心跳事件,然后NamServer会每隔十秒运行一个任务,去检查一下各个broker的最近一次心跳的时间,如果超过120s没有收到相应broker的心跳,则判定对应的broker已经挂掉。
三、Broker
3.1 Master-Slave模式
为了保证MQ的数据不丢失而且具备一定的高可用性,我们采用的是主从复制模式。
「RocketMQ自身的Master-Slave模式主采取的是Slave主动从Master拉取消息。」
3.2 究竟是如何从Master-Slave中进行读写呢?
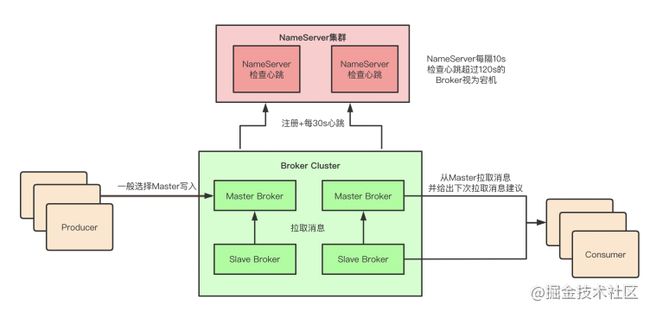
image.png
-
生产者在写入消息时,一般写入到Master
-
消费者在拉取消息时,可能从Master拉取,也可能从Slave拉取,「根据Master的负载情况和Slave的同步情况,」 由Master给出建议
-
Master负载过高,建议下次从Slave获取消息
-
Slave未同步完全,建议下次从Master获取消息
-
3.3 Broker宕机分析
3.3.1 Slave宕机
对系统会存在一点影响,但是影响不大,只不过少了Slave Broker,「会导致所有的读写压力都集中在Master Broker上」
3.3.2 Master宕机:基于Dledger实现RocketMQ高可用自动切换
选举方式这里不做重点介绍。
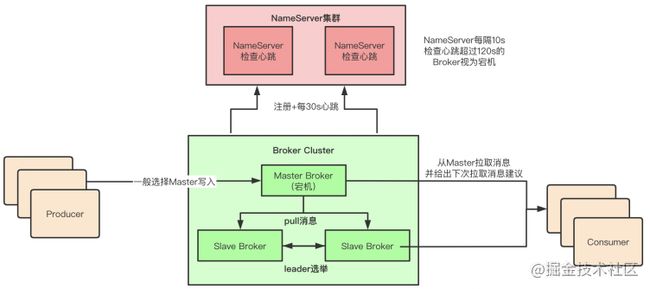
image.png
四、生产者
4.1 MessageQueue是什么?
我们先看看Topic、Broker、Message之间的关系。
如图比如说一个TopicA有n条消息,然后一个TopicA中的n条数据分配放入给4个MessageQueue1-4。

image.png
「所以本质上来说就是一个数据分片机制,通过MessageQueue将一个Topic的数据拆分为很多数据分片,在每个Broker机器上都存储一些MessageQueue。通过这个方法可以实现分布式存储。」
4.2 生产者发送消息写入哪个MessageQueue?

image.png
因为从前面我们知道,生产者会跟NameServer通信获取相应Topic的路由数据,从而知道,「一个Topic有几个MessageQueue,哪些MessageQueue在哪台Broker机器上,通过对应的规则写入对应的MessageQueue。」
4.2.1 Master Broker故障分析
当MasterBroker宕机,此时SlaveBroker正在切换过程中,有一组Broker就没有Master可以写入。
此时我们可以打开Producer的「自动容错机制开关:sendLatencyFaultEnable」,比如说访问其中一个Broker发现网络延迟有1000ms还无法访问,我们会自动回避这个Broker一段时间,比如接下来3000ms内,就不会访问这个Broker。
过一段时间之后,MasterBroker修复好了,或者说SlaveBroker选举成功了,就可以提供给别人访问了。

image.png
4.3 Broker数据存储(核心环节)
「Broker数据存储实际上是MQ最核心的环节:」
-
消息吞吐量
-
消息不丢失
4.3.1 磁盘日志文件CommitLog

image.png
首先,Producer发送消息给Broker,「Broker接收到消息后,把这个消息直接顺序写入写入到磁盘上的一个日志文件,叫做CommitLog。」
-
CommitLog是由很多磁盘文件组成
-
每个文件限定最多1GB
4.3.2 ConsumeQueue存储对应消息的偏移量
「在Broker中,每一个Topic下的每一个MessageQueue都会有对应一系列的ConsumeQueue文件。」
「Broker磁盘存储类似于文件树的形式存在:」

image.png
「ConsumeQueue中存储着对应MessageQueue中的消息在CommitLog中的物理偏移量地址offset。」

image.png
「如图:」
-
Broker接受消息,顺序写入消息到CommitLog中
-
同时找到对应的TopicA/MessageQueue1/ConsumeQueue0写入对应的物理地址
-
TopicA/MessageQueue1/ConsumeQueue0的物理地址,即为CommitLog文件中一个消息的引用
即:「Topic的每个MessageQueue都对应了Broker机器上的多个ConsumeQueue文件,这些ConsumeQueue共同组成保存了MessageQueue的所有消息在CommitLog文件中的物理offset偏移量。」
4.3.3 Broker写入磁盘CommitLog怎么近乎内存写性能?
「磁盘文件顺序写+OS PageCache写入+OS异步刷盘的策略」
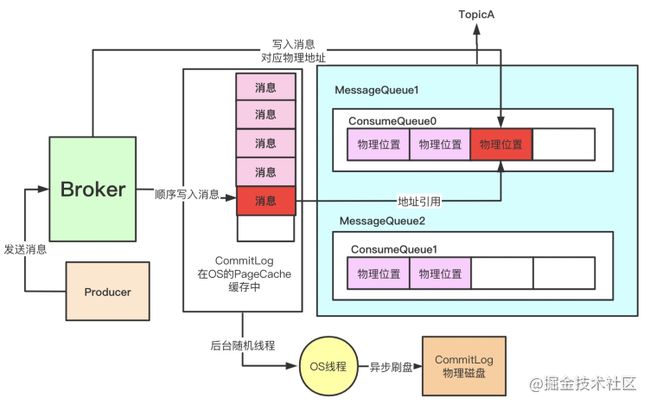
image.png
「如图:」
-
数据写入CommitLog时候,不是直接写入磁盘,而是写入OS的PageCache内存缓冲中
-
后台开启线程,异步刷盘到CommitLog中
「这样的话基本上可以让消息写入CommitLog的性能跟直接写入内存里面是差不多的,所以Broker才能具有高吞吐量。」
4.3.4 异步刷盘和同步刷盘
-
异步刷盘:高吞吐写入+丢失数据风险
-
同步刷盘:吞吐量下降+数据不丢失
对于日志类型这种场景,可以允许数据的丢失,但是要求比较高的吞吐量,可以采用异步刷盘的方式。另外非核心的业务场景,不涉及重要核心数据变更的场景,也可以使用异步刷盘,比如订单支付成功,发送短信这种场景。但是对于涉及到核心的数据变更的场景,就需要使用同步刷盘,比如订单支付成功后扣减库存。
五、消费者
5.1 一个Topic上多个MessageQueue怎么被消费?
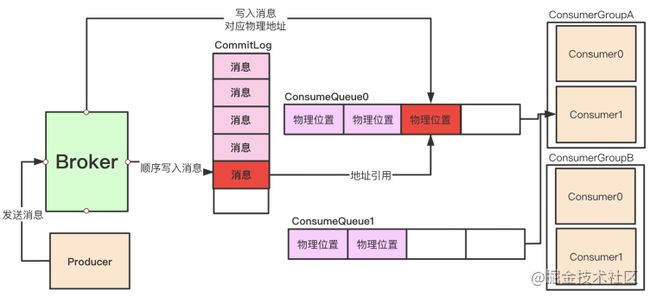
image.png
「原则」:一个Consumer机器可以消费处理多个MessageQueue,一个MessageQueue只能被一个相同ConsumerGroup中的同一个Consumer消费。
5.2 Broker收到消息拉取请求,返回给消费者处理提交消费进度
Broker收到消息拉取请求后,会找到对应的MessageQueue中开始消费的位置,在ConsumeQueue读取里面对应位置的的消息在CommitLog中的offset

image.png
「如图:」
-
consumer找到要消费的MessageQueue对应的ConsumeQueue对应要消费的位置
-
消费完成之后消费者返回一个消费状态,broker会存储我们的消费位置
-
接下来可以根据这个消费位置进行下一步消费,不需要从头拉取
5.3 消费者消费消息的性能问题
生产者是基于os cache提升写性能的,broker收到一条消息,会写入CommitLog文件,但是会先把CommitLog文件中的数据写入os cache(操作系统管理的缓存中),然后os开启后台线程,异步的将os cache缓存中的CommitLog文件的数据刷入磁盘。
在消费者消费信息的时候:
「第一步,我们会去读取ConsumeQueue中的offset偏移量,此时大量的读取压力全部都在ConsumeQueue,ConsumeQueue文件的读性能是很大程度上会影响消息拉取的性能和吞吐量。」
「所以,Broker对ConsumeQueue文件也是基于os cache来进行优化的。」
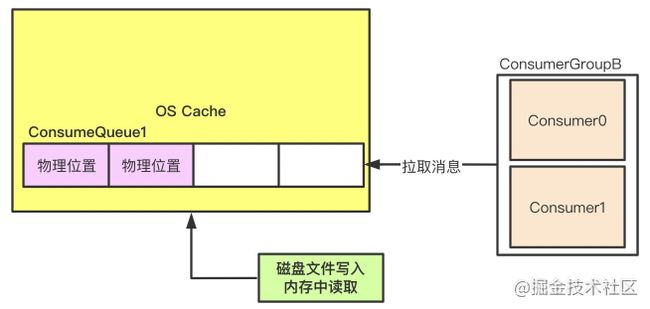
image.png
「实际上,ConsumeQueue主要只是存放消息的offset,所以每个文件很小,占不了多少磁盘空间,完全可以被os缓存在内存里。所以几乎可以说消息的读取性能达到内存级别。」
「第二步,根据读取到的offset去CommitLog里读取消息的完整数据。此时会有两种可能」
-
第一种:如果读取的是刚刚写入到CommitLog的数据,那么大概率他们还停留在os cache中,此时可以顺利的直接从os cache中读取CommitLog中的数据,这个就是直接读取内存,性能很高。
-
第二种:读取较早之前的CommitLog的数据,已经被刷入磁盘不在os cache里面了,此时只能从磁盘上的文件读取了,这个性能稍微差一点。
「这两种状态很好区分,比如说消费者一直在快速的拉取和消费处理,跟上了broker的消息写入速率,这么来说os cache中每次CommitLog的消息还没来得及被刷入磁盘中的时候就被消费者消费了;但是比如说broker负载很高,拉取消息的性能很低,跟不上生产者的速率,那么数据会保存在磁盘中进行读取。」
5.4 Master Broker什么时候通知你去Slave Broker读取?
根据以上,我们可以判断了什么时候Master Broker负载会高,也就是当消费者读取消息的时候,要从磁盘中加载大量的数据出来,此时Master Broker就会知道本次的负载会比较高,通知消费者下次从Slave Broker去拉取数据。
「本质上就是对比当前没有拉取消息的数量和大小,以及最多可以存放在os cache内存里的消****息的大小,如果没有拉取的消息超过了最大能使用的内存的量,那么之后会频繁的从磁盘加载数据,此时就让你从slave broker去加载数据了!」
六、问题分析
举一个简单的例子作为分析的入口,将从各个环节可能发生的问题进行深入分析,如图:

image.png
-
用户进行一笔生活缴费
-
订单系统推送缴费订单支付消息到RocketMQ
-
红包系统接受订单消息
-
发红包给用户
6.1 消息发送失败
「消息发送失败的原因多种多样,存在于多个环节,我们一一分析。」
6.1.1 系统推送消息丢失
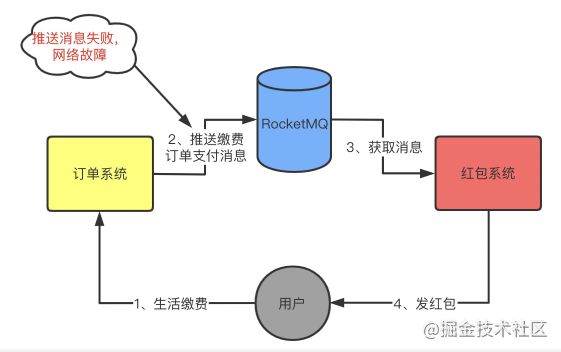
image.png
第一个环节就是,订单系统推送消息到MQ的过程中,由于网络等因素导致消息丢失。
6.1.2 RocketMQ的事务消息原理分析
为了解决系统推送消息丢失问题,RocketMQ有一个非常强悍的功能就是事务消息,能够确保我们消息一定会成功写入MQ里面,不会半路搞丢。
如图是在本系统中的一个基本事务消息的流程图。

image.png
-
「订单系统先发送half消息到MQ中,试探MQ是否正常」
如果此阶段,half消息发送给MQ失败,会执行一系列回滚操作,关闭这个订单的状态,因为后续的消息都操作不了
-
「当half消息成功被RocketMQ接收时」
-
返回half消息的成功响应,进入第3步
-
返回的响应未收到,但是此时MQ已经存储下来了一条half消息,进入第5步
-
-
「得知half消息发送成功之后,订单系统可以更新数据库,此时会有两种情况对应两种不同的提交」
-
更新数据库等操作一切顺利,向RocketMQ发送一个commit请求
-
由于网络异常或者数据库挂了等,为了执行数据库更新等操作,更新不了订单状态,发送rollback请求
-
发送rollback或者commit失败,跳转到第5步
-
-
「RocketMQ收到commit或者rollback请求」
-
收到rollback请求删除half消息
-
收到commit请求改变half消息状态为已提交,红包系统可以开始消费消息
-
-
「未收到commit和rollback请求的消息,RocketMQ会有补偿机制,回调接口去判断订单的状态是已关闭,则发送rollback进行回滚。」
6.1.3 RocketMQ的事务消息底层分析

image.png
「如图解释如下:」
-
「消费系统对half消息不可见的原因:」 我们知道,消费者是是通过ConsumeQueue获取到对应的CommitLog里面的消息,如图,消费系统对half消息不可见的原因是因为half消息在未提交的时候,MQ维护了一个内部的TRANS_HALF_TOPIC,此时红包系统只获取TopicA中的MessageQueue中ConsumeQueue。
-
「返回half消息成功的响应时机:」 当half消息写入成功到TRANS_HALF_TOPIC中的ConsumeQueue的时候,就回认为写入消息成功,返回给对应的订单系统成功响应。
-
「补偿机制:」 RocketMQ会启动一个定时任务,定时扫描half消息状态,如果还是为half消息,则回调订单系统接口,判断状态。
-
「如何标记消息回滚或提交:」 消息回滚并不是直接删除,而是内部维护了一个OP_TOPIC,用一个OP操作来标记half消息的状态。
-
「执行commit操作后消费系统可见:」 执行commit操作之后,OP操作会标记half为commit状态,并且把对应消息在TRANS_HALF_TOPIC中的消息offset写入到TOPICA中,此时消息可见
6.1.4 思考:一定要用事务消息吗?
上面这么复杂的事务消息机制可能导致整体的性能比较差,而且吞吐量会比较低,我们一定要用事务消息吗?
❝可以基于同步发送消息+反复多次重试的方案
❞
6.1.5 消息成功发送到MQ中了,就一定不会丢了吗?
我们可以分析的到,事务消息能够保证我们的消息从生产者成功发送到broker中对应的消费者需要消费的Topic中,我们认为他的消息推送成功。
「问题一:」
「但是这个消息推送仅仅先是推送到os cache缓存中,仅仅只是可以被消费系统看到,由于消息积压等原因,还没来得及去获取这条消息,还没来得及刷到ConsumeQueue的磁盘文件中去,此时万一机器突然宕机,os cache中的数据全部丢失,此时消息必然丢失,消费系统无法读到这条消息。」
「如图示意:」

「解决」:
为了解决这个问题,一定要确保消息零丢失的话,我们的解决办法就是「将异步刷盘调整为同步刷盘」。
放弃了异步刷盘的高吞吐量,确保消息数据的零丢失,也就是说只要MQ返回响应half消息发送成功了,此时消息就已经进入了磁盘文件了。
「问题二:」
「就算os cache的消息写入ConsumeQueue的磁盘文件了,红包没来得及消费这条消息的时候,磁盘突然就坏了,一样会导致消息丢失。」
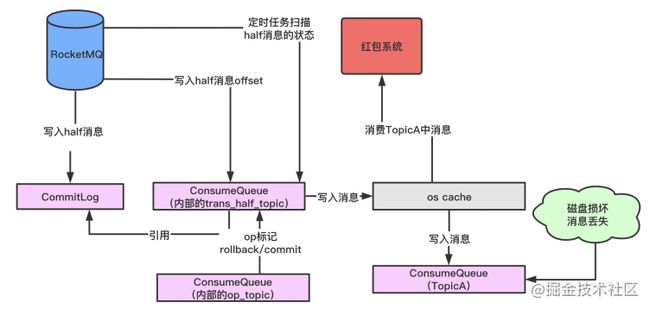
image.png
「所以说,无论是通过同步发送消息+反复多次重试的方案,还是事务消息的方案,哪怕保证写入MQ成功了,消息未必不会丢失。」
解决:
对Broker使用主从架构的模式,每一个MasterBroker至少有一个SlaveBroker去同步他的数据,而且一条消息写入成功,必须让SlaveBroker也写入成功,保证数据有多个副本的冗余。
6.1.6 红包系统拿到了消息就一定会消费消息吗?
「不一定。」
「问题分析:」
因为当红包系统拿到消息数据进内存里时,此时还没有执行发红包的逻辑,然后此时红包系统就已经提交了这条消息的offset到broker中告诉broker已经消费掉了这条消息,消息位置会往后移。然后此时红包系统宕机,这条消息就会丢失,永远执行不了发红包的逻辑。
「RocketMQ解决方案:」 利用消息监听器同步处理消息
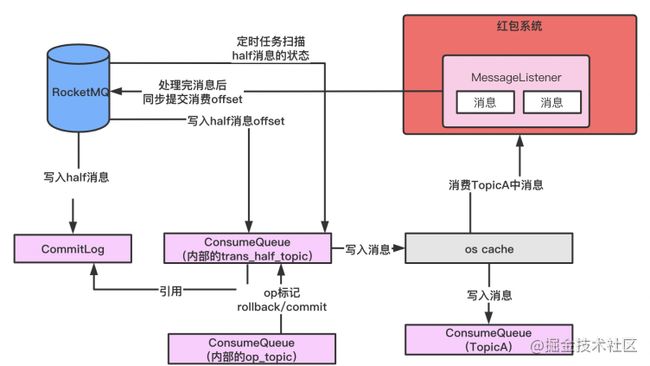
image.png
在RocketMQ的Consumer的默认消费模式下,我们在消息监听器中接收到一批消息之后,会执行处理消息的逻辑,处理完成之后才会返回SUCCESS状态提交offset到broker中,如果处理时宕机,不会返回SUCCESS状态给broker,broker会继续将这个消息给下一个Consumer消费。
6.2 消息发送全链路零丢失方案总结
6.2.1 发送消息到MQ的零丢失
-
同步发送消息+反复多次尝试
-
事务消息机制
6.2.2 MQ收到消息之后的零丢失
-
同步刷盘策略:解决os cache未能刷入磁盘问题
-
主从架构同步机制:解决单个broker磁盘文件损坏问题
6.2.3 消费消息的零丢失
-
采用同步处理消息方式
6.2.4 适用场景
「首先,消息零丢失方案会必然的导致从头到尾的性能下降和MQ的吞吐量下降」
一般和金钱、交易以及核心数据相关的系统和核心链路,可以用这套零消息丢失方案:比如支付系统、订单系统等。
6.3 消息发送重复
重复发红包等问题
6.3.1 发送方重复发送
「如图:」

image.png
-
用户支付缴费订单时候,会通知订单系统发送订单支付消息
-
此时订单系统响应超时
-
支付系统再次重试调用订单接口通知发送消息
-
两个订单都成功,推送两条相同的消息到MQ
-
红包系统收到两条消息发送两个红包
「有类似很多这种消息重试,接口重试的情况都会有消息重复发送的可能性,还比如说当你发送消息成功到MQ,MQ返回的SUCCESS的响应由于网络原因未收到,重试机制会再次发送消息,导致消息重复。」
「解决方案:幂等性机制」
-
「业务判断法:RocketMQ支持消息查询功能」
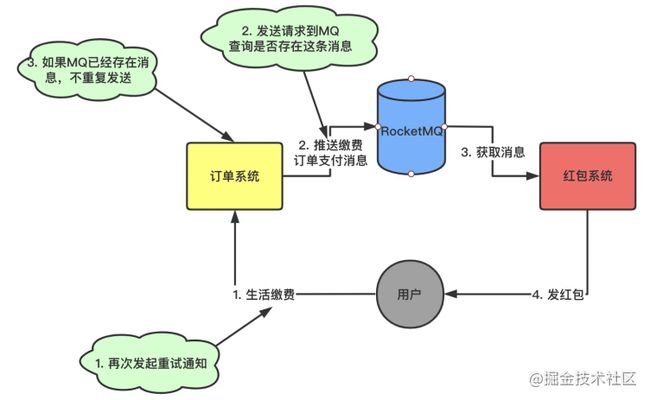
image.png
-
由于订单系统调用超时,重试调用接口
-
当订单系统发消息之前,发送请求到MQ查询是否存在这条消息
-
如果MQ已经存在,则不重复发送
-
「Redis缓存:」
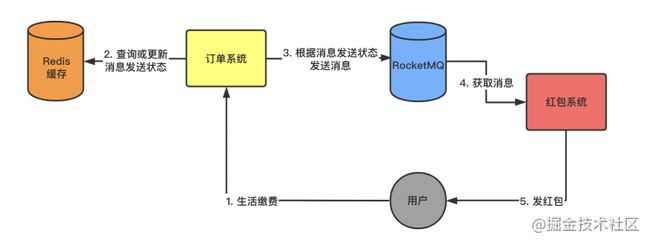
image.png
Redis缓存思想也比较简单,只需要根据对应的订单信息去缓存里面查询一下是否已经发送给MQ了。
但是这种解决方案也不是绝对的安全,因为你消息发送成功给MQ了还没来得及写Redis系统就挂了,之后也会被重复调用。
「总结以上两种解决方案,我们不建议在消息的发送环节保证消息的不重复发送,会影响接口性能。」
6.3.2 消费方重复消费

image.png
-
消费方消费消息,执行完了发红包逻辑后,应该返回SUCCESS状态,提交消费进度
-
但是刚发完红包,没来得及提交offset消费进度,红包系统重启
-
MQ没收到offset消费进度返回,将这个消息继续发送到消费系统进行消费
-
二次发送红包。
「解决方案:」
-
依据在生产者方设置消息的messageKey,然后每一条消息在消费方依据这个唯一的messageKey,进行幂等判断:
-
业务判断,判断这个业务的环节是否执行成功,如果没有成功则消费,成功则舍弃消息
-
维护一个消息表,当新的消息到达的时候,根据新消息的id在该表中查询是否已经存在该id,如果存在则表明消息已经被消费过,那么丢弃该消息不再进行业务操作即可
-
若是消息,然后执行insert数据库方法,可以建立一个唯一主键,插入会保证不会重复
6.4 死信队列
通过以上的学习,我已经基本解决了MQ消息不丢失以及不会重复处理消息的问题,在正常流程下基本上没有什么问题。但是会出现以下问题。
我们一直都是假设的一个场景就是红包系统的MessageListener监听回调函数接收到消息都能顺利的处理好消息逻辑,发送红包,落库等操作,返回SUCCESS,提交offset到broker中去,然后从broker中获取下一批消息来处理。
如图:
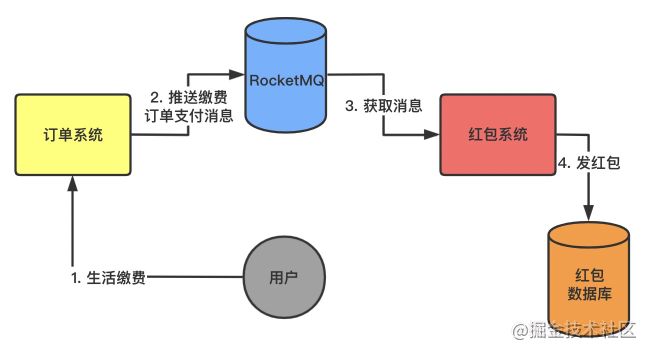
image.png
「问题:」
但是如果在我们MessageListener处理消息逻辑时候,红包数据库宕机了,没办法完成发红包的逻辑,此时出现对消息处理的异常,我们应该怎么处理呢?
「解决方案:」
在MessageListener中,除了返回SUCCESS状态,我们还可以返回RECONSUME_LATER状态,也就是用try-cache包裹住我们的业务代码,成功则返回SUCCESS状态,顺利进行后续操作,「如果出现异常则返回RECONSUME_LATER状态。」
「当RocketMQ收到我们返回的RECONSUME_LATER状态之后,会将这批消息放到对应消费组的重试队列中。」
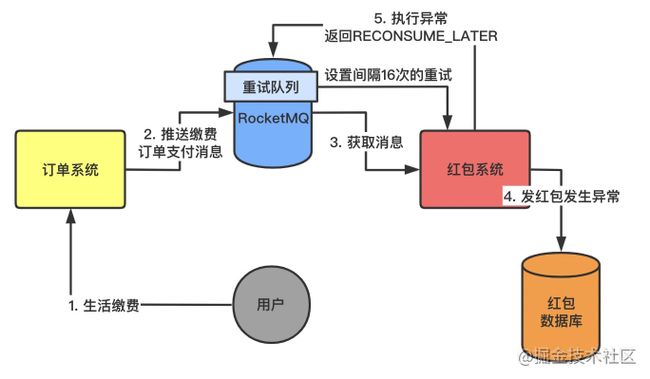
image.png
重试队列里面的消息会再次发给消费组,默认最多重试16次,如果重试16次失败则进入「死信队列。」
「死信队列:」
对于死信队列,一般我们可以专门开一个后台线程,订阅这个死信队列,对死信队列中的消息,一直不停的尝试。
6.5 消息乱序
6.5.1 业务场景
「大数据团队要获取到订单系统的binlog,然后保存一份在自己的大数据存储系统中」
「数据库binlog:记录数据库的增删改查操作。」
大数据团队不能直接跑复杂的大SQL在订单系统的数据库中跑出来一些数据报表,这样会严重影响订单系统的性能,为了优化方案,我们采用类似基于Canal这样的中间件去监听订单数据的binlog,然后把这个binlog发到MQ中去,然后我们的大数据系统自己用MQ里获取binlog,自己在自己的大数据存储中执行增删改查操作,得到我们需要的报表,如图下:

image.png
6.5.2 乱序问题原理分析
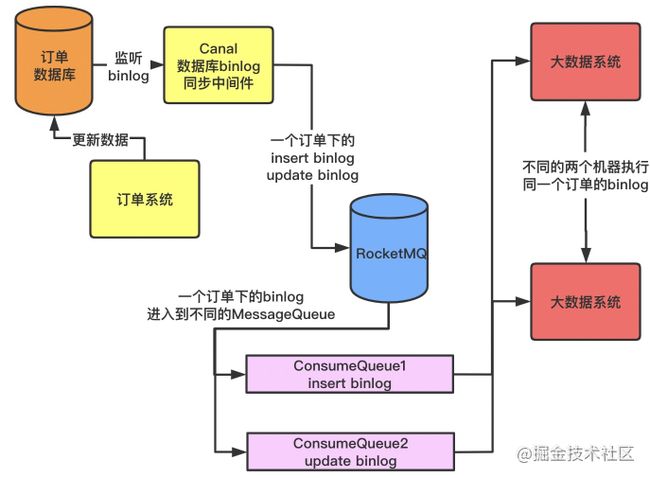
image.png
-
Canal监听到binlog日志中,操作数据库的顺序为先执行insert插入操作,后update更新操作。
-
因为我们消息可能会发送到不同MessageQueue中的不同的ConsumeQueue中去
-
然后同一个消费组的大数据消费系统获取到insert binlog和update binlog,「这两个是并行操作的,所以不能确定哪个消息先获取到执行,可能会出现消息乱序。」
6.5.3 消息乱序解决方案
出现上面问题的原因,根本问题就是一个订单binlog分别进入了两个MessageQueue中,解决这个问题的方法其实非常简单,就是得想办法让同一个订单的binlog进入到一个MessageQueue里面去。
「方法很简单:我们可以根据订单id对MessageQueue的数量取模来对应每个订单究竟去哪个MessageQueue。」
「消息乱序解决方案不能和重试队列混用。」
6.6 延迟消息
6.6.1 业务场景
「大量订单点击提交未支付,超过30min需要自动退款,我们研究需要定时退款扫描问题。」
「如图:」
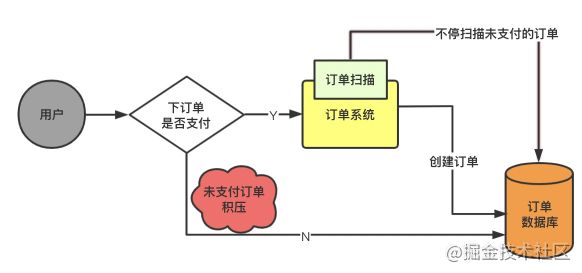
image.png
当一个订单下单之后,没有支付会进入订单数据库保存,如果30分钟内没有支付,就必须订单系统自动关闭这个订单。
可能我们就需要有一个后台的线程,不停的去扫描订单数据库里所有的未支付状态的订单,超过30分钟了就必须把订单状态更新为关闭。这里会有一个问题,订单系统的后台线程必须不停的扫描各种未支付的订单,可能每个未支付的订单在30分钟之内会被扫描很多遍。这个扫描订单的服务是一个麻烦的问题。
「针对这种场景,RocketMQ的延迟消息就登场了。」
「如图:」

image.png
-
创建一个订单,发送一条延迟消息到MQ中去
-
需要等待30分钟之后,才能被订单扫描服务消费
-
当订单扫描服务在30分钟后消费了一条消息,就针对这条消息查询订单数据库
-
看过了30分钟了,他的支付状态如果是未支付,则关闭,这样只会被扫描到一次
「所以RocketMQ的延迟消息,是非常常用并且非常有用的一个功能」
6.7 经验总结
6.7.1 运用tags过滤数据
在一些真正的生产项目中,「我们需要合理的规划Topic和里面的tags」,一个Topic代表了某一类的业务消息类型数据,我们可以通过里面的tags来对同一个topic的一些消息进行过滤。
6.7.2 基于消息key来定位消息是否丢失
我们在消息零丢失方案中,万一消息真的丢失了,我们怎么去排查呢?在RocketMQ中我们可以给消息设置对应的Key值,比如设置一个订单ID:message.setKeys(orderId),「这样这个消息就和一个key绑定起来,当这个消息发送到broker中去,会根据对应message的数量构建hash索引」,存放在IndexFile索引文件中,我们可以通过MQ提供的命令去查询。
6.7.3 消息零丢失方案的补充
在我们这种大型的金融级的系统,或者跟钱有关的支付系统等等,需要有超高级别的高可用保障机制,所以对于零消息丢失解决方案来说,万一一整个MQ集群彻底崩溃了,我们需要有更完善的措施来保证我们消息不会丢失。
此时生产者发送不了消息到MQ,所以我们「生产者就应该把消息在本地进行持久化」,可以是存在本地磁盘,也可以是在数据库里去存起来,MQ恢复之后,再把持久化的消息投递到MQ中去。
6.7.4 提高消费者的吞吐量
最简单的方法去提高消费者的吞吐量,就是提高消费者的并行度,比如说部署更多的Consumer机器去消费消息。但是我们需要明确的一点就是对应的MessageQueue也要增加,因为一个MessageQueue只能被一个Consumer机器消费。
第二个办法是我们可以增加Consumer的线程数量,消费线程乐队,消费速度越快。
第三个办法是我们可以开启消费者的批量消费功能(有对应的参数设置)。
6.7.5 要不要消费历史记录
Consumer是支持设置在哪里开始消费的,常见的有两种:从Topic的第一条数据消费(CONSUME_FROM_LAST_OFFSET),或者是从最后一次消费过的消息之后开始消费(CONSUME_FROM_FIRTST_OFFSET),我们一般都是设置选择后者。
七、百万消息积压问题
7.1 业务场景
如图所示:在一个系统中,由生产者系统和消费者系统两个环节组成,生产者不断的向MQ里面写入消息,消费者不断的从MQ中消费消息。「突然有一天消费者依赖的一些数据库挂了,消费者就处理不了当下的业务逻辑,消息也不能正常的被消费,此时生产者还在正常的向MQ中写入消息,结果在高峰期内,就往MQ中写入了百万条消息,都积压在了MQ里面了。」

image.png
7.2 解决方案
「第一,」 最简单粗暴的方法,如果我们的消息能够容忍百万消息的丢失,那么我们可以直接修改消费者系统的代码,丢弃所有的消息,那么百万消息很快就被处理完了,但是往往对于绝大多数系统而言,我们不能使用这种办法。
「第二,」 我们需要等待消费者依赖的数据库恢复之后,根据线上的Topic的MEssageQueue来判断后续如何处理。
「MessageQueue数量多:」
-
比如说我现在一个Topic中有20个MessageQueue,有4个消费者系统在消费,那么我每个消费者就会从5个MessageQueue中获取消息进行消费,毕竟积压了百万消息,仅仅依赖4个消费者是远远不够的。
-
所以我们可以临时申请16台机器多部署16个消费者,这样20个消费者去同时消费20个MessageQueue,速度提高了5倍,积压的百万消息很快就能处理完毕。
-
但是此时我们要考虑的是,增加了5倍的消费能力,那么数据库的压力就增加了5倍,这个是我们需要考虑的
「如图:」

image.png
「MessageQueue数量少:」
-
比如说一个Topic总共就只有4个MessageQueue,然后就只有4个消费者系统,这时候没办法扩容消费系统
-
所以此时我们可以临时修改那4个消费者系统的代码,让他们获取的消息不写入数据库,而是写入一个新的topic
-
新的Topic有新增的20个MessageQUeue,部署20台临时增加的消费者系统去消费新的Topic中的Message。
「如图:」

image.png
八、MQ集群数据迁移问题:双读+双写
要做MQ的集群迁移,不是简单的粗暴的把Producer更新停机,新的代码重新上线发到新的MQ中去。
一般来说,我们需要做到两件事情:
-
「双写:」 要迁移的时候,我们需要在所有的Producer系统中,要引入一个双写的代码,让他同时往新老两个MQ中写入消息,多写几天,起码要持续一个星期,我们会发现这两个MQ的数据几乎一模一样了,但是双写肯定是不够的的,我们还要同时进行双读。
-
「双读:」 也就是说我在双写的时候,所有的Consumer系统都需要同时从新老两个MQ里面获取消息,分别都用一模一样的逻辑处理,只不过从老MQ中还是去走核心逻辑处理,可以落库存储之类的操作,但是新的MQ我们可以用一样的逻辑处理,但是不能把处理的结果具体落库,我们可以写入一个临时的存储中。
-
「观察:」 双写和双读一段时间之后,我们通过消费端对比,发现处理消息数量一致。
-
「切换:」 正式实施切换,停机Producer系统,再重新修改上线,全部修改为新MQ,此时他数据并不会丢失,因为之前已经双写一段时间了,然后Consumer系统代码修改上线。